搭配 Apache Kafka 和 Azure Cosmos DB 使用 Apache Spark 結構化串流
瞭解如何使用 Apache Spark 結構化串流從 Azure HDInsight 上的 Apache Kafka 讀取數據,然後將數據儲存至 Azure Cosmos DB。
Azure Cosmos DB 是全域散發的多模型資料庫。 此範例使用適用於 NoSQL 的 Azure Cosmos DB 資料庫模型。 如需詳細資訊,請參閱 歡迎使用 Azure Cosmos DB 檔。
Spark 結構化串流是以 Spark SQL 為基礎的串流處理引擎。 它可讓您在靜態數據上表示與批次計算相同的串流計算。 如需結構化串流的詳細資訊,請參閱 Apache.org 的結構化串流程序設計指南 。
重要
此範例會在 HDInsight 4.0 上使用 Spark 2.4。
本檔中的步驟會建立 Azure 資源群組,其中包含 HDInsight 上的 Spark 和 HDInsight 叢集上的 Kafka。 這些叢集都位於 Azure 虛擬網絡 內,可讓 Spark 叢集直接與 Kafka 叢集通訊。
當您完成本檔中的步驟時,請記得刪除叢集以避免產生過多費用。
建立叢集
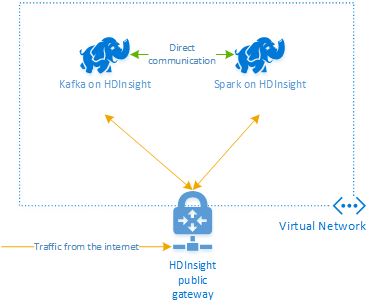
HDInsight 上的 Apache Kafka 無法透過公用因特網存取 Kafka 訊息代理程式。 與 Kafka 交談的任何專案都必須位於與 Kafka 叢集中節點相同的 Azure 虛擬網路中。 在此範例中,Kafka 和 Spark 叢集都位於 Azure 虛擬網路中。 下圖顯示叢集之間的通訊如何流動:
注意
Kafka 服務僅限於虛擬網路內的通訊。 叢集上的其他服務,例如 SSH 和 Ambari,可以透過因特網存取。 如需 HDInsight 可用公用埠的詳細資訊,請參閱 HDInsight 所使用的埠和 URI。
雖然您可以手動建立 Azure 虛擬網路、Kafka 和 Spark 叢集,但使用 Azure Resource Manager 範本會比較容易。 使用下列步驟,將 Azure 虛擬網路、Kafka 和 Spark 叢集部署到您的 Azure 訂用帳戶。
使用下列按鈕來登入 Azure,並在 Azure 入口網站 中開啟範本。

Azure Resource Manager 範本位於此專案的 GitHub 存放庫中(https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb)。
此範本會建立下列資源︰
HDInsight 4.0 叢集上的 Kafka。
HDInsight 4.0 叢集上的 Spark。
Azure 虛擬網路,其中包含 HDInsight 叢集。 範本所建立的虛擬網路會使用 10.0.0.0/16 位址空間。
適用於 NoSQL 資料庫的 Azure Cosmos DB。
重要
此範例中使用的結構化串流筆記本需要 HDInsight 4.0 上的 Spark。 如果您在 HDInsight 上使用舊版 Spark,當您使用筆記本時會收到錯誤。
使用下列資訊填入 [自訂部署] 區段上的專案:
屬性 值 訂用帳戶 選取 Azure 訂閱。 資源群組 建立群組或選取現有的群組。 此群組包含 HDInsight 叢集。 Azure Cosmos DB 帳戶名稱 此值會當做 Azure Cosmos DB 帳戶的名稱使用。 名稱只能包含小寫字母、數字及連字號 (-) 字元。 其長度必須介於 3 到 31 個字元之間。 基底叢集名稱 此值會當做 Spark 和 Kafka 叢集的基底名稱使用。 例如,輸入 myhdi 會建立名為 spark-myhdi 的 Spark 叢集,以及名為 kafka-myhdi 的 Kafka 叢集。 叢集版本 HDInsight 叢集版本。 此範例會使用 HDInsight 4.0 進行測試,而且可能無法與其他叢集類型搭配使用。 叢集登入使用者名稱 Spark 和 Kafka 叢集的管理員用戶名稱。 叢集登入密碼 Spark 和 Kafka 叢集的管理員用戶密碼。 SSH 使用者名稱 要為Spark和 Kafka 叢集建立的 SSH 使用者。 SSH 密碼 Spark 和 Kafka 叢集的 SSH 用戶密碼。 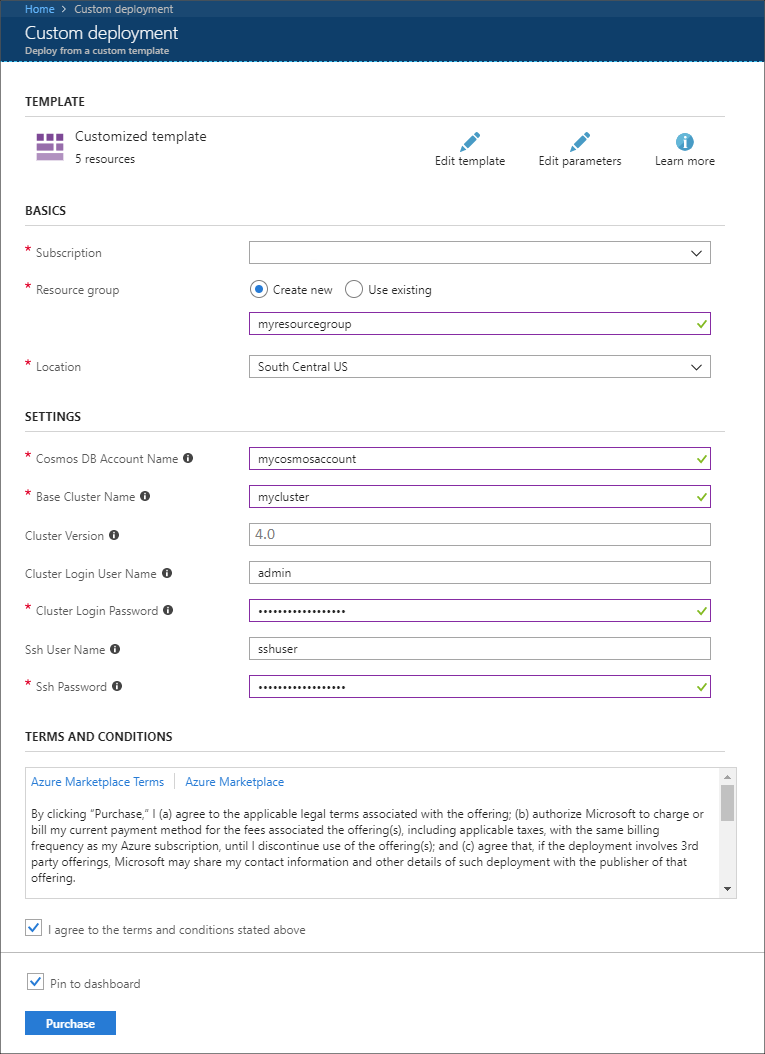
閱讀 [條款與條件],然後選取 [我同意以上所述的條款及條件]。
最後,選取 [ 購買]。 建立叢集、虛擬網路和 Azure Cosmos DB 帳戶最多可能需要 45 分鐘的時間。
建立 Azure Cosmos DB 資料庫和集合
本檔中使用的專案會將數據儲存在 Azure Cosmos DB 中。 在執行程式代碼之前,您必須先在 Azure Cosmos DB 實例中建立 資料庫 和 集合 。 您也必須擷取檔端點,以及 用來驗證對 Azure Cosmos DB 的要求的金鑰 。
其中一種方法是使用 Azure CLI。 下列腳本會建立名為 kafkadata 的資料庫,以及名為的 kafkacollection集合。 然後,它會傳回主鍵。
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
檔案端點與主鍵資訊類似下列文字:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
重要
儲存端點和索引鍵值,因為 Jupyter Notebook 中需要這些值。
取得筆記本
本檔中所述範例的程式代碼可在取得 https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb。
上傳筆記本
使用下列步驟,將筆記本從專案上傳至 HDInsight 叢集上的 Spark:
在網頁瀏覽器中,連線到Spark叢集上的 Jupyter Notebook。 在下列 URL 中,將 取代
CLUSTERNAME為您的 Spark 叢集名稱:https://CLUSTERNAME.azurehdinsight.net/jupyter出現提示時,請輸入您在建立叢集時所使用的叢集登入 (admin) 和密碼。
從頁面右上方,使用 [上傳] 按鈕將 Stream-taxi-data-to-kafka.ipynb 檔案上傳至叢集。 選取 [ 開啟 ] 以開始上傳。
在筆記本清單中尋找 Stream-taxi-data-to-kafka.ipynb 專案,然後選取其旁邊的 [上傳] 按鈕。
重複步驟 1-3 以載入 Stream-data-from-Kafka-to-Cosmos-DB.ipynb Notebook。
將計程車數據載入 Kafka
上傳檔案之後,請選取 Stream-taxi-data-to-kafka.ipynb 專案以開啟筆記本。 請遵循筆記本中的步驟將數據載入 Kafka。
使用 Spark 結構化串流處理計程車數據
從 Jupyter Notebook 首頁,選取 Stream-data-from-Kafka-to-Cosmos-DB.ipynb 專案。 請遵循筆記本中的步驟,使用 Spark 結構化串流將數據從 Kafka 和串流至 Azure Cosmos DB。
下一步
既然您已瞭解如何使用 Apache Spark 結構化串流,請參閱下列檔以深入瞭解使用 Apache Spark、Apache Kafka 和 Azure Cosmos DB:
- 如何搭配 Apache Kafka 使用 Apache Spark 串流 (DStream)。
- 從 HDInsight 上的 Jupyter Notebook 和 Apache Spark 開始
- 歡迎使用 Azure Cosmos DB