測試自定義語音模型的辨識品質
您可以在 Speech Studio 中檢查自訂語音模型的辨識品質。 您可以播放上傳的音訊,並判斷提供的辨識結果是否正確。 成功建立測試之後,您可以看到模型如何轉譯音頻數據集,或並排比較兩個模型的結果。
並存模型測試有助於驗證哪一個語音辨識模型最適合應用程式。 如需需要轉譯數據集輸入的精確度目標量值,請參閱 量化測試模型。
重要
進行測試時,系統會執行轉錄。 因為每個服務供應項目和訂用帳戶層級的定價有所不同,所以請務必牢記這一點。 請一律參閱官方的 Azure AI 服務價格,以取得最新的詳細資料。
建立測試
請遵循下列指示來建立測試:
登入 Speech Studio。
流覽至 Speech Studio> 自訂語音 ,然後從清單中選取您的項目名稱。
選取 [測試模型>] [建立新的測試]。
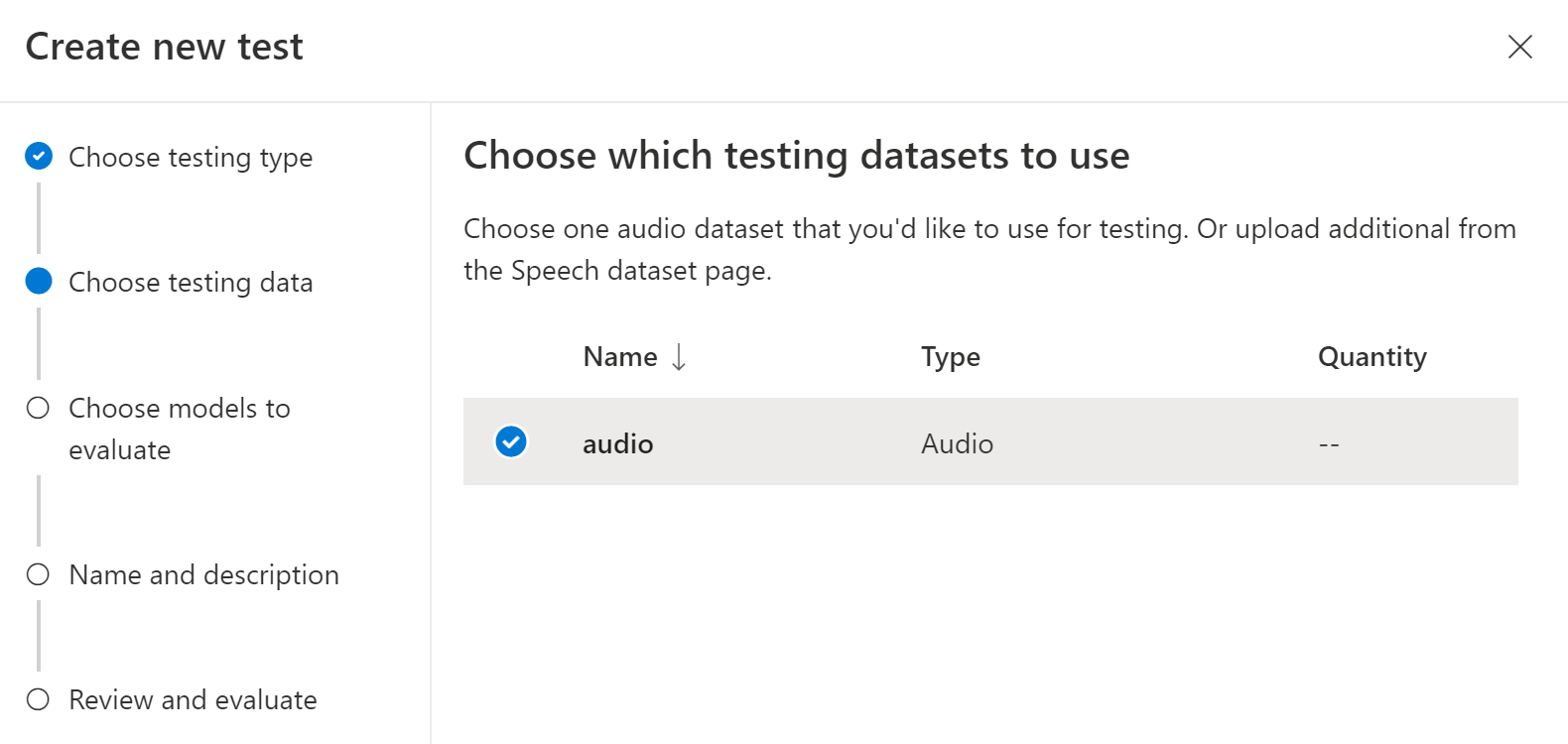
選取 [檢查品質][僅限音訊數據][>下一步]。
選擇您想要用於測試的音訊數據集,然後選取 [ 下一步]。 如果沒有可用的資料集,請取消設定,然後前往 [語音資料集] 功能表以上傳資料集。
選擇一或兩個模型來評估及比較精確度。
輸入測試名稱和描述,然後選取 [下一步]。
檢閱您的設定,然後選取 [儲存後關閉]。
若要建立測試,請使用 spx csr evaluation create 命令。 根據下列指示來建構要求參數:
- 將
project參數設定為現有專案的識別碼。 建議使用此參數,以便您也可以在Speech Studio中檢視測試。 您可以執行spx csr project list命令來取得可用的專案。 - 將必要的
model1參數設定為您想要測試之模型的識別碼。 - 將必要的
model2參數設定為您想要測試之另一個模型的識別碼。 如果您不想比較兩個模型,請針對model1和model2使用相同的模型。 - 將必要的
dataset參數設定為您想要用於測試之資料集的識別碼。 language設定 參數,否則語音 CLI 預設會設定 「en-US」。。 此參數應該是數據集內容的地區設定。 稍後無法變更此地區設定。 語音 CLIlanguage參數會對應至 JSON 要求和回應中的locale屬性。- 設定必要的
name參數。 此參數是Speech Studio中顯示的名稱。 語音 CLIname參數會對應至 JSON 要求和回應中的displayName屬性。
以下是建立測試的範例語音 CLI 命令:
spx csr evaluation create --api-version v3.1 --project 9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226 --dataset be378d9d-a9d7-4d4a-820a-e0432e8678c7 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 1aae1070-7972-47e9-a977-87e3b05c457d --name "My Inspection" --description "My Inspection Description"
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ff43e922-e3e6-4bf0-8473-55c08fd68048"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/be378d9d-a9d7-4d4a-820a-e0432e8678c7"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/6eaf6a15-6076-466a-83d4-a30dba78ca63"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/0c5b1630-fadf-444d-827f-d6da9c0cf0c3"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca/files"
},
"properties": {
"wordErrorRate2": -1.0,
"wordErrorRate1": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1
},
"lastActionDateTime": "2022-05-20T16:42:43Z",
"status": "NotStarted",
"createdDateTime": "2022-05-20T16:42:43Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
回應本文中最上層 self 屬性是評估的 URI。 使用此 URI 來取得專案和測試結果的詳細資料。 您也可以使用此 URI 來更新或刪除評估。
如需使用評估的語音 CLI 說明,請執行下列命令:
spx help csr evaluation
若要建立測試,請使用語音轉換文字 REST API 的 Evaluations_Create 作業。 根據下列指示來建構要求本文:
- 將
project屬性設定為現有專案的 URI。 建議使用這個屬性,以便您也可以在Speech Studio中檢視測試。 您可以提出 Projects_List 要求以取得可用的專案。 - 將必要的
model1屬性設定為您想要測試的模型的 URI。 - 將必要的
model2屬性設定為您想要測試的另一個模型的 URI。 如果您不想比較兩個模型,請針對model1和model2使用相同的模型。 - 將必要的
dataset屬性設定為您想要用於測試的資料集的 URI。 - 設定必要的
locale屬性。 此屬性應該是數據集內容的地區設定。 稍後無法變更此地區設定。 - 設定必要的
displayName屬性。 此屬性是Speech Studio中顯示的名稱。
使用 URI 提出 HTTP POST 要求,如下列範例所示。 以您的語音資源金鑰取代 YourSubscriptionKey、以您的語音資源區域取代 YourServiceRegion,並設定要求本文屬性,如前所述。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ff43e922-e3e6-4bf0-8473-55c08fd68048"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/be378d9d-a9d7-4d4a-820a-e0432e8678c7"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226"
},
"displayName": "My Inspection",
"description": "My Inspection Description",
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations"
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ff43e922-e3e6-4bf0-8473-55c08fd68048"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/be378d9d-a9d7-4d4a-820a-e0432e8678c7"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/6eaf6a15-6076-466a-83d4-a30dba78ca63"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/0c5b1630-fadf-444d-827f-d6da9c0cf0c3"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca/files"
},
"properties": {
"wordErrorRate2": -1.0,
"wordErrorRate1": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1
},
"lastActionDateTime": "2022-05-20T16:42:43Z",
"status": "NotStarted",
"createdDateTime": "2022-05-20T16:42:43Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
回應本文中最上層 self 屬性是評估的 URI。 使用此 URI 來取得評估專案和測試結果的詳細資料。 您也可以使用此 URI 來更新或刪除評估。
取得測試結果
您應該取得測試結果,並 檢查 與每個模型的轉譯結果相比較的音訊數據集。
遵循下列步驟來取得測試結果:
- 登入 Speech Studio。
- 選取 [自定義語音> 您的專案名稱 >測試模型]。
- 依測試名稱選取連結。
- 測試完成之後,如設定為 [成功] 的狀態所指出,您應該會看到結果,其中包含每個測試模型的 WER 數字。
此頁面會列出資料集中的所有語句和辨識結果,以及來自所提交資料集的轉錄。 您可以切換各種錯誤類型,包括插入、刪除和替代。 藉由聆聽音訊並比較每個數據行中的辨識結果,您可以決定哪一個模型符合您的需求,並判斷需要更多訓練和改進。
若要取得測試結果,請使用 spx csr evaluation status 命令。 根據下列指示來建構要求參數:
- 將必要的
evaluation參數設定為您要取得測試結果之評估的識別碼。
以下是取得測試結果的範例語音 CLI 命令:
spx csr evaluation status --api-version v3.1 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
回應本文中會傳回模型、音訊數據集、轉譯和更多詳細數據。
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ff43e922-e3e6-4bf0-8473-55c08fd68048"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/be378d9d-a9d7-4d4a-820a-e0432e8678c7"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/6eaf6a15-6076-466a-83d4-a30dba78ca63"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/0c5b1630-fadf-444d-827f-d6da9c0cf0c3"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca/files"
},
"properties": {
"wordErrorRate2": 4.62,
"wordErrorRate1": 4.6,
"sentenceErrorRate2": 66.7,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 166,
"wordSubstitutionCount2": 7,
"wordDeletionCount2": 0,
"wordInsertionCount2": 1,
"sentenceErrorRate1": 66.7,
"sentenceCount1": 3,
"wordCount1": 174,
"correctWordCount1": 166,
"wordSubstitutionCount1": 7,
"wordDeletionCount1": 1,
"wordInsertionCount1": 0
},
"lastActionDateTime": "2022-05-20T16:42:56Z",
"status": "Succeeded",
"createdDateTime": "2022-05-20T16:42:43Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
如需使用評估的語音 CLI 說明,請執行下列命令:
spx help csr evaluation
若要取得測試結果,請從使用語音轉換文字 REST API 的 Evaluations_Get 作業開始。
使用 URI 提出 HTTP GET 要求,如下列範例所示。 以您的評估識別碼取代 YourEvaluationId、以您的語音資源金鑰取代 YourSubscriptionKey,並以您的語音資源區域取代 YourServiceRegion。
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSubscriptionKey"
回應本文中會傳回模型、音訊數據集、轉譯和更多詳細數據。
您應該會收到下列格式的回應本文:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/ff43e922-e3e6-4bf0-8473-55c08fd68048"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/models/base/1aae1070-7972-47e9-a977-87e3b05c457d"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/datasets/be378d9d-a9d7-4d4a-820a-e0432e8678c7"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/6eaf6a15-6076-466a-83d4-a30dba78ca63"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/transcriptions/0c5b1630-fadf-444d-827f-d6da9c0cf0c3"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/projects/9f8c4cbb-f9a5-4ec1-8bb0-53cfa9221226"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.1/evaluations/8bfe6b05-f093-4ab4-be7d-180374b751ca/files"
},
"properties": {
"wordErrorRate2": 4.62,
"wordErrorRate1": 4.6,
"sentenceErrorRate2": 66.7,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 166,
"wordSubstitutionCount2": 7,
"wordDeletionCount2": 0,
"wordInsertionCount2": 1,
"sentenceErrorRate1": 66.7,
"sentenceCount1": 3,
"wordCount1": 174,
"correctWordCount1": 166,
"wordSubstitutionCount1": 7,
"wordDeletionCount1": 1,
"wordInsertionCount1": 0
},
"lastActionDateTime": "2022-05-20T16:42:56Z",
"status": "Succeeded",
"createdDateTime": "2022-05-20T16:42:43Z",
"locale": "en-US",
"displayName": "My Inspection",
"description": "My Inspection Description"
}
比較轉譯與音訊
您可以針對音訊輸入數據集,檢查每個模型所測試的轉譯輸出。 如果您在測試中包含兩個模型,您可以並排比較其轉譯品質。
若要檢閱轉譯的品質:
- 登入 Speech Studio。
- 選取 [自定義語音> 您的專案名稱 >測試模型]。
- 依測試名稱選取連結。
- 在讀取模型對應的轉譯時播放音訊檔案。
如果測試數據集包含多個音訊檔案,您會在數據表中看到多個數據列。 如果您在測試中包含兩個模型,文字記錄會並排顯示於數據行中。 模型之間的轉譯差異會以藍色文字字型顯示。
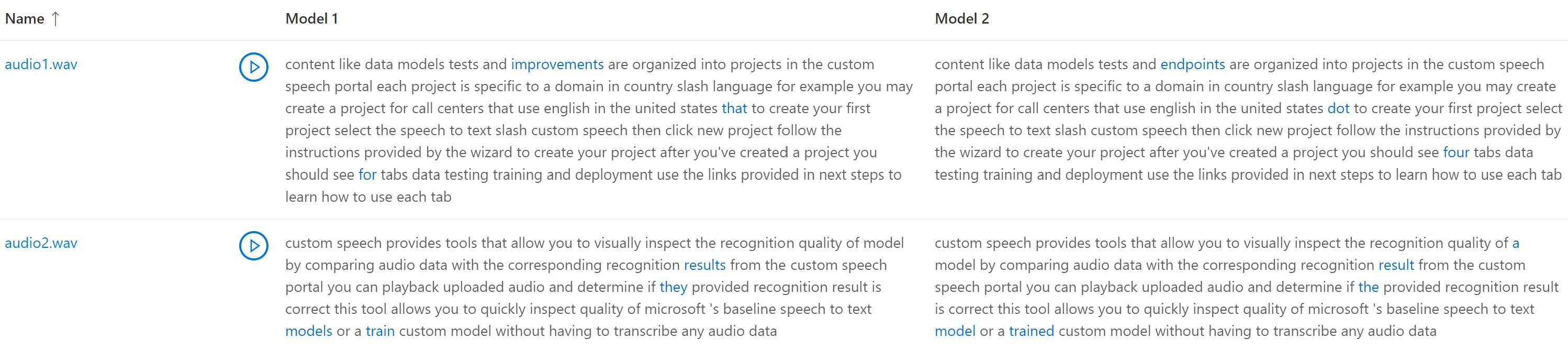
音訊測試數據集、轉譯和測試的模型會在測試結果中傳回。 如果只測試過一個模型,則 model1 值會 model2比對 ,而 transcription1 值會比對 transcription2。
若要檢閱轉譯的品質:
- 除非您已經有複本,否則請下載音訊測試數據集。
- 下載輸出轉譯。
- 在讀取模型對應的轉譯時播放音訊檔案。
如果您要比較兩個模型之間的品質,請特別注意每個模型轉譯之間的差異。
音訊測試數據集、轉譯和測試的模型會在測試結果中傳回。 如果只測試過一個模型,則 model1 值會 model2比對 ,而 transcription1 值會比對 transcription2。
若要檢閱轉譯的品質:
- 除非您已經有複本,否則請下載音訊測試數據集。
- 下載輸出轉譯。
- 在讀取模型對應的轉譯時播放音訊檔案。
如果您要比較兩個模型之間的品質,請特別注意每個模型轉譯之間的差異。