Azure Cosmos DB 和 .NET SDK v2 的效能秘訣
適用於:![]() NoSQL
NoSQL
Azure Cosmos DB 是一個既快速又彈性的分散式資料庫,可在獲得延遲與輸送量保證的情況下順暢地調整。 使用 Azure Cosmos DB 時,您不必進行主要的架構變更,或是撰寫複雜的程式碼來調整您的資料庫。 相應增加和減少就像進行單一 API 呼叫一樣簡單。 若要深入了解,請參閱如何佈建容器輸送量或如何佈建資料庫輸送量。 不過,由於 Azure Cosmos DB 是透過網路呼叫存取,所以您可以在使用 SQL .NET SDK 時進行用戶端最佳化,以達到最高效能。
因此,如果您想要改善資料庫效能,請考慮以下選項:
升級至 .NET V3 SDK
.NET v3 SDK 已發行。 如果您使用的是 .NET v3 SDK,請參閱 .NET v3 效能指南以了解下列資訊:
- 預設為直接 TCP 模式
- 串流 API 支援
- 支援自訂序列化程式以允許使用 System.Text.JSON
- 整合式批次和大量支援
裝載建議
開啟伺服器端記憶體回收 (GC)
在部份情況下,降低記憶體回收頻率可能會有幫助。 在 .NET 中,請將 gcServer 設為 true。
擴增用戶端工作負載
如果您是以高輸送量層級 (超過 50,000 RU/秒) 進行測試,用戶端應用程式可能會成為瓶頸,因為電腦的 CPU 或網路的使用率將達到上限。 如果到了這一刻,您可以將用戶端應用程式向外延展至多部伺服器,以繼續將 Azure Cosmos DB 帳戶再往前推進一步。
注意
高 CPU 使用方式可能會導致延遲增加和要求逾時例外狀況。
中繼資料作業
請勿透過在最忙碌的路徑中呼叫 Create...IfNotExistsAsync 和/或 Read...Async,和/或在執行項目作業之前,確認資料庫和/或集合是否存在。 只有在應用程式啟動且有必要時才應進行驗證 (例如您預期應用程式將會刪除,否則沒有必要)。 這些中繼資料作業會產生額外的端對端延遲,也沒有 SLA,且因為各自的限制而不像資料作業一樣會縮放。
記錄和追蹤
部份環境已啟用 .NET DefaultTraceListener。 DefaultTraceListener 會在生產環境中造成效能問題,導致高 CPU 和 I/O 瓶頸。 請將應用程式從生產環境的 TraceListeners 中移除,藉此檢查並確定您的應用程式已停用 DefaultTraceListener。
最新 SDK 版本 (2.16.2 以上) 偵測到 DefaultTraceListener 時會自動將其移除,而針對較舊的版本,您可以透過下列方式移除:
if (!Debugger.IsAttached)
{
Type defaultTrace = Type.GetType("Microsoft.Azure.Documents.DefaultTrace,Microsoft.Azure.DocumentDB.Core");
TraceSource traceSource = (TraceSource)defaultTrace.GetProperty("TraceSource").GetValue(null);
traceSource.Listeners.Remove("Default");
// Add your own trace listeners
}
網路
原則︰使用直接連接模式
.NET V2 SDK 的預設連線模式是網路閘道。 您可以使用 ConnectionPolicy 參數,在 DocumentClient 執行個體建構期間設定連線模式。 如果您使用直接模式,也會需要使用 ConnectionPolicy 參數來設定 Protocol。 若要深入了解不同的連線選項,請參閱連線模式一文。
Uri serviceEndpoint = new Uri("https://contoso.documents.net");
string authKey = "your authKey from the Azure portal";
DocumentClient client = new DocumentClient(serviceEndpoint, authKey,
new ConnectionPolicy
{
ConnectionMode = ConnectionMode.Direct, // ConnectionMode.Gateway is the default
ConnectionProtocol = Protocol.Tcp
});
暫時連接埠耗盡
如果您的執行個體呈現高連線量或高連接埠使用量,請先確認您的用戶端執行個體為單一資料庫。 換句話說,用戶端執行個體在應用程式的存留期內應該是唯一的。
當用戶端透過 TCP 通訊協定執行時,會利用長時間執行的連線,將延遲縮到最短,這與 HTTPS 通訊協定相反,只要處於非使用狀態下兩分鐘,HTTPS 通訊協定就會終止連線。
在有稀疏存取的情況下,如果您發現相較於網路閘道模式存取,連線計數更高,此時可以:
- 將 ConnectionPolicy.PortReuseMode 屬性設為
PrivatePortPool(有效的架構版本>= 4.6.1 和 .NET Core 版本 >= 2.0):此屬性可讓 SDK 針對不同的 Azure Cosmos DB 目的地端點使用小型的暫時連接埠集區。 - 設定 ConnectionPolicy.IdleConnectionTimeout 屬性必須大於或等於 10 分鐘。 建議值為介於 20 分鐘到 24 小時。
呼叫 OpenAsync 以避免第一次要求的啟動延遲
根據預設,第一個要求會有較高的延遲,因為要求必須擷取位址路由表。 使用 SDK V2 時,請在初始化期間呼叫 OpenAsync() 一次,以避免第一個要求發生這種啟動延遲。 呼叫看起來像這樣:await client.OpenAsync();
注意
OpenAsync 會產生要求,以取得帳戶中所有容器的位址路由表。 如果帳戶有許多容器,但其應用程式只存取一部分的容器,OpenAsync 會產生不必要的流量,導致初始化變慢。 因此在這個案例中,使用 OpenAsync 可能不太實用,因為這會降低應用程式啟動的速度。
為了效能,請將用戶端共置在相同的 Azure 區域中
可能的話,請將任何呼叫 Azure Cosmos DB 的應用程式放在與 Azure Cosmos DB 資料庫相同的區域中。 以下是約略的比較:在相同區域內對 Azure Cosmos DB 進行的呼叫會在 1-2 毫秒內完成,但美國西岸和美國東岸之間的延遲則會大於 50 毫秒。 視要求所採用的路由而定,各項要求從用戶端傳遞至 Azure 資料中心界限的這類延遲可能會有所不同。 請確保呼叫端應用程式與佈建的 Azure Cosmos DB 端點位於相同的 Azure 區域中,如此一來便有可能達到最低的延遲。 如需可用區域的清單,請參閱 Azure 區域。
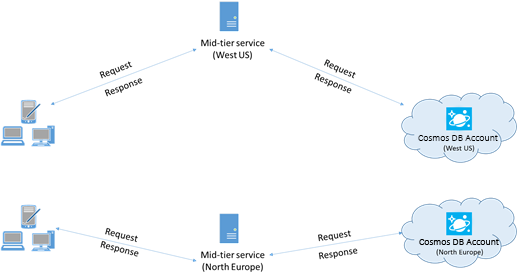
由於對 Azure Cosmos DB 的呼叫要透過網路進行,因此您可能需要改變要求的平行處理原則程度,以便讓用戶端應用程式在不同要求之間的等待時間降到最低。 例如,如果您使用的是 .NET 工作平行程式庫,請依照從 Azure Cosmos DB 讀取或寫入的數百個工作的順序來建立。
啟用加速網路
若要減少延遲和 CPU 抖動,建議您在用戶端虛擬機器上啟用加速網路。 請參閱建立具有加速網路的 Windows 虛擬機器,或建立具有加速網路的 Linux 虛擬機器。
SDK 使用方式
安裝最新的 SDK
Azure Cosmos DB SDK 會持續改善以提供最佳效能。 請參閱 Azure Cosmos DB SDK 頁面來判斷最新的 SDK 並檢閱改善項目。
在應用程式存留期內使用單一 Azure Cosmos DB 用戶端
在直接模式下運作時,每個 DocumentClient 執行個體都是安全執行緒,且能執行有效率的連線管理和位址快取。 若要允許有效率的連線管理和更理想的 SDK 用戶端效能,建議您在應用程式的存留期內針對各 AppDomain 使用單一執行個體。
避免封鎖呼叫
Azure Cosmos DB SDK 應能夠同時處理許多要求。 非同步 API 允許小型執行緒集區透過不等候封鎖呼叫來處理數千個並行要求。 執行緒可以處理另一個要求,而不是等候長時間執行的同步工作完成。
使用 Azure Cosmos DB SDK 的應用程式常出現的效能問題,就是封鎖可能為非同步的呼叫。 許多同步封鎖呼叫會導致執行緒集區耗盡和回應時間降級。
請勿:
- 呼叫 Task.Wait 或 Task.Result 來封鎖非同步執行。
- 使用 Task.Run 將同步 API 改為非同步。
- 透過通用程式碼路徑取得鎖定。 Azure Cosmos DB .NET SDK 的架構為平行執行程式碼時效能最佳。
- 呼叫 Task.Run 並隨即等待。 ASP.NET Core 已在一般執行緒集區執行緒上執行應用程式程式碼,因此呼叫 Task.Run 只會導致額外且不必要的執行緒集區排程。 即使已排程的程式碼會封鎖執行緒,Task.Run 還是無法防止這種情況。
- 將 ToList() 用於
DocumentClient.CreateDocumentQuery(...),而後者使用封鎖呼叫來同步清空查詢。 請使用 ToFeedIterator() 以非同步方式清空查詢。
建議:
- 以非同步方式呼叫 Azure Cosmos DB .NET API。
- 整個呼叫堆疊屬於非同步,可受益於非同步/等候模式。
分析工具如 PerfView,可用來尋找經常新增至執行緒集區的執行緒。 Microsoft-Windows-DotNETRuntime/ThreadPoolWorkerThread/Start 事件表示已新增至執行緒集區的執行緒。
使用網路閘道模式時增加每部主機的 System.Net MaxConnections
當您使用網路閘道模式,系統會透過 HTTPS/REST 發出 Azure Cosmos DB 要求。 這些要求受限於每個主機名稱或 IP 位址的預設連線限制。 您可能需要將 MaxConnections 設為較高的值 (100 至 1000),這樣一來用戶端程式庫就可以使用多個同時連至 Azure Cosmos DB 的連線。 在 .NET SDK 1.8.0 和更新版本中,ServicePointManager.DefaultConnectionLimit 的預設值是 50。 若要變更此值,您可以將 Documents.Client.ConnectionPolicy.MaxConnectionLimit 設為較高的值。
在 RetryAfter 間隔實作降速
在效能測試執行期間,您應該增加負載到系統對小部分要求進行節流處理為止。 如果要求經過節流處理,用戶端應用程式應該在節流時降速,且持續時間達伺服器指定的重試間隔。 採用降速有助於確保您在重試之間花費最少的等待時間。
這些 SDK 包含重試原則支援:
- 適用於 SQL 的 .NET SDK 版本 1.8.0 和更新版本,以及適用於 SQL 的 JAVA SDK
- 適用於 SQL 的 Node.js SDK 版本 1.9.0 和更新版本,以及適用於 SQL 的 Python SDK
- 所有的 .Net Core SDK 支援版本
如需詳細資訊,請參閱 RetryAfter (英文)。
在 .NET SDK 1.19 版和更新版本中,有個機制可以記錄額外的診斷資訊,並且針對延遲問題進行移難排解,如以下範例所示。 您可以針對具有較高讀取延遲的要求記錄診斷字串。 所擷取的診斷字串有助於您了解特定要求收到的 429 錯誤次數。
ResourceResponse<Document> readDocument = await this.readClient.ReadDocumentAsync(oldDocuments[i].SelfLink);
readDocument.RequestDiagnosticsString
快取較低讀取延遲的文件 URI
盡可能快取文件 URI 以達到最佳讀取效能。 在建立資源時,您必須定義邏輯才能快取資源識別碼。 以資源識別碼為基礎的查閱比以名稱為基礎的查閱更快速,因此快取這些值可改善效能。
增加執行緒/工作數目
請參閱本文中「網路」一節中的增加執行緒/工作數目。
查詢作業
如需查詢作業,請參閱查詢的效能秘訣。
編製索引原則
將未使用的路徑排除於索引編製外以加快寫入速度
Azure Cosmos DB 的編製索引原則也可讓您運用檢索路徑 (IndexingPolicy.IncludedPaths 和 IndexingPolicy.ExcludedPaths),指定要在編製索引中包含或排除的文件路徑。 若能事先知道查詢模式,檢索路徑可改善寫入效能並減少索引儲存體。 這是因為編製索引的成本與編製索引的唯一路徑數目直接相互關聯。 例如,此程式碼示範如何使用 "*" 萬用字元將文件 (樹狀子目錄) 的整個區段自編製索引中排除:
var collection = new DocumentCollection { Id = "excludedPathCollection" };
collection.IndexingPolicy.IncludedPaths.Add(new IncludedPath { Path = "/*" });
collection.IndexingPolicy.ExcludedPaths.Add(new ExcludedPath { Path = "/nonIndexedContent/*");
collection = await client.CreateDocumentCollectionAsync(UriFactory.CreateDatabaseUri("db"), collection);
如需詳細資訊,請參閱 Azure Cosmos DB 索引編製原則。
輸送量
測量並調整為較低的每秒要求單位使用量
Azure Cosmos DB 提供豐富的資料庫作業。 這些作業包括使用 UDF、預存程序和觸發程序進行關聯式和階層式查詢,而這些作業全都是對資料庫集合內的文件來進行。 與上述各項作業相關聯的成本,會因為完成作業所需的 CPU、IO 和記憶體而有所不同。 與其思考管理硬體資源,您可以將要求單位 (RU) 視為執行應用程式要求之各種資料庫作業和服務所需資源的單一計量。
輸送量是根據為每個容器所設定的要求單位數量來佈建。 要求單位消耗量是以每秒的速率來計算。 如果應用程式的速率超過為其容器佈建的要求單位速率,便會受到限制,直到該速率降到容器的佈建層級以下。 如果您的應用程式需要較高的輸送量,您可以藉由佈建其他的要求單位來增加輸送量。
查詢的複雜性會影響針對作業所耗用的要求單位數目。 述詞數目、述詞性質,UDF 數目以及來源資料集的大小,全都會影響查詢作業的成本。
若要測量任何作業 (建立、更新或刪除) 的負荷,請檢查 x-ms-request-charge 標頭 (或 ResourceResponse\<T> 中的同等 RequestCharge 屬性,或 .NET SDK 中的 FeedResponse\<T>) 來測量作業所耗用的要求單位數量:
// Measure the performance (Request Units) of writes
ResourceResponse<Document> response = await client.CreateDocumentAsync(collectionSelfLink, myDocument);
Console.WriteLine("Insert of document consumed {0} request units", response.RequestCharge);
// Measure the performance (Request Units) of queries
IDocumentQuery<dynamic> queryable = client.CreateDocumentQuery(collectionSelfLink, queryString).AsDocumentQuery();
while (queryable.HasMoreResults)
{
FeedResponse<dynamic> queryResponse = await queryable.ExecuteNextAsync<dynamic>();
Console.WriteLine("Query batch consumed {0} request units", queryResponse.RequestCharge);
}
在此標頭中傳回的要求費用是佈建輸送量的一小部分 (也就是 2000 RU/秒)。 例如,如果前述查詢傳回 1,000 份 1KB 文件,作業成本會是 1,000。 因此在一秒內,伺服器在對後續要求進行速率限制前,只會接受兩個這類要求。 如需詳細資訊,請參閱要求單位和要求單位計算機。
處理速率限制/要求速率太大
當用戶端嘗試超過為帳戶保留的輸送量時,伺服器的效能不會降低,而且不會使用超過保留層級的輸送量容量。 伺服器會事先以 RequestRateTooLarge (HTTP 狀態碼 429) 結束要求。 伺服器會傳回 x-ms-retry-after-ms 標頭,以毫秒為單位表示使用者必須先等待多少時間,才能再次嘗試要求。
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
SDK 全都隱含地攔截這個回應,採用伺服器指定的 retry-after 標頭,並重試此要求。 除非有多個用戶端同時存取您的帳戶,否則下次重試將會成功。
如果您有多個用戶端不斷逐漸地以高於要求速率的方式運作,則用戶端目前設定為 9 的內部預設重試計數可能會不敷使用。 在此情況下,用戶端會對應用程式擲回狀態碼為 429 的 Documentclientexception。
您可以在 ConnectionPolicy 執行個體上設定 RetryOptions,以變更預設的重試計數。 根據預設,如果要求繼續以高於要求速率的方式運作,則會在 30 秒的累計等候時間後傳回 DocumentClientException (狀態碼 429)。 即使目前的重試計數小於最大重試計數,這項錯誤會也會傳回,無論目前的值為預設的 9 或使用者定義值。
自動化重試行為可協助改善大部分應用程式的復原能力和可用性。 但是在執行效能基準測試時,這可能不是最佳的行為,尤其是在測量延遲的時候。 如果實驗達到伺服器節流並導致用戶端 SDK 以無訊息模式重試,則用戶端觀察到的延遲將會突然增加。 若要避免效能實驗期間的延遲尖峰,測量每個作業所傳回的費用,並確保要求是以低於保留要求速率的方式運作。 如需詳細資訊,請參閱要求單位。
設計較小型的文件以達到較高的輸送量
指定作業的要求費用 (也就是要求的處理成本) 與文件大小直接相關。 大型文件的作業成本高於小型文件的作業成本。
下一步
如需用來評估 Azure Cosmos DB 在數個用戶端電腦上達到高效能情節的範例應用程式,請參閱 Azure Cosmos DB 的效能和規模測試。
若要深入了解如何針對規模和高效能設計您的應用程式,請參閱 Azure Cosmos DB 的資料分割與調整規模。