使用 Azure HDInsight IO 快取改進 Apache Spark 工作負載效能
注意
- IO 快取在 Spark 2.3 之前受到支援,而在 Spark 2.4 (HDInsight 4.0) 和 Spark 3.1.2 (HDInsight 5.0) 將不受支援
IO 快取是適用於 Azure HDInsight 的資料快取服務,可改進 Apache Spark 作業效能。 IO 快取也可搭配 Apache TEZ 與 Apache Hive 工作負載使用,這些工作負載可在 Apache Spark 叢集上執行。 IO 快取使用稱為 RubiX 的開放原始碼快取元件。 RubiX 是可搭配巨量資料分析引擎使用的本機磁碟快取,這些引擎通常會從雲端儲存體系統存取資料。 RubiX 在快取系統中是獨一無二的,因為它針對快取用途使用固態硬碟 (SSDs) 而非保留作業記憶體。 IO 快取服務會在叢集的每個背景工作角色上啟動並管理 RubiX 中繼資料伺服器。 它也會設定叢集的所有服務,在背景使用 RubiX 快取。
大部分的 SSD 都提供每秒超過 1 GB 的頻寬。 此頻寬加上作業系統記憶體內檔案快取的幫助,提供足夠的頻寬來載入巨量資料計算處理引擎,例如 Apache Spark。 作業系統會保留給 Apache Spark 來處理耗用大量記憶體的繁重工作,例如輪換。 擁有專屬的作業記憶體使用權讓 Apache Spark 可以達成最佳資源使使用狀況。
注意
IO 快取目前使用 RubiX 做為快取元件,但在未來的服務版本中可能會變更。 請使用 IO 快取介面,而不要直接相依於任何 RubiX 實作。 目前只有 Azure BLOB 儲存體支援 IO 快取。
Azure HDInsight IO 快取的優點
使用 IO 快取提供可為從 Azure Blob 儲存體讀取資料的作業提高效能。
使用 IO 快取時,您不需要對您的 Spark 作業進行任何變更,就可以看到效能改進。 當停用 IO 快取時,此 Spark 程式碼可從遠端 Azure Blob 儲存體讀取資料:spark.read.load('wasbs:///myfolder/data.parquet').count()。 當啟用 IO 快取時,相同的程式碼會讓應用程式透過 IO 快取進行快取讀取。 在後續的讀取作業中,會從本機 SSD 讀取資料。 HDInsight 叢集上的背景工作角色節點是本機連結的專屬 SSD 磁碟機。 HDInsight IO 快取使用這些本機 SSD 來進行快取,這樣可提供最低層級的延遲並讓頻寬最佳化。
開始使用
Azure HDInsight IO 快取在預覽版中預設是停用的。 您可以在 Azure HDInsight 3.6+ Spark 叢集中使用 IO 快取,這些叢集執行 Apache Spark 2.3。 若要在 HDInsight 4.0 上啟用 IO 快取,請執行下列步驟:
從網頁瀏覽器瀏覽至
https://CLUSTERNAME.azurehdinsight.net,其中CLUSTERNAME是叢集的名稱。選取左邊的 [IO 快取]。
選取 [動作] (在 HDI 3.6 中,選取 [服務動作]) 及 [啟動]。
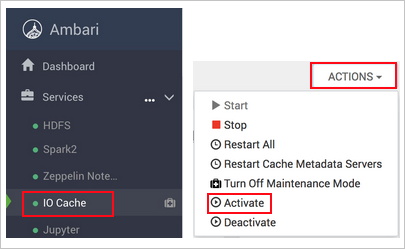
確認叢集上的所有受影響服務都已重新啟動。
注意
雖然進度列顯示已啟用,但 IO 快取在您重新啟動其他受影響的服務之前實際上不會啟用。
疑難排解
啟用 IO 快取之後,執行 Spark 作業時可能會發生磁碟空間錯誤。 發生這些錯誤的原因是 Spark 在輪換作業期間也使用本機磁碟儲存體來存放資料。 當 IO 快取已啟用且用於 Spark 儲存體的空間減少時,Spark 可能會用盡 SSD 空間。 IO 快取所使用的空間量預設是總 SSD 空間的一半。 您可以在 Ambari 中設定 IO 快取的磁碟空間使用量。 若發生磁碟空間錯誤,請減少用於 IO 快取的 SSD 空間量,並重新啟動服務。 若要變更為 IO 快取設定的空間,請執行下列步驟:
在 Apache Ambari 中,選取左邊的 HDFS 服務。
選取 [設定] 與 [進階] 索引標籤。
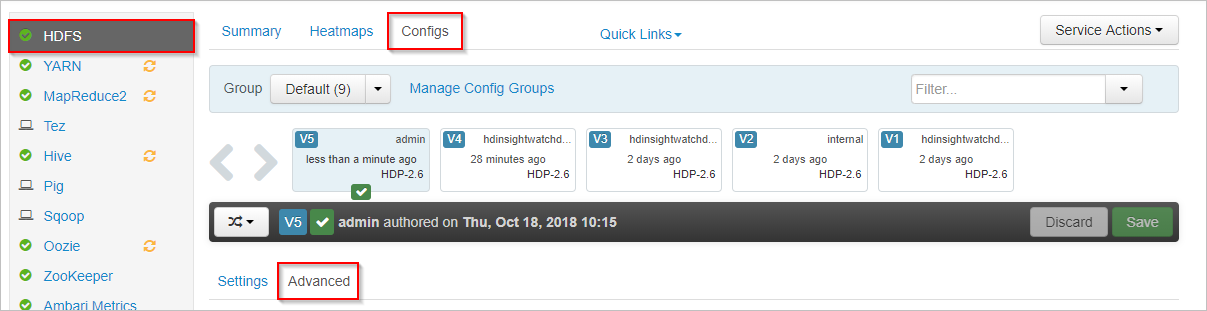
向下捲動並展開 [自訂核心網站] 區域。
尋找 hadoop.cache.data.fullness.percentage 屬性。
在方塊中變更值。

選取右上角的 [儲存]。
選取 [重新啟動]>[重新啟動所有受影響項目]。

選取 [確認重新啟動所有項目]。
若那樣沒有用,請停用 IO 快取。
後續步驟
在此部落格文章中深入了解 IO 快取,包括效能基準測試:Apache Spark 作業透過 HDInsight IO 快取獲得快 9 倍的速度 \(英文\)