使用 Data Factory 對應資料流處理固定長度文字檔
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
您可以使用 Microsoft Azure Data Factory 中的對應資料流,從固定寬度文字檔轉換資料。 在以下工作中,我們將不使用分隔符號定義文字檔資料集,然後根據序數位置設定 substring 分割。
建立新管線
選取 [+ 新增管線],建立新管線。
新增資料流程活動,此活動將用於處理固定寬度檔案:
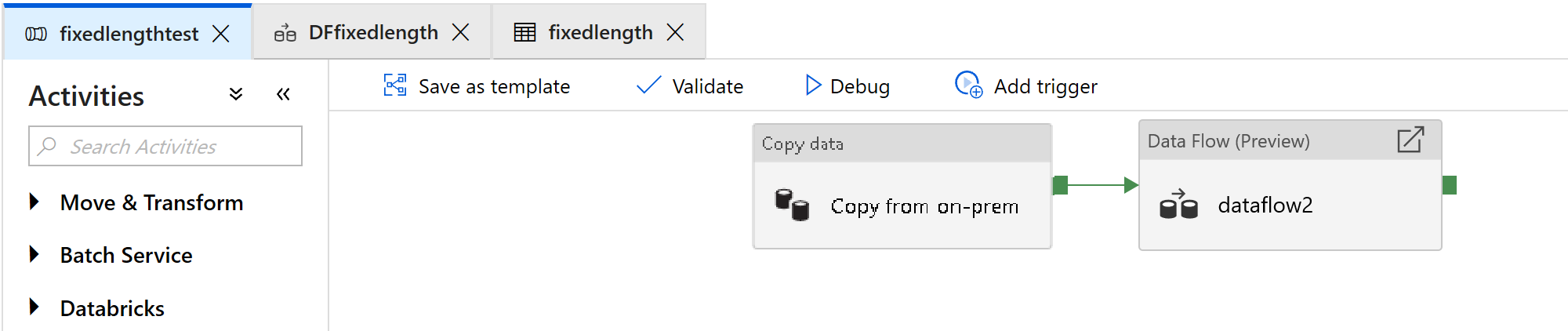
在資料流程活動中,選取 [新增對應資料流]。
新增 [來源]、[衍生的資料行]、[選取] 和 [接收] 轉換:
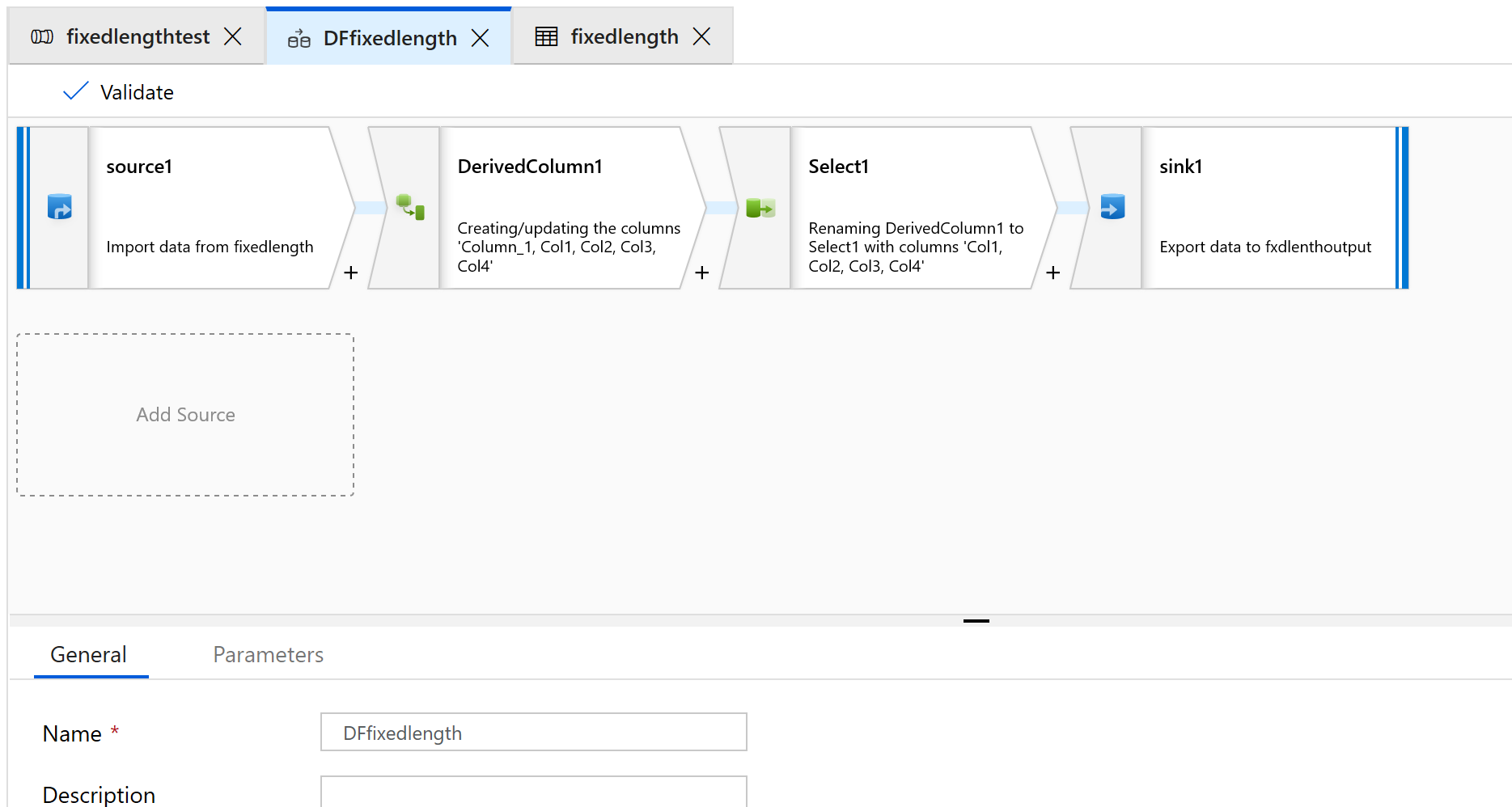
將 [來源] 轉換設定為使用新資料集,資料集會是分隔文字類型。
請勿設定任何資料行分隔符號或標頭。
我們現在要設定此檔案內容的欄位起點和長度:
1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468 1234567813572468在 [來源] 轉換的 [投影] 索引標籤上,您應該會看到 Column_1 字串資料行。
在 [衍生的資料行] 中,建立新資料行。
我們會為資料行取簡單名稱,如 col1。
在運算式建立器中,輸入下列內容:
substring(Column_1,1,4)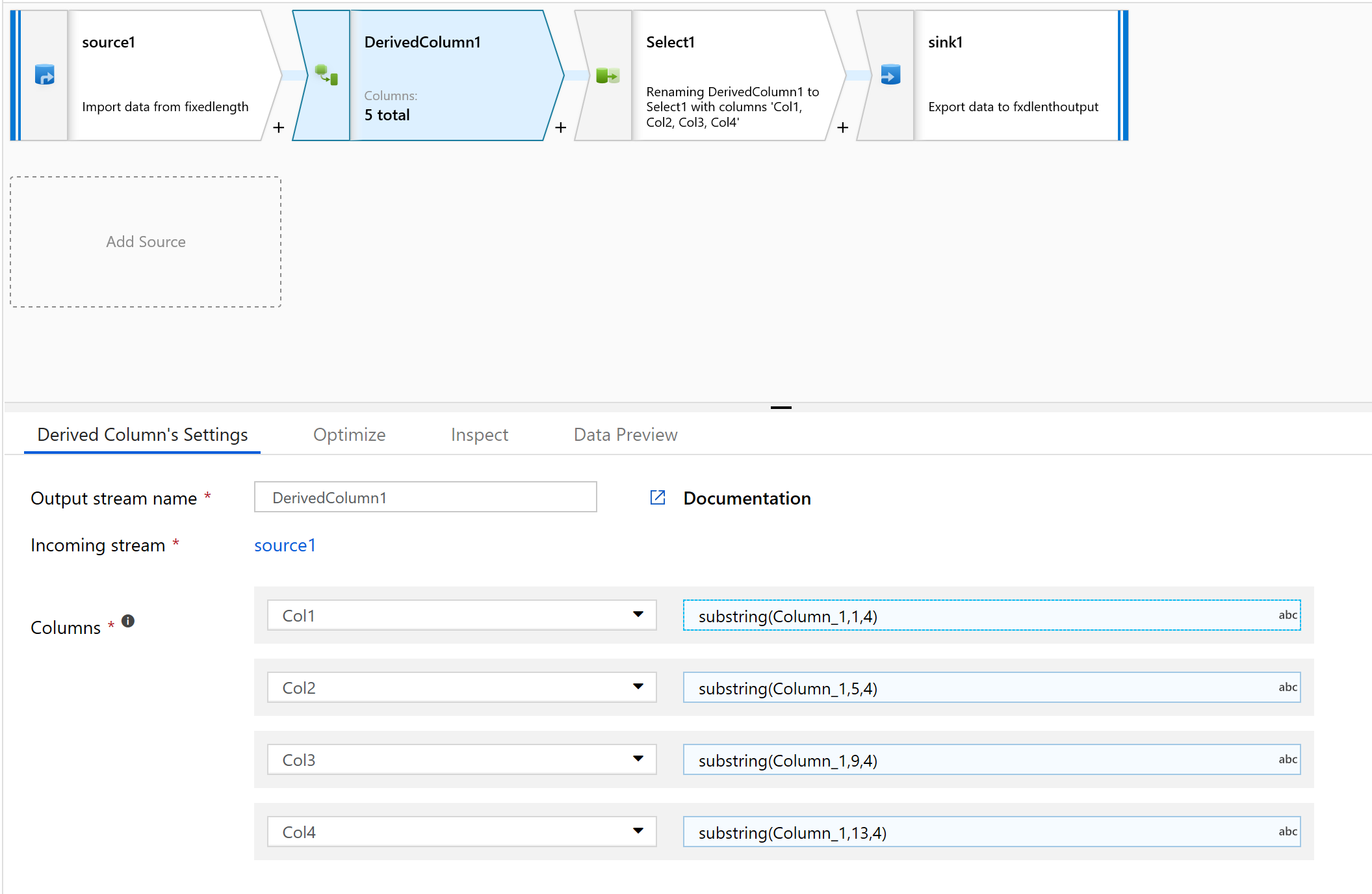
對您必須剖析的所有資料行重複步驟 10。
選取 [檢查] 索引標籤,查看將產生的新資料行:
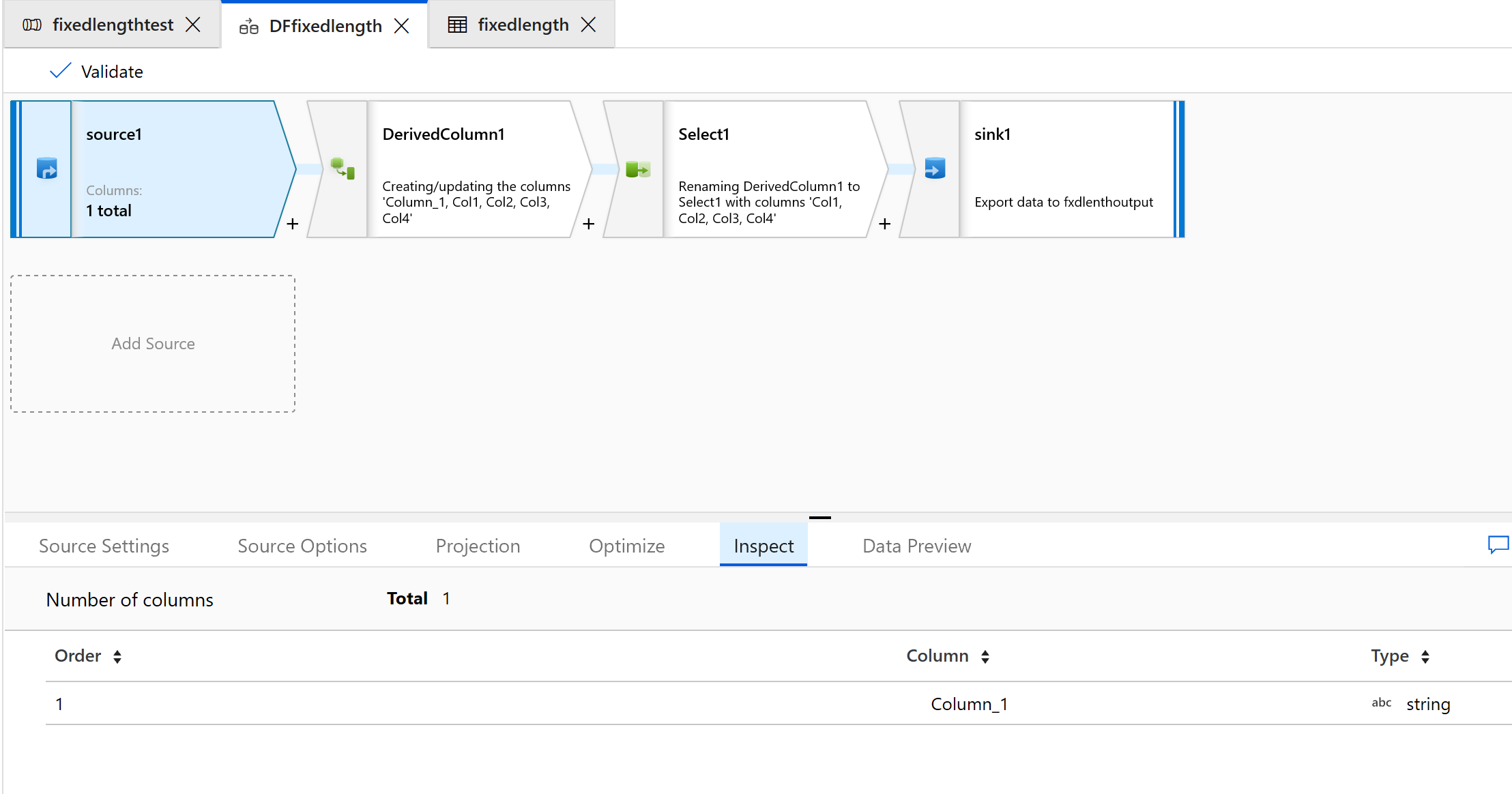
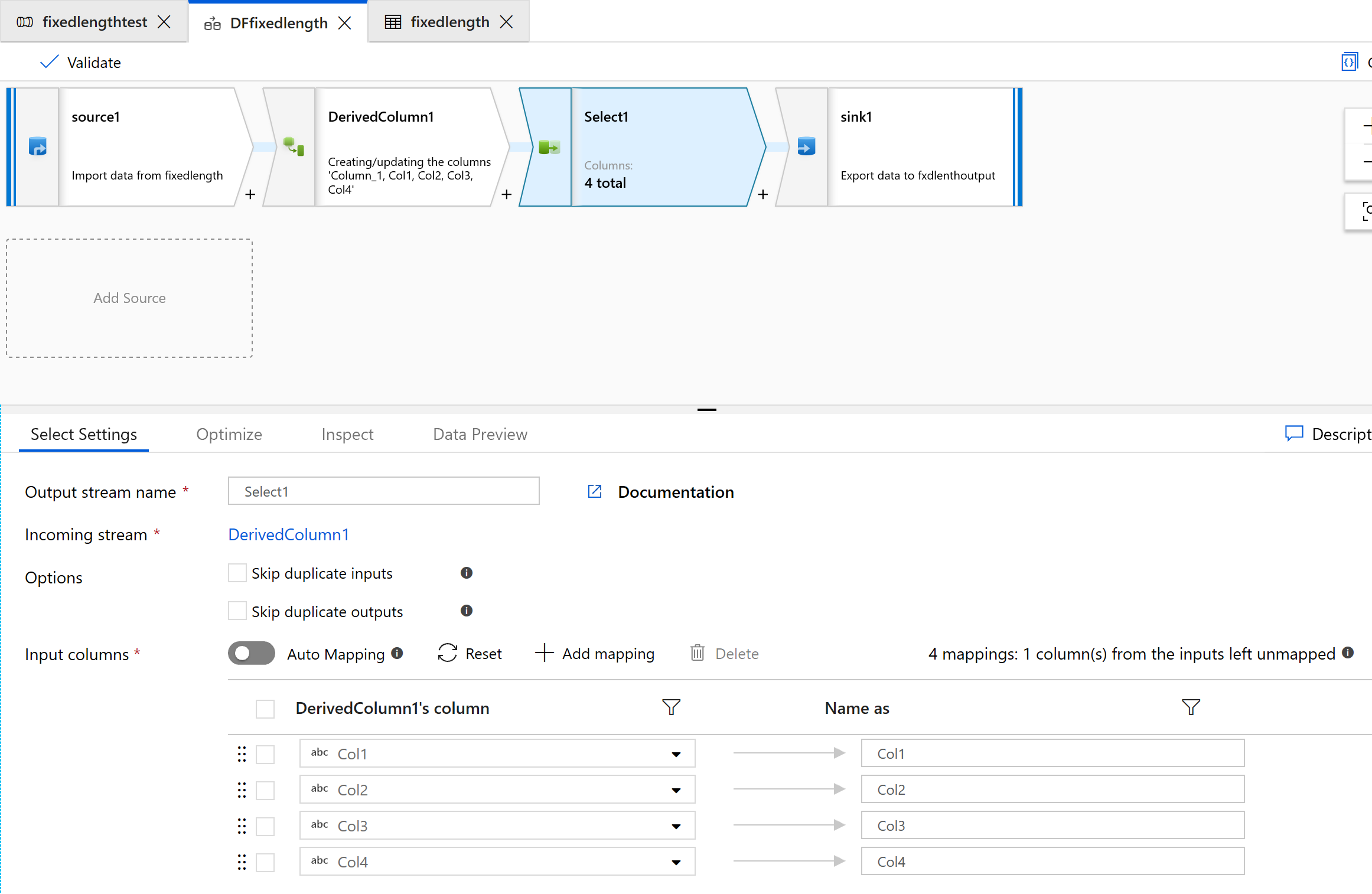
使用 [選取] 轉換,移除不須轉換的任何資料行:
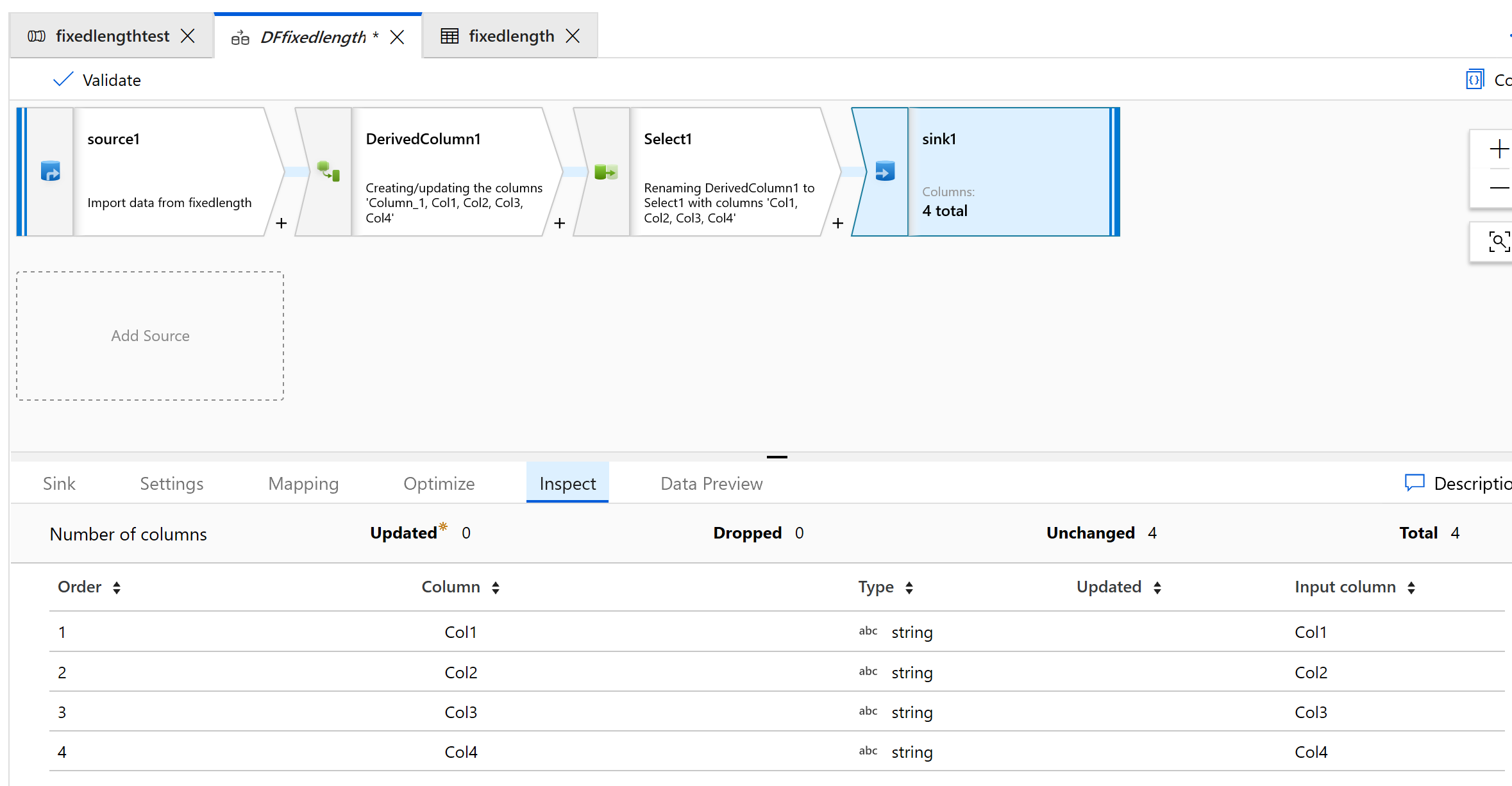
使用 [接收] 將資料輸出至資料夾:
輸出看起來像這樣:
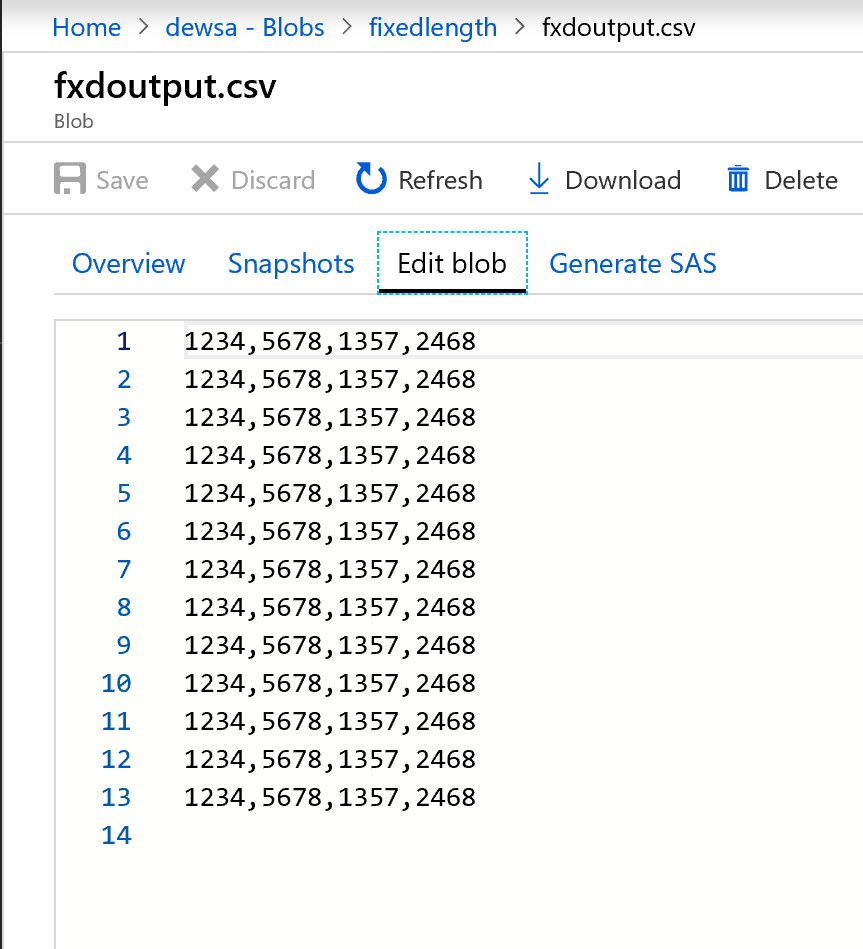
現在已分割固定寬度資料,每個有四個字元,並指派給 Col1、Col2、Col3、Col4 等。 根據上述範例,資料會分割成四個資料行。
相關內容
- 使用對應資料流程轉換,以組建資料流程邏輯的其餘部分。