Apache Spark 結構化串流的概觀
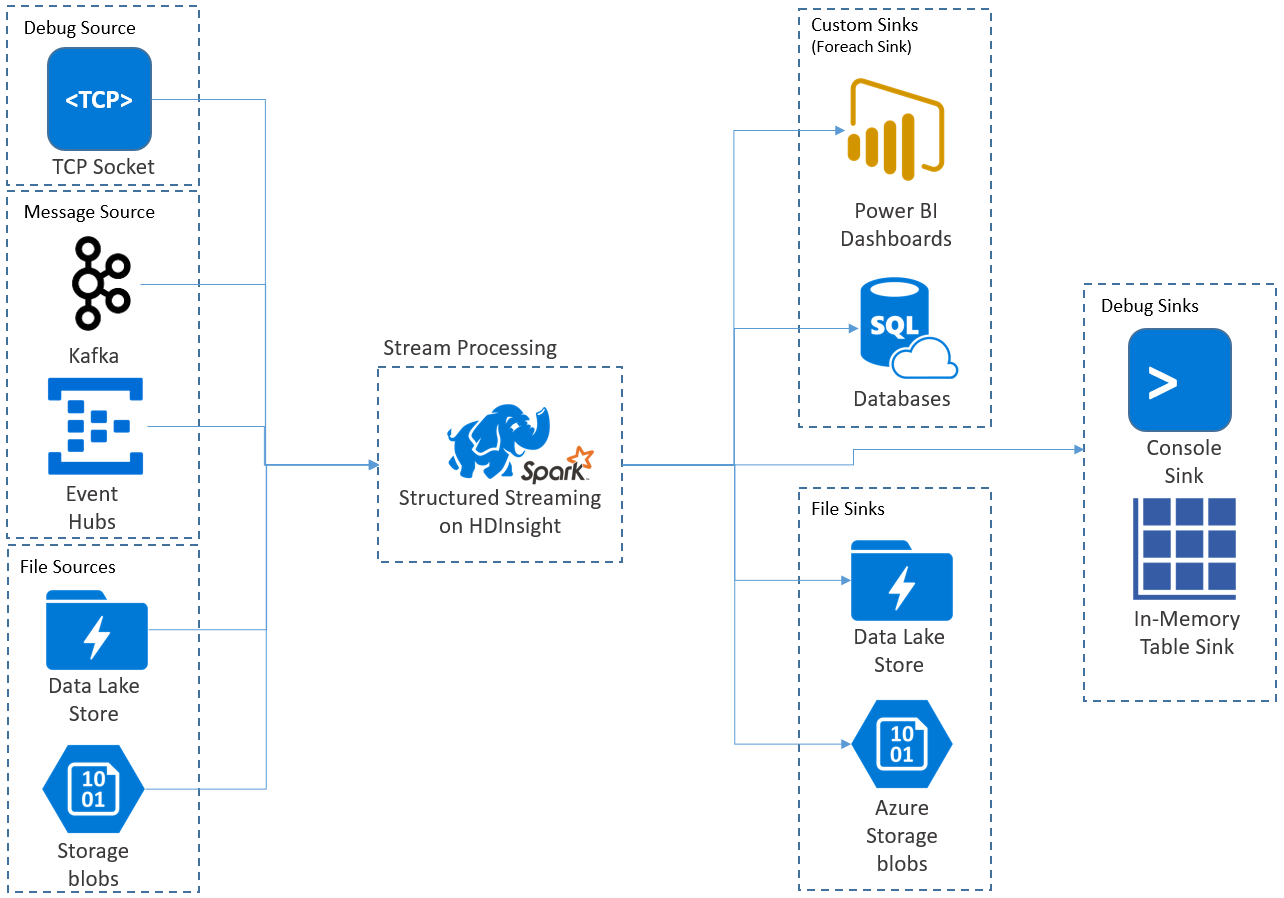
Apache Spark 結構化串流可讓您實作可調整且高輸送量的容錯應用程式來處理資料流。 結構化串流建置於 Spark SQL 引擎,並從 Spark SQL 資料框架和資料集的建構中進行改良,因此您可以使用與撰寫批次查詢相同的方式來撰寫串流查詢。
結構化串流應用程式會在 HDInsight Spark 叢集上執行,並從 Apache Kafka、TCP 通訊端 (適用於偵錯)、Azure 儲存體或 Azure Data Lake Storage 連線到串流資料。 後面兩個選項依賴外部儲存體服務,可讓您監看新增至儲存體的新檔案,並處理其內容,彷彿檔案已經過串流處理。
結構化串流會建立長時間執行的查詢,在這段期間您會將作業套用到輸入資料,例如選取範圍、投影、彙總,視窗化,以及聯結串流 DataFrame 與參考 DataFrame。 接下來,您會使用自訂程式碼(例如 SQL Database 或 Power BI)將結果輸出至檔案儲存體 (Azure 儲存體 Blob 或 Data Lake Storage) 或任何資料存放區。 結構化串流也會提供輸出給主控台以在本機偵錯,和給記憶體內部資料表,讓您可以查看在 HDInsight 中偵錯所產生的資料。
注意
Spark 結構化串流即將取代 Spark 串流 (DStreams)。 從現在開始,結構化串流將會接受增強功能和維護,而 DStreams 將只處於維護模式。 結構化串流在支援現成的來源與接收方面,目前不像 DStreams 一樣功能完善,因此請評估您的需求,選擇適當的 Spark 串流處理選項。
以資料表的形式串流
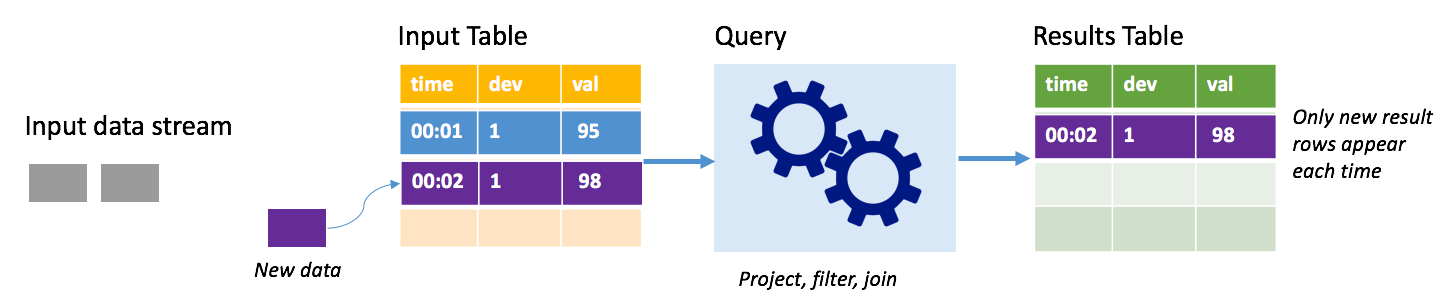
Spark 結構化串流會將資料流表示為無限深度的資料表,也就是資料表會在新資料到達時繼續成長。 此「輸入資料表」會由長時間執行的查詢持續進行處理,而結果會傳送至「輸出資料表」:

在結構化串流中,資料抵達系統後會立即內嵌至輸入資料表。 您可以撰寫查詢 (使用 DataFrame 和資料集 API),以針對此輸入資料表執行作業。 查詢輸出會產生另一個資料表:「結果資料表」。 結果資料表包含您的查詢結果,您可以從中為外部資料存放區提取資料,例如關聯式資料庫。 「觸發間隔」會控制從輸入資料表處理資料的時機。 根據預設,觸發程序間隔為零,因此結構化串流會在資料到達時立即嘗試處理資料。 實際上,這表示只要結構化串流完成執行前一個查詢,就會針對任何新收到的資料啟動另一個處理回合。 您可以設定觸發程序以間隔執行,讓以時間為基礎的批次處理串流資料。
結果資料表中的資料可能只包含自上次處理查詢後的新資料 (附加模式),或是每次有新資料時,結果資料表中的資料就會重新整理,使該資料表包含自串流查詢開始後的所有輸出資料 (完整模式)。
附加模式
在附加模式中,只有自從上次查詢執行之後新增至結果資料表的資料列才會出現在結果資料表中,並寫入外部儲存體。 例如,最簡單的查詢是將所有資料完全不變地從輸入資料表直接複製到結果資料表。 每次觸發程序間隔經過時,都會處理新的資料,以及代表新資料的資料列會出現在結果資料表中。
設想一個情況,您正在處理來自溫度感應器 (例如溫度調節器) 的遙測資料。 假設第一個觸發程序在時間 00:01 處理了裝置 1 的一個事件,其中取得的溫度是 95 度。 在查詢的第一個觸發程序中,只有時間為 00:01 的資料列才會出現在結果資料表中。 當另一個事件於時間 00:02 到達時,唯一新資料列是時間為 00:02 的資料列,因此,結果資料表將只包含該資料列。
使用附加模式時,您的查詢會套用投影 (選取它關心的資料行)、篩選 (只挑選符合特定條件的資料列) 或聯結 (以靜態查閱資料表中的資料增強資料)。 附加模式可讓您輕鬆地只將相關的新資料點推送至外部儲存體。
完整模式
請考慮相同的情節,這次使用完整模式。 在完整模式中,會在每個觸發程序時重新整理整個輸出資料表,因此資料表不僅包含來自最近觸發程序執行的資料,也包含來自所有執行的資料。 您可以使用完整模式,將未改變的資料從輸入資料表複製到結果資料表。 每次觸發執行時,新的結果資料列會與先前的所有資料列一起出現。 輸出結果資料表最後會將查詢開始後所收集的所有資料儲存起來,而您最終會用盡記憶體。 完整模式旨在與彙總查詢搭配使用,以相同的方式彙總傳入資料,因此,每次觸發時,就會以新的彙總更新結果資料表。
假設目前為止已處理五秒的資料,而且是時候處理第六秒的資料。 輸入資料表有時間 00:01 及時間 00:03 的事件。 此查詢範例的目標是每五秒提供裝置的平均溫度。 此查詢的實作會套用彙總,以取得落入每 5 秒這個時間範圍內的所有值,將溫度值平均,並產生該間隔內的平均溫度資料列。 在第一個 5 秒視窗結束時,有兩個 Tuple:(00:01、1、95) 和 (00:03、1、98)。 因此,針對 00:00-00:05 的時間範圍,彙總產生了平均溫度 96.5 度的元組。 在下一個 5 秒的時間範圍中,只有時間 00:06 上有一個資料點,所以產生的平均溫度是 98 度。 在時間 00:10 上使用完整模式,則結果資料表具 00:00-00:05 和 00:05-00:10 這兩個時間範圍的資料列,因為查詢會輸出所有彙總的資料列,而不是只輸出新的資料列。 因此,若新增時間範圍,結果資料表就會繼續成長。

並非所有使用完整模式的查詢都會導致資料表無極限地成長。 請將前面的案例設想為不是根據時間範圍來平均溫度,而是根據裝置 ID 來平均溫度。 結果資料表會包含固定數目的資料列 (每個裝置一列),以及裝置的平均溫度 (利用從裝置接收的所有資料點來計算)。 資料表會在收到新溫度時進行更新,因此資料表中的平均值一律是最新的。
Spark 結構化串流應用程式的元件
簡單的範例查詢可彙總一小時時間範圍內的顯示溫度。 在此案例中,資料會以 JSON 檔案的形式儲存在 Azure 儲存體中 (附加為 HDInsight 叢集的預設儲存體):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
這些 JSON 檔案會儲存在 HDInsight 叢集容器下方的 temps 子資料夾。
定義輸入來源
首先設定描述資料來源以及該來源所需之任何設定的 DataFrame。 此範例會從 Azure 儲存體中抽取 JSON 檔案,並在讀取時對其套用結構描述。
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
套用查詢
接下來,針對串流 DataFrame,套用包含所需作業的查詢。 在此案例中,彙總會將所有資料列群組至 1 個小時的時間範圍,然後再計算此 1 小時時間範圍內溫度的最小值、平均值和最大值。
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
定義輸出接收
接下來,為每個觸發間隔內新增至結果資料表的資料列定義目的地。 此範例直接將所有資料列輸出到記憶體內部資料表 temps,您之後可以透過 SparkSQL 進行查詢。 完整輸出模式可確保每次都會輸出所有時間範圍的所有資料列。
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
啟動查詢
啟動串流查詢並執行,直到收到終止訊號。
val query = streamingOutDF.start()
查看結果
執行查詢時,在相同的 SparkSession 中,您可以對儲存查詢結果的 temps 資料表執行 SparkSQL 查詢。
select * from temps
此查詢會產生類似下列的結果:
| 時間範圍 | 最小值 (溫度) | 平均值 (溫度) | 最大值 (溫度) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95.231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96.023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96.797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96.984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97.014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96.980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96.965997 | 99 |
如需深入了解 Spark 結構化串流 API 及其支援的輸入資料來源、作業和輸出接收,請參閱 Apache Spark Structured Streaming Programming Guide (Apache Spark 結構化串流程式設計指南)。
檢查點與預寫記錄
為了提供備援和容錯,結構化串流會藉由「檢查點」來確保串流處理即使在發生節點錯誤時,也能夠持續而不中斷。 在 HDInsight 中,Spark 會在可靠的儲存體 (Azure 儲存體或 Data Lake Storage) 上建立檢查點。 這些檢查點會儲存有關串流查詢的進度資訊。 此外,結構化串流會使用「預寫記錄檔 (WAL)」。 WAL 會擷取已接收但未由查詢處理的內嵌資料。 如果發生失敗,處理作業會從 WAL 重新啟動,這樣一來從來源收到的任何事件就不會遺失。
部署 Spark 串流處理應用程式
您通常會在本機將 Spark 串流應用程式組建成 JAR 檔案,然後藉由將此 JAR 檔案複製到預設的儲存體 (已連結至您的 HDInsight 叢集),來將其部署至 HDInsight 上的 Spark。 您可以使用 POST 作業,藉由叢集提供的 Apache Livy REST API 來啟動您的應用程式。 POST 的主體包含 JSON 文件,此文件會提供 JAR 路徑、類別名稱 (此類別的主要方法會定義和執行串流應用程式) 和選擇性的作業資源要求 (例如執行程式、記憶體及核心的數量),以及您應用程式程式碼所需的任何組態設定。
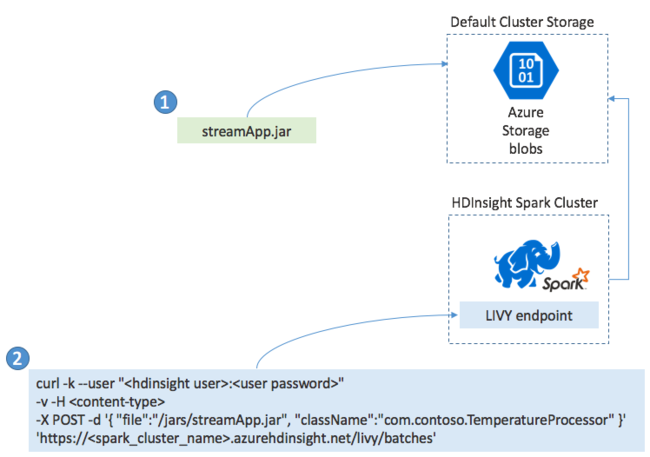
您也可以藉由 LIVY 端點,使用 GET 要求來檢查所有應用程式的狀態。 最後,您可以對 LIVY 端點發出 DELETE 要求,來終止執行中的應用程式。 如需 LIVY API 的詳細資料,請參閱使用 Apache LIVY 執行遠端作業