教學課程:使用 IntelliJ 在 HDInsight 中建立 Apache Spark 的 Scala Maven 應用程式
在本教學課程中,您將瞭解如何使用 Apache Maven 搭配 IntelliJ IDEA 建立以 Scala 撰寫的 Apache Spark 應用程式。 本文使用 Apache Maven 作為建置系統。 從 IntelliJ IDEA 所提供的 Scala 的現有 Maven 原型開始。 在 IntelliJ IDEA 中建立 Scala 應用程式牽涉到下列步驟:
- 使用 Maven 作為建置系統。
- 更新 Project 物件模型 (POM) 檔案以解析 Spark 模組相依性。
- 在 Scala 撰寫您的應用程式。
- 產生可提交至 HDInsight Spark 叢集的 jar 檔案。
- 使用 Livy 在 Spark 叢集上執行應用程式。
在本教學課程中,您會了解如何:
- 安裝 IntelliJ IDEA 的 Scala 外掛程式
- 使用 IntelliJ 開發 Scala Maven 應用程式
- 建立獨立 Scala 專案
必要條件
HDInsight 上的 Apache Spark 叢集。 如需指示,請參閱在 Azure HDInsight 中建立 Apache Spark 叢集。
Oracle Java 開發工具包。 本教學課程使用 Java 8.0.202 版。
Java IDE。 本文使用 IntelliJ IDEA Community 2018.3.4。
適用於 IntelliJ 的 Azure 工具組。 請參閱 安裝適用於 IntelliJ 的 Azure 工具組。
安裝 IntelliJ IDEA 的 Scala 外掛程式
請執行下列步驟來安裝 Scala 外掛程式:
開啟 IntelliJ IDEA。
在歡迎畫面上,流覽至 [設定>外掛程式] 以開啟 [外掛程式] 視窗。
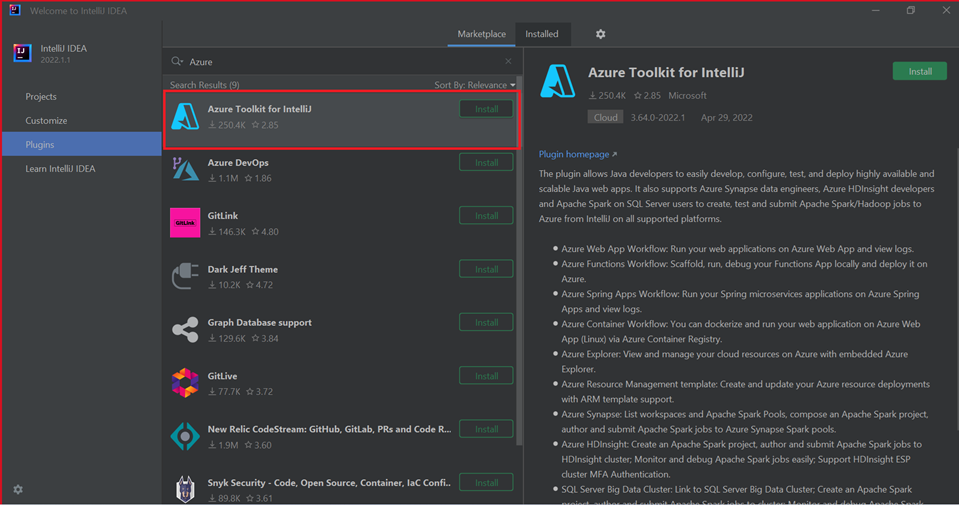
選取 [安裝 適用於 IntelliJ 的 Azure 工具組]。
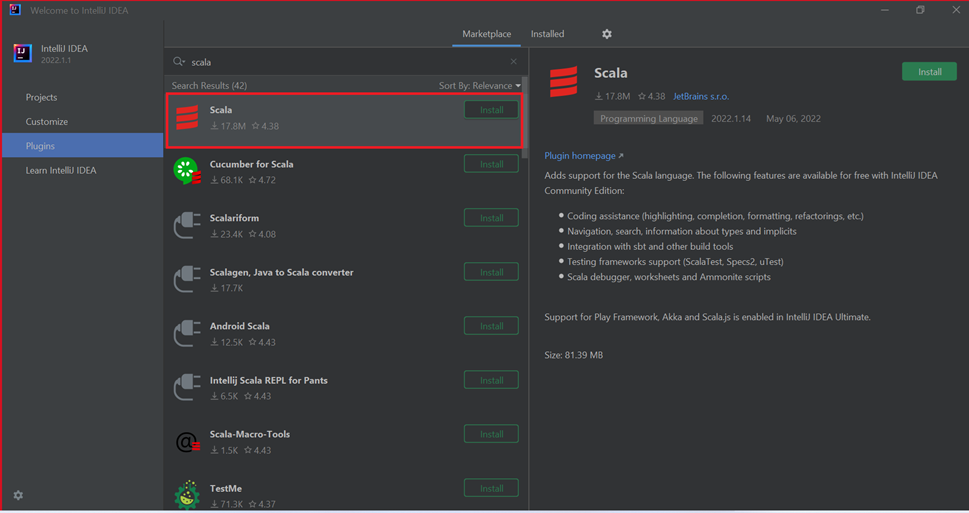
針對新視窗中精選的 Scala 外掛程式,選取 [安裝 ]。
外掛程式安裝成功之後,您必須重新啟動 IDE。
使用 IntelliJ 建立應用程式
啟動 IntelliJ IDEA,然後選取 [ 建立新專案 ] 以開啟 [ 新增專案 ] 視窗。
從左窗格中選取 [Apache Spark/HDInsight ]。
從主視窗中選取 [Spark 專案] [Scala ]。
從 [ 建置工具 ] 下拉式清單中,選取下列其中一個值:
- 適用於 Scala 專案建立精靈的 Maven 支援。
- 用於管理 Scala 專案的相依性和建置的 SBT 。
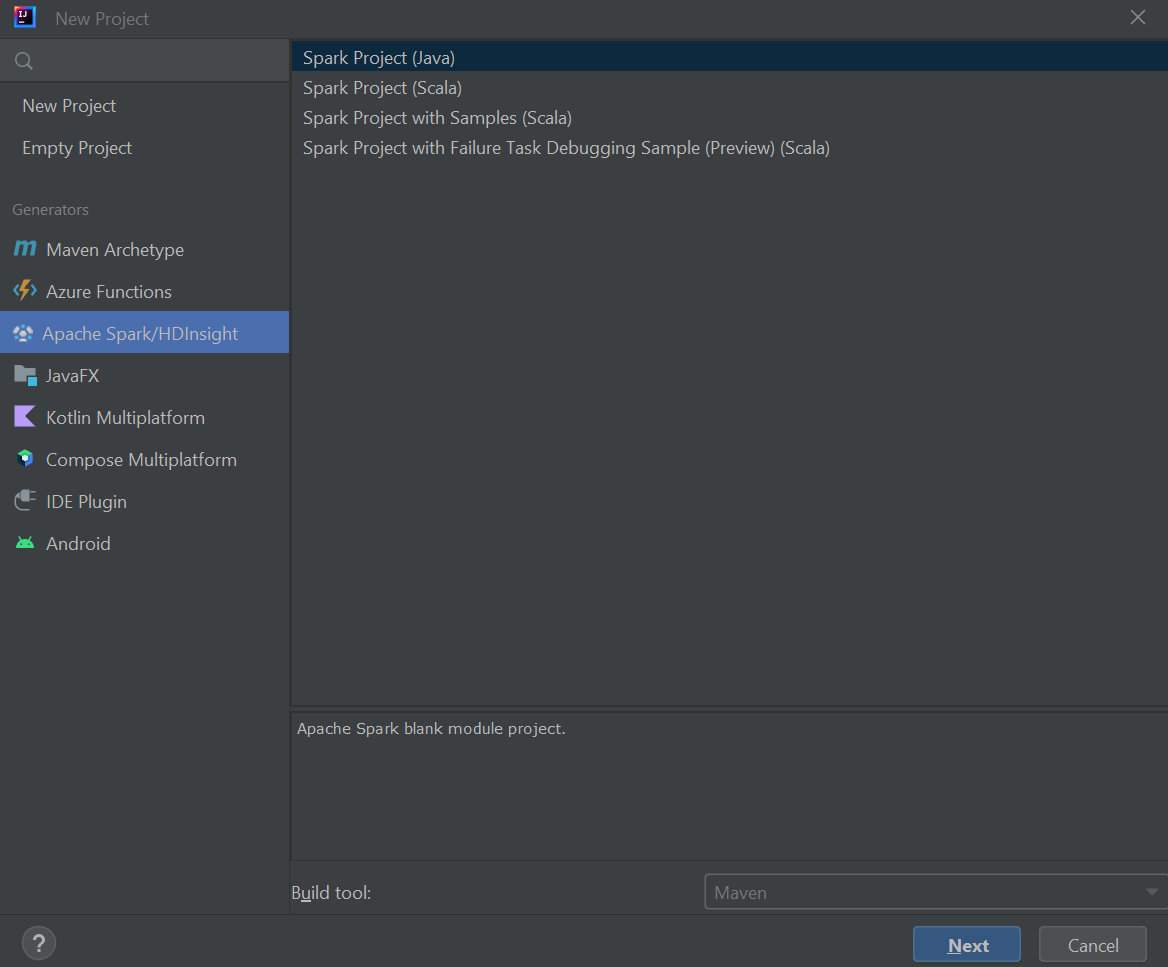
選取 [下一步]。
在 [ 新增專案] 視窗中,提供下列資訊:
屬性 說明 專案名稱 輸入名稱。 專案位置 輸入儲存專案的位置。 專案 SDK 第一次使用 IDEA 時,此字段將會是空白的。 選取 [ 新增... ],然後瀏覽至您的 JDK。 Spark 版本 建立精靈會整合 Spark SDK 和 Scala SDK 的適當版本。 如果 Spark 叢集版本早於 2.0,請選取 [Spark 1.x] 。 否則,請選取 [Spark 2.x] 。 此範例使用Spark 2.3.0 (Scala 2.11.8)。 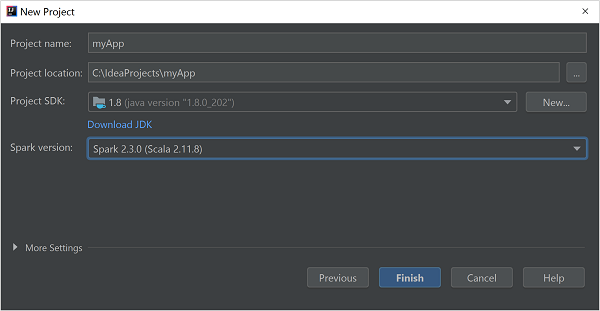
選取 [完成]。
建立獨立 Scala 專案
啟動 IntelliJ IDEA,然後選取 [ 建立新專案 ] 以開啟 [ 新增專案 ] 視窗。
從左窗格中選取 [Maven ]。
指定 Project SDK。 如果空白,請選取 [ 新增... ],然後流覽至 Java 安裝目錄。
選取 [ 從原型 建立] 複選框。
從原型清單中,選取
org.scala-tools.archetypes:scala-archetype-simple。 此原型會建立正確的目錄結構,並下載必要的預設相依性來撰寫 Scala 程式。
選取 [下一步]。
展開 [成品座標]。 提供 GroupId 和 ArtifactId 的相關值。 名稱和位置將會自動填入。 本教學課程會使用下列值:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
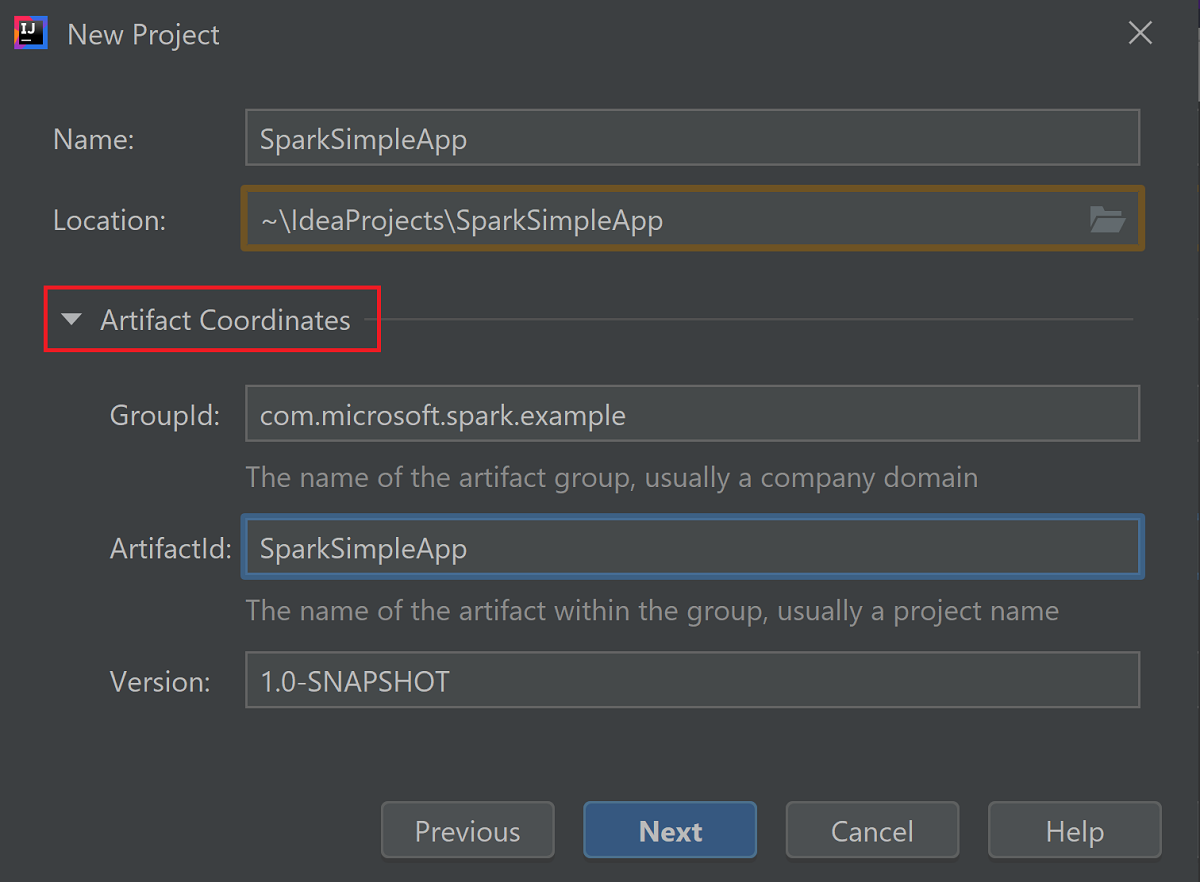
選取 [下一步]。
確認設定,然後選取 [ 下一步]。
確認項目名稱和位置,然後選取 [ 完成]。 專案需要幾分鐘的時間才能匯入。
匯入項目之後,從左窗格流覽至 SparkSimpleApp>src>測試>scala>com>microsoft>spark>範例。 以滑鼠右鍵按兩下 [MySpec],然後選取 [ 刪除...]。您不需要此檔案供應用程式使用。 在對話框中選取 [ 確定 ]。
在後續步驟中 ,您會更新 pom.xml ,以定義Spark Scala 應用程式的相依性。 若要自動下載和解析這些相依性,您必須設定 Maven。
從 [檔案] 選單中,選取 [設定] 以開啟 [設定] 視窗。
從 [設定] 視窗中,流覽至 [建置]、[執行]、[部署>建置工具>Maven>匯入]。
選取 [自動匯入 Maven 專案] 複選框。
選取套用,然後選取確定。 接著,您將返回項目視窗。
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::從左窗格中,流覽至 src>main>scala>com.microsoft.spark.example,然後按兩下 [應用程式] 以開啟 App.scala。
以下列程式代碼取代現有的範例程式代碼,並儲存變更。 此程式代碼會從HVAC.csv讀取數據(適用於所有 HDInsight Spark 叢集)。 擷取第六個數據行中只有一位數的數據列。 並將輸出寫入叢 集預設記憶體容器下的 /HVACOut 。
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }在左窗格中,按兩下 pom.xml。
在 中
<project>\<properties>新增下列區段:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>在 中
<project>\<dependencies>新增下列區段:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.建立.jar檔案。 IntelliJ IDEA 可讓您建立 JAR 作為專案的成品。 請執行下列步驟。
從 [ 檔案] 功能表中,選取 [項目結構...]。
從 [項目結構] 視窗中,流覽至 [成品>] 加號 +>JAR>[來自具有相依性的模組...]。
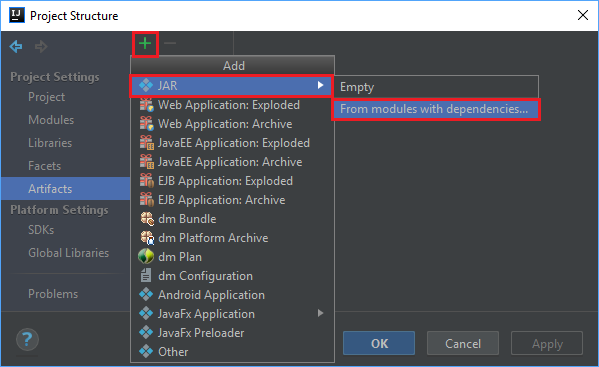
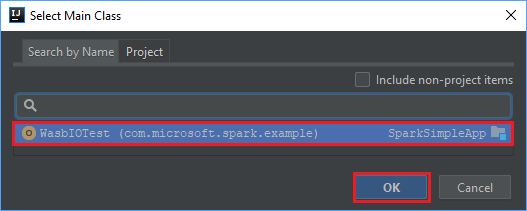
在 [從模組建立 JAR] 視窗中,選取 [主要類別] 文本框中的資料夾圖示。
在 [ 選取主要類別 ] 視窗中,選取預設出現的類別,然後選取 [ 確定]。
在 [ 從模組 建立 JAR] 視窗中,確定 已選取 [擷取至目標 JAR] 選項,然後選取 [ 確定]。 此設定會建立具有所有相依性的單一 JAR。
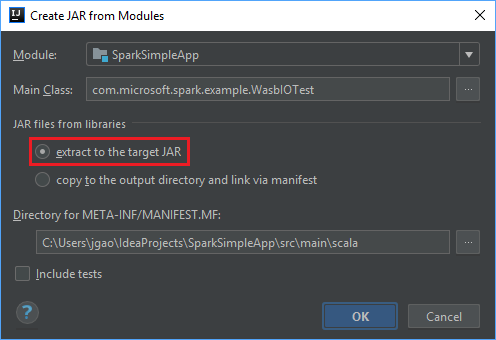
[輸出配置] 索引標籤會列出 Maven 專案隨附的所有 jar。 您可以選取並刪除 Scala 應用程式沒有直接相依性的應用程式。 針對應用程式,您要在這裡建立,您可以移除最後一個應用程式的所有專案(SparkSimpleApp 編譯輸出)。 選取要刪除的 jar,然後選取負號 -。
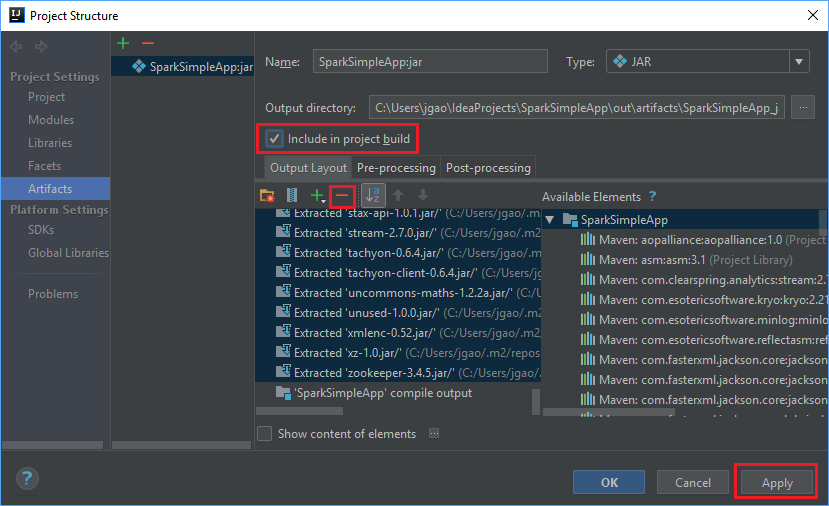
確定已選取 [ 在專案建置 中包含] 複選框。 此選項可確保每次建置或更新專案時,都會建立 jar。 選取 [套用],然後選取 [確定]。
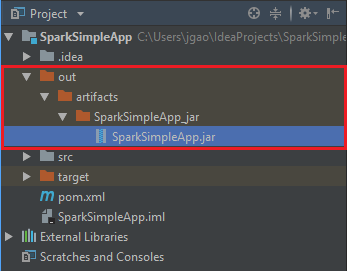
若要建立 jar,請流覽至 [建>置組建成品>組建]。 專案將在大約30秒內編譯。 輸出 jar 是在 \out\artifacts 底下建立。
在 Apache Spark 叢集上執行應用程式
若要在叢集上執行應用程式,您可以使用下列方法:
將應用程式 jar 複製到與叢集相關聯的 Azure 儲存體 Blob。 您可以使用 命令列公用程式 AzCopy 來執行此動作。 還有其他許多用戶端可用來上傳數據。 如需詳細資訊 ,請參閱上傳 HDInsight 中 Apache Hadoop 作業的數據。
使用 Apache Livy 從 遠端將應用程式作業提交至 Spark 叢集。 HDInsight 上的 Spark 叢集包含 Livy,可公開 REST 端點以遠端提交 Spark 作業。 如需詳細資訊,請參閱 在 HDInsight 上使用 Apache Livy 搭配 Spark 叢集從遠端提交 Apache Spark 作業。
清除資源
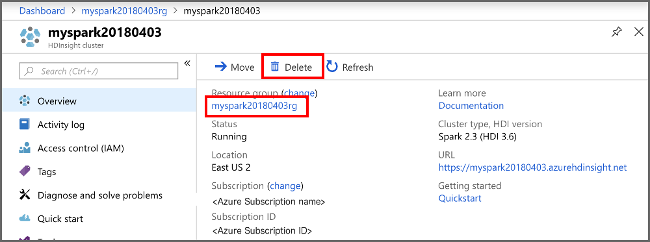
如果您不打算繼續使用此應用程式,請使用下列步驟刪除您所建立的叢集:
登入 Azure 入口網站。
在頂端的 [搜尋] 方塊中,輸入 HDInsight。
在 [服務] 底下,選取 [HDInsight 叢集]。
在顯示的 HDInsight 叢集清單中,選取 您為此教學課程建立的叢集旁的 ... 。
選取 [刪除]。 選取 [是]。
後續步驟
在本文中,您已瞭解如何建立 Apache Spark Scala 應用程式。 請前進到下一篇文章,瞭解如何使用 Livy 在 HDInsight Spark 叢集上執行此應用程式。