此參考架構會顯示 無伺服器事件驅動架構,可內嵌數據流、處理數據,並將結果寫入後端資料庫。
架構
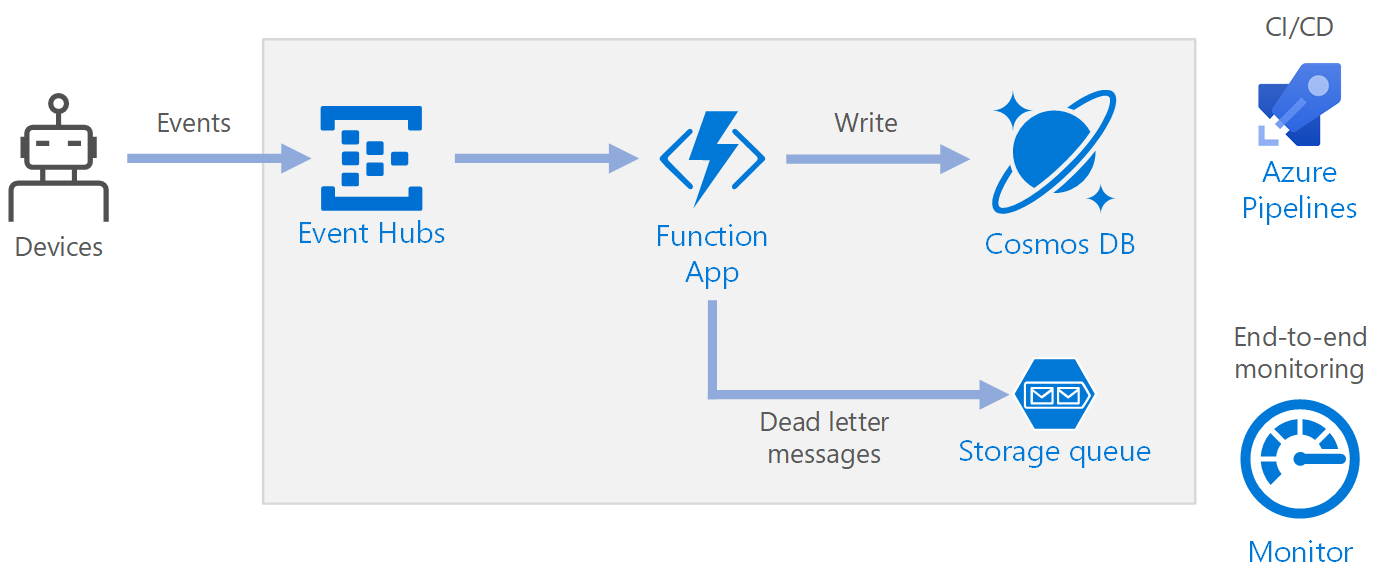
工作流程
- 事件抵達 Azure 事件中樞。
- 函式應用程式會觸發以處理事件。
- 事件會儲存在 Azure Cosmos DB 資料庫中。
- 如果函式應用程式無法成功儲存事件,事件會儲存至稍後要處理的 儲存體 佇列。
元件
事件中 樞內嵌數據流。 事件中 樞是專為高輸送量數據串流案例所設計。
注意
針對物聯網 (IoT) 案例,我們建議 Azure IoT 中樞。 IoT 中樞 具有與 Azure 事件中樞 API 兼容的內建端點,因此您可以在此架構中使用任一服務,而後端處理中沒有任何重大變更。 如需詳細資訊,請參閱將IoT裝置 連線至 Azure:IoT 中樞 和事件中樞。
函式應用程式。 Azure Functions 是無伺服器計算選項。 它會使用事件驅動模型,其中觸發程式會叫用一段程式代碼(函式)。 在此架構中,當事件抵達事件中樞時,他們會觸發處理事件的函式,並將結果寫入記憶體。
函式應用程式適用於處理事件中樞的個別記錄。 如需更複雜的串流處理案例,請考慮 使用 Azure Databricks 或 Azure 串流分析的 Apache Spark。
Azure Cosmos DB。 Azure Cosmos DB 是多模型資料庫服務,可在無伺服器耗用量模式中使用。 在此案例中,事件處理函式會使用 適用於 NoSQL 的 Azure Cosmos DB 來儲存 JSON 記錄。
佇列記憶體。 佇列記憶體 用於寄不出的信件訊息。 如果處理事件時發生錯誤,函式會將事件資料儲存在寄不出的信件佇列中,以供稍後處理。 如需詳細資訊,請參閱 本文稍後的復原一節 。
Azure 監視器。 監視 會收集解決方案中所部署 Azure 服務的效能計量。 藉由在儀錶板中可視化這些專案,您可以了解解決方案的健康情況。
考量
這些考量能實作 Azure Well-Architected Framework 的要素,其為一組指導原則,可以用來改善工作負載的品質。 如需詳細資訊,請參閱 Microsoft Azure Well-Architected Framework (部分機器翻譯)。
可用性
此處顯示的部署位於單一 Azure 區域中。 如需災害復原的更有彈性的方法,請利用各種服務中的異地散發功能:
- 事件中樞。 建立兩個事件中樞命名空間:主要 (主動) 命名空間和次要 (被動) 命名空間。 除非您故障轉移至次要命名空間,否則訊息會自動路由傳送至使用中命名空間。 如需詳細資訊,請參閱 Azure 事件中樞 異地災害復原。
- 函式應用程式。 部署正在等候從次要事件中樞命名空間讀取的第二個函式應用程式。 此函式會寫入寄不出的信件佇列的次要記憶體帳戶。
- Azure Cosmos DB。 Azure Cosmos DB 支援 多個寫入區域,可讓您寫入您新增至 Azure Cosmos DB 帳戶的任何區域。 如果您未啟用多寫入,您仍然可以故障轉移主要寫入區域。 Azure Cosmos DB 用戶端 SDK 和 Azure 函式系結會自動處理故障轉移,因此您不需要更新任何應用程式組態設定。
- Azure 儲存體。 針對寄不出的信件佇列使用 RA-GRS 記憶體 。 這會在另一個區域中建立唯讀複本。 如果主要區域變成無法使用,您可以讀取佇列中目前的專案。 此外,在次要區域中布建另一個記憶體帳戶,函式可以在故障轉移之後寫入該帳戶。
延展性
事件中樞
事件中樞的輸送量容量是以輸送量單位來測量。 您可以藉由啟用 自動擴充來自動調整事件中樞,以根據流量自動調整輸送量單位,最多可達到設定的最大值。
函 式應用程式中的事件中樞觸發 程式會根據事件中樞中的數據分割數目進行調整。 每個分割區會一次指派一個函式實例。 若要將輸送量最大化,請接收批次中的事件,而不是一次一個。
Azure Cosmos DB
Azure Cosmos DB 有兩種不同的容量模式可供使用:
若要確保您的工作負載可調整,請務必在建立 Azure Cosmos DB 容器時選擇適當的 分割區索引鍵 。 以下是良好數據分割索引鍵的一些特性:
- 索引鍵值空間很大。
- 每個索引鍵值都會有平均讀取/寫入的分佈,以避免作用中的索引鍵。
- 針對任何單一索引鍵值所儲存的數據上限不會超過實體分割區大小上限(20 GB)。
- 檔的數據分割索引鍵不會變更。 您無法更新現有檔案上的分割區索引鍵。
在此參考架構的案例中,函式會為每個傳送數據的裝置只儲存一份檔。 函式會使用 upsert 作業,以最新的裝置狀態持續更新檔。 裝置標識碼是此案例的良好分割區索引鍵,因為寫入會平均分散到索引鍵,而且每個分割區的大小將會嚴格系結,因為每個索引鍵值都有單一檔。 如需分割區索引鍵的詳細資訊,請參閱 Azure Cosmos DB 中的數據分割和調整。
復原
搭配函式使用事件中樞觸發程式時,請攔截處理迴圈內的例外狀況。 如果發生未處理的例外狀況,Functions 運行時間不會重試訊息。 如果無法處理訊息,請將訊息放入寄不出的信件佇列中。 使用頻外程式來檢查訊息並判斷更正動作。
下列程式代碼示範擷取函式如何攔截例外狀況,並將未處理的訊息放入寄不出的信件佇列中。
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
顯示的程式代碼也會將例外狀況記錄到 Application Insights。 您可以使用分割區索引鍵和序號,將寄不出的信件訊息與記錄中的例外狀況相互關聯。
寄不出的信件佇列中的訊息應該有足夠的資訊,以便您瞭解錯誤的內容。 在此範例中,類別 DeadLetterMessage 包含例外狀況訊息、原始事件本文數據,以及還原串行化事件訊息(如果有的話)。
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
使用 Azure 監視器 來監視事件中樞。 如果您看到有輸入,但沒有輸出,表示訊息不會進行處理。 在此情況下,請移至 Log Analytics 並尋找例外狀況或其他錯誤。
DevOps
盡可能使用基礎結構即程序代碼 (IaC)。 IaC 會使用 Azure Resource Manager 之類的宣告式方法來管理基礎結構、應用程式和記憶體資源。 這有助於使用 DevOps 作為持續整合和持續傳遞 (CI/CD) 解決方案來自動化部署。 範本應進行版本設定,並包含在發行管線中。
建立範本時,將資源分組為組織並隔離每個工作負載的方式。 考慮工作負載的常見方式是單一無伺服器應用程式或虛擬網路。 工作負載隔離的目標是將資源與小組產生關聯,讓 DevOps 小組可以獨立管理這些資源的所有層面,並執行 CI/CD。
當您部署服務時,您必須監視它們。 請考慮使用 Application Insights 來讓開發人員監視效能並偵測問題。
如需詳細資訊,請參閱 DevOps檢查清單。
災害復原
此處顯示的部署位於單一 Azure 區域中。 如需災害復原的更有彈性的方法,請利用各種服務中的異地散發功能:
事件中樞。 建立兩個事件中樞命名空間:主要 (主動) 命名空間和次要 (被動) 命名空間。 除非您故障轉移至次要命名空間,否則訊息會自動路由傳送至使用中命名空間。 如需詳細資訊,請參閱 Azure 事件中樞 異地災害復原。
函式應用程式。 部署正在等候從次要事件中樞命名空間讀取的第二個函式應用程式。 此函式會將寄不出的信件佇列寫入次要記憶體帳戶。
Azure Cosmos DB。 Azure Cosmos DB 支援 多個寫入區域,可讓您寫入您新增至 Azure Cosmos DB 帳戶的任何區域。 如果您未啟用多寫入,您仍然可以故障轉移主要寫入區域。 Azure Cosmos DB 用戶端 SDK 和 Azure 函式系結會自動處理故障轉移,因此您不需要更新任何應用程式組態設定。
Azure 儲存體。 針對寄不出的信件佇列使用 RA-GRS 記憶體。 這會在另一個區域中建立唯讀複本。 如果主要區域變成無法使用,您可以讀取佇列中目前的專案。 此外,在次要區域中布建另一個記憶體帳戶,函式可以在故障轉移之後寫入該帳戶。
成本最佳化
成本最佳化是關於考慮如何減少不必要的費用,並提升營運效率。 如需詳細資訊,請參閱成本最佳化要素的概觀。
使用 Azure 定價計算機來預估成本。 以下是 Azure Functions 和 Azure Cosmos DB 的其他一些考慮。
Azure Functions
Azure Functions 支持兩個裝載模型:
- 使用情況方案。 計算能力會在程式代碼執行時自動配置。
- Service 方案的資源。 系統會為您的程式代碼配置一組虛擬機 (VM)。 App Service 方案會定義 VM 數目和 VM 大小。
在此架構中,抵達事件中樞的每個事件都會觸發處理該事件的函式。 從成本的觀點來看,建議使用 耗用量方案 ,因為您只需支付您使用的計算資源費用。
Azure Cosmos DB
使用 Azure Cosmos DB 時,您需支付對資料庫執行的作業以及資料耗用的儲存體所產生的費用。
- 資料庫作業。 您支付資料庫作業費用的方式取決於您所使用的 Azure Cosmos DB 帳戶類型。
- Storage. 系統會針對您的數據和索引所耗用的總記憶體數量(以 GB 為單位)收取一般費率。
在此參考架構中,函式會為每個傳送數據的裝置儲存一份檔。 函式會使用 upsert 作業,以最新的裝置狀態持續更新檔,這在已取用的記憶體方面具有成本效益。 如需詳細資訊,請參閱 Azure Cosmos DB 定價模型。
使用 Azure Cosmos DB 容量計算機來快速估計工作負載成本。
部署此案例
 GitHub 上提供此架構的參考實作。
GitHub 上提供此架構的參考實作。