在 Azure Databricks 中執行 Jar 活動來轉換資料
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
管線中的 Azure Databricks Jar 活動會在 Azure Databricks 叢集中執行 Spark Jar 檔案。 本文是根據 資料轉換活動 一文,它呈現資料轉換和支援的轉換活動的一般概觀。 Azure Databricks 是用於執行 Apache Spark 的受控平台。
如需此功能的簡介與示範,請觀看下列 11 分鐘長的影片:
使用 UI 將適用於 Azure Databricks 的 Jar 活動新增至管線
若要在管線中使用適用於 Azure Databricks 的 Jar 活動,請完成下列步驟:
在管線 [活動] 窗格中搜尋 Jar,然後將 Jar 活動拖曳至管線畫布中。
若尚未選取 Jar 活動,請在畫布上選取新的 Jar 活動。
選取 [Azure Databricks] 索引標籤,以選取或建立將要執行 Jar 活動的新 Azure Databricks 連結服務。
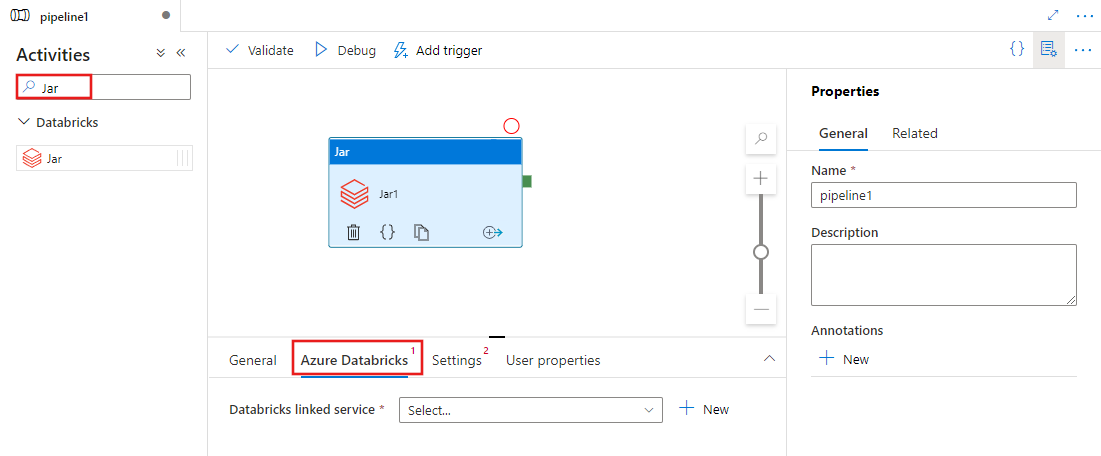
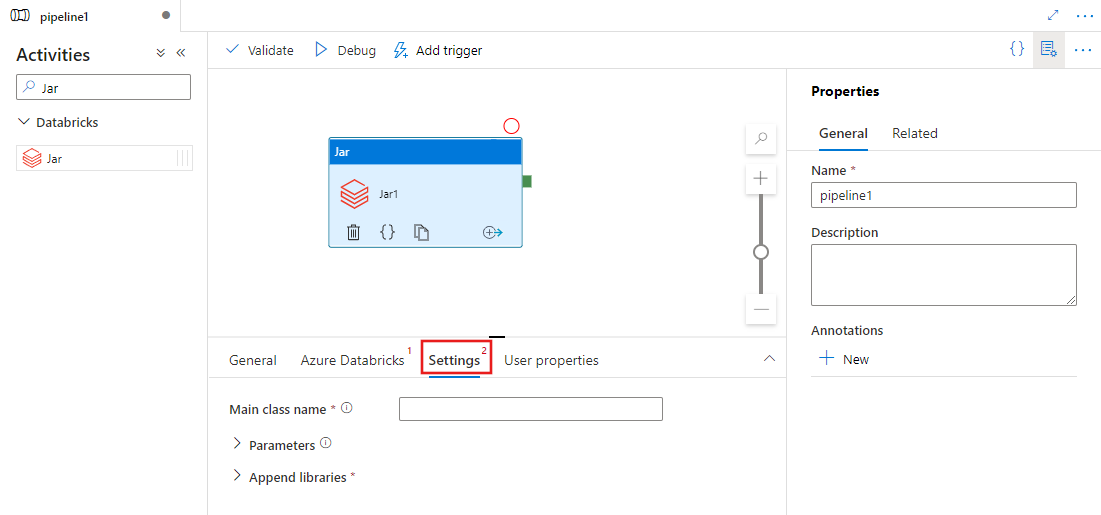
選取[設定] 索引標籤,並指定要在 Azure Databricks 上執行的類別名稱、要傳遞至 Jar 的選用參數,以及要安裝於叢集上以執行該作業的程式庫。
Databricks Jar 活動定義
以下是 Databricks Jar 活動的 JSON 定義範例:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Databricks Jar 活動屬性
下表說明 JSON 定義中使用的 JSON 屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| NAME | 管線中的活動名稱。 | Yes |
| description | 說明活動用途的文字。 | No |
| type | 若是 Databricks Jar 活動,則活動類型是 DatabricksSparkJar。 | Yes |
| linkedServiceName | Jar 活動執行所在之 Databricks 連結服務的名稱。 若要深入了解此已連結的服務,請參閱計算已連結的服務一文。 | Yes |
| mainClassName | 類別的完整名稱,該類別包含要執行的 main 方法。 這個類別必須包含在提供做為程式庫的 JAR 中。 JAR 檔案中可包含多個類別。 每一個類別都可以含有 main 方法。 | Yes |
| parameters | 將傳遞至 main 方法的參數。 此屬性為字串陣列。 | No |
| 程式庫 | 要在負責執行工作的叢集上,即將安裝的程式庫清單。 它可以是<字串, 物件>的陣列 | 是 (至少有一個包含 mainClassName 方法) |
注意
已知問題 - 使用相同的互動式叢集來執行並行 Databricks Jar 活動 (而不重新啟動叢集) 時,Databricks 有一個已知的問題,就是第 1 個活動中的參數中也會用於後續的活動中。 進而導致了將不正確的參數傳遞至後續的作業。 若要緩解此一情況,請改用作業叢集。
Databricks 活動支援的程式庫
在先前的 Databricks 活動定義中,您已指定以下的程式庫型別:jar、egg、maven、pypi、cran。
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
如需詳細資訊,請參閱 Databricks 說明文件,以了解程式庫型別。
如何在 Databricks 中上傳程式庫
您可以使用工作區 UI:
若要取得使用 UI 所新增程式庫的 dbfs 路徑,您可以使用 Databricks CLI。
使用 UI 時,Jar 程式庫通常會儲存在 dbfs: FileStore/jar。 您可以透過 CLI 來列出所有 Jar 程式庫:databricks fs ls dbfs:/FileStore/job-jars
或者,您可以使用 Databricks CLI:
使用 Databricks CLI (安裝步驟)
舉例來說,若要將 JAR 複製到 dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
相關內容
如需此功能的簡介與示範,請觀看以下片長 11 分鐘的影片。