教學課程:使用 Azure Cosmos DB 端點實作 Azure Databricks
本教學課程說明如何實作 VNet 插入的 Databricks 環境,並啟用 Azure Cosmos DB 的服務端點。
在本教學課程中,您將瞭解如何:
- 在虛擬網路中建立 Azure Databricks 工作區
- 建立 Azure Cosmos DB 服務端點
- 建立 Azure Cosmos DB 帳戶並匯入資料
- 建立 Azure Databricks 叢集
- 從 Azure Databricks 筆記本查詢 Azure Cosmos DB
Prerequisites
開始之前,請執行下列動作:
下載 Spark 連接器。
從 NOAA 國家環境資訊中心下載範例資料。 選取狀態或區域,然後選取 [搜尋]。 在下一個頁面上,接受預設值,然後選取 [ 搜尋]。 然後選取頁面左側的 [CSV 下載 ] 以下載結果。
下載 Azure Cosmos DB 資料移轉工具預先 編譯的二進位 檔。
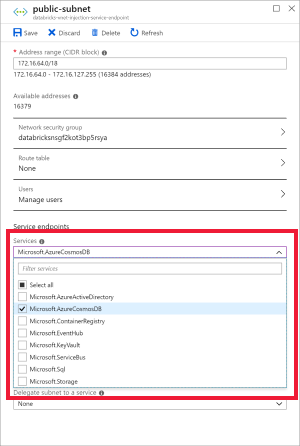
建立 Azure Cosmos DB 服務端點
將 Azure Databricks 工作區部署至虛擬網路之後,請流覽至Azure 入口網站中的虛擬網路。 請注意透過 Databricks 部署建立的公用和私人子網。
選取 公用子網 並建立 Azure Cosmos DB 服務端點。 然後 儲存。
建立 Azure Cosmos DB 帳戶
開啟Azure 入口網站。 在畫面左上角,選取 [建立資源 > 資料庫 > Azure Cosmos DB]。
使用下列設定,填寫 [基本] 索引標籤上的[實例詳細資料]:
設置 價值 訂閱 您的訂用帳戶 資源群組 您的資源群組 帳戶名稱 db-vnet-service-endpoint Api Core (SQL) 位置 美國西部 Geo-Redundancy 禁用 多區域寫入 使 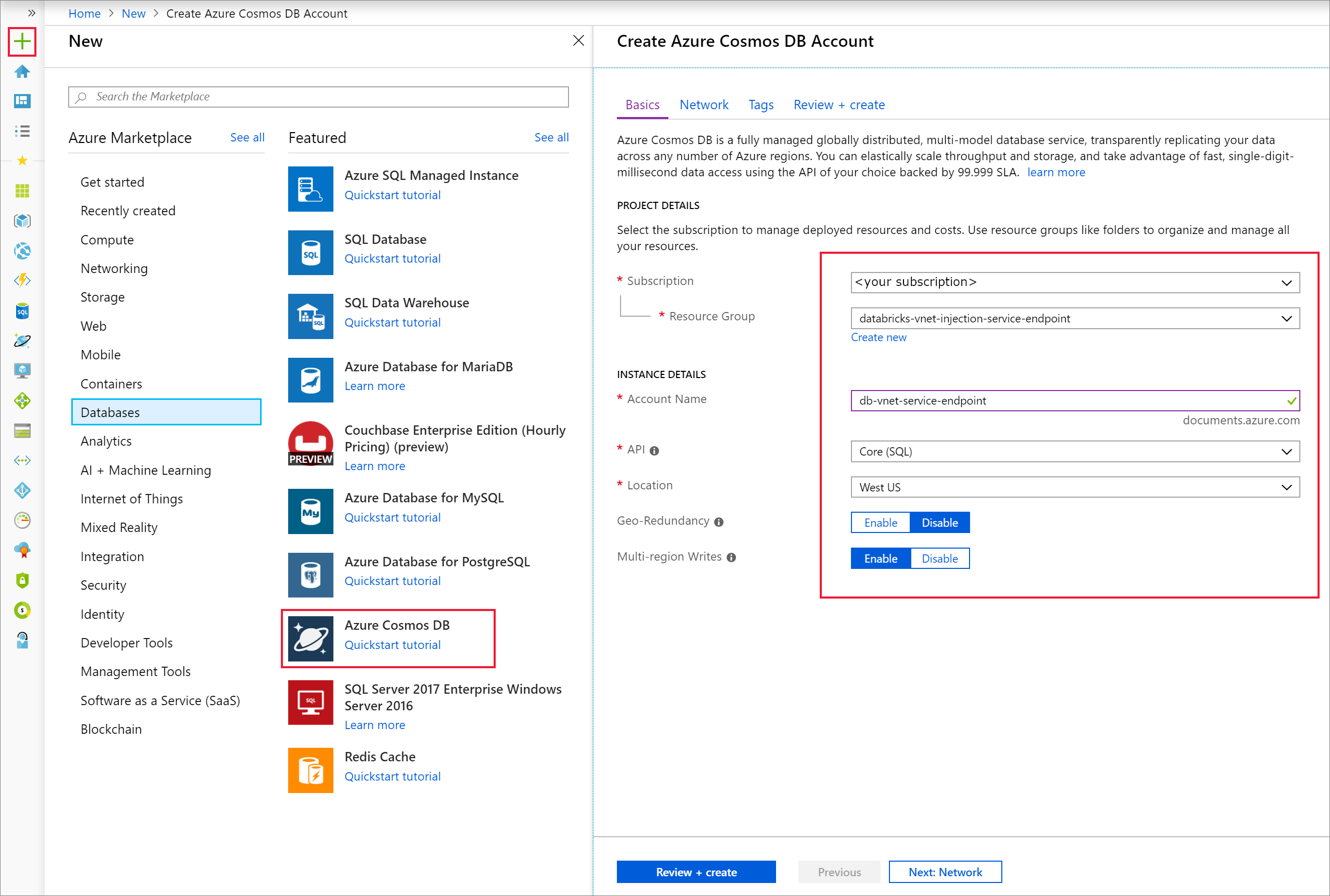
選取 [ 網路] 索引標籤並設定您的虛擬網路。
a. 選擇您建立為必要條件的虛擬網路,然後選取 [公用子網]。 請注意, 私人子網 有「 Microsoft AzureCosmosDB」端點遺失」的附注。 這是因為您只啟用 公用子網上的 Azure Cosmos DB 服務端點。
B。 請確定您已啟用[允許從Azure 入口網站存取]。 此設定可讓您從Azure 入口網站存取 Azure Cosmos DB 帳戶。 如果此選項設定為 [拒絕],當您嘗試存取您的帳戶時,您會收到錯誤。
注意
本教學課程不需要,但如果您想要從本機電腦存取 Azure Cosmos DB 帳戶的能力,您也可以啟用 [允許從我的 IP 存取]。 例如,如果您要使用 Azure Cosmos DB SDK 連線到您的帳戶,則需要啟用此設定。 如果停用,您會收到「拒絕存取」錯誤。
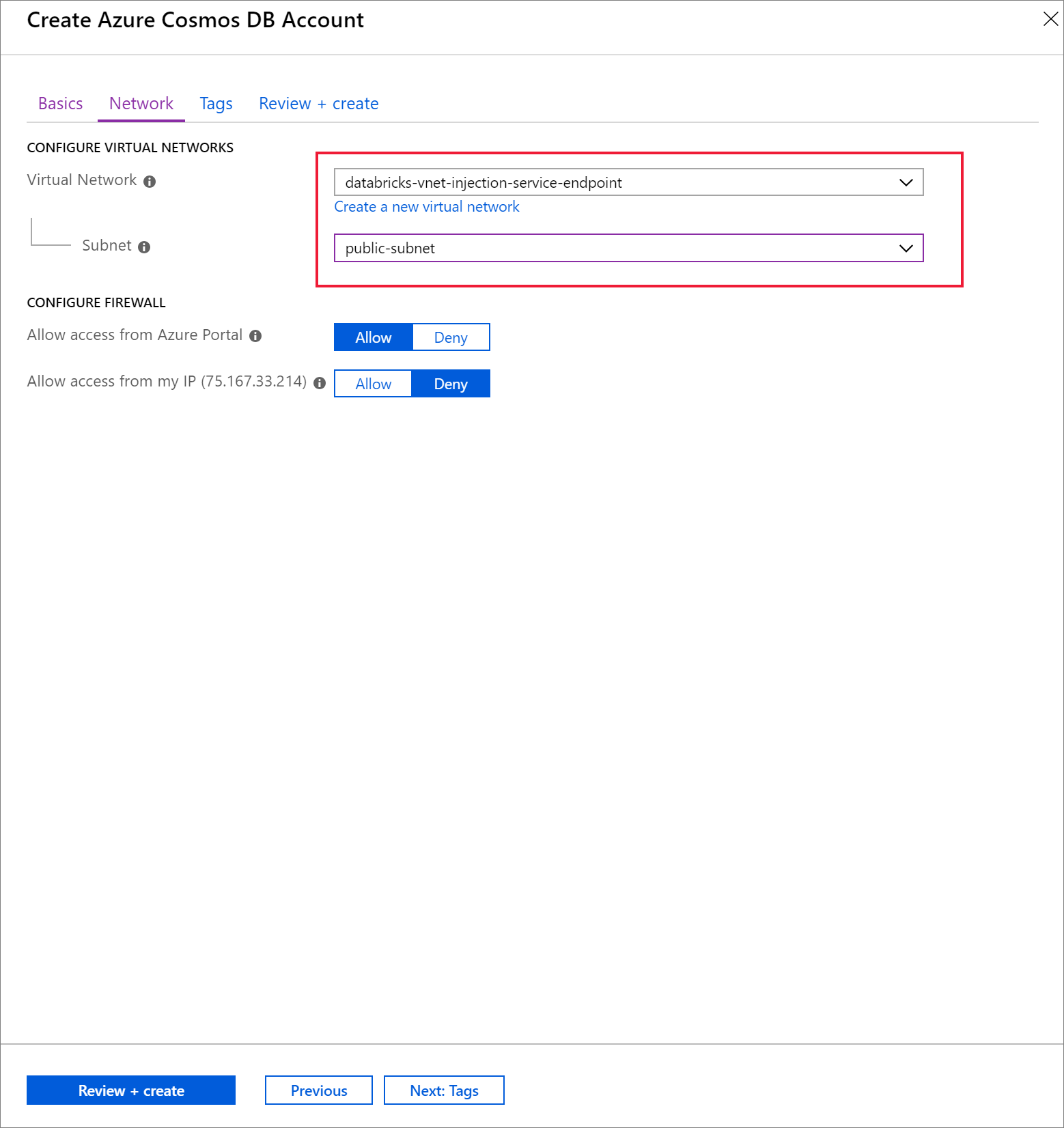
選取 [檢閱 + 建立],然後選取 [ 建立 ] 以在虛擬網路內建立您的 Azure Cosmos DB 帳戶。
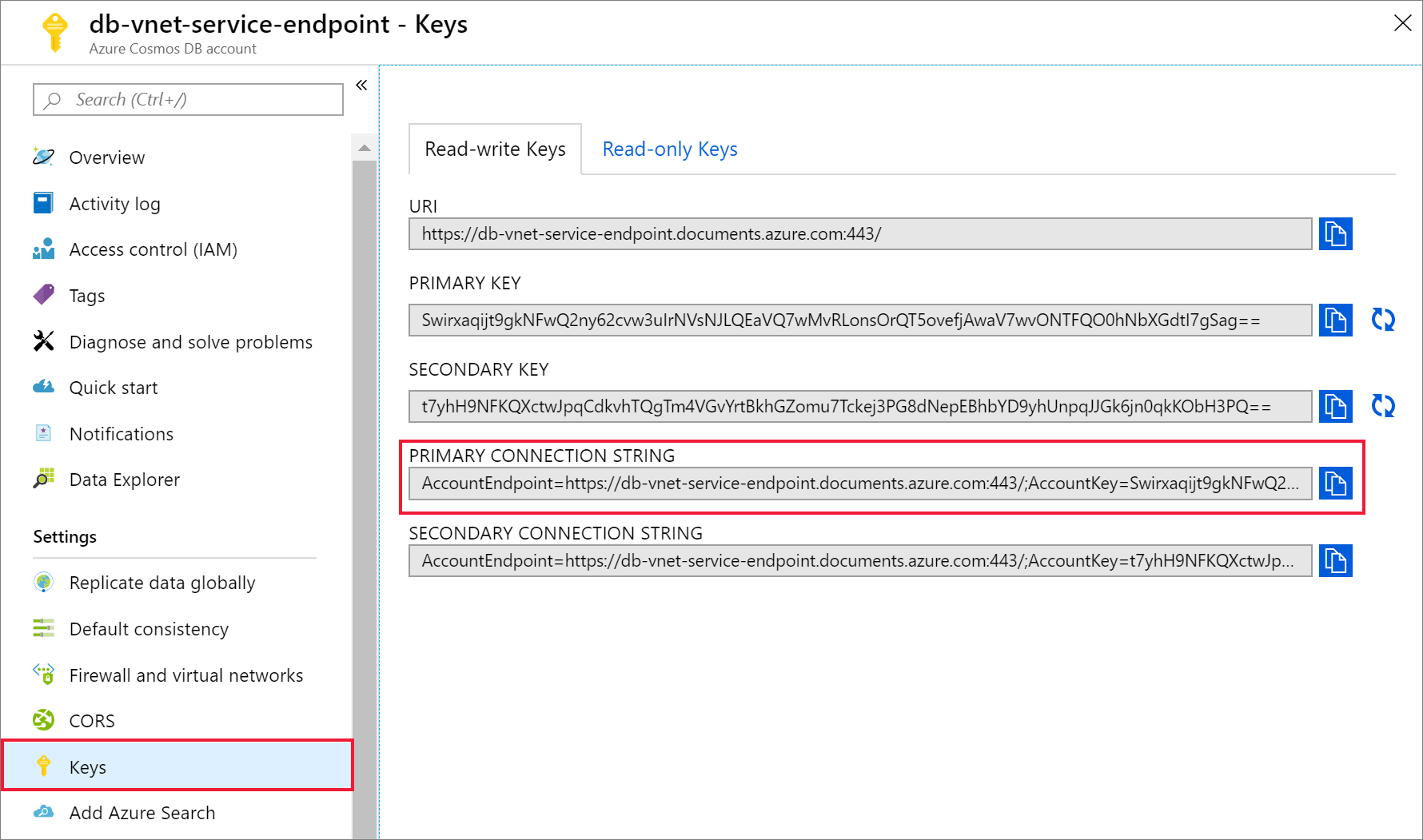
建立 Azure Cosmos DB 帳戶之後,請流覽至 [設定] 底下的[金鑰]。 複製主要連接字串,並將其儲存在文字編輯器中以供稍後使用。
選取[Data Explorer] 和 [新增容器],將新的資料庫和容器新增至您的 Azure Cosmos DB 帳戶。
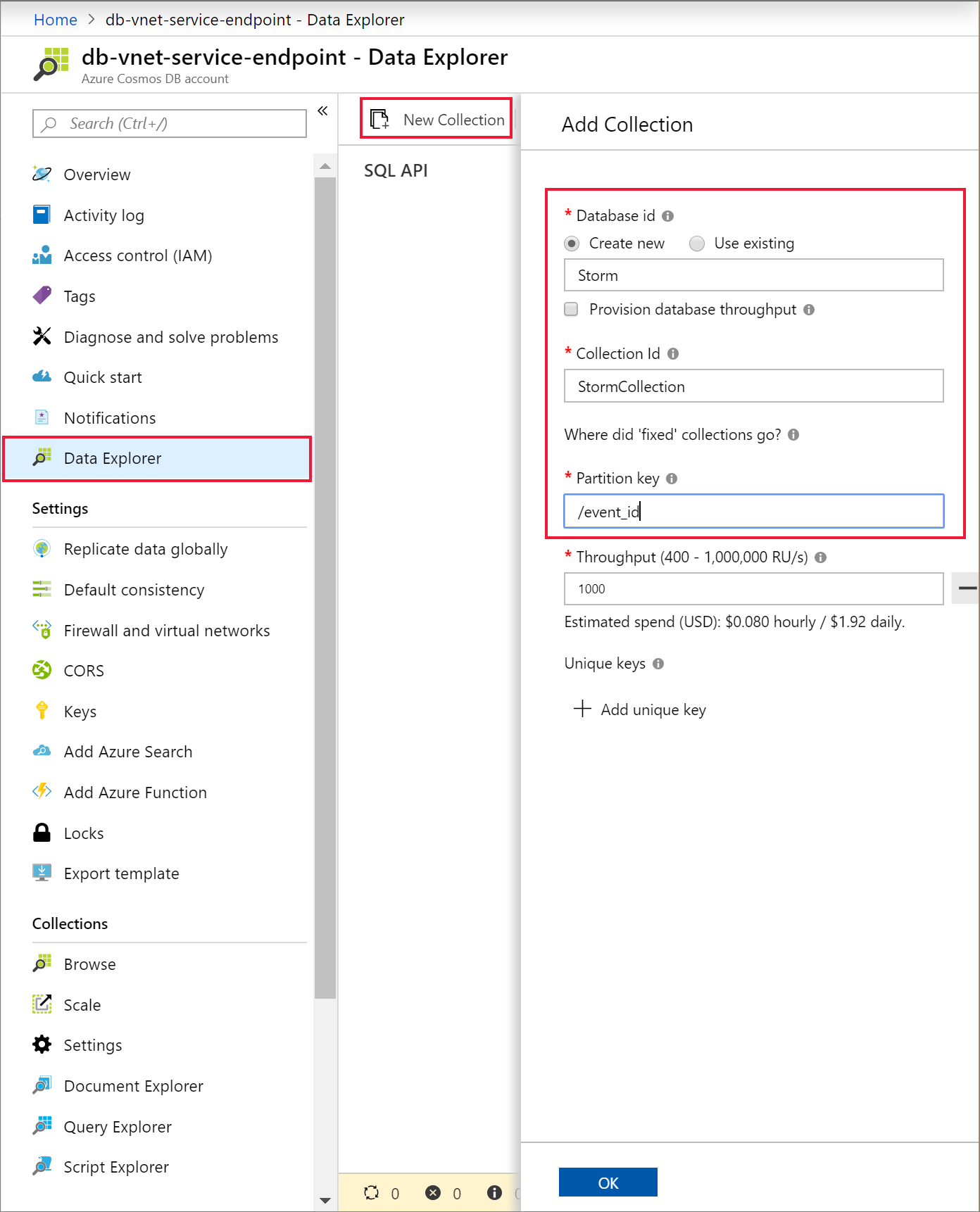
將資料上傳至 Azure Cosmos DB
開啟 Azure Cosmos DB 資料移轉工具的圖形化介面版本, Dtui.exe。

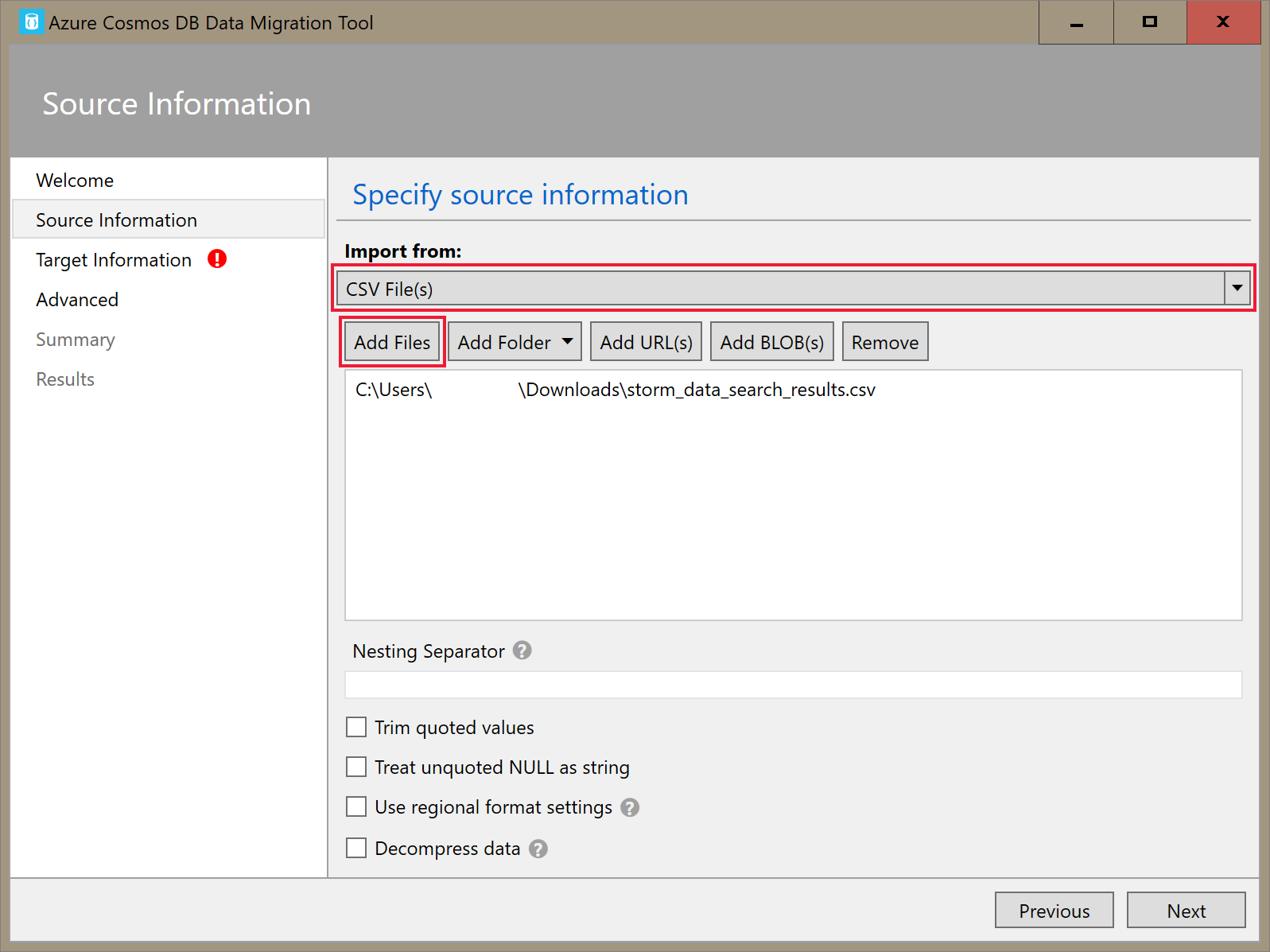
在 [來源資訊] 索引標籤上,在 [從匯入] 下拉式清單中選取[CSV 檔案] (s) 。 然後選取 [新增檔案 ],然後新增您下載的 Storm 資料 CSV 作為必要條件。
在 [ 目標資訊] 索引 標籤上,輸入您的連接字串。 連接字串格式為
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>。 AccountEndpoint 和 AccountKey 會包含在您在上一節中儲存的主要連接字串中。 附加Database=<your database name>至連接字串結尾,然後選取 [ 驗證]。 然後,新增容器名稱和分割區索引鍵。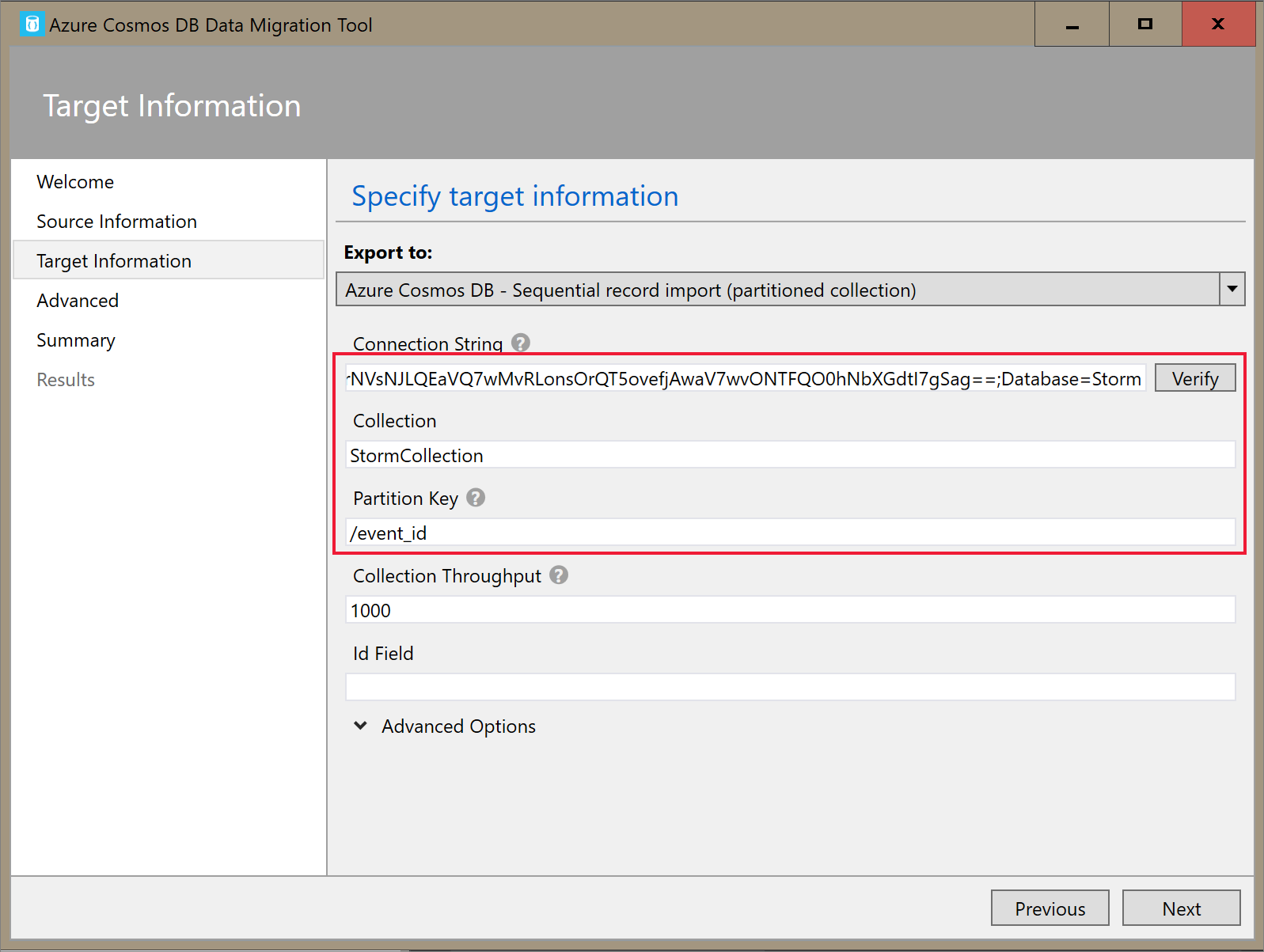
選取 [下一步 ],直到您進入 [摘要] 頁面為止。 然後,選取 [ 匯入]。
建立叢集並新增程式庫
流覽至Azure 入口網站中的 Azure Databricks 服務,然後選取 [啟動工作區]。
建立新的叢集。 選擇 [叢集名稱],並接受其餘的預設設定。
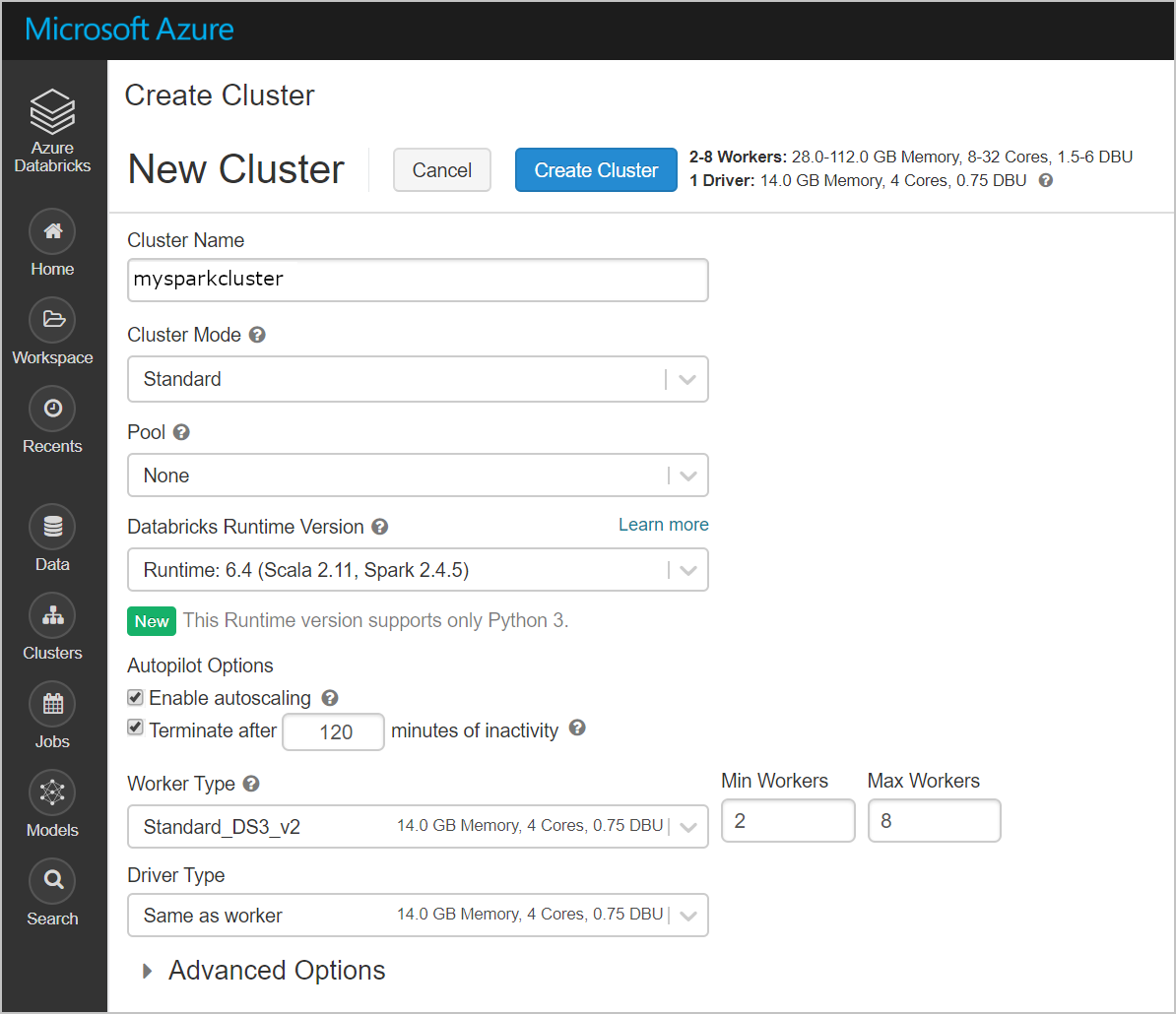
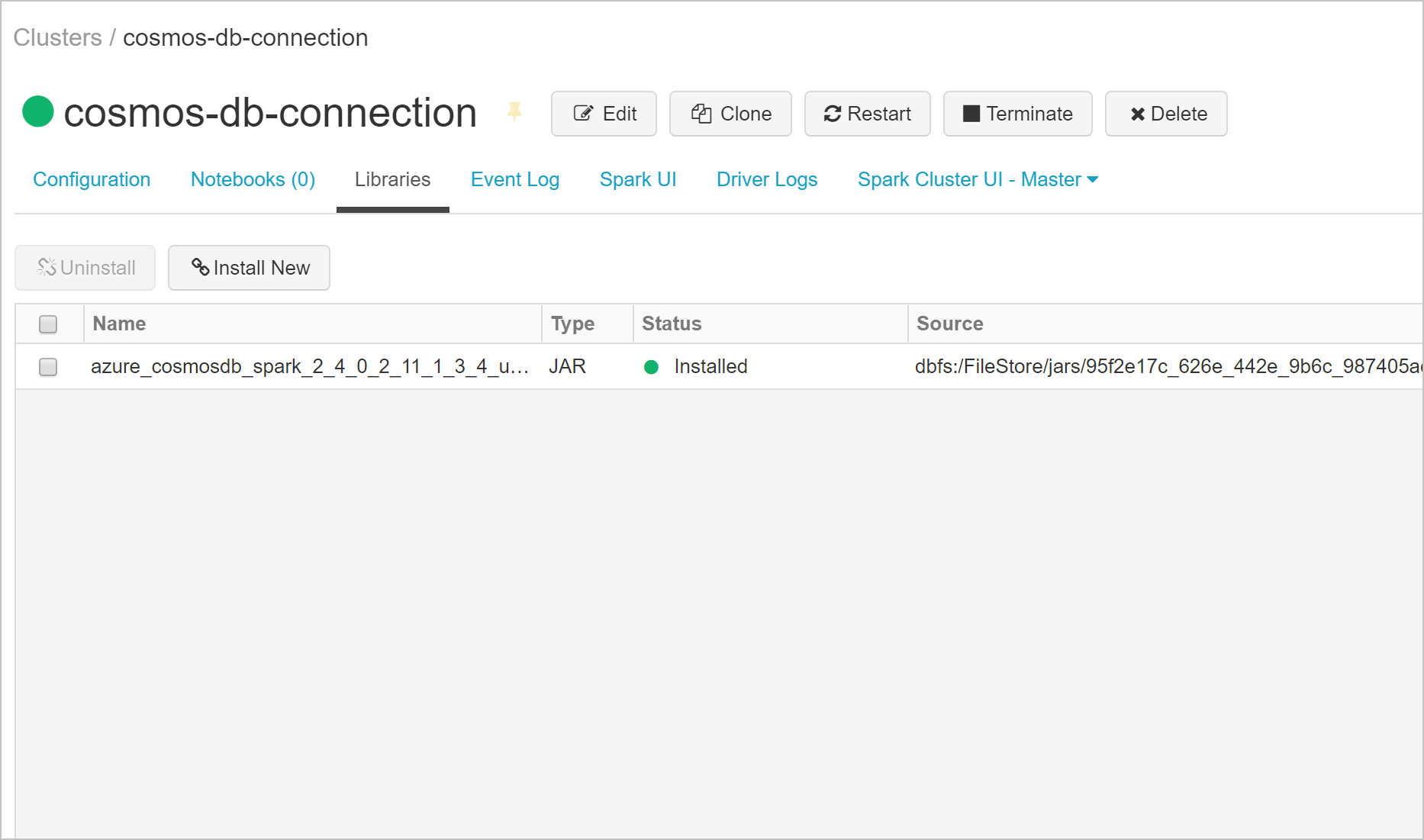
建立叢集之後,流覽至叢集頁面,然後選取 [ 程式庫] 索引卷 標。選取 [安裝新增 ] 並上傳 Spark 連接器 jar 檔案以安裝程式庫。
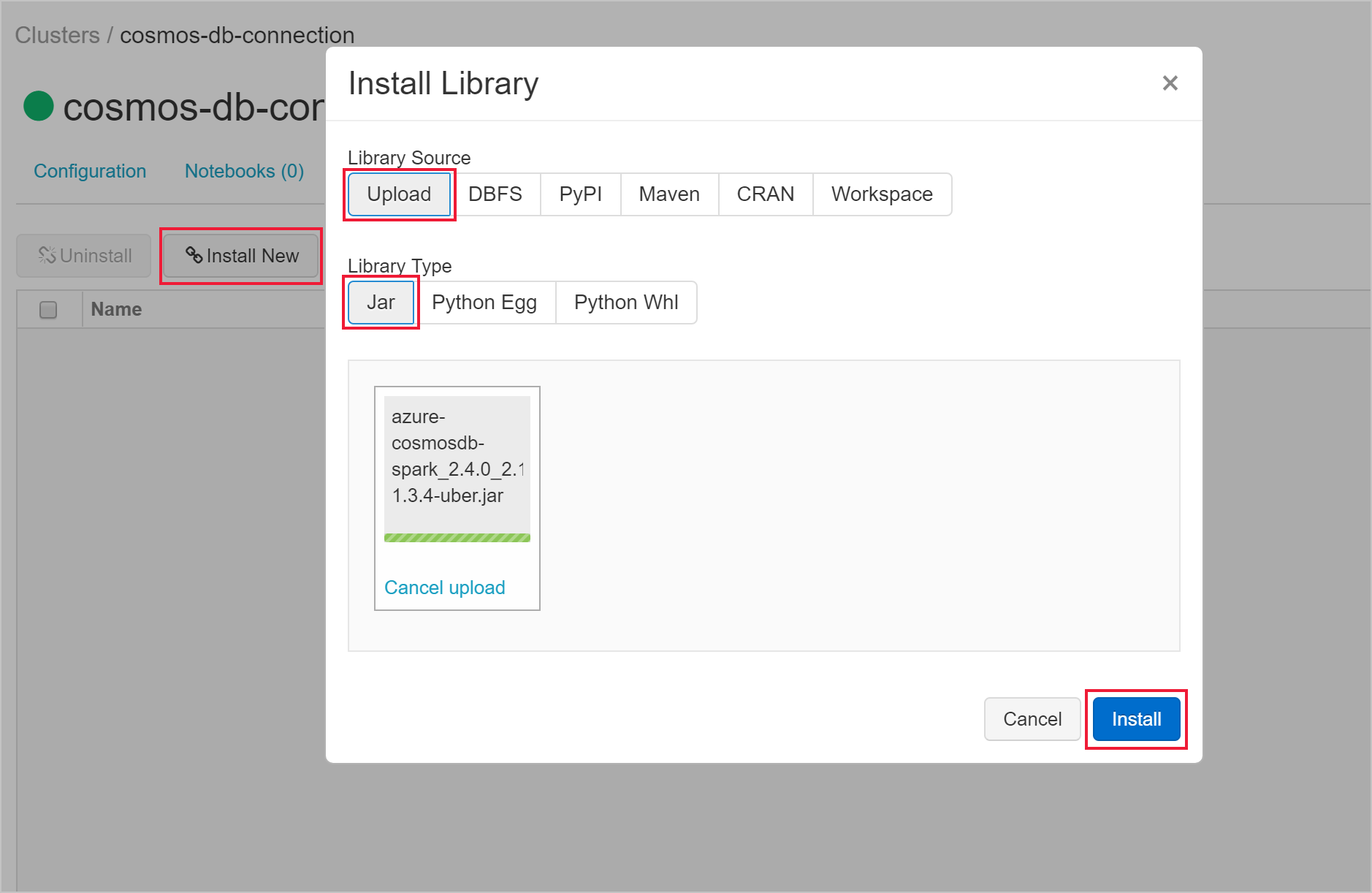
您可以確認程式庫已安裝在 [連結 庫 ] 索引標籤上。
從 Databricks 筆記本查詢 Azure Cosmos DB
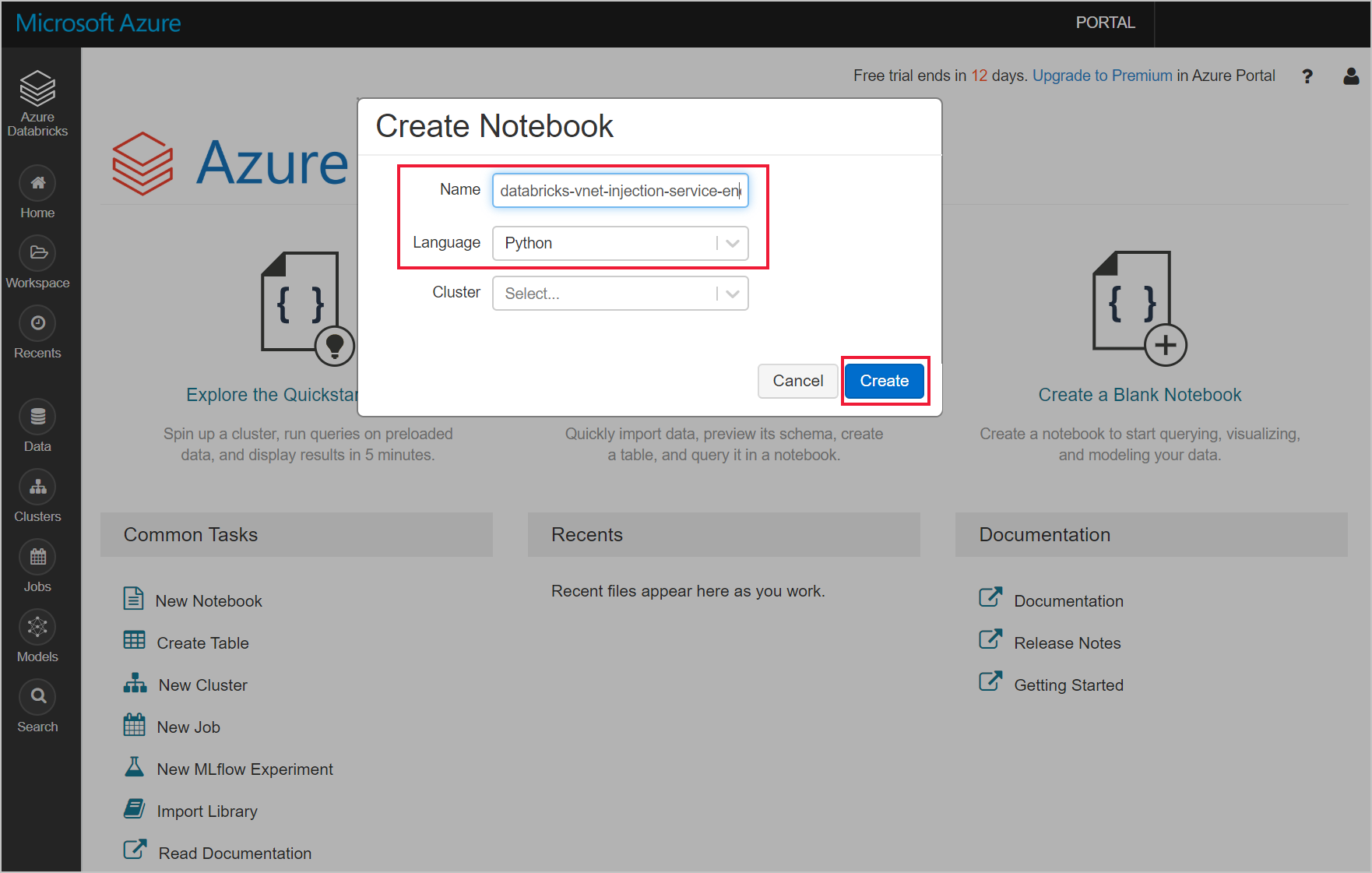
流覽至您的 Azure Databricks 工作區,並建立新的 Python 筆記本。
執行下列 Python 程式碼來設定 Azure Cosmos DB 連線組態。 據以變更 Endpoint、 Masterkey、 Database和 Container 。
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }使用下列 Python 程式碼載入資料並建立暫存檢視。
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")使用下列 magic 命令來執行傳回資料的 SQL 語句。
%sql select * from storm您已成功將 VNet 插入 Databricks 工作區連線到已啟用服務端點的 Azure Cosmos DB 資源。 若要深入瞭解如何連線到 Azure Cosmos DB,請參閱 適用于 Apache Spark 的 Azure Cosmos DB 連接器。
清除資源
不再需要時,請刪除資源群組、Azure Databricks 工作區和所有相關資源。 刪除作業可避免不必要的計費。 如果您打算在未來使用 Azure Databricks 工作區,您可以停止叢集,稍後再重新開機。 如果您不打算繼續使用此 Azure Databricks 工作區,請使用下列步驟刪除您在本教學課程中建立的所有資源:
從Azure 入口網站左側功能表中,按一下 [資源群組],然後按一下您建立的資源群組名稱。
在資源群組頁面上,選取 [ 刪除],在文字方塊中輸入要刪除的資源名稱,然後再次選取 [ 刪除 ]。
後續步驟
在本教學課程中,您已將 Azure Databricks 工作區部署至虛擬網路,並使用 Azure Cosmos DB Spark 連接器從 Databricks 查詢 Azure Cosmos DB 資料。 若要深入瞭解如何在虛擬網路中使用 Azure Databricks,請繼續進行搭配 Azure Databricks 使用SQL Server的教學課程。