定型模型元件
本文描述 Azure Machine Learning 設計工具中的一個元件。
您可以使用這個元件來定型分類或迴歸模型。 定型是在您定義模型並設定其參數之後進行,需要已標記的資料。 您也可以使用定型模型,以新的資料重新定型現有的模型。
定型流程的運作方式
在 Azure Machine Learning 中,建立和使用機器學習模型通常是三步驟的流程。
您可以選擇特定類型的演算法並定義其參數或超參數,以設定模型。 選擇下列任何模型類型:
- 分類模型,以神經網路、決策樹、決策樹系和其他演算法為基礎。
- 迴歸模型,可能包括標準線性迴歸,或使用其他演算法 (包括神經網路和貝氏迴歸)。
提供已標記且資料與演算法相容的資料集。 將資料和模型都連線至定型模型。
定型會產生特定的二進位格式,即 iLearner,其中封裝從資料學習到的統計形態。 您無法直接修改或讀取此格式;不過,其他元件可以使用這個定型的模型。
您也可以檢視模型的屬性。 如需詳細資訊,請參閱〈結果〉一節。
定型完成之後,請使用定型的模型搭配其中一個評分元件,以根據新資料進行預測。
如何使用定型模型
將定型模型元件新增至管線。 您可以在 Machine Learning 類別下找到此元件。 展開 [定型],然後將 [定型模型] 元件拖曳至管線。
在左側輸入中,附加未定型的模型。 將定型資料集附加至定型模型的右側輸入。
定型資料集必須包含標籤資料行。 任何不含標籤的資料列會被忽略。
針對 [標籤資料行],按一下元件右面板中的 [編輯資料行],然後選擇單一資料行,內有結果供模型用於定型。
若為分類問題,標籤資料行必須包含分類值或離散值。 例子,是/否評等、疾病分類碼或名稱,或收入組別。 如果您挑選非分類資料行,則元件會在定型期間傳回錯誤。
若為迴歸問題,標籤資料行必須包含數值資料,代表反應變數。 在觀念上,數值資料代表連續量表。
例如,信用風險分數、硬碟的故障預測時間,或預測客服中心在特定一天或時間的來電數。 如果不選擇數值資料行,可能會發生錯誤。
- 如果未指定要使用哪一個標籤資料行,Azure Machine Learning 會使用資料集的中繼資料,嘗試推斷適當的標籤資料行。 如果挑選錯誤的資料行,請使用資料行選取器來修正。
提示
如果您使用資料行選取器時有困難,請參閱選取資料集的資料行一文中的秘訣。 其中描述一些常見的情節和 WITH RULES 和 BY NAME 選項的使用秘訣。
提交管線。 如果您有大量資料,可能需要一些時間。
重要
如果您有識別碼資料行,代表每個資料列的識別碼,或有文字資料行,其中包含太多唯一值,則定型模型可能會遇到錯誤,例如「資料行 "{column_name}" 中的唯一值超過允許的數量」。
這是因為資料行達到唯一值的閾值,可能導致記憶體不足。 您可以使用編輯中繼資料,將該資料行標示為 [清除特徵]就不會用於定型,或使用從文字擷取 N -Gram 特徵元件,以預先處理文字資料行。 如需錯誤的更多詳細資料,請參閱設計工具錯誤碼。
模型可解釋性
模型可解釋性可讓您理解 ML 模型,並以人們可理解的方式呈現決策制定的基礎。
目前,定型模型元件支援使用可解釋性封裝來說明 ML 模型。 支援下列內建演算法:
- 線性迴歸
- 類神經網路迴歸
- 促進式決策樹迴歸
- 決策樹系迴歸
- 波氏迴歸
- 二元羅吉斯迴歸
- 二元支援向量機器
- 二元促進式決策樹
- 二元決策樹系
- 多元決策樹系
- 多元羅吉斯迴歸
- 多元神經網路
若要產生模型說明,您可以在定型模型元件的 [模型說明] 下拉式清單中選取 [True]。 在定型模型元件中預設為 False。 請注意,產生說明需要額外的計算成本。
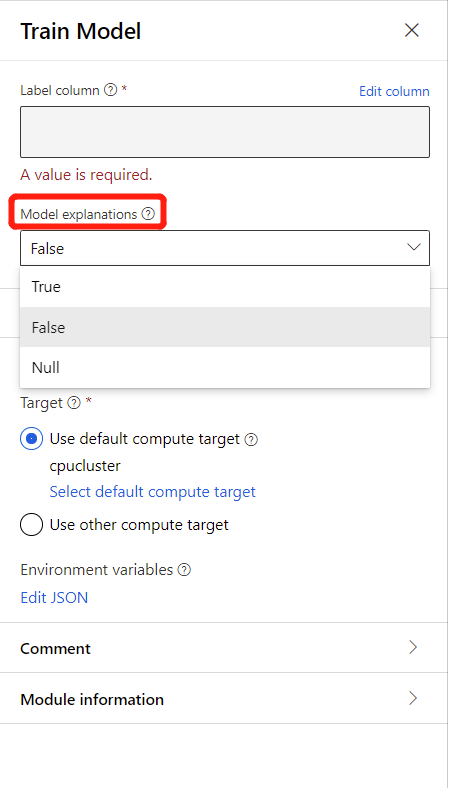
在管線執行完成之後,您可以瀏覽定型模型元件右窗格中的 [說明] 索引標籤,並探索模型效能、資料集和特徵重要度。
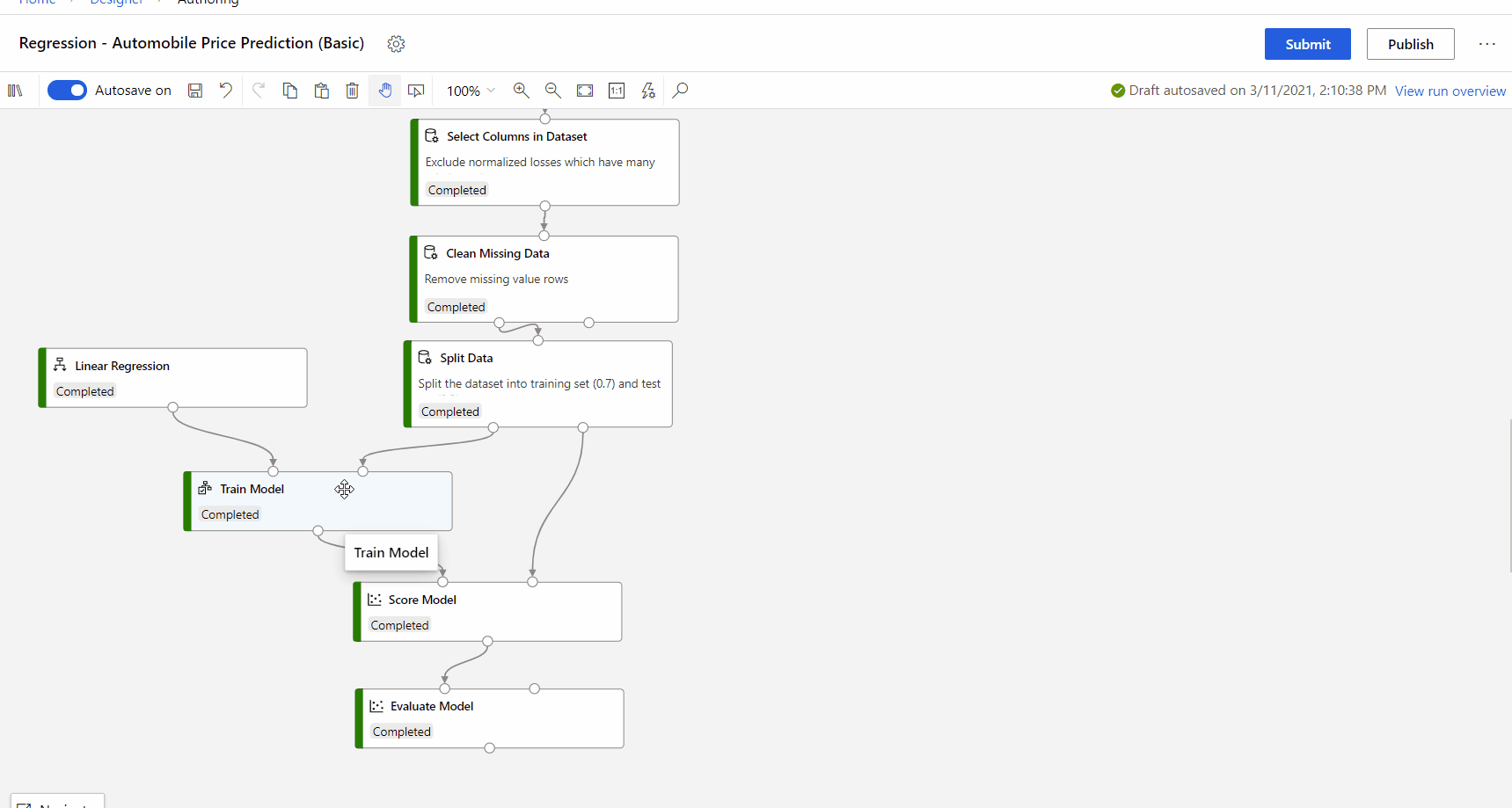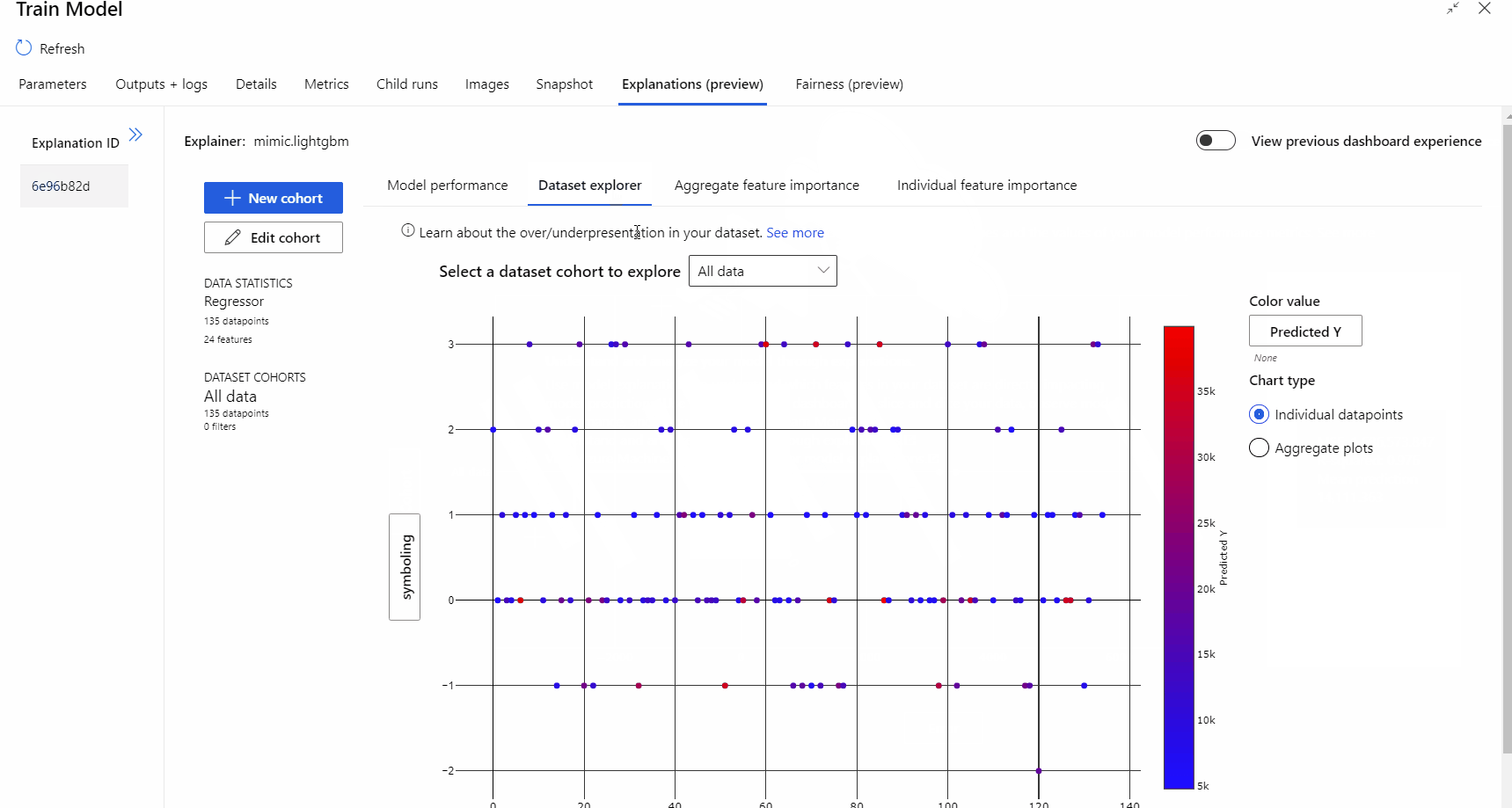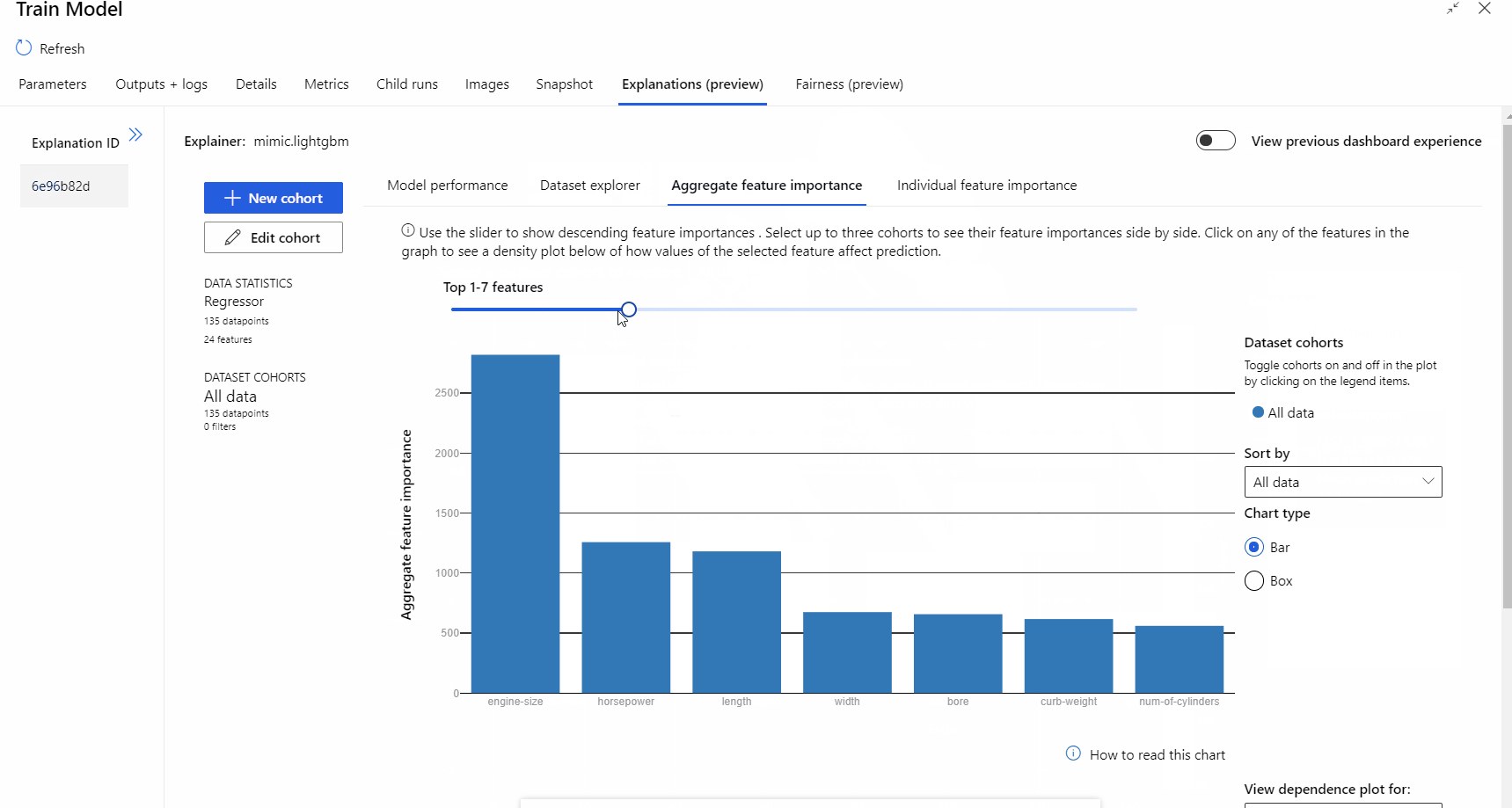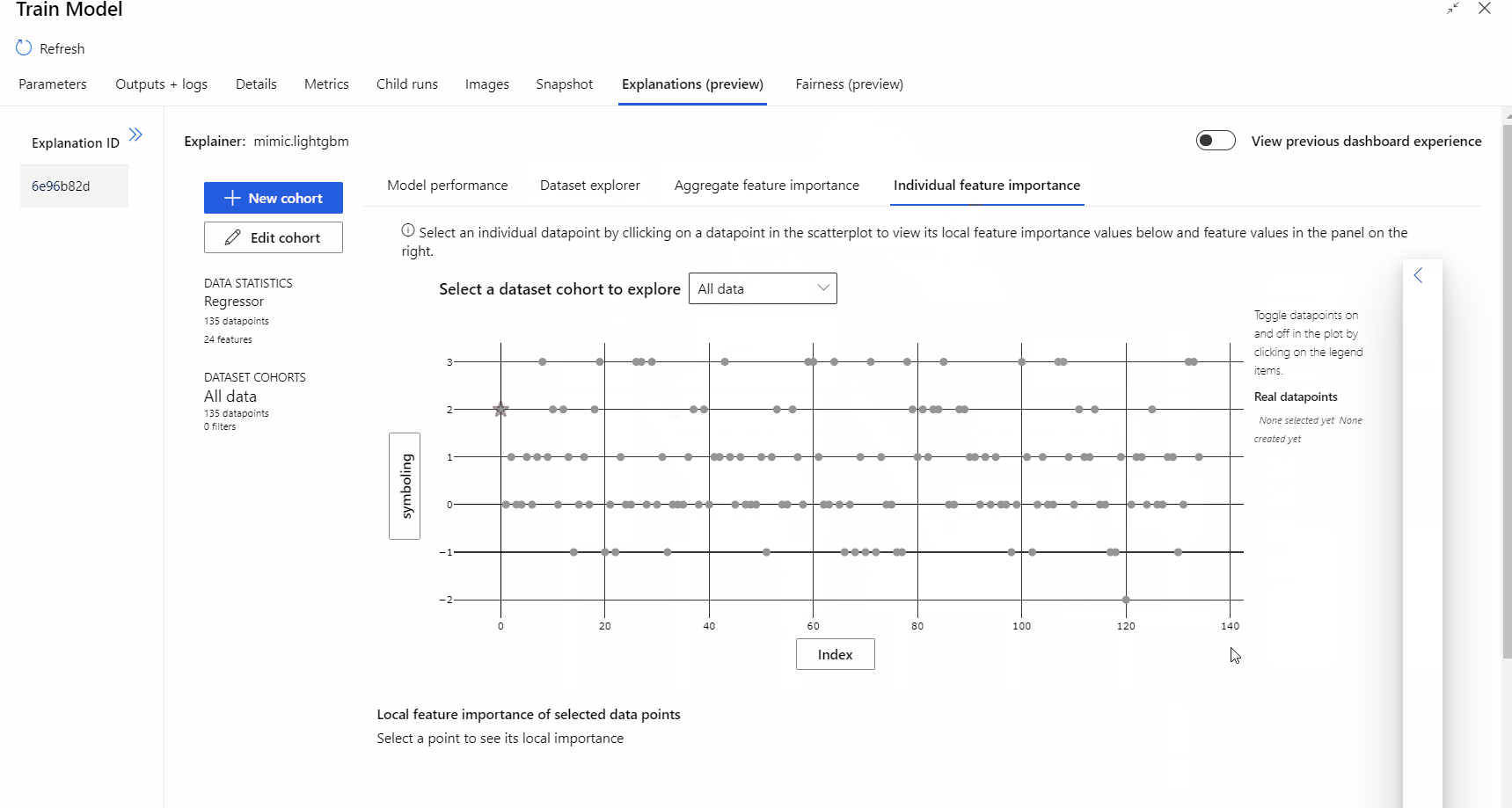
若要深入了解如何在 Azure Machine Learning 中使用模型說明,請參閱解譯 ML 模型的作法文章。
結果
定型模型之後:
若要在其他管線中使用模型,請選取元件,然後在右面板的 [輸出] 索引標籤下選取 [註冊資料集] 圖示。 您可以在元件選擇區的 [資料集] 下方存取儲存的模型。
若要使用模型來預測新的值,請將模型連同新的輸入資料,一起連線至評分模型元件。
後續步驟
請參閱 Azure Machine Learning 可用的元件集。