使用 viseme 取得臉部位置
注意
若要探索viseme標識碼和混合圖形支援的地區設定,請參閱 所有支援的地區設定清單。 地區設定僅支援可調整的 en-US 向量圖形 (SVG)。
viseme 是語音語音語音的視覺描述。 它定義了一個人說話時臉部和嘴的位置。 每個內臟都會描述一組特定音素的主要臉部姿勢。
您可以使用 visemes 來控制 2D 和 3D 虛擬人偶模型的移動,讓臉部位置最適合與合成語音對齊。 例如,您可以:
- 為智慧型手機智慧型 Kiosk 建立動畫虛擬語音助理,為客戶建置多模式整合式服務。
- 使用自然臉部和嘴部移動來建置沉浸式新聞廣播,並改善觀眾體驗。
- 產生更多互動式遊戲虛擬人偶和卡通人物,這些人物可以與動態內容交談。
- 製作更有效的語言教學影片,協助語言學習者瞭解每個單字和語音的口語行為。
- 聽力障礙的 人員 也可以以視覺方式和「唇讀」語音內容來拾取聲音,以在動畫的臉上顯示內臟。
如需 visemes 的詳細資訊,請檢視此 簡介影片。
使用語音產生viseme的整體工作流程
類神經文字到語音轉換 (類神經 TTS) 會將輸入文字或 SSML (語音合成標記語言) 轉換成類似生命的合成語音。 語音音訊輸出可以伴隨viseme標識碼、可調整向量圖形(SVG)或混合圖形。 使用 2D 或 3D 轉譯引擎,您可以使用這些 viseme 事件以動畫顯示您的虛擬人偶。
viseme 的整體工作流程描述於下列流程圖中:
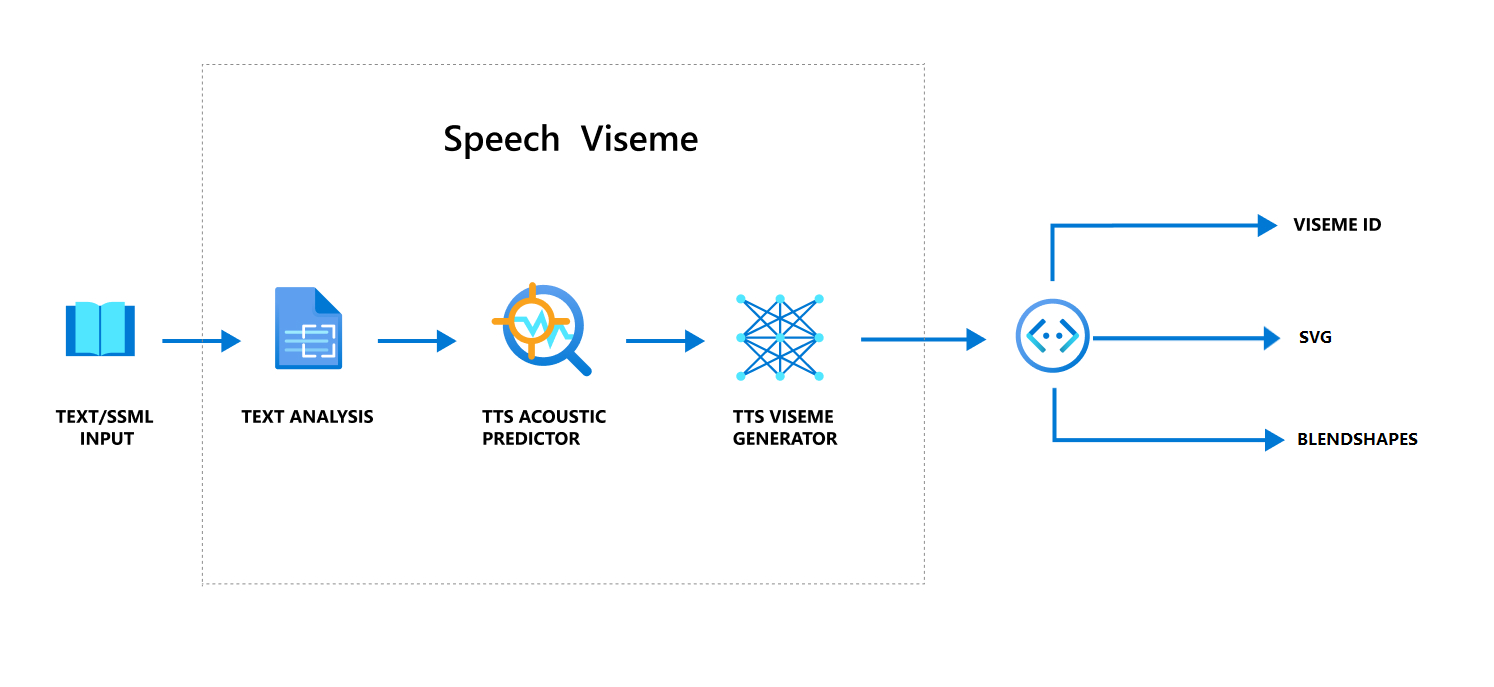
Viseme識別碼
Viseme 識別碼是指指定viseme的整數。 我們提供22個不同的內臟,每一個描繪一組特定音素的嘴位置。 內臟與音素之間沒有一對一的對應。 通常,數個音素會對應至單一 viseme,因為它們在產生時在說話者的臉上看起來相同,例如 s 和 z。 如需更具體的資訊,請參閱將音素對應至viseme標識碼的數據表。
語音音訊輸出可以伴隨viseme識別碼和 Audio offset。 Audio offset表示每個viseme開始時間的位移時間戳,以刻度為單位 (100 奈秒)。
將音素對應至 visemes
Visemes 會依語言和地區設定而有所不同。 每個地區設定都有一組對應至其特定音素的內臟。 SSML 注音字母檔會將viseme識別碼對應至對應的國際 電話 字母 (IPA) 音素。 本節中的表格顯示 viseme 標識符與嘴部位置之間的對應關聯性,列出每個 viseme 標識碼的一般 IPA 音素。
| Viseme識別碼 | Ipa | 嘴部位置 |
|---|---|---|
| 0 | 沉默 |  |
| 1 | æ、 、 əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j、 、 iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ、 、 tʃ、 dʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d、 、 t、 nθ |
 |
| 20 | k、 、 gŋ |
 |
| 21 | p、 、 bm |
 |
2D SVG 動畫
針對 2D 字元,您可以設計適合您案例的字元,並針對每個 viseme 識別碼使用可調整向量圖形 (SVG)來取得以時間為基礎的臉部位置。
透過viseme事件中提供的時態標記,這些設計良好的SVG會以流暢的修改來處理,並提供強固的動畫給使用者。 例如,下圖顯示專為語言學習設計的紅色小寫字元。

3D 混合圖形動畫
您可以使用混合圖形來驅動您設計的 3D 字元臉部移動。
混合圖形 JSON 字串會以 2 維矩陣表示。 每個數據列都代表框架。 每個畫面(以 60 FPS 為單位)都包含 55 個臉部位置的陣列。
使用語音 SDK 取得 viseme 事件
若要使用合成語音取得viseme,請在語音 SDK 中訂閱 VisemeReceived 事件。
注意
若要要求 SVG 或混合圖形輸出,您應該使用 mstts:viseme SSML 中的 元素。 如需詳細資訊,請參閱 如何在 SSML 中使用 viseme 元素。
下列代碼段示範如何訂閱viseme事件:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
以下是viseme輸出的範例。
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
取得viseme輸出之後,您可以使用這些事件來驅動字元動畫。 您可以建置自己的字元並自動建立動畫。