使用 Apache Hive 作為擷取、 轉換和載入 (ETL) 工具
您通常需要先將傳入的資料清理並轉換,才能將它載入至適合進行分析的目的地。 擷取、轉換和載入 (ETL) 作業可用來準備資料並將其載入至資料目的地。 HDInsight 上的 Apache Hive 可以讀入非結構化資料、視需要處理該資料,然後將該資料載入至關聯式資料倉儲以供決策支援系統使用。 在此方法中,資料會從來源擷取。 然後儲存在可調整的儲存體中,例如 Azure 儲存體 Blob 或Azure Data Lake Storage。 然後,資料會使用 Hive 查詢序列進行轉換。 Hive 內的暫存資料會準備大量載入至目的地資料存放區。
使用案例和模型概觀
下圖提供 ETL 自動化使用案例和模型的概觀。 輸入資料會經過轉換來產生適當的輸出。 在轉換期間,資料會變更形狀、資料類型,甚至是語言。 ETL 程序可以將英制轉換成公制、變更時區及提升精準度,來與目的地中現有的資料正確相符。 ETL 程序也可以將新資料與現有資料結合以更新報告,或是提供現有資料的更深入解析。 接著,應用程式 (例如報告工具和服務) 便能以想要的格式取用此資料。
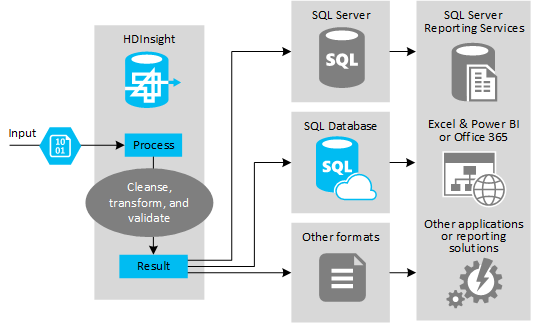
通常在會匯入大量文字檔 (例如 CSV) 的 ETL 程序中會使用 Hadoop。 或較小但經常變更的文字檔數目,或兩者。 Hive 是一個絕佳的工具,可在將資料載入至資料目的地前,先備妥資料。 Hive 可讓您在 CSV 上建立結構描述,然後使用類似 SQL 的語言來產生與資料互動的 MapReduce 程式。
使用 Hive 來執行 ETL 的一般步驟如下:
將資料載入至 Azure Data Lake Storage 或 Azure Blob 儲存體。
建立「中繼資料存放區」資料庫 (使用 Azure SQL Database) 供 Hive 用來儲存結構描述。
建立 HDInsight 叢集並連接資料存放區。
定義要在讀取階段套用至資料存放區中資料的結構描述:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';轉換資料並將其載入至目的地。 在轉換和載入期間,有數種使用 Hive 的方式:
- 使用 Hive 來查詢和準備資料,然後將其以 CSV 形式儲存在 Azure Data Lake Storage 或 Azure Blob 儲存體中。 接著,使用工具 (例如 SQL Server Integration Services (SSIS)) 來取得這些 CSV,然後將資料載入至目的地關聯式資料庫 (例如 SQL Server)。
- 使用 Hive ODBC 驅動程式直接從 Excel 或 C# 查詢資料。
- 使用 Apache Sqoop 來讀取已備妥的一般 CSV 檔案,然後將其載入至目的地關聯式資料庫。
資料來源
資料來源通常是可與資料存放區中現有資料進行比對的外部資料,例如:
- 社交媒體資料、記錄檔、感應器,以及會產生資料檔的應用程式。
- 從資料提供者取得的資料集,例如天氣統計資料或廠商銷售數字。
- 透過適當的工具或架構來擷取、篩選及處理的資料。
輸出目標
您可以使用 Hive 將資料輸出至各種類型的目標,包括:
- 關聯式資料庫,例如 SQL Server 或 Azure SQL Database。
- 資料倉儲,例如 Azure Synapse Analytics。
- Excel。
- Azure 資料表和 Blob 儲存體。
- 要求將資料處理成特定格式或處理成包含特定類型之資訊結構的應用程式或服務。
- JSON 文件存放區,例如 Azure Cosmos DB。
考量
通常在您想要執行下列操作時,會使用 ETL 模型:
* 將資料流資料或大量半結構化或非結構化資料,從外部來源載入至現有的資料庫或資訊系統。
* 在載入資料之前,也許透過叢集使用多個轉換階段先清理、轉換及驗證資料。
* 產生定期更新的報表和視覺效果。 例如,如果在日間產生報表耗時太長,您可以排定在夜間執行報表。 若要自動執行 Hive 查詢,您可以使用 Azure Logic Apps 和 PowerShell。
如果資料的目標不是資料庫,則您可以在查詢中以適當的格式 (例如 CSV) 產生檔案。 接著,便可將此檔案匯入至 Excel 或 Power BI。
如果您需要在 ETL 程序中對資料執行數個作業,請考量要如何管理它們。 作業由外部程式來控制,並非以解決方案內的工作流程來控制作業,從而判斷某些作業是否可以平行執行。 以及偵測每個作業完成的時間。 與使用外部指令碼或自訂程式來嘗試協調一系列作業相比,使用工作流程機制 (例如 Hadoop 內的 Oozie) 可能較簡單。