此參考架構示範如何使用 Azure Batch 搭配 R 模型執行批次評分。 Azure Batch 適用於內部平行工作負載,並包含作業排程和計算管理。 批次推斷(評分)廣泛使用來分割客戶、預測銷售、預測客戶行為、預測維護或改善網路安全。

工作流程
此架構包含下列元件。
Azure Batch 會在虛擬機叢集上平行執行預測產生作業。 使用 R 中實作的預先定型機器學習模型進行預測。Azure Batch 可以根據提交至叢集的作業數目自動調整 VM 數目。 在每個節點上,R 腳本會在 Docker 容器內執行,以評分數據併產生預測。
Azure Blob 儲存體 儲存輸入數據、預先定型的機器學習模型,以及預測結果。 它會為此工作負載所需的效能提供符合成本效益的記憶體。
Azure 容器執行個體 會視需要提供無伺服器計算。 在此情況下,容器實例會依排程部署,以觸發產生預測的 Batch 作業。 Batch 作業是使用 doAzureParallel 套件從 R 腳本觸發。 容器實例會在作業完成後自動關閉。
Azure Logic Apps 會依排程部署容器實例來觸發整個工作流程。 Logic Apps 中的 Azure 容器執行個體 連接器可讓實例部署在一系列觸發程式事件上。
元件
解決方案詳細資料
雖然下列案例是以零售商店銷售預測為基礎,但是對於任何需要使用 R 模型產生預測的案例,其架構都可以一般化。 GitHub 上提供此架構的參考實作。
潛在的使用案例
連鎖超市需要預測未來季度的產品銷售量。 預測允許公司更好地管理其供應鏈,並確保它可以滿足其每個商店的產品需求。 隨著前一周的新銷售數據可供使用,並設定下個季度的產品行銷策略,該公司每周都會更新其預測。 會產生分位數預測,以估計個別銷售預測的不確定性。
處理牽涉到下列步驟:
Azure 邏輯應用程式會每周觸發預測產生程式一次。
邏輯應用程式會啟動執行排程器 Docker 容器的 Azure 容器實例,以觸發 Batch 叢集上的評分作業。
評分作業會跨 Batch 叢集的節點平行執行。 每個節點:
提取背景工作角色 Docker 映射並啟動容器。
從 Azure Blob 記憶體讀取輸入數據和預先定型的 R 模型。
為數據評分以產生預測。
將預測結果寫入 Blob 記憶體。
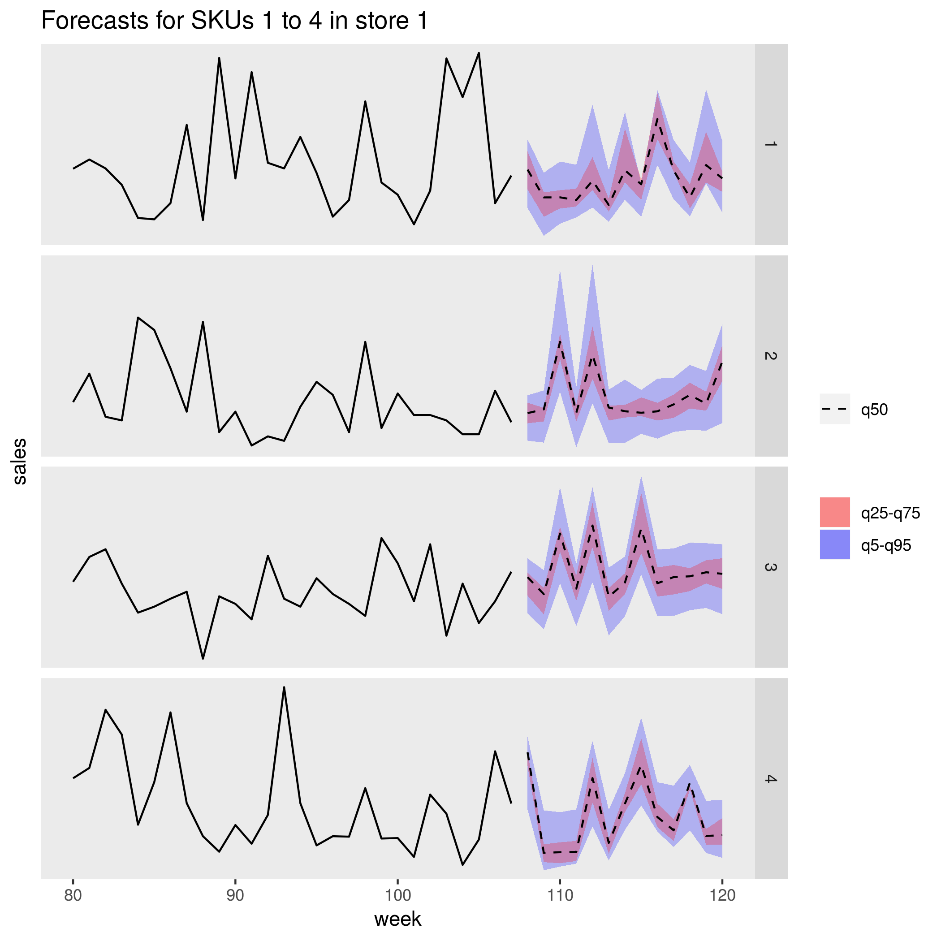
下圖顯示一家商店中四個產品(SKU)的預測銷售額。 黑線是銷售歷程記錄,虛線是中位數(q50)預測,粉紅色帶代表第25和第75個百分位數,而藍色帶代表第50和第95個百分位數。
考量
這些考慮會實作 Azure Well-Architected Framework 的支柱,這是一組指導原則,可用來改善工作負載的品質。 如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework。
效能
容器化部署
使用此架構時,所有 R 腳本都會在 Docker 容器內執行。 使用容器可確保腳本每次都以相同的 R 版本和套件版本在一致的環境中執行。 個別的 Docker 映射會用於排程器和背景工作角色容器,因為每個映像都有一組不同的 R 套件相依性。
Azure 容器執行個體 提供無伺服器環境來執行排程器容器。 排程器容器會執行 R 腳本,以觸發在 Azure Batch 叢集上執行的個別評分作業。
Batch 叢集的每個節點都會執行背景工作容器,其會執行評分腳本。
平行處理工作負載
使用 R 模型批次評分數據時,請考慮如何平行處理工作負載。 輸入數據必須分割,才能將評分作業分散到叢集節點。 請嘗試不同的方法來探索散發工作負載的最佳選擇。 以案例為基礎,請考慮:
- 在單一節點的記憶體中可以載入和處理多少數據。
- 啟動每個批次作業的額外負荷。
- 載入 R 模型的額外負荷。
在此範例中使用的案例中,模型物件很大,只需要幾秒鐘的時間才會產生個別產品的預測。 基於這個理由,您可以將產品分組,並針對每個節點執行單一 Batch 作業。 每個作業內的循環都會循序產生產品的預測。 此方法是平行處理此特定工作負載的最有效率方式。 它可避免啟動許多較小的 Batch 作業,並重複載入 R 模型的額外負荷。
替代方法是為每個產品觸發一個 Batch 作業。 Azure Batch 會自動形成作業佇列,並在節點可供使用時提交它們以在叢集上執行。 根據作業數目,使用 自動調整 來調整叢集中的節點數目。 如果完成每個評分作業需要相當長的時間,此方法就很有用,這可讓啟動作業和重載模型對象的額外負荷合理。 這個方法也比較容易實作,而且可讓您彈性地使用自動調整,如果事先不知道總工作負載的大小,請務必考慮。
監視 Azure Batch 作業
從 Azure 入口網站 中 Batch 帳戶的 [作業] 窗格監視和終止 Batch 作業。 從 [集區] 窗格監視批次叢集,包括個別節點的狀態。
使用 doAzureParallel 記錄
doAzureParallel 套件會自動收集 Azure Batch 上提交之每個作業的所有 stdout/stderr 記錄。 您可以在安裝時建立的記憶體帳戶中找到這些記錄。 若要檢視它們,請使用記憶體導覽工具,例如 Azure 儲存體 Explorer 或 Azure 入口網站。
若要在開發期間快速偵錯 Batch 作業,請檢視本機 R 會話中的記錄。 如需詳細資訊,請參閱使用設定 和提交定型執行。
成本最佳化
成本優化是考慮如何減少不必要的費用,並提升營運效率。 如需詳細資訊,請參閱 成本優化要素概觀。
此參考架構中使用的計算資源是成本最高的元件。 在此案例中,每當觸發作業,然後在作業完成之後關閉時,就會建立固定大小的叢集。 只有在叢集節點正在啟動、執行或關閉時,才會產生成本。 此方法適用於產生預測所需的計算資源,從作業到作業維持相對不變的情況。
在事先不知道完成作業所需的計算量的情況下,可能更適合使用自動調整。 使用此方法時,叢集的大小會根據作業的大小相應增加或減少。 Azure Batch 支援一系列自動調整公式,您可以在使用 doAzureParallel API 定義叢集時設定此公式。
在某些情況下,作業之間的時間可能太短,無法關閉和啟動叢集。 在這些情況下,如果適當,請讓叢集在作業之間執行。
Azure Batch 和 doAzureParallel 支援使用低優先順序 VM。 這些 VM 具有顯著的折扣,但其他優先順序較高的工作負載會承擔風險。 因此,不建議針對重要的生產工作負載使用低優先順序 VM。 不過,它們適用於實驗性或開發工作負載。
部署此案例
若要部署此參考架構,請遵循 GitHub 存放庫中所述的步驟。
參與者
本文由 Microsoft 維護。 原始投稿人如下。
主體作者:
- 安格斯·泰勒 |資深 資料科學家
若要查看非公用LinkedIn配置檔,請登入LinkedIn。