使用 Azure Data Factory 或 Synapse Analytics 從 Amazon Redshift 複製資料
適用于:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用于企業的單一分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告等所有專案。 瞭解如何 免費啟動新的試用版 !
本文概述如何使用 Azure Data Factory 中的「複製活動」和 Synapse Analytics 管線,從 Amazon Redshift 複製資料。 它會以 複製活動概觀 一文為基礎,提供複製活動的一般概觀。
支援的功能
下列功能支援此 Amazon Redshift 連接器:
| 支援的功能 | IR |
|---|---|
| 複製活動 (source/-) | ① ② |
| 查閱活動 | ① ② |
(1) Azure 整合執行時間 (2) 自我裝載整合執行時間
如需複製活動支援做為來源或接收的資料存放區清單,請參閱 支援的資料存放區 資料表。
具體而言,此 Amazon Redshift 連接器支援使用查詢或內建的 Redshift UNLOAD 支援,從 Redshift 擷取資料。
提示
若要在從 Redshift 複製大量資料時達到最佳效能,請考慮透過 Amazon S3 使用內建的 Redshift UNLOAD。 如需詳細資訊,請參閱 使用 UNLOAD 從 Amazon Redshift 複製資料一節。
必要條件
- 如果您要使用 自我裝載整合執行時間 將資料複製到內部部署資料存放區,請將 Amazon Redshift 叢集的存取權授與 Integration Runtime (使用電腦的 IP 位址)。 如需指示,請參閱 授權存取叢集 。
- 如果您要將資料複製到 Azure 資料存放區,請參閱 Azure 資料中心 IP 範圍 ,以取得 Azure 資料中心所使用的計算 IP 位址和 SQL 範圍。
開始使用
若要使用管線執行複製活動,您可以使用下列其中一個工具或 SDK:
- 複製資料工具
- Azure 入口網站
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- Azure Resource Manager 範本
使用 UI 建立 Amazon Redshift 的連結服務
使用下列步驟,在 Azure 入口網站 UI 中建立 Amazon Redshift 的連結服務。
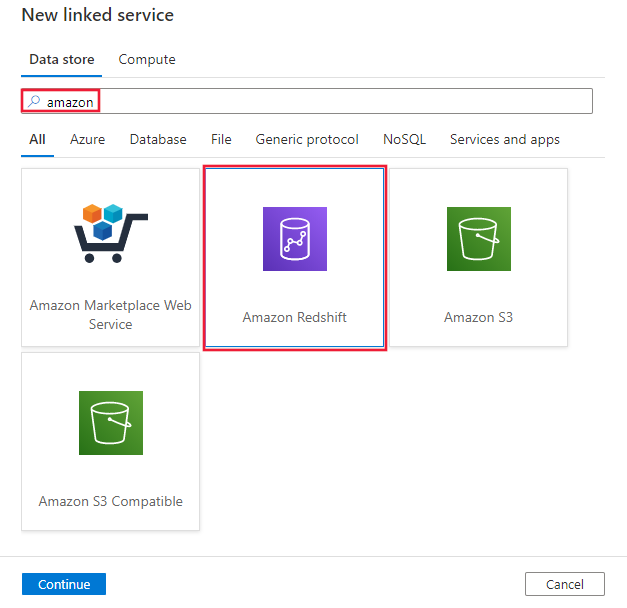
流覽至 Azure Data Factory 或 Synapse 工作區中的 [管理] 索引標籤,然後選取 [連結服務],然後按一下 [新增]:
搜尋 Amazon,然後選取 Amazon Redshift 連接器。
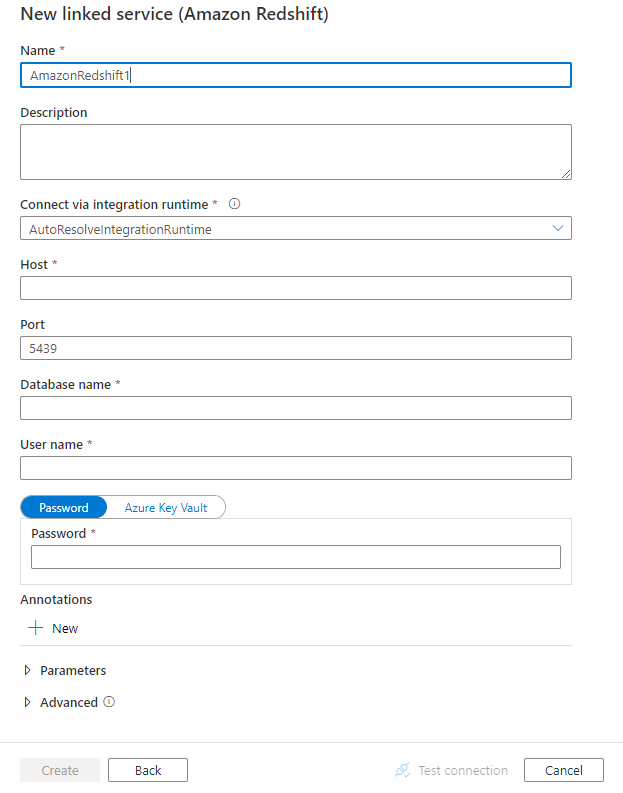
設定服務詳細資料、測試連線,並建立新的連結服務。
連線or 組態詳細資料
下列各節提供屬性的相關詳細資料,這些屬性是用來定義 Amazon Redshift 連接器專屬的 Data Factory 實體。
連結的服務屬性
Amazon Redshift 連結服務支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | type 屬性必須設定為: AmazonRedshift | Yes |
| 伺服器 | Amazon Redshift 伺服器的 IP 位址或主機名稱。 | Yes |
| port | Amazon Redshift 伺服器用來接聽用戶端連線的 TCP 埠數目。 | 否,預設值為 5439 |
| database | Amazon Redshift 資料庫的名稱。 | Yes |
| username | 具有資料庫存取權的使用者名稱。 | Yes |
| password | 使用者帳戶的密碼。 將此欄位標示為 SecureString 以安全地儲存,或 參考儲存在 Azure 金鑰保存庫 中的秘密。 | Yes |
| connectVia | 用於連線到資料存放區的 Integration Runtime。 您可以使用 Azure Integration Runtime 或自我裝載整合執行時間(如果您的資料存放區位於私人網路中)。 如果未指定,就會使用預設的 Azure Integration Runtime。 | No |
範例:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
資料集屬性
如需可用來定義資料集的完整區段和屬性清單,請參閱 資料集 一文。 本節提供 Amazon Redshift 資料集所支援的屬性清單。
若要從 Amazon Redshift 複製資料,支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的類型屬性必須設定為: AmazonRedshiftTable | Yes |
| schema | 架構的名稱。 | 否(如果已指定活動來源中的「查詢」) |
| table | 資料表的名稱。 | 否(如果已指定活動來源中的「查詢」) |
| tableName | 具有架構的資料表名稱。 這個屬性支援回溯相容性。 針對新的工作負載使用 schema 和 table 。 |
否(如果已指定活動來源中的「查詢」) |
範例
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
如果您使用 RelationalTable 具類型的資料集,則仍依目前支援,同時建議您使用新的資料集。
複製活動屬性
如需可用來定義活動的區段和屬性的完整清單,請參閱 管線 一文。 本節提供 Amazon Redshift 來源所支援的屬性清單。
Amazon Redshift 作為來源
若要從 Amazon Redshift 複製資料,請將複製活動中的來源類型設定為 AmazonRedshiftSource 。 複製活動 來源 區段中支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的類型屬性必須設定為: AmazonRedshiftSource | Yes |
| query | 使用自訂查詢來讀取資料。 例如:從 MyTable 中選取 * 。 | 否(如果已指定資料集中的 「tableName」 ) |
| redshiftUnload設定 | 使用 Amazon Redshift UNLOAD 時的屬性群組。 | No |
| s3LinkedServiceName | 指定 「AmazonS3」 類型的連結服務名稱,以作為臨時商店使用 Amazon S3。 | 是,如果使用 UNLOAD |
| bucketName | 指出要儲存過渡資料的 S3 貯體。 如果未提供,服務會自動產生它。 | 是,如果使用 UNLOAD |
範例:使用 UNLOAD 在複製活動中使用 AMAZON Redshift 來源
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
深入瞭解如何使用 UNLOAD 從下一節有效率地從 Amazon Redshift 複製資料。
使用 UNLOAD 從 Amazon Redshift 複製資料
UNLOAD 是 Amazon Redshift 所提供的機制,可將查詢的結果卸載至 Amazon Simple 儲存體 Service (Amazon S3) 上的一或多個檔案。 這是 Amazon 建議從 Redshift 複製大型資料集的方式。
範例:使用 UNLOAD、分段複製和 PolyBase 將資料從 Amazon Redshift 複製到 Azure Synapse Analytics
針對此範例使用案例,複製活動會將資料從 Amazon Redshift 卸載至 Amazon S3,如 「redshiftUnload設定」 中所設定,然後將資料從 Amazon S3 複製到「預備設定」中指定的 Azure Blob,最後使用 PolyBase 將資料載入 Azure Synapse Analytics。 所有過渡格式都由複製活動正確處理。

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Amazon Redshift 的資料類型對應
從 Amazon Redshift 複製資料時,下列對應會從 Amazon Redshift 資料類型使用到服務內部使用的過渡資料類型。 請參閱 架構和資料類型對應 ,以瞭解複製活動如何將來源架構和資料類型對應至接收。
| Amazon Redshift 資料類型 | 過渡期服務資料類型 |
|---|---|
| BIGINT | Int64 |
| BOOLEAN | String |
| CHAR | String |
| 日期 | Datetime |
| DECIMAL | Decimal |
| 雙精確度 | 雙重 |
| INTEGER | Int32 |
| REAL | Single |
| SMALLINT | Int16 |
| TEXT | String |
| timestamp | Datetime |
| VARCHAR | String |
查閱活動屬性
若要瞭解屬性的詳細資料,請檢查 查閱活動 。
相關內容
如需複製活動支援做為來源和接收的資料存放區清單,請參閱 支援的資料存放區 。