針對 HDInsight 叢集上速度變慢或失敗的作業進行疑難排解
如果 HDInsight 叢集上的應用程式處理資料執行速度變慢或失敗並出現錯誤碼,有數個疑難排解選項可供您選擇。 如果您的作業執行時間超出預期,或通常回應時間都較慢,就可能是叢集上游 (例如叢集執行所在的服務) 發生失敗。 不過,這些變慢情況的最常見原因是規模調整不足。 當您建立新的 HDInsight 叢集時,請選取適當的虛擬機器大小。
若要診斷速度變慢或失敗的叢集,請收集該環境所有方面的相關資訊,例如關聯的 Azure 服務、叢集設定及作業執行資訊。 其中一種實用的診斷方式是嘗試在另一個叢集上重現錯誤狀態。
- 步驟 1:收集問題的相關資料。
- 步驟 2:驗證 HDInsight 叢集環境。
- 步驟 3:檢視叢集健康情況。
- 步驟 4:檢閱環境堆疊和版本。
- 步驟 5:檢查叢集記錄檔。
- 步驟 6:檢查組態設定。
- 步驟 7:在不同的叢集上重現失敗情況。
步驟 1:收集問題的相關資料
HDInsight 提供許多工具,可供您用來識別叢集相關問題並進行疑難排解。 下列步驟將引導您完成這些工具的程序,並會提供建議來指出問題所在。
識別問題
為了協助您識別問題,請思考一下下列問題:
- 預期會發生什麼情況? 相反地,發生了什麼情況?
- 程序的執行時間有多長? 程序的執行時間應該有多長?
- 我的工作是否在此叢集上總是執行速度很慢? 這些工作是否在其他叢集上執行速度較快?
- 第一次發生此問題是在何時? 之後的發生頻率為何?
- 我的叢集組態是否有任何變更?
叢集詳細資料
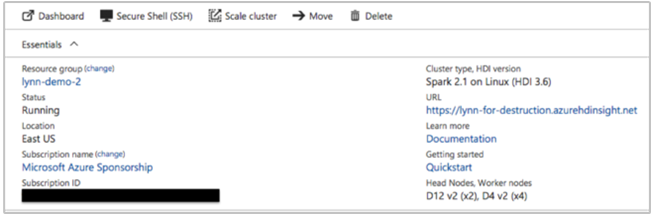
重要的叢集資訊包括:
- 叢集名稱。
- 叢集區域 - 查看區域中斷狀況。
- HDInsight 叢集類型和版本。
- 為前端節點和背景工作節點指定的 HDInsight 執行個體類型和數目。
Azure 入口網站可以提供以下資訊:
您也可以使用 Azure CLI:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
另一個選項是使用 PowerShell。 如需詳細資訊,請參閱使用 Azure PowerShell 來管理 HDInsight 中的 Apache Hadoop 叢集。
步驟 2:驗證 HDInsight 叢集環境
每個 HDInsight 叢集都倚賴各種 Azure 服務,以及倚賴開放原始碼軟體,例如 Apache HBase 和 Apache Spark。 HDInsight 叢集也可以呼叫其他 Azure 服務,例如 Azure 虛擬網路。 造成叢集失敗的有可能是您叢集上任何執行中的服務,也可能是外部服務。 叢集服務設定變更也可能導致叢集發生失敗。
服務詳細資料
- 檢查開放原始碼程式庫發行版本。
- 檢查 Azure 服務中斷。
- 查看 Azure 服務使用限制。
- 檢查 Azure 虛擬網路子網路設定。
使用 Ambari UI 來檢視叢集組態設定
Apache Ambari 可讓您透過 Web UI 和 REST API 來管理和監視 HDInsight 叢集。 以 Linux 為基礎的 HDInsight 叢集會隨附 Ambari。 請在 Azure 入口網站 HDInsight 頁面上,選取 [叢集儀表板] 窗格。 選取 [HDInsight 叢集儀表板] 窗格以開啟 Ambari UI,然後輸入叢集登入認證。

若要開啟服務檢視清單,請在 Azure 入口網站頁面上選取 [Ambari 檢視]。 此清單會依所安裝的程式庫而有所不同。 例如,您可能會看到 [YARN 佇列管理員]、[Hive 檢視] 及 [Tez 檢視]。 請選取一個服務連結來查看設定和服務資訊。
檢查 Azure 服務中斷
HDInsight 倚賴數個 Azure 服務。 它會在 Azure HDInsight 上執行虛擬伺服器、在 Azure Blob 儲存體或 Azure Data Lake Storage 上儲存資料和指令碼,以及在「Azure 資料表」儲存體中編製記錄檔索引。 這些服務的中斷可能導致 HDInsight 發生問題,但此情況相當罕見。 如果叢集發生非預期的速度變慢或失敗情況,請檢查 Azure 狀態儀表板。 此儀表板會依區域列出每個服務的狀態。 請檢查您叢集的區域,並一併檢查所有相關服務的區域。
檢查 Azure 服務使用限制
如果您要啟動一個大型叢集,或是已同時啟動許多叢集,則在超出 Azure 服務限制時,叢集就可能發生失敗。 服務限制會依您的 Azure 訂用帳戶而有所不同。 如需詳細資訊,請參閱 Azure 訂用帳戶和服務限制、配額與條件約束。 您可以透過 Resource Manager 核心配額增加要求,要求 Microsoft 增加可用的 HDInsight 資源 (例如 VM 核心和 VM 執行個體) 數目。
檢查發行版本
將叢集版本與最新的 HDInsight 發行版本做比較。 每個 HDInsight 發行版本都包含改進功能,例如新應用程式、功能、修補程式及 Bug 修正。 在最新的發行版本中可能已修正影響您叢集的問題。 可能的話,請使用最新版的 HDInsight 和相關程式庫 (例如 Apache HBase、Apache Spark 等) 來重新執行您的叢集。
重新啟動您的叢集服務
如果您的叢集發生速度變慢的情況,請考慮透過 Ambari UI 或 Azure 傳統 CLI 來重新啟動服務。 叢集可能是發生暫時性錯誤,而重新啟動是可穩定您環境的最快方式,並且可能改善效能。
步驟 3:檢視叢集健康情況
HDInsight 叢集是由在虛擬機器執行個體上執行的各種不同類型節點所組成。 您可以監視每個節點的資源耗盡狀況、網路連線問題,以及其他可能導致叢集速斷變慢的問題。 每個叢集都包含兩個前端節點,而且大多數叢集類型都包含背景工作節點與邊緣節點的組合。
如需每個叢集類型所使用之各種節點的說明,請參閱使用 Apache Hadoop、 Apache Spark、 Apache Kafka 等在 HDInsight 中設定叢集。
下列各節將說明如何檢查每個節點及叢集整體的健康情況。
使用 Ambari UI 儀表板來簡要了解叢集健康情況
Ambari UI 儀表板 (https://<clustername>.azurehdinsight.net) 會提供叢集健康情況概觀,例如執行時間、記憶體、網路與 CPU 使用狀況、HDFS 磁碟使用況狀等。 請使用 Ambari 的 [Hosts] \(主機\) 區段來檢視主機層級的資源。 您也可以將服務停止和重新啟動。
檢查您的 WebHCat 服務
Apache Hive、Apache Pig 或 Apache Sqoop 作業發生失敗的其中一個常見案例是 WebHCat (或 Templeton) 服務發生失敗。 WebHCat 是一個用於執行遠端作業 (例如 Hive、Pig、Scoop 及 MapReduce) 的 REST 介面。 WebHCat 會將作業提交要求轉譯成 Apache Hadoop YARN 應用程式,然後傳回從 YARN 應用程式狀態衍生的狀態。 下列各節說明常見的 WebHCat HTTP 狀態碼。
BadGateway (502 狀態碼)
此程式碼是來自閘道節點的一般訊息,是最常見的失敗狀態碼。 此狀況的其中一個可能原因是的 WebHCat 服務在作用中的前端節點上停止運作。 若要檢查是否有此可能性,請使用下列 CURL 命令:
curl -u admin:{HTTP PASSWD} https://{CLUSTERNAME}.azurehdinsight.net/templeton/v1/status?user.name=admin
Ambari 會顯示警示,當中會指出 WebHCat 服務停止運作的主機。 您可以嘗試在 WebHCat 服務的主機上重新啟動此服務來讓此服務恢復運作。

如果 WebHCat 伺服器仍然未恢復運作,則請查看作業記錄是否有失敗訊息。 如需更多詳細資訊,請查看節點上所參考的 stderr 和 stdout 檔案。
WebHCat 逾時
「HDInsight 閘道」會讓花費時間超出兩分鐘的回應逾時,並傳回 502 BadGateway。 WebHCat 會查詢 YARN 服務來了解作業狀態,如果 YARN 的回應時間超出兩分鐘,該要求就會逾時。
在此情況下,請檢閱 /var/log/webhcat 目錄中的下列記錄:
- webhcat.log 是伺服器寫入記錄的 log4j 記錄
- webhcat-console.log 是伺服器啟動時的 stdout
- webhcat-console-error.log 是伺服器處理序的 stderr
注意
每個 webhcat.log 會每天變換,其中會產生名為 webhcat.log.YYYY-MM-DD 的檔案。 請針對您要調查的時間範圍,選取適當的檔案。
下列各節將說明一些可能的 WebHCat 逾時原因。
WebHCat 層級的逾時
當 WebHCat 負載過低時 (開啟的通訊端超過 10 個),會花費較長的時間建立新的通訊端連線,進而導致逾時。 若要列出連入或連出 WebHCat 的網路連線,請在目前作用中的前端節點上使用 netstat:
netstat | grep 30111
30111 是 WebHCat 進行接聽的連接埠。 開啟的通訊埠數目應該少於 10 個。
如果沒有任何開啟的通訊埠,上述命令就不會產生結果。 若要檢查 Templeton 是否已啟動並在連接埠 30111 上進行監聽,請使用:
netstat -l | grep 30111
YARN 層級的逾時
Templeton 會呼叫 YARN 來執行作業,而 Templeton 與 YARN 之間的通訊可能造成逾時。
在 YARN 層級,有兩種類型的逾時:
提交 YARN 作業所花費的時間可能足以造成逾時。
如果您開啟
/var/log/webhcat/webhcat.log記錄檔並搜尋 "queued job",可能會看到多個執行時間過長 (>2000 毫秒) 的項目,其中會有項目顯示等候時間增加。佇列作業的時間會持續增加,因為提交新作業的速率高於完成舊作業的速率。 一旦 YARN 記憶體的使用率達到 100%,joblauncher 佇列便無法再從預設佇列借用容量。 因此,joblauncher 佇列會無法再接受新的作業。 此行為會導致等候時間變得越來越長,除了造成逾時錯誤之外,後面通常也會跟著許多其他錯誤。
下圖顯示已達 714.4% 過度使用情況的 joblauncher 佇列。 如果預設佇列仍有可用容量可供借用,此情況是可接受的。 不過,當叢集使用率已滿載且 YARN 記憶體容量已達 100% 時,新作業就必須等候,最終就會造成逾時。

有兩個方法可以解決此問題:減緩提交新作業的速度,或是擴大叢集規模來加快消耗舊作業的速度。
YARN 處理可能需要花費很長的時間,進而可能造成逾時。
列出所有作業:這是一個相當費時的呼叫。 此呼叫會列舉來自 YARN ResourceManager 的應用程式,並針對每個已完成的應用程式,從 YARN JobHistoryServer 取得狀態。 當作業數量較多時,此呼叫便可能逾時。
列出超過 7 天的作業:HDInsight YARN JobHistoryServer 已設定為保留已完成的工作資訊長達 7 天 (
mapreduce.jobhistory.max-age-ms值)。 嘗試列舉已清除的作業會造成逾時。
診斷這些問題:
- 判斷要進行疑難排解的 UTC 時間範圍
- 選取適當的
webhcat.log檔案 - 尋找該期間內的 WARN 和 ERROR 訊息
其他 WebHCat 失敗
HTTP 狀態碼 500
在 WebHCat 傳回 500 的大多數情況下,錯誤訊息會包含有關失敗的詳細資料。 否則,請瀏覽
webhcat.log來尋找 WARN 和 ERROR 訊息。作業失敗
有可能發生與 WebHCat 的互動成功但作業卻失敗的情況。
Templeton 會將作業主控台輸出以
stderr的形式收集在statusdir中,這通常對疑難排解相當有用。stderr會包含實際查詢的 YARN 應用程式識別碼。
步驟 4:檢閱環境堆疊和版本
Ambari UI [Stack and Version] \(堆疊與版本\) 頁面會提供有關叢集服務組態與服務版本歷程記錄的資訊。 Hadoop 服務程式庫版本如果不正確,可能會導致叢集發生失敗。 在 Ambari UI 中,選取 [Admin] \(系統管理\) 功能表,然後選取 [Stack and Version] \(堆疊與版本\)。 選取頁面上的 [Versions] \(版本\) 索引標籤以查看服務版本資訊:

步驟 5:檢查記錄檔
從組成 HDInsight 叢集的眾多服務和元件會產生許多類型的記錄。 先前已說明過 WebHCat 記錄檔。 此外,還有數種其他實用的記錄檔,可供您調查來縮小叢集相關問題的範圍,如以下各節所述。
HDInsight 叢集是由數個節點所組成,大多數都負有執行所提交作業的任務。 作業會以並行方式執行,但記錄檔只能以線性方式顯示結果。 HDInsight 會執行新工作,其中會先終止其他無法完成的工作。 此活動全部都會記錄到
stderr和syslog檔案中。指令碼動作記錄檔會顯示在叢集建立過程中發生的錯誤或非預期的組態變更。
Hadoop 步驟記錄會識別與包含錯誤的步驟一併啟動的 Hadoop 作業。
檢查指令碼動作記錄
HDInsight 指令碼動作會以手動方式或在指定時,於叢集上執行指令碼。 例如,指令碼動作可用來在叢集上安裝額外的軟體,或是更改組態設定的預設值。 檢查指令碼動作記錄可讓您深入了解進行叢集設定和組態時所發生的錯誤。 您可以透過選取 Ambari UI 中的 [ops] 按鈕,或是從預設儲存體帳戶存取記錄,來檢視指令碼動作的狀態。
指令碼動作記錄位於 \STORAGE_ACCOUNT_NAME\DEFAULT_CONTAINER_NAME\custom-scriptaction-logs\CLUSTER_NAME\DATE 目錄中。
使用 Ambari 快速連結來檢視 HDInsight 記錄
HDInsight Ambari UI 包含一些 [Quick Links] \(快速連結\) 區段。 若要存取您 HDInsight 叢集中特定服務的記錄連結,請開啟叢集的 Ambari UI,然後從左邊的清單中選取服務連結。 依序選取 [Quick Links] \(快速連結\) 下拉式清單、感興趣的 HDInsight 節點,然後選取其相關記錄的連結。
例如,針對 HDFS 記錄:

檢視 Hadoop 產生的記錄檔
HDInsight 叢集會產生寫入至 Azure 資料表和 Azure Blob 儲存體的記錄。 YARN 會建立自己的執行記錄。 如需詳細資訊,請參閱管理 HDInsight 叢集的記錄。
檢閱堆積傾印
堆積傾印含有應用程式記憶體的快照,其中包括當時的變數值,這對診斷在執行階段發生的問題來說,相當有用。 如需詳細資訊,請參閱在以 Linux 為基礎的 HDInsight 上啟用 Apache Hadoop 服務的堆積傾印。
步驟 6:檢查組態設定
HDInsight 叢集已針對相關服務 (例如 Hadoop、Hive、HBase 等) 預先設定好預設設定。 視叢集的類型、其硬體組態、其節點數目、您要執行的作業類型和要搭配運作的資料 (以及資料的處理方式) 而定,您可能需要將組態最佳化。
如需將大部分案例的效能組態最佳化的詳細指示,請參閱使用 Apache Ambari 將叢集組態最佳化。 使用 Spark 時,請參閱最佳化 Apache Spark 作業的效能。
步驟 7:在不同的叢集上重現失敗情況
若要協助診斷叢集錯誤的來源,請啟動一個具有相同組態的新叢集,然後逐一重新提交失敗作業的步驟。 請先查看每個步驟的結果,再繼續進行下一個步驟。 這個方法可讓您有機會更正並重新執行單一的失敗步驟。 這個方法還有一個優點,就是只需載入您的輸入資料一次。
- 建立一個組態與失敗叢集相同的新測試叢集。
- 向測試叢集提交第一個作業步驟。
- 當步驟完成處理時,查看步驟記錄檔中是否有錯誤。 請連線至測試叢集的主要節點,並檢視該處的記錄檔。 只有在步驟已執行一段時間、結束或失敗之後,步驟記錄檔才會出現。
- 如果第一個步驟成功,請執行下一個步驟。 如果有錯誤,請調查記錄檔中的錯誤。 如果是您的程式碼出錯,請進行更正,然後重新執行該步驟。
- 繼續執行,直到所有步驟都已執行且沒有錯誤為止。
- 完成對測試叢集的偵錯之後,請將其刪除。