2019 年 10 月
這些功能和 Azure Databricks 平臺改良功能於 2019 年 10 月發行。
注意
發行會暫存。 在初始發行日期之後的一周之前,您的 Azure Databricks 帳戶可能不會更新。
可支援性計量已移至 Azure 事件中樞
2019 年 10 月 22 日至 29 日
可讓 Azure Databricks 監視叢集健康情況的支援性計量已從 Azure Blob 記憶體移轉至事件中樞端點。 這可讓 Azure Databricks 提供較低的延遲回應來解決客戶事件。 針對 VNet 插入 工作區,我們已將額外的規則新增至服務端點的網路 EventHub 安全組。 網路安全組規則數據表中 提供詳細數據 。 服務持續可用性不需要採取任何動作。
如需依區域的 Azure Databricks 支援性計量事件中樞端點清單,請參閱 中繼存放區、成品 Blob 記憶體、系統數據表記憶體、記錄 Blob 記憶體和事件中樞端點 IP 位址。
標準叢集和 Scala 上的 Azure Data Lake 儲存體 認證傳遞為 GA
2019 年 10 月 22 日至 29 日:版本 3.5
執行 Databricks Runtime 5.5 和更新版本之標準叢集上的 Python、SQL 和 Scala 認證傳遞 ,以及 Databricks Runtime 6.0 和更新版本上的 SparkR 已正式推出。 請參閱為標準叢集啟用 Azure Data Lake 儲存體 認證傳遞。
適用於 Genomics GA 的 Databricks Runtime 6.1
2019年10月22日
適用於 Genomics 的 Databricks Runtime 6.1 已正式推出。
適用於 機器學習 GA 的 Databricks Runtime 6.1
2019年10月22日
Databricks Runtime 6.1 ML 已正式推出。 它包含 GPU 叢集的支援,以及升級至下列機器學習連結庫:
- TensorFlow 至 1.14.0
- PyTorch 至 1.2.0
- Torchvision 至 0.4.0
- MLflow 至 1.3.0
如需詳細資訊,請參閱 ML 的完整 Databricks Runtime 6.1 版本資訊。
MLflow API 呼叫現在速率有限
2019 年 10 月 22 日至 29 日:版本 3.5
為了確保負載過重的服務品質,Azure Databricks 現在會針對所有 MLflow API 呼叫強制執行 API 速率限制。 每個帳戶都會設定這些限制,以確保所有共用工作區的組織都能公平使用和高可用性。
具有自動重試的 MLflow 用戶端可在 MLflow 1.3.0 中使用,且位於適用於 ML 的 Databricks Runtime 6.1 中(不支援)。 我們建議所有客戶切換至最新的 MLflow 用戶端版本。
如需詳細資訊,請參閱 實驗 API。
快速叢集啟動的實例集區已正式推出
2019 年 10 月 22 日至 29 日:版本 3.5
現在已正式推出支援將叢集連結至預先定義閑置實例集區的 Azure Databricks 功能。
Azure Databricks 不會在集區中的實例閑置時向 DBU 收費。 實例提供者計費確實適用。 請參閱定價。
如需詳細資訊,請參閱 集區組態參考。
Databricks Runtime 6.1 GA
2019年10月16日
Databricks Runtime 6.1 為 Delta Lake 帶來數個增強功能:
- 輕鬆地將數據表轉換成 Delta Lake 格式
- Delta 數據表的 Python API (公開預覽)
- 預設會啟用動態檔案剪除 (DFP)
Databricks Runtime 6.1 也會移除認證傳遞中的數個限制。
注意
從 6.1 版開始,Databricks Runtime 僅支援 CPU 叢集。 如果您想要使用 GPU 叢集,則必須使用 Databricks Runtime ML。
如需詳細資訊,請參閱完整的 Databricks Runtime 6.1(不支援) 版本資訊。
適用於 Genomics GA 的 Databricks Runtime 6.0
2019年10月16日
適用於 Genomics 的 Databricks Runtime (Databricks Runtime Genomics) 是 Databricks Runtime 的變體,專為使用基因和生物醫學數據而優化。 從 6.0 版開始,正式推出適用於 Genomics 的 Databricks Runtime。
將 Azure Databricks 工作區部署到您自己的虛擬網路的能力,也稱為 VNet 插入,是 GA
2019年10月9日
我們很高興宣佈 GA 能夠將 Azure Databricks 工作區部署到您自己的虛擬網路,也稱為 VNet 插入。 此選項適用於需要網路自定義的使用者,因此不想使用以標準方式部署 Azure Databricks 工作區時所建立的預設 VNet。 透過 VNet 插入,您可以:
- 使用服務端點,以更安全的方式 連線 Azure Databricks 至其他 Azure 服務(例如 Azure 儲存體)。
- 連線 內部部署數據源以搭配 Azure Databricks 使用,並利用使用者定義的路由。
- 連線 Azure Databricks 至網路虛擬設備,以檢查所有輸出流量,並根據允許和拒絕規則採取動作。
- 設定 Azure Databricks 以使用自定義 DNS。
- 設定 網路安全組 (NSG) 規則 以指定輸出流量限制。
- 在現有的虛擬網路中部署 Azure Databricks 叢集。
將 Azure Databricks 部署到您自己的虛擬網路也可讓您利用彈性 CIDR 範圍(虛擬網路的 /16-/24 之間,子網最多為 /26)。
使用 Azure 入口網站 UI 的設定非常快速且簡單:當您建立工作區時,只要在 虛擬網絡 中選取 [部署 Azure Databricks 工作區],選取您的虛擬網路,併為兩個子網提供 CIDR 範圍。 Azure Databricks 會使用兩個新的子網和網路安全組來更新虛擬網路、允許存取輸入和輸出子網流量,並將工作區部署至更新的虛擬網路。
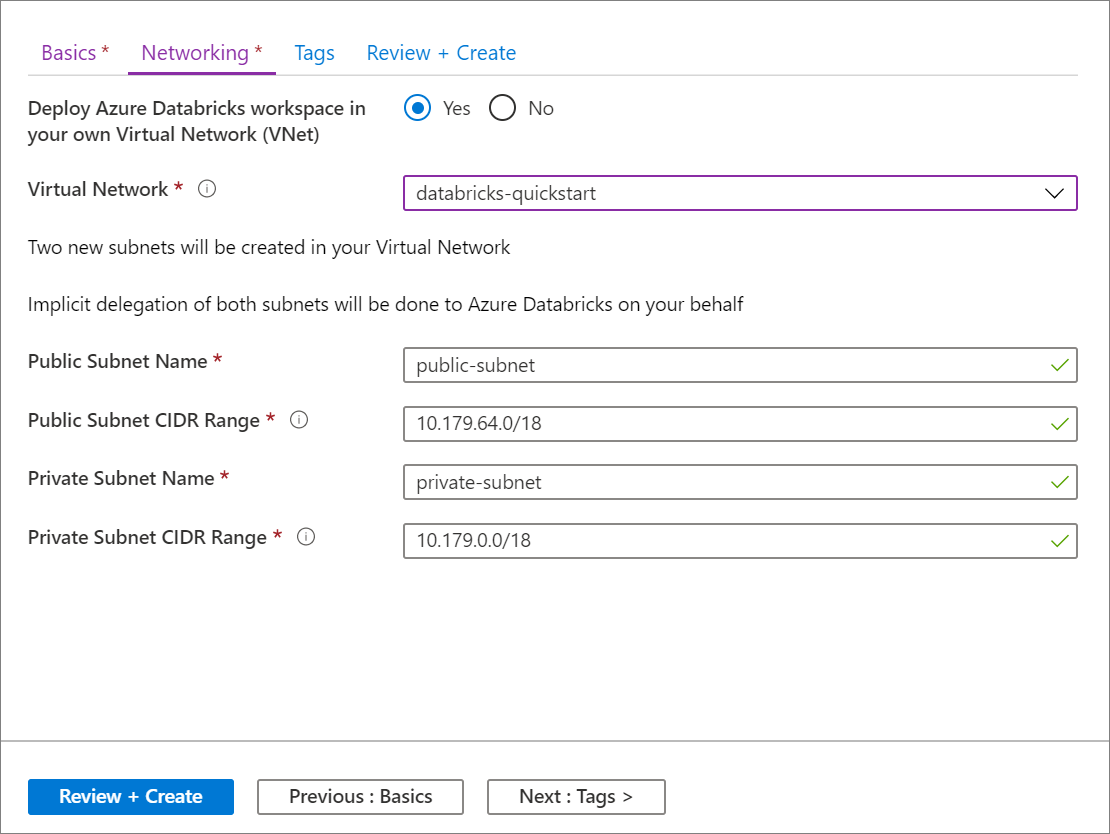
如果您想要自行設定 VNet 插入的虛擬網路,例如,您想要使用現有的子網、使用現有的網路安全組,或建立您自己的安全性規則,您可以使用 Azure-Databricks 提供的 ARM 範本 ,而不是入口網站 UI。
注意
如果您參與 VNet 插入預覽,則必須在 2020 年 1 月 31 日之前將預覽工作區升級為 GA 版本,才能繼續獲得支援。
如需詳細資訊,請參閱在 Azure 虛擬網路中部署 Azure Databricks (VNet 插入式),並將 Azure Databricks 工作區 連線 部署至內部部署網路。
非系統管理員 Azure Databricks 使用者可以使用 SCIM API 讀取使用者和組名和標識碼
2019 年 10 月 8 日至 15 日:版本 3.4
非系統管理員用戶現在可以叫 用群組 API 取得使用者和取得群組端點,只讀取使用者和群組顯示名稱和標識符。 所有其他 SCIM API 作業都會繼續要求系統管理員存取權。
工作區 API 會傳回筆記本和資料夾物件識別碼
2019 年 10 月 8 日至 15 日:版本 3.4
get-status工作區 API 的 和 list 端點現在會傳回筆記本和資料夾物件識別碼,讓您能夠在其他 API 呼叫中參考這些物件。
Databricks Runtime 6.0 ML GA
2019年10月4日
Databricks Runtime 6.0 ML 包含下列更新:
- MLflow
- MLflow 實驗的新 Spark 數據源現在提供標準 API 來載入 MLflow 實驗執行數據。
- 已新增 MLflow Java 用戶端
- MLflow 現在已升階為最上層連結庫
- Hyperopt GA - 因為公開預覽版包含對 Spark 背景工作角色的 MLflow 記錄支援、正確處理 PySpark 廣播變數,以及使用 Hyperopt 選取模型的新指南。
- 已升級 Horovod 和 MLflow 連結庫和 Anaconda 散發套件。
注意
此版本僅支援 CPU 叢集。
如需詳細資訊,請參閱 ML 的完整 Databricks Runtime 6.0 版本資訊。
新區域:巴西南部和法國中部
2019 年 10 月 1 日
Azure Databricks 現已在巴西南部(聖保羅州)和法國中部(巴黎)提供。
Databricks Runtime 6.0 GA
2019 年 10 月 1 日
Databricks Runtime 6.0 帶來許多連結庫升級和新功能,包括:
- Delta Lake DML 命令的新 Scala 和 Java API,以及真空和歷程記錄公用程式命令。
- 增強的 DBFS FUSE 用戶端,以在模型定型期間更快且更可靠的讀取和寫入。
- 支援每個筆記本數據格的多個 matplotlib 繪圖。
- 更新至 Python 3.7,以及更新 numpy、pandas、matplotlib 和其他連結庫。
- Python 2 支援的日落。
注意
此版本僅支援 CPU 叢集。
如需詳細資訊,請參閱完整的 Databricks Runtime 6.0(不支援) 版本資訊。