在查詢經常參考的數據存放區中建立索引。 此模式可藉由讓應用程式更快速地找出要從數據存放區擷取的數據,來改善查詢效能。
內容和問題
許多數據存放區會使用主鍵來組織實體集合的數據。 應用程式可以使用此金鑰來尋找和擷取數據。 此圖顯示保存客戶信息的數據存放區範例。 主鍵是客戶標識碼。 此圖顯示由主鍵 (客戶識別符) 組織的客戶資訊。
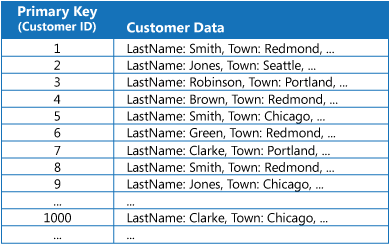
雖然主鍵對於根據此索引鍵值擷取數據的查詢而言很重要,但如果應用程式需要根據其他字段擷取數據,可能無法使用主鍵。 在客戶範例中,如果應用程式只藉由參考客戶所在城鎮的值來查詢數據,應用程式就無法使用客戶標識碼主鍵來擷取客戶。 若要執行這類查詢,應用程式可能必須擷取並檢查每個客戶記錄,這可能是一個緩慢的程式。
許多關係資料庫管理系統都支援次要索引。 次要索引是個別的數據結構,由一或多個非主要索引鍵字段組織,並指出每個索引值的數據儲存位置。 次要索引中的專案通常會依次要索引鍵的值排序,以便快速查閱數據。 這些索引通常會由資料庫管理系統自動維護。
您可以視需要建立多個次要索引,以支援應用程式執行的不同查詢。 例如,在客戶標識符為主鍵的關係資料庫中的 Customers 數據表中,如果應用程式經常依其所在城鎮查閱客戶,在城鎮字段上新增次要索引會很有説明。
不過,雖然次要索引在關係型系統中很常見,但雲端應用程式所使用的某些 NoSQL 資料存放區不提供對等的功能。
解決方案
如果數據存放區不支援次要索引,您可以藉由建立自己的索引數據表來手動模擬它們。 索引表會依指定的索引鍵來組織數據。 三種策略通常用於建構索引數據表,視所需的次要索引數目和應用程式執行的查詢本質而定。
第一個策略是複製每個索引表中的數據,但依不同的索引鍵加以組織(完整反正規化)。 下圖顯示依 Town 和 LastName 組織相同客戶資訊的索引數據表。
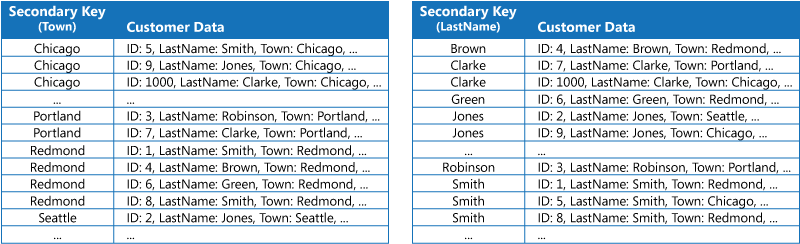
相較於使用每個索引鍵查詢的數據次數,此策略相當適當。 如果數據更動態,維護每個索引數據表的處理額外負荷會變得太大,因此此方法會變得太有用。 此外,如果數據量非常大,則儲存重複資料所需的空間量相當重要。
第二個策略是建立依不同索引鍵組織的正規化索引表,並使用主鍵來參考原始數據,而不是複製它,如下圖所示。 原始數據稱為事實數據表。
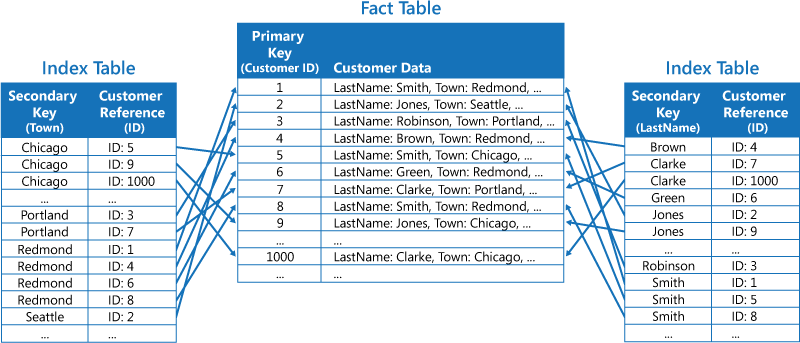
這項技術可節省空間,並減少維護重複數據的額外負荷。 缺點是應用程式必須執行兩個查閱作業,才能使用次要金鑰尋找數據。 它必須尋找索引表中數據的主鍵,然後使用主鍵來查閱事實數據表中的數據。
第三個策略是建立由重複經常擷取欄位的不同索引鍵所組織的部分正規化索引表。 參考事實數據表,以存取較不常存取的欄位。 下圖顯示每個索引數據表中經常存取的數據重複的方式。
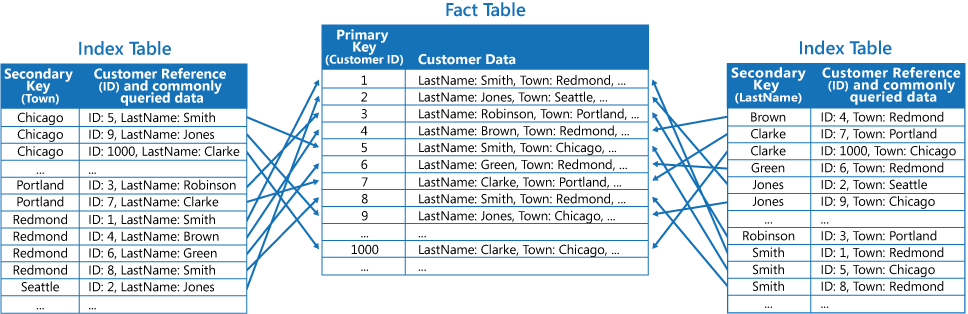
透過此策略,您可以在前兩種方法之間取得平衡。 一般查詢的數據可以使用單一查閱來快速擷取,而空間和維護額外負荷不如複製整個數據集那麼重要。
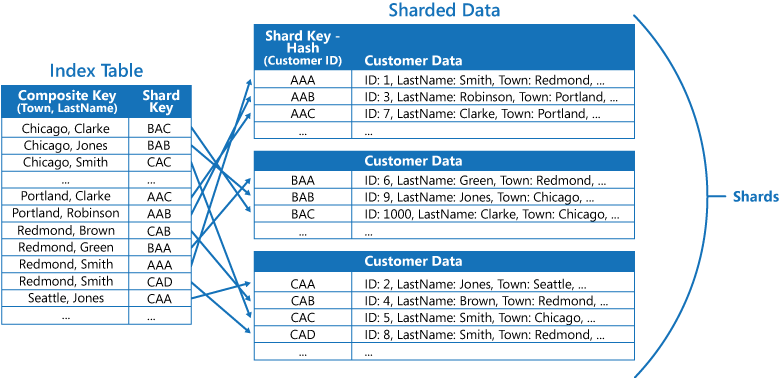
如果應用程式經常藉由指定值的組合來查詢資料(例如,「尋找位於 Redmond 且姓氏為 Smith 的所有客戶),您可以實作索引數據表中專案的索引鍵,做為 Town 屬性和 LastName 屬性的串連。 下圖顯示以複合索引鍵為基礎的索引表。 索引鍵會依 Town 排序,然後依 LastName 排序,記錄的 Town 值相同。

索引表可以加速分區化數據的查詢作業,而且在分區索引鍵哈希時特別有用。 下圖顯示分區索引鍵是客戶標識碼哈希的範例。 索引數據表可以依非哈希值 (Town 和 LastName) 來組織數據,並提供哈希分區索引鍵做為查閱數據。 如果應用程式需要擷取落在某個範圍內的數據,或需要依非哈希索引鍵的順序擷取數據,這可能會從重複計算哈希索引鍵來儲存應用程式。 例如,在索引數據表中尋找相符專案,即可快速解決「尋找所有位於 Redmond 中的客戶」等查詢,這些專案全都儲存在連續區塊中。 然後,使用儲存在索引數據表中的分區索引鍵,遵循客戶數據的參考。
問題和考慮
決定如何實作此模式時,請考慮下列幾點:
維護次要索引的額外負荷可能相當重要。 您必須分析並瞭解應用程式所使用的查詢。 只有在索引數據表可能經常使用時,才建立索引數據表。 請勿建立推測性索引數據表來支援應用程式未執行的查詢,或只偶爾執行。
複製索引數據表中的數據可能會增加記憶體成本的顯著負荷,以及維護多個數據複本所需的工作。
將索引數據表實作為參考原始數據的標準化結構,需要應用程式執行兩個查閱作業來尋找數據。 第一個作業會搜尋索引表以擷取主鍵,而第二個作業會使用主鍵來擷取數據。
如果系統在非常大的數據集上併入一些索引數據表,則很難維持索引數據表與原始數據之間的一致性。 在最終一致性模型周圍可能設計應用程式。 例如,若要插入、更新或刪除數據,應用程式可以將訊息張貼至佇列,並讓個別的工作執行作業,並維護以異步方式參考此數據的索引數據表。 如需實作最終一致性的詳細資訊,請參閱 數據一致性入門。
提示
Microsoft Azure 記憶體數據表支援交易式更新,以變更保留在相同數據分割中的數據(稱為實體群組交易)。 如果您可以將事實數據表和一或多個索引數據表的數據儲存在相同的分割區中,您可以使用這項功能來協助確保一致性。
索引數據表本身可能已分割或分區化。
使用此模式的時機
當應用程式經常需要使用主鍵(或分區)索引鍵以外的索引鍵來擷取數據時,請使用此模式來改善查詢效能。
當下列情況時,此模式可能不實用:
- 數據是揮發性的。 索引數據表可能會非常快速地過期,使其無效,或讓維護索引數據表的額外負荷大於使用索引數據表所節省的任何成本。
- 選取為索引表次要索引鍵的欄位不區分,而且只能有一組小的值(例如性別)。
- 選取為索引數據表之次要索引鍵之字段的數據值平衡高度扭曲。 例如,如果 90% 的記錄在欄位中包含相同的值,則建立和維護索引數據表以根據此欄位查閱資料可能會比循序掃描數據更額外負荷。 不過,如果查詢非常頻繁地以剩餘 10% 為目標的值,這個索引就很有用。 您應該瞭解應用程式正在執行的查詢,以及其執行頻率。
工作負載設計
架構設計人員應該評估索引表模式如何用於其工作負載的設計,以解決 Azure 架構架構要素中涵蓋的目標和原則。 例如:
| 要素 | 此模式如何支援支柱目標 |
|---|---|
| 可靠性設計決策可協助工作負載復原到故障,並確保它會在發生失敗后復原到完全正常運作的狀態。 | 由於客戶端會透過查閱程式指向其分區、分割區或端點,因此您可以使用此模式來加速資料存取的故障轉移方法。 - RE:06 數據分割 - RE:09 災害復原 |
| 效能效率 可透過調整、數據、程式代碼的優化,有效率地協助您的工作負載 符合需求 。 | 用戶端會指向其分區、數據分割或端點,以啟用動態數據分割以達到效能優化。 - PE:05 調整和分割 - PE:08 數據效能 |
如同任何設計決策,請考慮對其他可能以此模式導入之目標的任何取捨。
範例
Azure 記憶體資料表可為在雲端中執行的應用程式提供可高度調整的索引鍵/值數據存放區。 應用程式會藉由指定索引鍵來儲存和擷取數據值。 數據值可以包含多個字段,但數據項的結構對數據表記憶體來說並不透明,這隻會將數據項當做位元組陣列來處理。
Azure 記憶體數據表也支援分區化。 分區化索引鍵包含兩個元素:分割區索引鍵和數據列索引鍵。 具有相同分割區索引鍵的專案會儲存在相同的分割區(分區),而專案會以數據列索引鍵順序儲存在分區內。 數據表記憶體已針對執行查詢進行優化,以擷取數據落在數據分割內連續數據列索引鍵值範圍內的數據。 如果您要建置將資訊儲存在 Azure 資料表中的雲端應用程式,您應該考慮使用這項功能來建構您的數據。
例如,請考慮儲存電影相關信息的應用程式。 應用程式經常依流派(動作、紀錄片、歷史、喜劇、戲劇等)查詢電影。 您可以使用內容類型作為分割區索引鍵,並將電影名稱指定為數據列索引鍵,以為每個內容類型建立具有分割區的 Azure 數據表,如下圖所示。
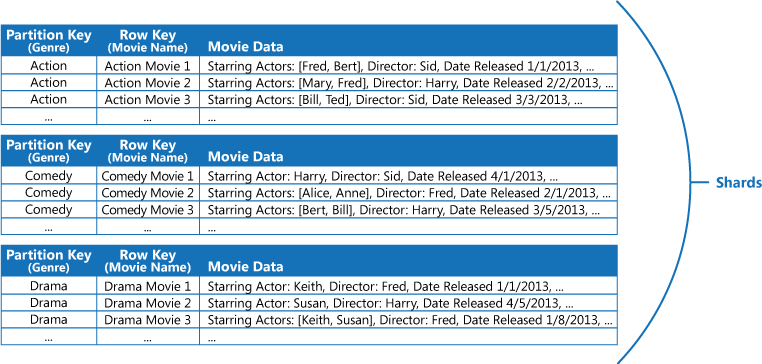
如果應用程式也需要藉由主演演員查詢電影,這個方法就不太有效。 在此情況下,您可以建立個別的 Azure 數據表,做為索引數據表。 分割區索引鍵是動作專案,而數據列索引鍵是電影名稱。 每個動作項目的數據都會儲存在個別的數據分割中。 如果電影主演多個演員,相同的電影將會在多個分割區中發生。
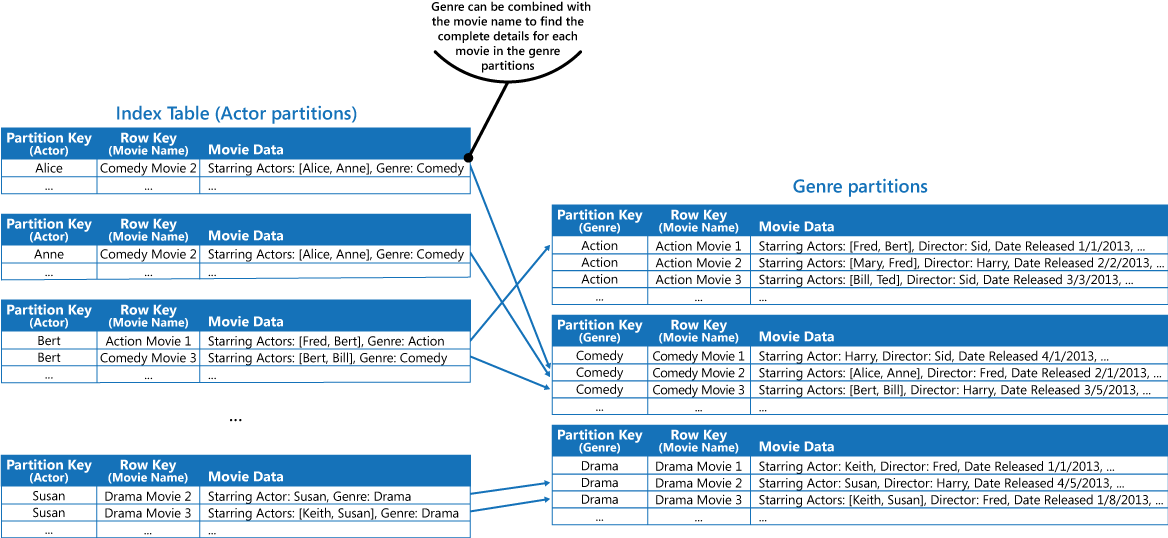
您可以採用上述解決方案一節中所述的第一種方法,複製每個分割區所持有的值中的電影數據。 不過,每個影片可能會復寫數次(每個動作專案一次),因此部分反正規化數據可能會更有效率,以支援最常見的查詢(例如其他動作專案的名稱),並讓應用程式藉由包含尋找內容類型分割區中完整資訊所需的分割區索引鍵來擷取任何剩餘的詳細數據。 這個方法是由解決方案一節中的第三個選項所描述。 下一個圖顯示此方法。
下一步
- 數據一致性入門。 索引數據表必須維持為索引變更的數據。 在雲端中,可能無法或適當地執行在修改數據之相同交易中更新索引的作業。 在此情況下,最終一致的方法更合適。 提供有關最終一致性問題的資訊。
相關資源
實作此模式時,下列模式也可能相關: