什麼是 Databricks 連線?
注意
本文涵蓋 Databricks 連線 Databricks Runtime 13.0 和更新版本。
如需舊版 Databricks 連線 的相關信息,請參閱 Databricks 連線 For Databricks Runtime 12.2 LTS 和以下版本。
- 若要略過本文並開始立即使用適用於 Python 的 Databricks 連線,請參閱適用於 Python 的 Databricks 連線。
- 若要略過本文並開始立即使用適用於 R 的 Databricks 連線,請參閱適用於 R 的 Databricks 連線。
- 若要略過本文並開始立即使用適用於 Scala 的 Databricks 連線,請參閱適用於 Scala 的 Databricks 連線。
概觀
Databricks 連線 可讓您將熱門 IDE 連線到 Azure Databricks 叢集,例如 Visual Studio Code、PyCharm、RStudio Desktop、IntelliJ IDEA、Notebook 伺服器和其他自定義應用程式。 本文說明 Databricks 連線 的運作方式。
Databricks 連線 是 Databricks Runtime 的用戶端連結庫。 它可讓您使用 Spark API 撰寫程式代碼,並在 Azure Databricks 叢集上遠端執行程式碼,而不是在本機 Spark 工作階段中執行。
例如,當您使用 Databricks 連線 執行 DataFrame 命令spark.read.format(...).load(...).groupBy(...).agg(...).show()時,命令的邏輯表示法會傳送至在 Azure Databricks 中執行的 Spark 伺服器,以在遠端叢集上執行。
使用 Databricks 連線,您可以:
從任何 Python、R 或 Scala 應用程式執行大規模的 Spark 程式代碼。 您
import pyspark現在可以從應用程式直接執行 Spark 程式代碼,而不需要安裝任何 IDE 外掛程式或使用 Spark 提交腳本,即可從 Python、library(sparklyr)R 或import org.apache.sparkScala 的任何位置執行 Spark 程式代碼。注意
Databricks 連線 Databricks Runtime 13.0 和更新版本支援執行 Python 應用程式。 只有 Databricks Runtime 13.3 LTS 和更新版本 連線 才支援 R 和 Scala。
即使在使用遠端叢集時,也請逐步執行並偵錯 IDE 中的程式碼。
開發連結庫時會快速反覆運算。 您不需要在 Databricks 連線 中變更 Python 或 Scala 連結庫相依性之後重新啟動叢集,因為每個用戶端會話都會與叢集中的彼此隔離。
關閉閑置叢集,而不會遺失工作。 由於用戶端應用程式與叢集分離,因此不會受到叢集重新啟動或升級的影響,這通常會導致失去筆記本中定義的所有變數、RDD 和 DataFrame 物件。
針對 Databricks Runtime 13.3 LTS 和更新版本,Databricks 連線 現在建置在開放原始碼 Spark 連線 上。 Spark 連線 為 Apache Spark 引進了分離的用戶端-伺服器架構,可讓您使用 DataFrame API 與未解析的邏輯計劃作為通訊協定,對 Spark 叢集進行遠端連線。 透過此以Spark連線為基礎的「V2」架構,Databricks 連線 會變成簡單且容易使用的精簡用戶端。 Spark 連線 可以內嵌到任何地方以連線到 Azure Databricks:在 IDE、筆記本和應用程式中,允許個別使用者和合作夥伴根據 Databricks 平臺建置新的(互動式)用戶體驗。 如需Spark連線的詳細資訊,請參閱Spark連線 簡介。
Databricks 連線 會決定程式代碼執行和偵錯的位置,如下圖所示。
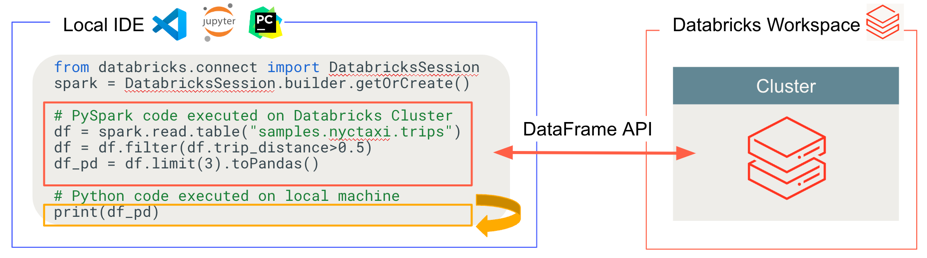
針對執行程式代碼:所有程式代碼都會在本機執行,而涉及 DataFrame 作業的所有程式代碼都會在遠端 Azure Databricks 工作區的叢集上執行,並執行回應會傳回給本機呼叫端。
針對偵錯程式代碼:所有程式代碼都會在本機偵錯,而所有Spark程式代碼都會繼續在遠端 Azure Databricks 工作區中的叢集上執行。 核心 Spark 引擎程式代碼無法直接從客戶端進行偵錯。
下一步
- 若要開始使用 Python 開發 Databricks 連線 解決方案,請從適用於 Python 的 Databricks 連線 教學課程開始。
- 若要開始使用 R 開發 Databricks 連線 解決方案,請從適用於 R 的 Databricks 連線 教學課程開始。
- 若要開始使用 Scala 開發 Databricks 連線 解決方案,請從適用於 Scala 的 Databricks 連線 教學課程開始。