巨量數據架構的設計訴求是處理對傳統資料庫系統而言太大或複雜數據的擷取、處理和分析。

巨量數據解決方案通常涉及下列一或多種工作負載類型:
- 待用巨量數據源的批處理。
- 即時處理移動中的巨量數據。
- 巨量數據的互動式探索。
- 預測性分析和機器學習。
大部分的巨量數據架構都包含下列部分或所有元件:
數據源:所有巨量數據解決方案都是以一或多個數據源開頭。 範例包含:
- 應用程式資料存放區,例如關係資料庫。
- 應用程式所產生的靜態檔案,例如 Web 伺服器記錄檔。
- 實時數據源,例如IoT裝置。
數據儲存:批處理作業的數據通常會儲存在分散式檔案存放區中,以各種格式保存大量大型檔案。 這種存放區通常稱為 Data Lake。 實作此記憶體的選項包括 azure Data Lake Store 或 Azure 儲存體 中的 Blob 容器。
批處理:因為數據集太大,所以巨量數據解決方案通常必須使用長時間執行的批次作業來處理數據檔,以篩選、匯總,否則準備數據以供分析。 這些作業通常涉及讀取來源檔案、處理來源檔案,以及將輸出寫入新檔案。 選項包括在 Azure Data Lake Analytics 中執行 U-SQL 作業、在 HDInsight Hadoop 叢集中使用 Hive、Pig 或自定義 Map/Reduce 作業,或在 HDInsight Spark 叢集中使用 Java、Scala 或 Python 程式。
即時訊息擷取:如果解決方案包含即時來源,架構必須包含擷取和儲存即時訊息的方法,以進行串流處理。 這可能是簡單的數據存放區,其中傳入訊息會放入資料夾進行處理。 不過,許多解決方案都需要訊息擷取存放區作為訊息的緩衝區,並支援向外延展處理、可靠傳遞和其他消息佇列語意。 選項包括 Azure 事件中樞、Azure IoT 中樞 和 Kafka。
串流處理:擷取即時訊息之後,解決方案必須藉由篩選、匯總,以及準備數據進行分析來處理它們。 然後,處理過的數據流數據會寫入輸出接收。 Azure 串流分析會根據在未系結數據流上運作的永久執行 SQL 查詢,提供受控串流處理服務。 您也可以使用 開放原始碼 Apache 串流技術,例如 HDInsight 叢集中的 Spark 串流。
分析數據存放區:許多巨量數據解決方案會準備數據以供分析,然後使用分析工具以結構化格式提供已處理的數據。 用來提供這些查詢的分析數據存放區可以是 Kimball 樣式的關係型數據倉儲,如大多數傳統商業智慧 (BI) 解決方案所示。 或者,數據可以透過低延遲的 NoSQL 技術來呈現,例如 HBase,或互動式 Hive 資料庫,以提供分散式數據存放區中數據檔的元數據抽象概念。 Azure Synapse Analytics 為大規模雲端式數據倉儲提供受控服務。 HDInsight 支援互動式 Hive、HBase 和 Spark SQL,其也可用來提供數據進行分析。
分析和報告:大部分巨量數據解決方案的目標是透過分析和報告來提供數據的見解。 為了讓用戶能夠分析數據,架構可能包含數據模型層,例如 Azure Analysis Services 中的多維度 OLAP Cube 或表格式數據模型。 它也可能支援自助 BI,使用 Microsoft Power BI 或 Microsoft Excel 中的模型化和視覺效果技術。 分析與報告也可以採用數據科學家或數據分析師的互動式數據探索形式。 在這些案例中,許多 Azure 服務都支援分析筆記本,例如 Jupyter,讓這些用戶能夠利用 Python 或 R 的現有技能。若要進行大規模的數據探索,您可以使用 Microsoft R Server 獨立或搭配 Spark。
協調流程:大部分巨量數據解決方案都包含重複的數據處理作業、封裝在工作流程中、轉換源數據、在多個來源和接收之間移動數據、將數據載入分析數據存放區,或將結果直接推送至報表或儀錶板。 若要將這些工作流程自動化,您可以使用 Azure Data Factory 或 Apache Oozie 和 Sqoop 等協調流程技術。
Azure 包含許多可用於巨量數據架構的服務。 它們大致分為兩個類別:
- 受控服務,包括 Azure Data Lake Store、Azure Data Lake Analytics、Azure Synapse Analytics、Azure 串流分析、Azure 事件中樞、Azure IoT 中樞 和 Azure Data Factory。
- 以 Apache Hadoop 平台為基礎的開放原始碼技術,包括 HDFS、HBase、Hive、Spark、Oozie、Sqoop 和 Kafka。 這些技術可在 Azure HDInsight 服務中使用。
這些選項並非互斥,許多解決方案會結合 開放原始碼 技術與 Azure 服務。
使用此架構的時機
當您需要下列專案時,請考慮此架構樣式:
- 儲存和處理磁碟區中的數據對於傳統資料庫而言太大。
- 轉換非結構化數據以進行分析和報告。
- 實時擷取、處理和分析未系結的數據串流,或低延遲。
- 使用 Azure 機器學習 或 Azure 認知服務。
福利
- 技術選擇。 您可以混合和比對 HDInsight 叢集中的 Azure 受控服務和 Apache 技術,以利用現有的技能或技術投資。
- 透過平行處理原則的效能。 巨量數據解決方案會利用平行處理原則,以達到大量數據的高效能解決方案。
- 彈性規模。 巨量數據架構中的所有元件都支援向外延展布建,讓您可以將解決方案調整為小型或大型工作負載,並只支付您使用的資源。
- 與現有解決方案的互操作性。 巨量數據架構的元件也用於IoT處理和企業BI解決方案,讓您跨數據工作負載建立整合式解決方案。
挑戰
- 複雜度。 巨量數據解決方案可能非常複雜,具有許多元件來處理來自多個數據源的數據擷取。 建置、測試及疑難解答巨量數據程式可能很困難。 此外,可能有多個系統必須用來優化效能的組態設定。
- 技能集。 許多巨量數據技術都高度特製化,並使用不是較一般應用程式架構的典型架構和語言。 另一方面,巨量數據技術正在發展以更既定語言為基礎的新 API。 例如,Azure Data Lake Analytics 中的 U-SQL 語言是以 Transact-SQL 和 C# 的組合為基礎。 同樣地,SQL 型 API 適用於 Hive、HBase 和 Spark。
- 技術成熟度。 巨量數據中使用的許多技術正在演進。 雖然 Hive 和 Pig 等核心 Hadoop 技術已穩定下來,但 Spark 等新興技術會在每個新版本中引入廣泛的變更和增強功能。 相較於其他 Azure 服務,Azure Data Lake Analytics 和 Azure Data Factory 等受控服務相對年輕,而且可能會隨著時間發展。
- 安全性。 巨量數據解決方案通常依賴將所有靜態數據儲存在集中式數據湖中。 保護此數據的存取可能具有挑戰性,特別是當多個應用程式和平台必須內嵌和取用數據時。
最佳作法
利用平行處理原則。 大部分的巨量數據處理技術會將工作負載分散到多個處理單位。 這需要建立靜態數據檔,並以可分割的格式儲存。 HDFS 等分散式文件系統可以優化讀取和寫入效能,而實際處理是由多個叢集節點平行執行,進而降低整體作業時間。
數據分割數據。 批處理通常會以週期性排程發生,例如每周或每月。 根據符合處理排程的時態期間,分割數據檔和數據結構,例如數據表。 這可簡化數據擷取和作業排程,並讓您更輕鬆地針對失敗進行疑難解答。 此外,Hive、U-SQL 或 SQL 查詢中使用的數據分割數據表可以大幅改善查詢效能。
套用讀取架構語意。 使用 Data Lake 可讓您結合多種格式檔案的記憶體,無論是結構化、半結構化還是非結構化。 使用 架構 讀取語意,它會在處理數據時將架構投影到數據上,而不是儲存數據時。 這會在解決方案中建置彈性,並防止數據驗證和類型檢查所造成的數據擷取期間發生瓶頸。
就地處理數據。 傳統的 BI 解決方案通常會使用擷取、轉換和載入 (ETL) 程式將資料移至數據倉儲。 使用較大的磁碟區數據,以及更多樣化的格式,巨量數據解決方案通常會使用 ETL 的變化,例如轉換、擷取和載入 (TEL)。 使用這種方法,數據會在分散式數據存放區內進行處理,並將它轉換成所需的結構,再將轉換的數據移至分析數據存放區。
平衡使用率和時間成本。 對於批處理作業,請務必考慮兩個因素:計算節點的每單位成本,以及使用這些節點完成作業的每分鐘成本。 例如,批次作業可能需要八個小時,且有四個叢集節點。 不過,作業可能只會在前兩個小時內使用這四個節點,之後只需要兩個節點。 在此情況下,在兩個節點上執行整個作業會增加作業總時間,但不會加倍,因此總成本會降低。 在某些商務案例中,較久的處理時間可能會比使用使用量過低的叢集資源成本更高。
分隔叢集資源。 部署 HDInsight 叢集時,您通常會為每種工作負載類型布建個別的叢集資源,以達到更好的效能。 例如,雖然 Spark 叢集包含 Hive,但如果您需要使用 Hive 和 Spark 執行廣泛的處理,您應該考慮部署個別的專用 Spark 和 Hadoop 叢集。 同樣地,如果您使用 HBase 和 Storm 進行低延遲串流處理和 Hive 進行批處理,請考慮針對 Storm、HBase 和 Hadoop 個別的叢集。
協調數據擷取。 在某些情況下,現有的商務應用程式可能會將數據檔直接寫入 Azure 記憶體 Blob 容器中,而 HDInsight 或 Azure Data Lake Analytics 可以使用這些檔案。 不過,您通常需要將內部部署或外部數據源的數據擷取協調到 Data Lake。 使用協調流程工作流程或管線,例如 Azure Data Factory 或 Oozie 所支援工作流程或管線,以可預測且集中管理的方式達成此目的。
提早清除敏感數據。 數據擷取工作流程應該在程式初期清除敏感數據,以避免將數據儲存在 Data Lake 中。
IoT 架構
物聯網 (IoT) 是巨量數據解決方案的特製化子集。 下圖顯示IoT的可能邏輯架構。 此圖表強調架構的事件串流元件。
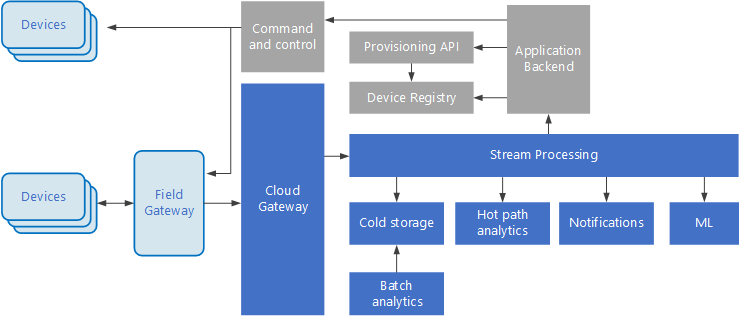
雲端閘道會使用可靠的低延遲傳訊系統,擷取雲端界限上的裝置事件。
裝置可能會直接將事件傳送至雲端閘道,或透過 現場閘道傳送。 現場閘道是特製化裝置或軟體,通常與裝置共置,可接收事件,並將其轉送至雲端網關。 現場閘道也可以預先處理原始裝置事件,並執行篩選、匯總或通訊協議轉換等功能。
擷取之後,事件會經過一或多個 串流處理器 ,以將數據路由傳送(例如,傳送至記憶體),或執行分析和其他處理。
以下是一些常見的處理類型。 (這份名單肯定不是詳盡的。
將事件數據寫入冷記憶體,以進行封存或批次分析。
經常性路徑分析、在 (近) 即時分析事件串流、偵測異常、在輪流時間範圍中辨識模式,或在串流中發生特定狀況時觸發警示。
處理來自裝置的特殊非遙測訊息類型,例如通知和警示。
機器學習。
陰影灰色的方塊會顯示與事件串流不直接相關的IoT系統元件,但此處包含完整性。
裝置 登錄 是已布建裝置的資料庫,包括裝置標識碼,通常是裝置元數據,例如位置。
布 建 API 是用來布建和註冊新裝置的通用外部介面。
某些IoT解決方案允許 將命令和控制訊息 傳送至裝置。
本節提出了IoT的高階檢視,而且需要考慮許多細微之處和挑戰。 如需更詳細的參考架構和討論,請參閱 Microsoft Azure IoT 參考架構 (PDF 下載)。
下一步
- 深入瞭解 巨量數據架構。
- 深入瞭解 物聯網 (IoT) 架構設計。