忙碌前端反模式
對大量背景執行緒執行非同步工作可能會耗盡資源的其他並行前景工作,降低無法接受層級的回應時間。
問題說明
資源密集型工作可以增加使用者要求的回應時間,並造成高延遲。 改善回應時間的其中一種方法是將資源密集型工作卸載至個別執行緒。 此方法可讓應用程式在處理發生在背景時保持回應。 不過,在背景執行緒上執行的工作仍會取用資源。 如果有太多,它們可能會耗盡正在處理要求的執行緒。
注意
資源一詞 可以包含許多專案,例如 CPU 使用率、記憶體佔用率,以及網路或磁片 I/O。
當應用程式開發為整合型程式碼時,通常會發生此問題,並將所有商務邏輯合併成與展示層共用的單一層。
以下是使用示範問題的 ASP.NET 範例。 您可以在這裡 找到完整的範例 。
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
Post控制器中的WorkInFrontEnd方法會實作 HTTP POST 作業。 此作業會模擬長時間執行的 CPU 密集型工作。 工作會在個別執行緒上執行,以嘗試讓 POST 作業快速完成。Get控制器中的UserProfile方法會實作 HTTP GET 作業。 此方法的 CPU 密集程度要少得多。
主要考慮是 方法的資源需求 Post 。 雖然工作會將工作放在背景執行緒上,但工作仍會耗用相當大量的 CPU 資源。 這些資源會與其他並行使用者執行的作業共用。 如果適量的使用者同時傳送此要求,整體效能可能會受到影響,讓所有作業變慢。 例如,使用者可能會在 方法中 Get 遇到顯著的延遲。
如何修正問題
將耗用大量資源的處理常式移至個別的後端。
使用這種方法,前端會將需要大量資源的工作放入訊息佇列。 後端會挑選工作以進行非同步處理。 佇列也會作為載入撫平器,緩衝後端的要求。 如果佇列長度變得太長,您可以設定自動調整以相應放大後端。
以下是先前程式碼的修訂版本。 在此版本中, Post 方法會將訊息放在服務匯流排佇列上。
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
後端會從服務匯流排佇列提取訊息,並執行處理。
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
考量
- 此方法會將一些額外的複雜度新增至應用程式。 您必須安全地處理佇列和清除佇列,以避免在發生失敗時遺失要求。
- 應用程式會相依于訊息佇列的其他服務。
- 處理環境必須能夠充分調整,才能處理預期的工作負載,並符合所需的輸送量目標。
- 雖然此方法應該改善整體回應性,但移至後端的工作可能需要較長的時間才能完成。
如何偵測問題
忙碌前端的徵兆包括執行資源密集型工作時的高延遲。 終端使用者可能會報表服務逾時所造成的延長回應時間或失敗。這些失敗也可能傳回 HTTP 500(內部伺服器)錯誤或 HTTP 503(服務無法使用)錯誤。 檢查網頁伺服器的事件記錄檔,這可能包含錯誤原因和情況的詳細資料。
您可以執行下列步驟來協助識別此問題:
- 執行生產系統的進程監視,以識別回應時間變慢的時間點。
- 檢查在這些點擷取的遙測資料,以判斷正在執行的作業混合和使用的資源。
- 尋找不良回應時間與當時所發生作業的磁片區與組合之間的任何相互關聯。
- 負載會測試每個可疑的作業,以識別哪些作業正在耗用資源,並耗盡其他作業。
- 請檢閱這些作業的原始程式碼,以判斷為何可能會導致過度的資源耗用量。
診斷範例
下列各節會將這些步驟套用至稍早所述的範例應用程式。
識別速度變慢點
檢測每個方法,以追蹤每個要求所耗用的持續時間和資源。 然後監視生產環境中的應用程式。 這可以提供要求彼此競爭方式的整體檢視。 在壓力期間,執行緩慢的資源需求要求可能會影響其他作業,而且監視系統並注意到效能下降可以觀察到此行為。
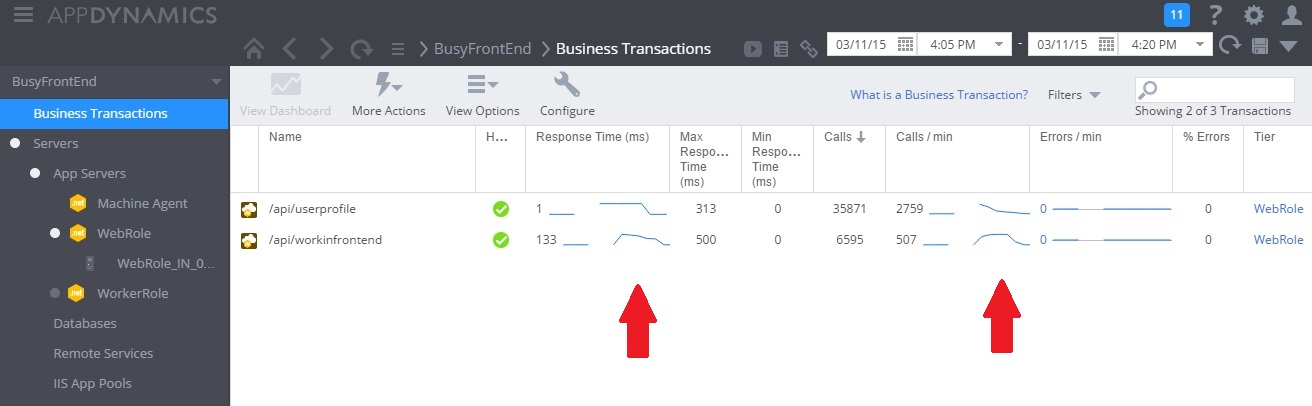
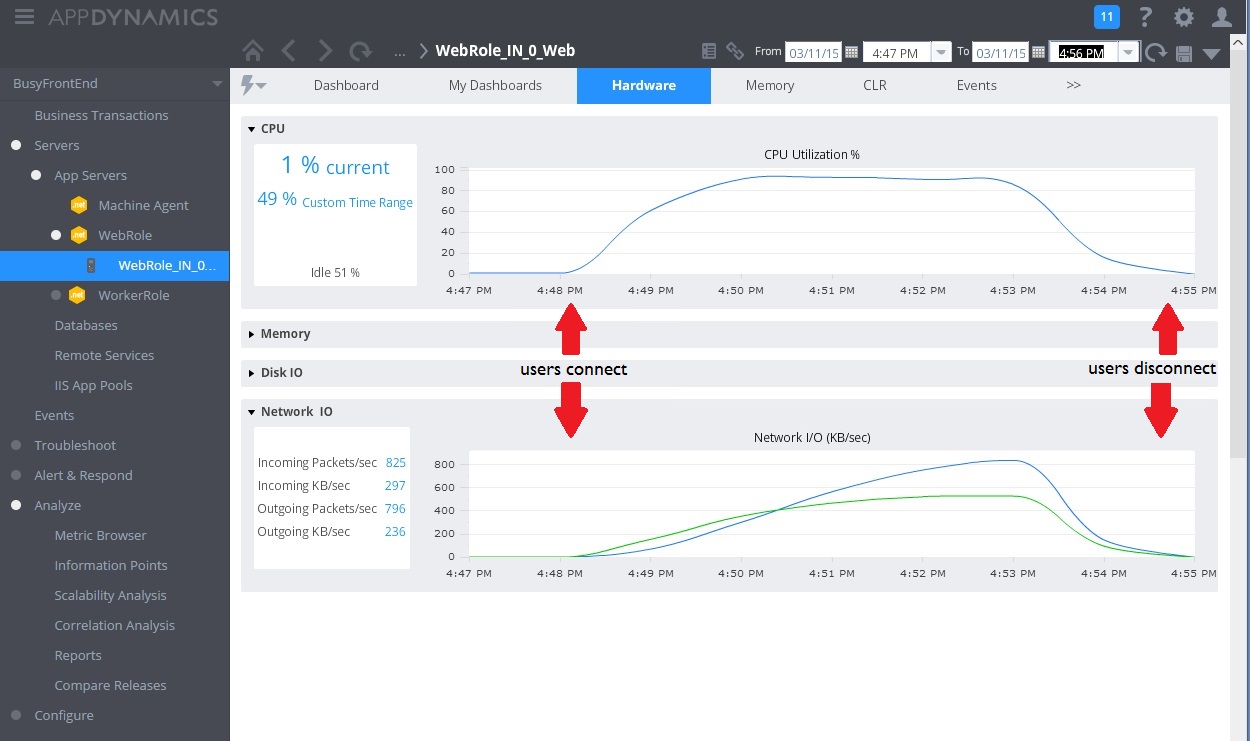
下圖顯示監視儀表板。 (我們使用了 測試的 AppDynamics 。一開始,系統具有輕量負載。 然後使用者開始要求 UserProfile GET 方法。 效能相當好,直到其他使用者開始向 POST 方法發出要求 WorkInFrontEnd 為止。 此時,回應時間會大幅增加(第一個箭號)。 只有在控制器的要求量減少(第二個箭號)之後, WorkInFrontEnd 回應時間才會改善。
檢查遙測資料並尋找相互關聯
下一個影像顯示一些收集來監視相同間隔內資源使用率的計量。 起初,很少有使用者正在存取系統。 隨著更多使用者連線,CPU 使用率會變得非常高(100%)。 另請注意,當 CPU 使用量增加時,網路 I/O 速率一開始會上升。 但一旦 CPU 使用量達到尖峰,網路 I/O 實際上就會關閉。 這是因為一旦 CPU 處於容量,系統就只能處理相對較少的要求。 當使用者中斷連線時,CPU 負載會關閉。
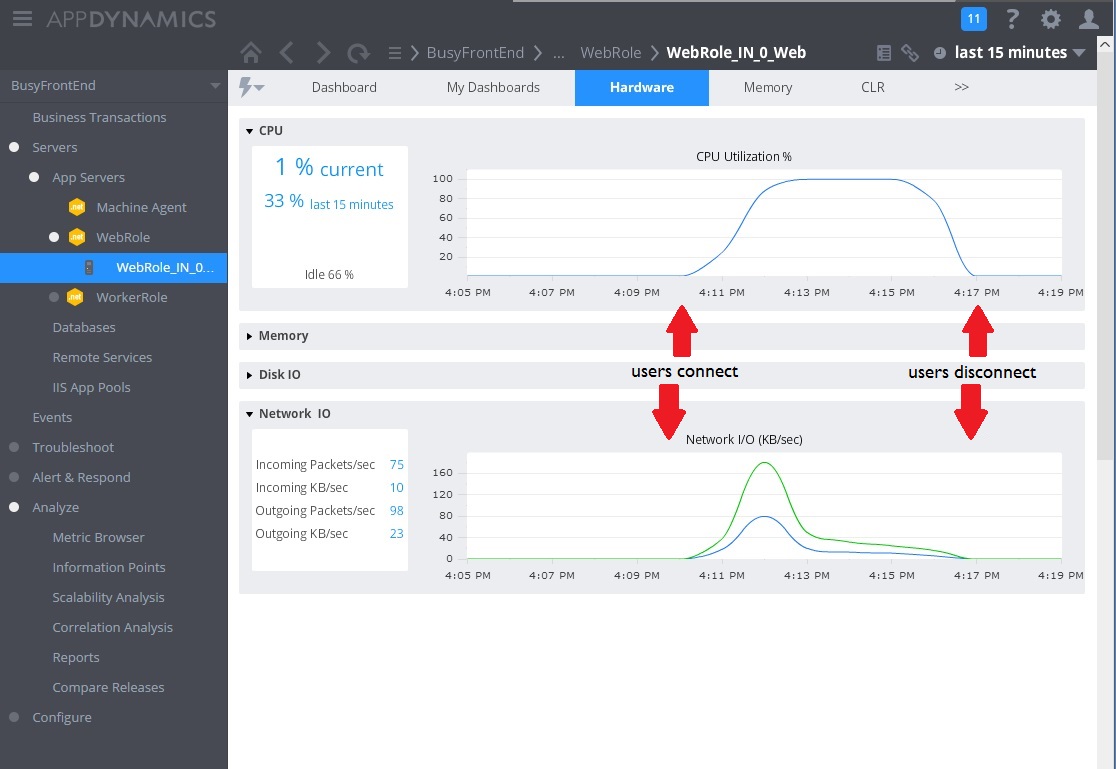
此時,控制器中 WorkInFrontEnd 的方法似乎是 Post 更仔細檢查的主要候選項目。 需要控制環境中的進一步工作,才能確認假設。
執行負載測試
下一個步驟是在受控制的環境中執行測試。 例如,執行一系列的負載測試,其中包含並接著省略每個要求以查看效果。
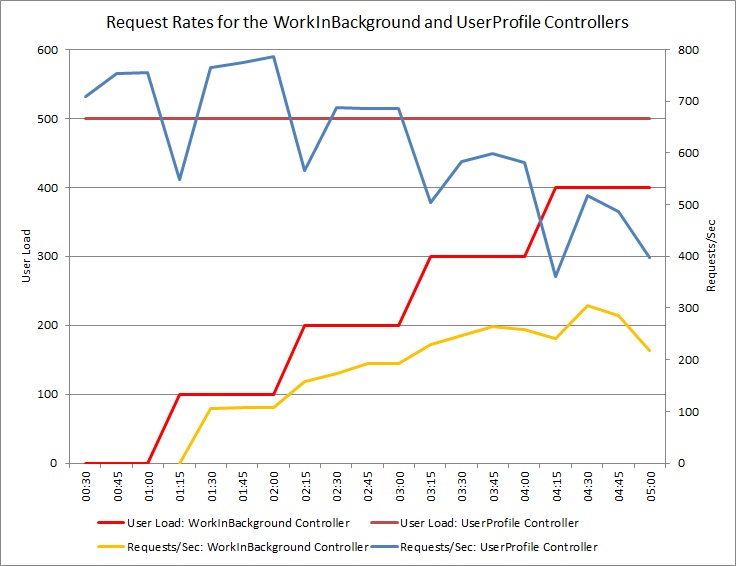
下圖顯示針對先前測試中使用的雲端服務相同部署所執行的負載測試結果。 測試使用 500 位在控制器中 UserProfile 執行 Get 作業的使用者常數負載,以及執行控制器中 WorkInFrontEnd 作業的使用者 Post 步驟負載。
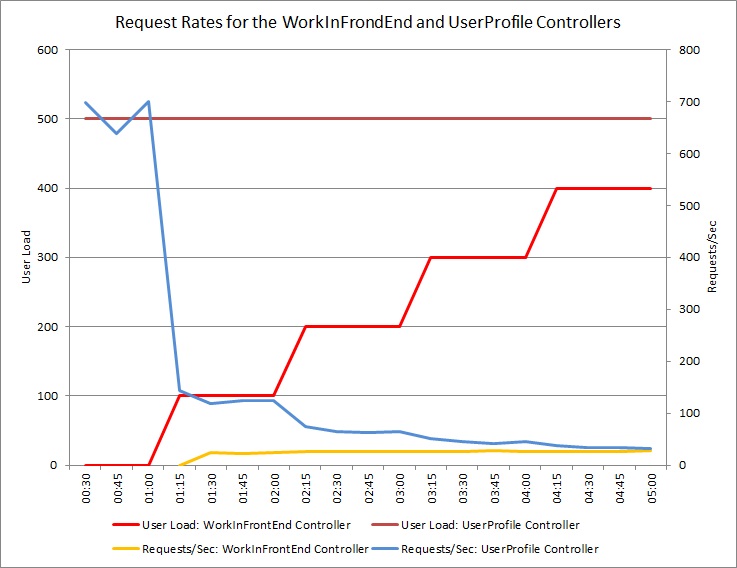
一開始,步驟載入為 0,因此唯一的作用中使用者會執行 UserProfile 要求。 系統每秒可以回應大約 500 個要求。 60 秒之後,100 個其他使用者的負載會開始將 POST 要求傳送至 WorkInFrontEnd 控制器。 幾乎立即,傳送至控制器的 UserProfile 工作負載每秒會捨棄約 150 個要求。 這是因為負載測試執行器的運作方式。 它會在傳送下一個要求之前等候回應,因此接收回應所需的時間越長,要求速率越低。
隨著更多使用者將 POST 要求傳送至 WorkInFrontEnd 控制器,控制器的 UserProfile 回應率會繼續下降。 但請注意,控制器所 WorkInFrontEnd 處理的要求數量維持相對不變。 系統飽和度變得很明顯,因為這兩個要求的整體速率傾向于穩定但低的限制。
檢閱原始程式碼
最後一個步驟是查看原始程式碼。 開發小組知道 Post 此方法可能需要相當長的時間,這就是為什麼原始實作使用不同的執行緒。 這解決了立即的問題,因為 Post 方法並未封鎖等候長時間執行的工作完成。
不過,此方法所執行的工作仍會耗用 CPU、記憶體和其他資源。 啟用此程式以非同步方式執行可能會實際損害效能,因為使用者可以以不受控制的方式同時觸發大量這些作業。 伺服器可執行檔執行緒數目有限制。 超過此限制之後,當應用程式嘗試啟動新執行緒時,可能會收到例外狀況。
注意
這並不表示您應該避免非同步作業。 建議在網路呼叫上執行非同步等候。 (請參閱 同步 I/O 反模式。)這裡的問題是,CPU 密集型工作在另一個執行緒上繁衍。
實作解決方案並驗證結果
下圖顯示實作解決方案之後的效能監視。 負載與稍早所示類似,但控制器的 UserProfile 回應時間現在要快得多。 要求數量會在同一持續時間內增加,從 2,759 增加到 23,565。
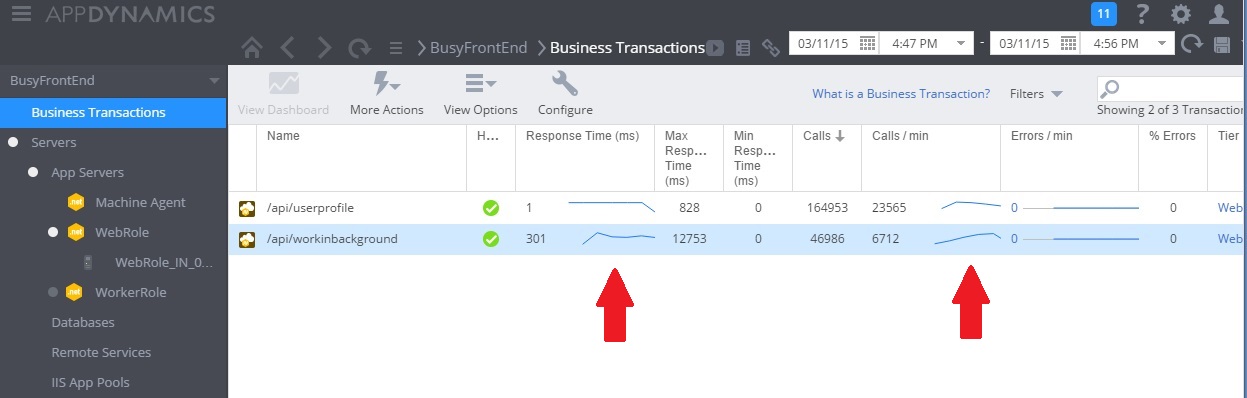
請注意, WorkInBackground 控制器也處理了更大的要求量。 不過,在此情況下,您無法進行直接比較,因為在此控制器中執行的工作與原始程式碼大不相同。 新版本只會將要求排入佇列,而不是執行耗時的計算。 重點是這個方法不再拖曳整個系統在負載下。
CPU 和網路使用率也會顯示改善的效能。 CPU 使用率永遠不會達到 100%,且已處理的網路要求數量遠高於先前,而且在工作負載卸載之前未結束。
下圖顯示負載測試的結果。 相較于先前的測試,服務的整體要求量會大幅改善。
相關指引
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應