忙碌資料庫反模式
將處理卸載至資料庫伺服器可能會導致它花費大量時間執行程式碼,而不是回應儲存和擷取資料的要求。
問題說明
許多資料庫系統都可以執行程式碼。 範例包括預存程式和觸發程式。 通常,在接近資料時執行此處理會更有效率,而不是將資料傳輸至用戶端應用程式進行處理。 不過,過度使用這些功能可能會造成效能損害,原因有數個:
- 資料庫伺服器可能會花費太多時間處理,而不是接受新的用戶端要求和擷取資料。
- 資料庫通常是共用資源,因此在高使用量期間可能會成為瓶頸。
- 如果資料存放區已計量,執行時間成本可能會過高。 這特別適用于受控資料庫服務。 例如,Azure SQL 資料庫資料庫交易單位 (DTU) 的費用 。
- 資料庫具有相應增加的有限容量,而且水準調整資料庫並不簡單。 因此,最好將處理移至計算資源,例如 VM 或 App Service 應用程式,以輕鬆相應放大。
此反模式通常會發生,因為:
- 資料庫會視為服務,而不是存放庫。 應用程式可能會使用資料庫伺服器來格式化資料(例如,轉換成 XML)、操作字串資料,或執行複雜的計算。
- 開發人員嘗試撰寫查詢,其結果可以直接向使用者顯示。 例如,查詢可能會根據地區設定來結合欄位或格式日期、時間和貨幣。
- 開發人員正嘗試藉由將計算推送至資料庫,來更正 多餘的擷取反模式。
- 預存程式可用來封裝商務邏輯,也許是因為它們被認為更容易維護和更新。
下列範例會擷取指定銷售領域的 20 個最有價值的訂單,並將結果格式化為 XML。 它會使用 Transact-SQL 函式來剖析資料,並將結果轉換成 XML。 您可以在這裡 找到完整的範例 。
SELECT TOP 20
soh.[SalesOrderNumber] AS '@OrderNumber',
soh.[Status] AS '@Status',
soh.[ShipDate] AS '@ShipDate',
YEAR(soh.[OrderDate]) AS '@OrderDateYear',
MONTH(soh.[OrderDate]) AS '@OrderDateMonth',
soh.[DueDate] AS '@DueDate',
FORMAT(ROUND(soh.[SubTotal],2),'C')
AS '@SubTotal',
FORMAT(ROUND(soh.[TaxAmt],2),'C')
AS '@TaxAmt',
FORMAT(ROUND(soh.[TotalDue],2),'C')
AS '@TotalDue',
CASE WHEN soh.[TotalDue] > 5000 THEN 'Y' ELSE 'N' END
AS '@ReviewRequired',
(
SELECT
c.[AccountNumber] AS '@AccountNumber',
UPPER(LTRIM(RTRIM(REPLACE(
CONCAT( p.[Title], ' ', p.[FirstName], ' ', p.[MiddleName], ' ', p.[LastName], ' ', p.[Suffix]),
' ', ' ')))) AS '@FullName'
FROM [Sales].[Customer] c
INNER JOIN [Person].[Person] p
ON c.[PersonID] = p.[BusinessEntityID]
WHERE c.[CustomerID] = soh.[CustomerID]
FOR XML PATH ('Customer'), TYPE
),
(
SELECT
sod.[OrderQty] AS '@Quantity',
FORMAT(sod.[UnitPrice],'C')
AS '@UnitPrice',
FORMAT(ROUND(sod.[LineTotal],2),'C')
AS '@LineTotal',
sod.[ProductID] AS '@ProductId',
CASE WHEN (sod.[ProductID] >= 710) AND (sod.[ProductID] <= 720) AND (sod.[OrderQty] >= 5) THEN 'Y' ELSE 'N' END
AS '@InventoryCheckRequired'
FROM [Sales].[SalesOrderDetail] sod
WHERE sod.[SalesOrderID] = soh.[SalesOrderID]
ORDER BY sod.[SalesOrderDetailID]
FOR XML PATH ('LineItem'), TYPE, ROOT('OrderLineItems')
)
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC
FOR XML PATH ('Order'), ROOT('Orders')
顯然,這是複雜的查詢。 如稍後所見,結果會在資料庫伺服器上使用大量處理資源。
如何修正問題
將處理從資料庫伺服器移至其他應用層。 在理想情況下,您應該使用資料庫優化的功能,例如 RDBMS 中的匯總,限制資料庫執行資料存取作業。
例如,先前的 Transact-SQL 程式碼可以取代為只擷取要處理之資料的 語句。
SELECT
soh.[SalesOrderNumber] AS [OrderNumber],
soh.[Status] AS [Status],
soh.[OrderDate] AS [OrderDate],
soh.[DueDate] AS [DueDate],
soh.[ShipDate] AS [ShipDate],
soh.[SubTotal] AS [SubTotal],
soh.[TaxAmt] AS [TaxAmt],
soh.[TotalDue] AS [TotalDue],
c.[AccountNumber] AS [AccountNumber],
p.[Title] AS [CustomerTitle],
p.[FirstName] AS [CustomerFirstName],
p.[MiddleName] AS [CustomerMiddleName],
p.[LastName] AS [CustomerLastName],
p.[Suffix] AS [CustomerSuffix],
sod.[OrderQty] AS [Quantity],
sod.[UnitPrice] AS [UnitPrice],
sod.[LineTotal] AS [LineTotal],
sod.[ProductID] AS [ProductId]
FROM [Sales].[SalesOrderHeader] soh
INNER JOIN [Sales].[Customer] c ON soh.[CustomerID] = c.[CustomerID]
INNER JOIN [Person].[Person] p ON c.[PersonID] = p.[BusinessEntityID]
INNER JOIN [Sales].[SalesOrderDetail] sod ON soh.[SalesOrderID] = sod.[SalesOrderID]
WHERE soh.[TerritoryId] = @TerritoryId
AND soh.[SalesOrderId] IN (
SELECT TOP 20 SalesOrderId
FROM [Sales].[SalesOrderHeader] soh
WHERE soh.[TerritoryId] = @TerritoryId
ORDER BY soh.[TotalDue] DESC)
ORDER BY soh.[TotalDue] DESC, sod.[SalesOrderDetailID]
然後,應用程式會使用 .NET Framework System.Xml.Linq API 將結果格式化為 XML。
// Create a new SqlCommand to run the Transact-SQL query
using (var command = new SqlCommand(...))
{
command.Parameters.AddWithValue("@TerritoryId", id);
// Run the query and create the initial XML document
using (var reader = await command.ExecuteReaderAsync())
{
var lastOrderNumber = string.Empty;
var doc = new XDocument();
var orders = new XElement("Orders");
doc.Add(orders);
XElement lineItems = null;
// Fetch each row in turn, format the results as XML, and add them to the XML document
while (await reader.ReadAsync())
{
var orderNumber = reader["OrderNumber"].ToString();
if (orderNumber != lastOrderNumber)
{
lastOrderNumber = orderNumber;
var order = new XElement("Order");
orders.Add(order);
var customer = new XElement("Customer");
lineItems = new XElement("OrderLineItems");
order.Add(customer, lineItems);
var orderDate = (DateTime)reader["OrderDate"];
var totalDue = (Decimal)reader["TotalDue"];
var reviewRequired = totalDue > 5000 ? 'Y' : 'N';
order.Add(
new XAttribute("OrderNumber", orderNumber),
new XAttribute("Status", reader["Status"]),
new XAttribute("ShipDate", reader["ShipDate"]),
... // More attributes, not shown.
var fullName = string.Join(" ",
reader["CustomerTitle"],
reader["CustomerFirstName"],
reader["CustomerMiddleName"],
reader["CustomerLastName"],
reader["CustomerSuffix"]
)
.Replace(" ", " ") //remove double spaces
.Trim()
.ToUpper();
customer.Add(
new XAttribute("AccountNumber", reader["AccountNumber"]),
new XAttribute("FullName", fullName));
}
var productId = (int)reader["ProductID"];
var quantity = (short)reader["Quantity"];
var inventoryCheckRequired = (productId >= 710 && productId <= 720 && quantity >= 5) ? 'Y' : 'N';
lineItems.Add(
new XElement("LineItem",
new XAttribute("Quantity", quantity),
new XAttribute("UnitPrice", ((Decimal)reader["UnitPrice"]).ToString("C")),
new XAttribute("LineTotal", RoundAndFormat(reader["LineTotal"])),
new XAttribute("ProductId", productId),
new XAttribute("InventoryCheckRequired", inventoryCheckRequired)
));
}
// Match the exact formatting of the XML returned from SQL
var xml = doc
.ToString(SaveOptions.DisableFormatting)
.Replace(" />", "/>");
}
}
注意
此程式碼有點複雜。 對於新的應用程式,您可能偏好使用序列化程式庫。 不過,這裡的假設是開發小組正在重構現有的應用程式,因此方法必須傳回與原始程式碼完全相同的格式。
考量
許多資料庫系統都經過高度優化,可執行特定類型的資料處理,例如計算大型資料集的匯總值。 請勿將這些類型的處理移出資料庫。
如果這樣做會導致資料庫透過網路傳輸更多資料,請勿重新放置處理。 請參閱外部擷 取反模式 。
如果您將處理移至應用層,該層可能需要相應放大以處理額外的工作。
如何偵測問題
忙碌資料庫的徵兆包括存取資料庫的作業中輸送量和回應時間不成比例的下降。
您可以執行下列步驟來協助識別此問題:
使用效能監視來識別生產系統執行資料庫活動所花費的時間。
檢查資料庫在這些期間所執行的工作。
如果您懷疑特定作業可能造成太多資料庫活動,請在受控制的環境中執行負載測試。 每個測試都應該使用可變使用者負載來執行可疑作業的混合。 檢查負載測試中的遙測,以觀察資料庫的使用方式。
如果資料庫活動顯示大量處理,但資料流量很少,請檢閱原始程式碼,以判斷處理是否可以更妥善地在其他地方執行。
如果資料庫活動量較低或回應時間相對較快,則忙碌的資料庫不太可能是效能問題。
診斷範例
下列各節會將這些步驟套用至稍早所述的範例應用程式。
監視資料庫活動的數量
下圖顯示針對範例應用程式執行負載測試的結果,其步驟負載最多為 50 位並行使用者。 要求數量迅速達到限制,並維持在該層級,而平均回應時間會穩步增加。 對數刻度用於這兩個計量。
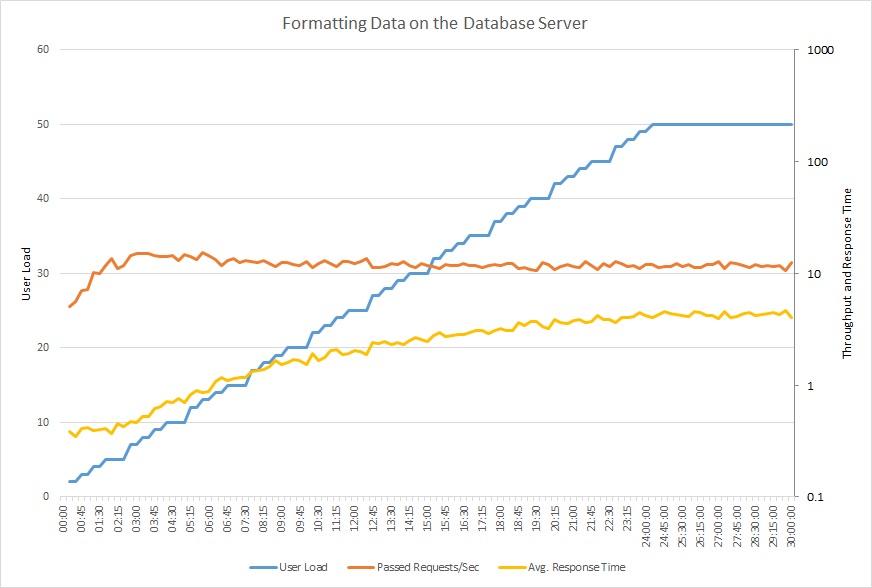
此折線圖顯示使用者負載、每秒要求數,以及平均回應時間。 圖表顯示回應時間隨著負載增加而增加。
下一個圖表會顯示 CPU 使用率和 DTU 作為服務配額的百分比。 DTU 會提供資料庫執行多少處理的量值。 圖表顯示 CPU 和 DTU 使用率都很快達到 100%。
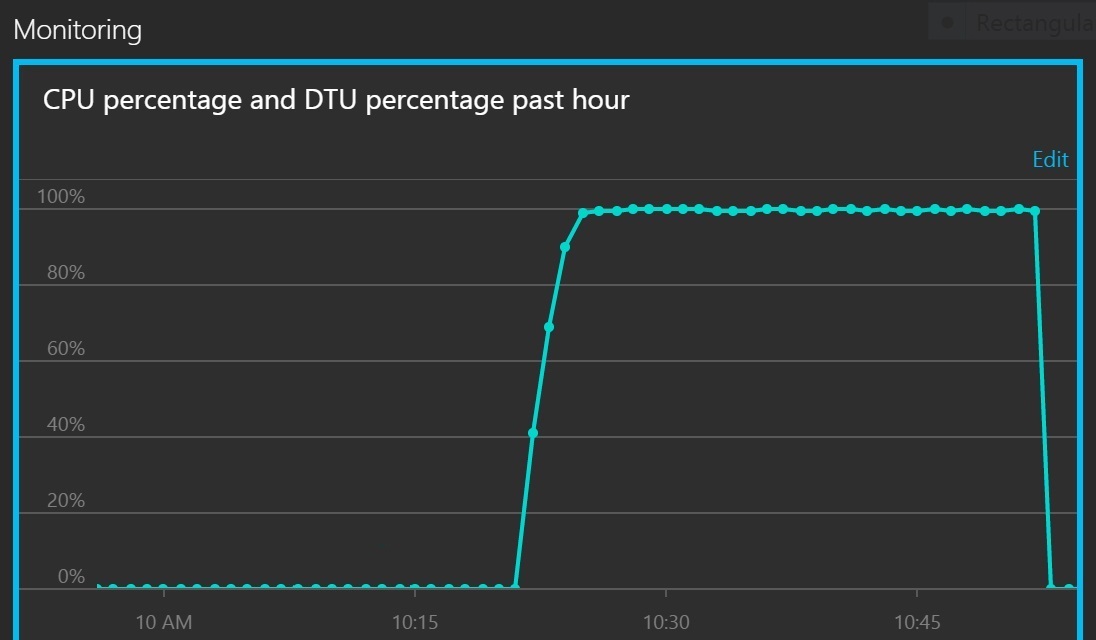
此折線圖會顯示一段時間的 CPU 百分比和 DTU 百分比。 圖表顯示兩者都快速達到 100%。
檢查資料庫所執行的工作
可能是資料庫所執行的工作是真正的資料存取作業,而不是處理,因此請務必瞭解資料庫忙碌時執行的 SQL 語句。 監視系統以擷取 SQL 流量,並將 SQL 作業與應用程式要求相互關聯。
如果資料庫作業純粹是資料存取作業,而不需要處理很多,則問題可能是 多餘的擷取 。
實作解決方案並驗證結果
下圖顯示使用更新的程式碼進行負載測試。 輸送量明顯較高,每秒超過 400 個要求,而不是先前的 12 個要求。 平均回應時間也比較低得多,相較于 4 秒以上,僅高於 0.1 秒。
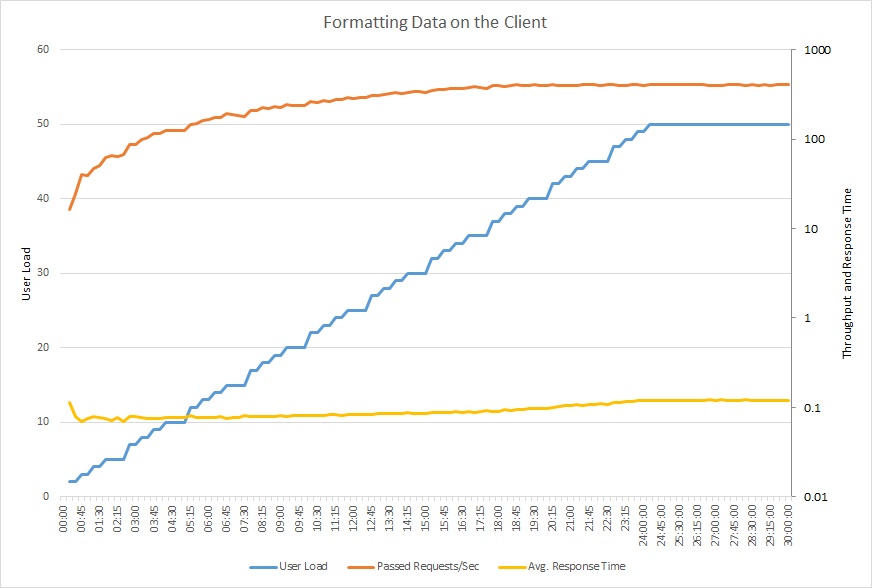
此折線圖顯示使用者負載、每秒要求數,以及平均回應時間。 此圖表顯示回應時間在整個負載測試中維持大致不變。
CPU 和 DTU 使用率顯示,儘管輸送量增加,系統仍花費較長的時間達到飽和度。
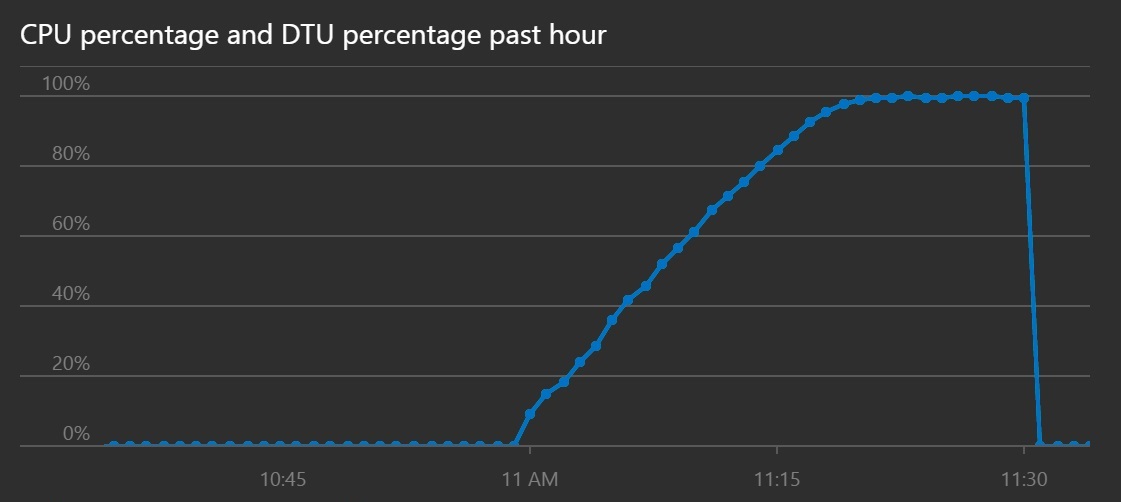
此折線圖會顯示一段時間的 CPU 百分比和 DTU 百分比。 此圖表顯示 CPU 和 DTU 需要比先前更長的時間達到 100%。
相關資源
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應