使用 Azure Data Factory 或 Azure Synapse Analytics 將資料複製到 Azure Data Lake 儲存體 Gen1 或從中複製資料
適用于:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用于企業的單一分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告等所有專案。 瞭解如何 免費啟動新的試用版 !
本文概述如何從 Azure Data Lake 儲存體 Gen1 複製資料。 若要深入瞭解,請閱讀 Azure Data Factory 或 Azure Synapse Analytics 的 簡介文章。
支援的功能
下列功能支援此 Azure Data Lake 儲存體 Gen1 連接器:
| 支援的功能 | IR |
|---|---|
| 複製活動 (來源/接收) | ① ② |
| 對應資料流程 (來源/接收) | ① |
| 查閱活動 | ① ② |
| GetMetadata 活動 | ① ② |
| 刪除活動 | ① ② |
(1) Azure 整合執行時間 (2) 自我裝載整合執行時間
具體來說,使用此連接器,您可以:
- 使用下列其中一種驗證方法來複製檔案:Azure 資源的服務主體或受控識別。
- 依目前方式複製檔案,或使用支援的檔案格式和壓縮編解碼器 來剖析或產生檔案 。
- 將 ACL 複製到 Azure Data Lake 儲存體 Gen2 時保留 ACL 。
重要
如果您使用自我裝載整合執行時間來複製資料,請將公司防火牆設定為允許埠 <ADLS account name>.azuredatalakestore.net 443 上的輸出 login.microsoftonline.com/<tenant>/oauth2/token 流量。 後者是整合執行時間需要與之通訊才能取得存取權杖的 Azure 安全性權杖服務。
開始使用
提示
如需如何使用 Azure Data Lake Store 連接器的逐步解說,請參閱 將資料載入 Azure Data Lake Store 。
若要使用管線執行複製活動,您可以使用下列其中一個工具或 SDK:
- 複製資料工具
- Azure 入口網站
- The .NET SDK
- The Python SDK
- Azure PowerShell
- The REST API
- Azure Resource Manager 範本
使用 UI 建立 Azure Data Lake 儲存體 Gen1 的連結服務
使用下列步驟,在 Azure 入口網站 UI 中建立 Azure Data Lake 儲存體 Gen1 的連結服務。
流覽至 Azure Data Factory 或 Synapse 工作區中的 [管理] 索引標籤,然後選取 [連結服務],然後選取 [新增]:
搜尋 Azure Data Lake 儲存體 Gen1,然後選取 Azure Data Lake 儲存體 Gen1 連接器。
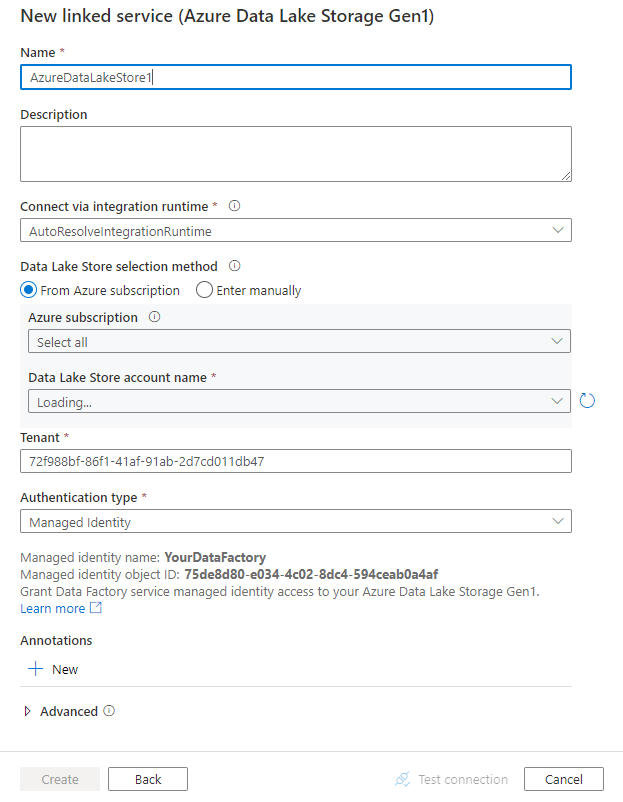
設定服務詳細資料、測試連線,並建立新的連結服務。
連線or 組態詳細資料
下列各節提供屬性的相關資訊,這些屬性是用來定義 Azure Data Lake Store Gen1 專屬的實體。
連結的服務屬性
Azure Data Lake Store 連結服務支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 屬性 type 必須設定為 AzureDataLakeStore 。 |
Yes |
| dataLakeStoreUri | Azure Data Lake Store 帳戶的相關資訊。 這項資訊採用下列其中一種格式: https://[accountname].azuredatalakestore.net/webhdfs/v1 或 adl://[accountname].azuredatalakestore.net/ 。 |
Yes |
| subscriptionId | Data Lake Store 帳戶所屬的 Azure 訂用帳戶識別碼。 | 接收的必要專案 |
| resourceGroupName | Data Lake Store 帳戶所屬的 Azure 資源組名。 | 接收的必要專案 |
| connectVia | 要用來連接到資料存放區的整合執行時間 。 如果您的資料存放區位於私人網路中,您可以使用 Azure 整合執行時間或自我裝載整合執行時間。 如果未指定此屬性,則會使用預設的 Azure 整合執行時間。 | No |
使用服務主體驗證
若要使用服務主體驗證,請遵循下列步驟。
在 Microsoft Entra ID 中註冊應用程式實體,並將 Data Lake Store 的存取權授與它。 如需詳細步驟,請參閱 服務對服務驗證 。 記下下列值,您用來定義連結服務:
- Application ID
- 應用程式金鑰
- 用戶識別碼
授與服務主體適當的許可權。 請參閱如何從 Azure Data Lake 儲存體 Gen1 中的存取控制,在 Data Lake 儲存體 Gen1 中運作許可權的範例。
- 作為來源 :在 [資料總管存取 ] > 中 ,至少 授與 包括根目錄在內的 ALL 上游資料夾執行許可權,以及要複製之檔案的讀取 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。 帳戶層級存取控制 (IAM) 不需要 。
- 作為接收 :在 [資料總 > 管存取 ] 中 ,至少 授與包括根目錄在內的 ALL 上游資料夾執行許可權,以及 接收資料夾的寫入 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。
支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| servicePrincipalId | 指定應用程式的用戶端識別碼。 | Yes |
| servicePrincipalKey | 指定應用程式的金鑰。 將此欄位標示為 SecureString ,以安全地儲存,或 參考儲存在 Azure 金鑰保存庫 中的秘密。 |
Yes |
| tenant | 指定租使用者資訊,例如您應用程式所在的功能變數名稱或租使用者識別碼。 您可以將滑鼠暫留在Azure 入口網站右上角來擷取它。 | Yes |
| azureCloudType | 針對服務主體驗證,請指定註冊 Microsoft Entra 應用程式的 Azure 雲端環境類型。 允許的值為 AzurePublic 、 AzureChina 、 AzureUsGovernment 和 AzureGermany 。 根據預設,會使用服務的雲端環境。 |
No |
範例:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用系統指派的受控識別驗證
資料處理站或 Synapse 工作區可以與 系統指派的受控識別 相關聯,此身分識別代表要驗證的服務。 您可以直接使用此系統指派的受控識別進行 Data Lake Store 驗證,類似于使用您自己的服務主體。 它可讓這個指定的資源存取和複製資料至 Data Lake Store 或從 Data Lake Store 複製資料。
若要使用系統指派的受控識別驗證,請遵循下列步驟。
將系統指派的受控識別存取權授與 Data Lake Store。 請參閱如何從 Azure Data Lake 儲存體 Gen1 中的存取控制,在 Data Lake 儲存體 Gen1 中運作許可權的範例。
- 作為來源 :在 [資料總管存取 ] > 中 ,至少 授與 包括根目錄在內的 ALL 上游資料夾執行許可權,以及要複製之檔案的讀取 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。 帳戶層級存取控制 (IAM) 不需要 。
- 作為接收 :在 [資料總 > 管存取 ] 中 ,至少 授與包括根目錄在內的 ALL 上游資料夾執行許可權,以及 接收資料夾的寫入 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。
您不需要在連結服務中指定一般 Data Lake Store 資訊以外的任何屬性。
範例:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用使用者指派的受控識別驗證
資料處理站可以使用一或多個 使用者指派的受控識別 來指派。 您可以使用此使用者指派的受控識別進行 Blob 儲存體驗證,以存取和複製資料至 Data Lake Store。 若要深入瞭解 Azure 資源的受控識別,請參閱 Azure 資源的受控識別
若要使用使用者指派的受控識別驗證,請遵循下列步驟:
建立一或多個使用者指派的受控識別, 並授與 Azure Data Lake 的存取權。 請參閱如何從 Azure Data Lake 儲存體 Gen1 中的存取控制,在 Data Lake 儲存體 Gen1 中運作許可權的範例。
- 作為來源 :在 [資料總管存取 ] > 中 ,至少 授與 包括根目錄在內的 ALL 上游資料夾執行許可權,以及要複製之檔案的讀取 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。 帳戶層級存取控制 (IAM) 不需要 。
- 作為接收 :在 [資料總 > 管存取 ] 中 ,至少 授與包括根目錄在內的 ALL 上游資料夾執行許可權,以及 接收資料夾的寫入 許可權。 您可以選擇將 新增至 此資料夾和所有子 系以進行遞迴,並新增為 存取權限和預設許可權專案 。
將一或多個使用者指派的受控識別指派給資料處理站,並為 每個使用者指派的受控識別建立 認證。
支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| credentials | 將使用者指派的受控識別指定為認證物件。 | Yes |
範例:
{
"name": "AzureDataLakeStoreLinkedService",
"properties": {
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://<accountname>.azuredatalakestore.net/webhdfs/v1",
"subscriptionId": "<subscription of ADLS>",
"resourceGroupName": "<resource group of ADLS>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
資料集屬性
如需可用來定義資料集之區段和屬性的完整清單,請參閱 資料集 一文。
Azure Data Factory 支援下列檔案格式。 如需以格式為基礎的設定,請參閱每個文章。
在格式型資料集的設定下 location ,Azure Data Lake Store Gen1 支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集底下的 location type 屬性必須設定為 AzureDataLakeStoreLocation 。 |
Yes |
| folderPath | 資料夾的路徑。 如果您想要使用萬用字元來篩選資料夾,請略過此設定,並在活動來源設定中指定。 | No |
| fileName | 指定 folderPath 底下的檔案名。 如果您想要使用萬用字元來篩選檔案,請略過此設定,並在活動來源設定中指定。 | No |
範例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<ADLS Gen1 linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureDataLakeStoreLocation",
"folderPath": "root/folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性的完整清單,請參閱 管線 。 本節提供 Azure Data Lake Store 來源和接收所支援的屬性清單。
Azure Data Lake Store 作為來源
Azure Data Factory 支援下列檔案格式。 如需以格式為基礎的設定,請參閱每個文章。
在格式型複製來源的設定下 storeSettings ,Azure Data Lake Store Gen1 支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 底下的 storeSettings type 屬性必須設定為 AzureDataLakeStoreRead設定 。 |
Yes |
| 找出要複製的檔案: | ||
| 選項 1:靜態路徑 |
從資料集中指定的指定資料夾/檔案路徑複製。 如果您想要從資料夾複製所有檔案,請另外指定 wildcardFileName 為 * 。 |
|
| 選項 2:名稱範圍 - listAfter |
擷取名稱是依字母順序排列的資料夾/檔案(獨佔)。 它利用 ADLS Gen1 的服務端篩選,可提供比萬用字元篩選更好的效能。 服務會將此篩選套用至資料集中定義的路徑,而且僅支援一個實體層級。 請參閱名稱範圍篩選範例中的 更多範例 。 |
No |
| 選項 2:名稱範圍 - listBefore |
依字母順序擷取名稱在此值之前的資料夾/檔案(含)。 它利用 ADLS Gen1 的服務端篩選,可提供比萬用字元篩選更好的效能。 服務會將此篩選套用至資料集中定義的路徑,而且僅支援一個實體層級。 請參閱名稱範圍篩選範例中的 更多範例 。 |
No |
| 選項 3:萬用字元 - 萬用字元FolderPath |
包含萬用字元的資料夾路徑,用來篩選源資料夾。 允許的萬用字元為: * (比對零或多個字元)和 ? (符合零或單一字元;如果您的實際資料夾名稱內有萬用字元或這個逸出字元,請使用 ^ 逸出。 請參閱資料夾和檔案篩選範例中的 更多範例 。 |
No |
| 選項 3:萬用字元 - 萬用字元FileName |
具有指定 folderPath/wildcardFolderPath 下萬用字元的檔案名,用來篩選來源檔案。 允許的萬用字元為: * (比對零或多個字元)和 ? (符合零或單一字元;如果您的實際檔案名中有萬用字元或這個逸出字元,請使用 ^ 逸出字元。 請參閱資料夾和檔案篩選範例中的 更多範例 。 |
Yes |
| OPTION 4:檔案清單 - fileListPath |
表示複製指定的檔案集。 指向包含您要複製之檔案清單的文字檔,每行一個檔案一個,這是資料集中所設定路徑的相對路徑。 使用此選項時,請勿在資料集中指定檔案名。 請參閱檔案清單範例中的 更多範例 。 |
No |
| 其他設定: | ||
| 遞迴 | 指出資料是以遞迴方式從子資料夾讀取,還是只從指定的資料夾讀取。 當遞迴設定為 true 且接收是檔案型存放區時,不會在接收端複製或建立空的資料夾或子資料夾。 允許的值為 true (預設值)和 false 。 當您設定 fileListPath 時,這個屬性不適用。 |
No |
| deleteFilesAfterCompletion | 指出成功移至目的地存放區之後,是否會從來源存放區刪除二進位檔案。 檔案刪除是每個檔案,因此當複製活動失敗時,您會看到某些檔案已複製到目的地並從來源刪除,而其他檔案仍在來源存放區中。 此屬性只有在二進位檔案複製案例中才有效。 預設值:false。 |
No |
| modifiedDatetimeStart | 根據屬性篩選檔案:上次修改。 如果上次修改的時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd ,則會選取檔案。 時間會套用至格式為 「2018-12-01T05:00:00Z」 的 UTC 時區。 屬性可以是 Null,這表示不會將檔案屬性篩選套用至資料集。 當 modifiedDatetimeStart 具有 datetime 值但 modifiedDatetimeEnd 為 Null 時,表示選取上次修改屬性大於或等於 datetime 值的檔案。 當 modifiedDatetimeEnd 具有 datetime 值但 modifiedDatetimeStart 為 Null 時,表示上次修改屬性小於選取 datetime 值的檔案。當您設定 fileListPath 時,這個屬性不適用。 |
No |
| modifiedDatetimeEnd | 同上。 | No |
| enablePartitionDiscovery | 針對已分割的檔案,指定是否要從檔案路徑剖析分割區,並將其新增為其他來源資料行。 允許的值為 false (預設值)和 true 。 |
No |
| partitionRootPath | 啟用資料分割探索時,請指定絕對根路徑,以便將分割區資料夾讀取為數據行。 如果未指定,則預設為 - 當您在資料集中使用檔案路徑或來源上的檔案清單時,分割區根路徑是資料集中設定的路徑。 - 當您使用萬用字元資料夾篩選時,分割區根路徑是第一個萬用字元之前的子路徑。 例如,假設您在資料集中將路徑設定為 「root/folder/year=2020/month=08/day=27」: - 如果您將分割區根路徑指定為 「root/folder/year=2020」,複製活動會分別產生兩個數據行, day 除了檔案內的資料行之外,還會分別產生兩 month 個值 「08」 和 「27」。- 如果未指定分割區根路徑,則不會產生任何額外的資料行。 |
No |
| maxConcurrent連線ions | 在活動執行期間,與資料存放區建立的並行連線上限。 只有在您想要限制並行連線時,才指定值。 | No |
範例:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureDataLakeStoreReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Data Lake Store 作為接收
Azure Data Factory 支援下列檔案格式。 如需以格式為基礎的設定,請參閱每個文章。
在格式型複製接收的設定下 storeSettings ,Azure Data Lake Store Gen1 支援下列屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 底下的 storeSettings type 屬性必須設定為 AzureDataLakeStoreWrite設定 。 |
Yes |
| copyBehavior | 當來源是檔案型資料存放區中的檔案時,定義複製行為。 允許的值如下: - PreserveHierarchy (預設值) :保留目的檔案夾中的檔案階層。 源檔案至源資料夾的相對路徑與目標檔案的相對路徑與目的檔案夾的相對路徑相同。 - FlattenHierarchy :源資料夾中的所有檔案都位於目的檔案夾的第一層。 目標檔案具有自動產生的名稱。 - MergeFiles :將所有檔案從源資料夾合併到一個檔案。 如果指定檔案名,合併的檔案名就是指定的名稱。 否則,它是自動產生的檔案名。 |
No |
| expiryDateTime | 指定寫入檔案的到期時間。 時間會以 「2020-03-01T08:00:00Z」 格式套用至 UTC 時間。 根據預設,它是 Null,這表示寫入的檔案永遠不會過期。 | No |
| maxConcurrent連線ions | 在活動執行期間,與資料存放區建立的並行連線上限。 只有在您想要限制並行連線時,才指定值。 | No |
範例:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureDataLakeStoreWriteSettings",
"copyBehavior": "PreserveHierarchy"
}
}
}
}
]
名稱範圍篩選範例
本節描述名稱範圍篩選的結果行為。
| 範例來源結構 | 組態 | 結果 |
|---|---|---|
| 根 a file.csv 斧頭 file2.csv ax.csv b file3.csv bx.csv c file4.csv cx.csv |
在資料集中: - 資料夾路徑: root在複製活動來源中: - 列出之後: a- 列出之前: b |
然後會複製下列檔案: 根 斧頭 file2.csv ax.csv b file3.csv |
資料夾和檔案篩選範例
本節描述具有萬用字元篩選的資料夾路徑和檔案名所產生的行為。
| folderPath | fileName | 遞迴 | 源資料夾結構和篩選結果( 擷取粗體 檔案) |
|---|---|---|---|
Folder* |
(空白,使用預設值) | false | FolderA File1.csv File2.json 子資料夾1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
(空白,使用預設值) | true | FolderA File1.csv File2.json 子資料夾1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
false | FolderA File1.csv File2.json 子資料夾1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
Folder* |
*.csv |
true | FolderA File1.csv File2.json 子資料夾1 File3.csv File4.json File5.csv AnotherFolderB File6.csv |
檔案清單範例
本節描述在複製活動來源中使用檔案清單路徑的結果行為。
假設您有下列來源資料夾結構,且想要以粗體複製檔案:
| 範例來源結構 | FileListToCopy.txt 中的內容 | 組態 |
|---|---|---|
| 根 FolderA File1.csv File2.json 子資料夾1 File3.csv File4.json File5.csv 中繼資料 FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
在資料集中: - 資料夾路徑: root/FolderA在複製活動來源中: - 檔案清單路徑: root/Metadata/FileListToCopy.txt 檔案清單路徑會指向相同資料存放區中的文字檔,其中包含您要複製的檔案清單,每行一個檔案,以及資料集中所設定路徑的相對路徑。 |
複製作業的行為範例
本節描述複製作業針對 和 copyBehavior 值的不同組合 recursive 所產生的行為。
| 遞迴 | copyBehavior | 來源資料夾結構 | 產生的目標 |
|---|---|---|---|
| true | preserveHierarchy | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以與來源相同的結構建立: Folder1 File1 File2 子資料夾1 File3 File4 File5。 |
| true | flattenHierarchy | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以下列結構建立: Folder1 File1 的自動產生名稱 File2 的自動產生名稱 File3 的自動產生名稱 File4 的自動產生名稱 File5 的自動產生名稱 |
| true | mergeFiles | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以下列結構建立: Folder1 File1 + File2 + File3 + File4 + File5 內容會合並成一個檔案,並具有自動產生的檔案名。 |
| false | preserveHierarchy | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以下列結構建立: Folder1 File1 File2 未挑選 File3、File4 和 File5 的子資料夾1。 |
| false | flattenHierarchy | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以下列結構建立: Folder1 File1 的自動產生名稱 File2 的自動產生名稱 未挑選 File3、File4 和 File5 的子資料夾1。 |
| false | mergeFiles | Folder1 File1 File2 子資料夾1 File3 File4 File5 |
目標 Folder1 是以下列結構建立: Folder1 File1 + File2 內容會合並成一個具有自動產生檔案名的檔案。 File1 的自動產生名稱 未挑選 File3、File4 和 File5 的子資料夾1。 |
將 ACL 保留至 Data Lake 儲存體 Gen2
提示
若要將資料從 Azure Data Lake 儲存體 Gen1 一般複製到 Gen2,請參閱 將資料從 Azure Data Lake 儲存體 Gen1 複製到 Gen2 ,以取得逐步解說和最佳做法。
如果您想要在從 Data Lake 儲存體 Gen1 升級至 Data Lake 儲存體 Gen2 時複寫存取控制清單 (ACL),以及資料檔案,請參閱 從 Data Lake 保留 ACL 儲存體 Gen1 。
對應資料流程屬性
當您在對應資料流程中轉換資料時,可以使用下列格式從 Azure Data Lake 儲存體 Gen1 讀取和寫入檔案:
格式特定設定位於該格式的檔中。 如需詳細資訊,請參閱 對應資料流程 中的來源轉換和 對應資料流程 中的接收轉換。
來源轉換
在來源轉換中,您可以從 Azure Data Lake 儲存體 Gen1 中的容器、資料夾或個別檔案讀取。 [ 來源選項 ] 索引標籤可讓您管理檔案的讀取方式。
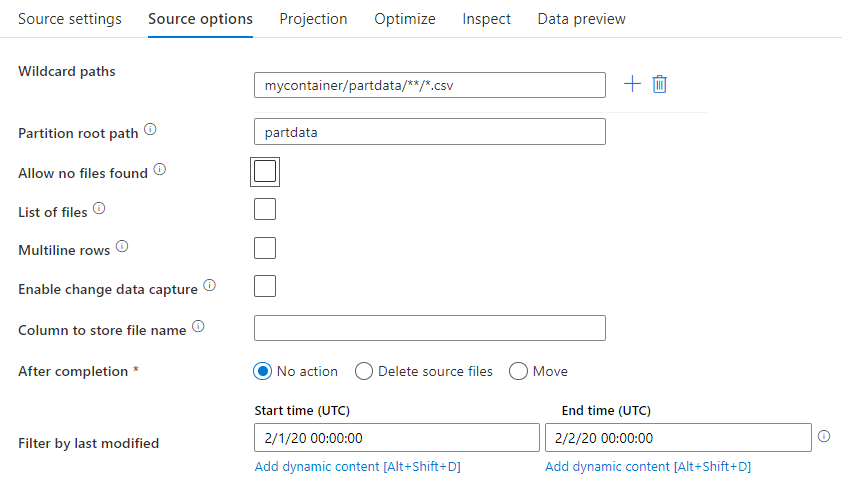
萬用字元路徑: 使用萬用字元模式會指示服務在單一來源轉換中迴圈處理每個相符的資料夾和檔案。 這是在單一流程中處理多個檔案的有效方式。 新增多個萬用字元比對模式,其中包含將滑鼠停留在現有萬用字元模式上方時出現的 + 符號。
從來源容器中,選擇一系列符合模式的檔案。 資料集中只能指定容器。 因此,您的萬用字元路徑也必須包含根資料夾的資料夾路徑。
萬用字元範例:
*代表任何一組字元**表示遞迴目錄巢狀?取代一個字元[]比對括弧中的其中一個字元/data/sales/**/*.csv取得 /data/sales 底下的所有 csv 檔案/data/sales/20??/**/在所有相符的 20xx 資料夾中以遞迴方式取得所有檔案/data/sales/*/*/*.csv取得 /data/sales 下兩個層級的 csv 檔案/data/sales/2004/12/[XY]1?.csv從 2004 年 12 月開始,從 X 或 Y 開始取得所有 csv 檔案,後面接著 1,以及任何單一字元
資料分割根路徑: 如果您的檔案來源 key=value 中有格式的資料分割資料夾(例如 year=2019),您可以將該資料分割資料夾樹的最上層指派給資料流程中的資料行名稱。
首先,設定萬用字元以包含分割資料夾的所有路徑,以及您想要讀取的分葉檔案。
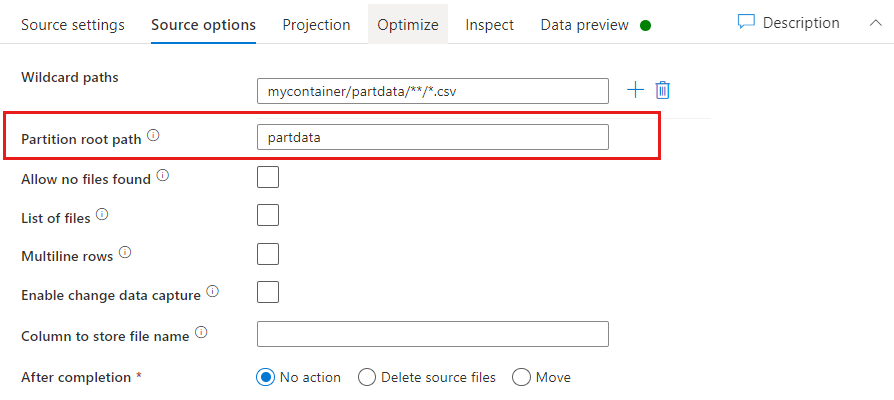
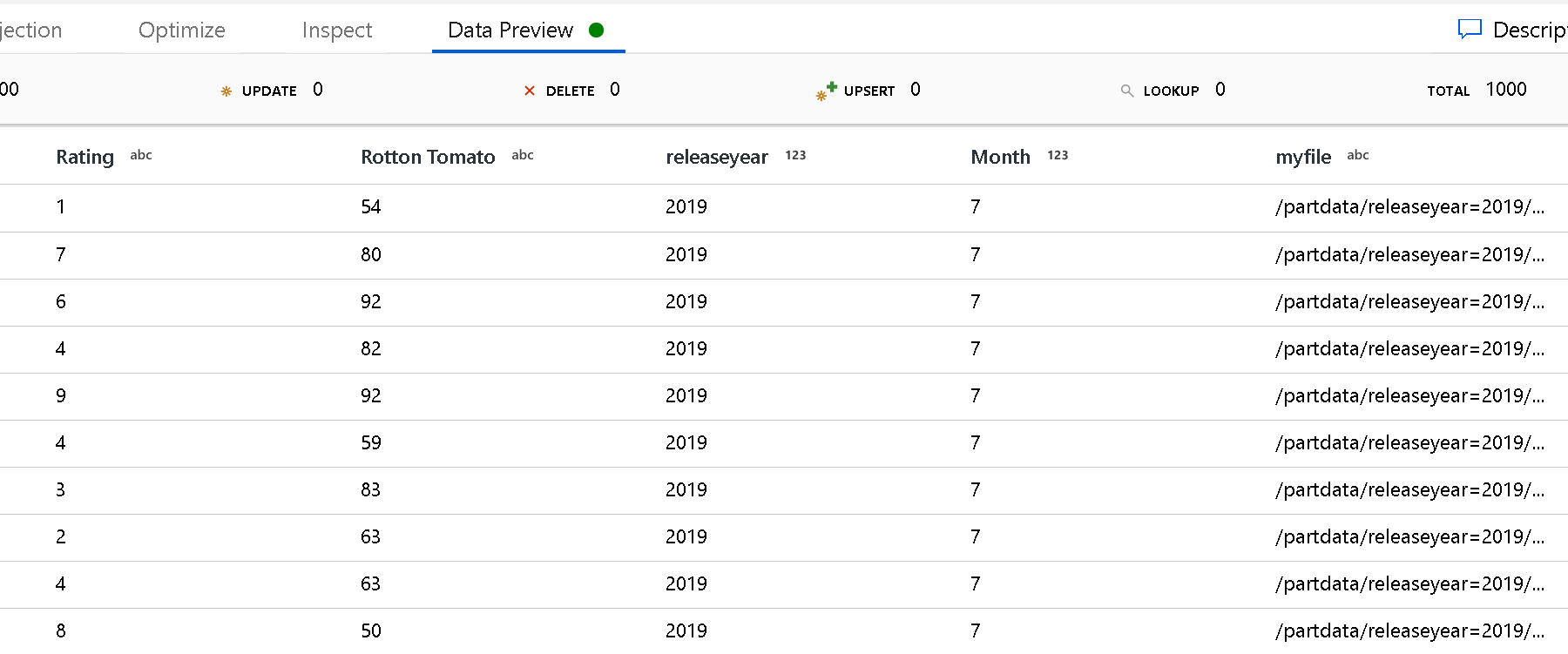
使用 [資料分割根路徑] 設定來定義資料夾結構的最上層。 當您透過資料預覽檢視資料的內容時,您會看到服務會在每個資料夾層級中新增解析的資料分割。
檔案清單: 這是檔案集。 建立文字檔,其中包含要處理的相對路徑檔案清單。 指向這個文字檔。
要儲存檔案名的資料行: 將資料行中的源檔案名稱儲存在資料行中。 在這裡輸入新的資料行名稱來儲存檔案名字串。
完成之後: 選擇在資料流程執行之後,對來源檔案執行任何動作、刪除來源檔案或移動來源檔案。 移動的路徑是相對的。
若要將原始程式檔移至另一個位置後處理,請先選取 [移動] 進行檔案作業。 然後,設定 「from」 目錄。 如果您未針對路徑使用任何萬用字元,則 「from」 設定會與您的源資料夾相同。
如果您有具有萬用字元的來源路徑,語法如下所示:
/data/sales/20??/**/*.csv
您可以將 「from」 指定為
/data/sales
和 「to」 作為
/backup/priorSales
在此情況下,在 /data/sales 下來源的所有檔案都會移至 /backup/priorSales。
注意
只有在您從管線執行啟動資料流程時,才會執行檔案作業(管線偵錯或執行執行),以使用管線中的執行資料流程活動。 檔案作業 不會 在資料流程偵錯模式中執行。
依上次修改的篩選: 您可以藉由指定上次修改日期範圍的 來篩選您處理的檔案。 所有日期時間都是 UTC。
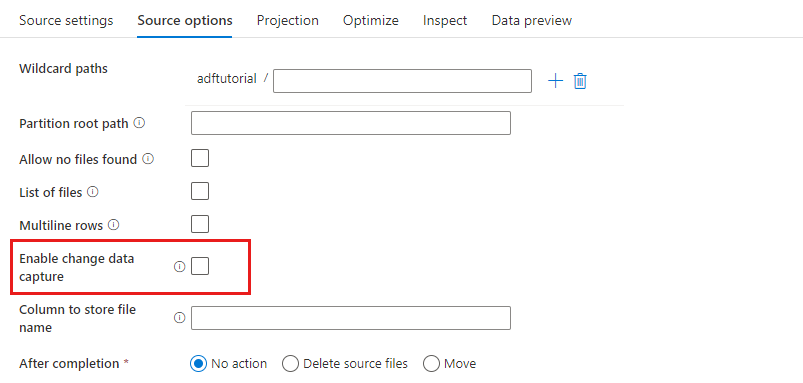
啟用異動資料擷取: 如果為 true,您只會從上次執行取得新的或變更的檔案。 初次執行時一律會擷取完整快照集資料的初始載入,然後只在下一次執行中擷取新的或變更的檔案。 如需詳細資訊,請參閱 異動資料擷取 。
接收屬性
在接收轉換中,您可以寫入 Azure Data Lake 儲存體 Gen1 中的容器或資料夾。 [設定] 索引 標籤可讓您管理檔案的寫入方式。
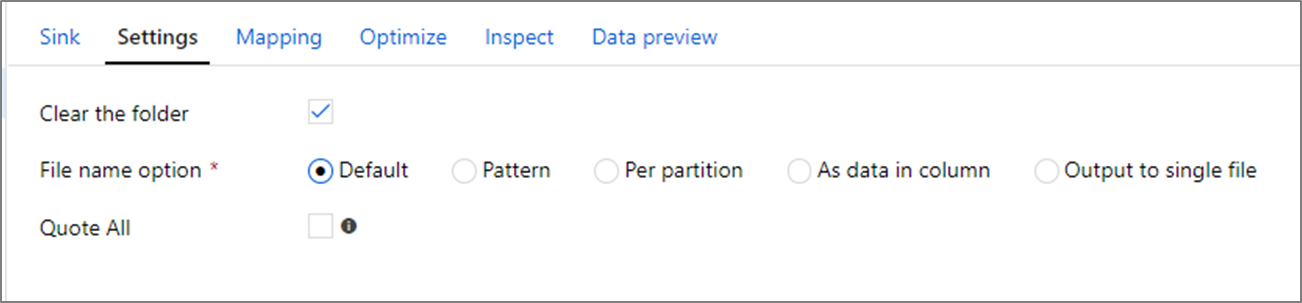
清除資料夾: 判斷是否在寫入資料之前清除目的地資料夾。
檔案名選項: 決定目的地資料夾中的目的地檔案命名方式。 檔案名選項如下:
- 預設值 :允許 Spark 根據 PART 預設值來命名檔案。
- 模式 :輸入列舉每個分割區的輸出檔案的模式。 例如, loans[n].csv 會建立 loans1.csv、loans2.csv 等等。
- 每個分割區:為每個分割 區輸入一個檔案名。
- 當做資料行 中的資料:將輸出檔設定為數據行的值。 路徑相對於資料集容器,而不是目的地資料夾。 如果您的資料集中有資料夾路徑,則會覆寫它。
- 輸出至單一檔案 :將分割的輸出檔案合併成單一具名檔案。 路徑相對於資料集資料夾。 請注意,合併作業可能會根據節點大小而失敗。 不建議針對大型資料集使用此選項。
全部引述: 決定是否以引號括住所有值
查閱活動屬性
若要瞭解屬性的詳細資料,請檢查 查閱活動 。
GetMetadata 活動屬性
若要瞭解屬性的詳細資料,請檢查 GetMetadata 活動
刪除活動屬性
若要瞭解屬性的詳細資料,請參閱 刪除活動
舊版模型
注意
目前仍支援下列模型,以提供回溯相容性。 建議您使用上述各節中提到的新模型,而撰寫 UI 已切換為產生新的模型。
舊版資料集模型
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的 type 屬性必須設定為 AzureDataLakeStoreFile 。 | Yes |
| folderPath | Data Lake Store 中資料夾的路徑。 如果未指定,則會指向根目錄。 支援萬用字元篩選。 允許的萬用字元為 * (比對零或多個字元) 和 ? (符合零或單一字元)。 如果您的實際資料夾名稱內有萬用字元或這個逸出字元,請使用 ^ 來逸出 。 例如:rootfolder/subfolder/。 請參閱資料夾和檔案篩選範例中的 更多範例 。 |
No |
| fileName | 指定 「folderPath」 下檔案的名稱或萬用字元篩選。 如果您未指定這個屬性的值,資料集會指向資料夾中的所有檔案。 針對篩選,允許的萬用字元為 * (符合零或多個字元)和 ? (符合零或單一字元)。- 範例 1: "fileName": "*.csv"- 範例 2: "fileName": "???20180427.txt"如果您的實際檔案名內有萬用字元或這個逸出字元,請使用 ^ 來逸出 。如果未為輸出資料集指定 fileName,而且 活動接收中未指定 preserveHierarchy ,複製活動會自動產生具有下列模式的檔案名:「 Data.[活動執行識別碼 GUID]。[如果 FlattenHierarchy],則為 [GUID]。[如果已設定],則為 [格式]。[如果已設定壓縮] 「,例如」Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz」。 如果您使用資料表名稱而非查詢從表格式來源複製,則名稱模式為 「 [table name].[format]。[如果已設定壓縮] 「,例如 」MyTable.csv」。 |
No |
| modifiedDatetimeStart | 檔案會根據上次修改的屬性進行篩選。 如果上次修改的時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd ,則會選取檔案。 時間會以 「2018-12-01T05:00:00Z」 的格式套用至 UTC 時區。 當您想要使用大量檔案執行檔案篩選時,資料移動的整體效能會受到啟用此設定的影響。 屬性可以是 Null,這表示不會將檔案屬性篩選套用至資料集。 當 modifiedDatetimeStart 有日期時間值但 modifiedDatetimeEnd 為 Null 時,表示選取上次修改屬性大於或等於日期時間值的檔案。 當 modifiedDatetimeEnd 有日期時間值但 modifiedDatetimeStart 為 Null 時,表示上次修改屬性小於選取 datetime 值的檔案。 |
No |
| modifiedDatetimeEnd | 檔案會根據上次修改的屬性進行篩選。 如果上次修改的時間大於或等於 modifiedDatetimeStart 且小於 modifiedDatetimeEnd ,則會選取檔案。 時間會以 「2018-12-01T05:00:00Z」 的格式套用至 UTC 時區。 當您想要使用大量檔案執行檔案篩選時,資料移動的整體效能會受到啟用此設定的影響。 屬性可以是 Null,這表示不會將檔案屬性篩選套用至資料集。 當 modifiedDatetimeStart 有日期時間值但 modifiedDatetimeEnd 為 Null 時,表示選取上次修改屬性大於或等於日期時間值的檔案。 當 modifiedDatetimeEnd 有日期時間值但 modifiedDatetimeStart 為 Null 時,表示上次修改屬性小於選取 datetime 值的檔案。 |
No |
| format | 如果您想要在檔案型存放區之間複製檔案(二進位複製),請略過輸入和輸出資料集定義中的 format 區段。 如果您想要剖析或產生具有特定格式的檔案,支援下列檔案格式類型: TextFormat 、 JsonFormat 、 AvroFormat 、 OrcFormat 和 ParquetFormat 。 將 格式 下的 type 屬性設定為下列其中一個值。 如需詳細資訊,請參閱 文字格式、 JSON 格式 、 Avro 格式 、 Orc 格式 和 Parquet 格式 小節。 |
否 (僅適用于二進位複製案例) |
| 壓縮 | 指定資料的壓縮類型和層級。 如需詳細資訊,請參閱 支援的檔案格式和壓縮編解碼器 。 支援的類型包括 GZip、 Deflate 、 BZip2 和 ZipDeflate 。 支援的層級是 最佳 且 最快的 層級。 |
No |
提示
若要複製資料夾下的所有檔案,請只指定 folderPath 。
若要複製具有特定名稱的單一檔案,請使用資料夾部分指定 folderPath ,並以 檔案名指定 fileName 。
若要複製資料夾下的檔案子集,請使用資料夾部分指定 folderPath ,並使用 萬用字元篩選來指定 fileName 。
範例:
{
"name": "ADLSDataset",
"properties": {
"type": "AzureDataLakeStoreFile",
"linkedServiceName":{
"referenceName": "<ADLS linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "datalake/myfolder/",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
舊版複製活動來源模型
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | type複製活動來源的 屬性必須設定為 AzureDataLakeStoreSource 。 |
Yes |
| 遞迴 | 指出資料是以遞迴方式從子資料夾讀取,還是只從指定的資料夾讀取。 當 recursive 設為 true 且接收是以檔案為基礎的存放區時,不會在接收端複製或建立空的資料夾或子資料夾。 允許的值為 true (預設值)和 false 。 |
No |
| maxConcurrent連線ions | 在活動執行期間,與資料存放區建立的並行連線上限。 只有在您想要限制並行連線時,才指定值。 | No |
範例:
"activities":[
{
"name": "CopyFromADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<ADLS Gen1 input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
舊版複製活動接收模型
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | type複製活動接收的 屬性必須設定為 AzureDataLakeStoreSink 。 |
Yes |
| copyBehavior | 當來源是檔案型資料存放區中的檔案時,定義複製行為。 允許的值如下: - PreserveHierarchy (預設值) :保留目的檔案夾中的檔案階層。 源檔案至源資料夾的相對路徑與目標檔案的相對路徑與目的檔案夾的相對路徑相同。 - FlattenHierarchy :源資料夾中的所有檔案都位於目的檔案夾的第一層。 目標檔案具有自動產生的名稱。 - MergeFiles :將所有檔案從源資料夾合併到一個檔案。 如果指定檔案名,合併的檔案名就是指定的名稱。 否則,會自動產生檔案名。 |
No |
| maxConcurrent連線ions | 在活動執行期間,與資料存放區建立的並行連線上限。 只有在您想要限制並行連線時,才指定值。 | No |
範例:
"activities":[
{
"name": "CopyToADLSGen1",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<ADLS Gen1 output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDataLakeStoreSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
異動資料擷取 (預覽)
Azure Data Factory 只能在對應資料流程來源轉換中啟用 異動資料擷取(預覽) ,以從 Azure Data Lake 儲存體 Gen1 取得新的或變更的檔案。 使用此連接器選項時,您只能讀取新的或更新的檔案,並在將轉換的資料載入您選擇的目的地資料集之前套用轉換。
請確定您保持管線和活動名稱不變,以便一律從上次執行記錄檢查點,以從該處取得變更。 如果您變更管線名稱或活動名稱,將會重設檢查點,並從下一個回合的開頭開始。
當您對管線進行偵錯時, 啟用異動資料擷取 (預覽) 也會運作。 當您在偵錯執行期間重新整理瀏覽器時,會重設檢查點。 滿意偵錯執行的結果之後,您可以發佈並觸發管線。 不論偵錯執行所記錄的先前檢查點為何,它一律會從頭開始。
在 [監視] 區段中,您一律有機會重新執行管線。 當您這樣做時,一律會從所選管線執行中的檢查點記錄取得變更。
相關內容
如需複製活動支援做為來源和接收的資料存放區清單,請參閱 支援的資料存放區 。