在 Machine Learning 工作室 (傳統) 中選擇參數來最佳化演算法
適用於: Machine Learning 工作室 (傳統)
Machine Learning 工作室 (傳統)  Azure Machine Learning
Azure Machine Learning
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
本主題說明如何在 Machine Learning 工作室 (傳統) 中選擇演算法的正確超參數集。 大部分的機器學習服務演算法都會有需要設定的參數。 當您訓練一個模型時,必須提供這些參數的值。 訓練過的模型效率會依據所選擇的模型參數而定。 找出最佳參數集的過程稱為模型選擇。
有各種方法可用來進行模型選擇。 在機器學習中,交叉驗證是其中一種最廣泛使用的模型選擇方法,也是 Machine Learning 工作室 (傳統) 中的預設模型選擇機制。 因為 Machine Learning 工作室 (傳統) 支援 R 和 Python ,所以您一律可以使用 R 或 Python 來實作其自己的模型選擇機制。
找出最佳參數集的過程有四個步驟:
- 定義參數空間:對於演算法,先決定您想要考慮的確切參數值。
- 定義交叉驗證設定:決定如何選擇資料集的交叉驗證折數。
- 定義計量:決定要使用哪一種計量來判斷最佳的參數集,例如正確度、均方根誤差、精確度、召回率或 f 分數。
- 訓練、評估和比較:對於每個唯一的參數值組合,執行交叉驗證並根據您定義的錯誤計量。 評估和比較之後,您可以選擇最佳的模型。
下圖說明在 Machine Learning 工作室 (傳統) 中如何做到。
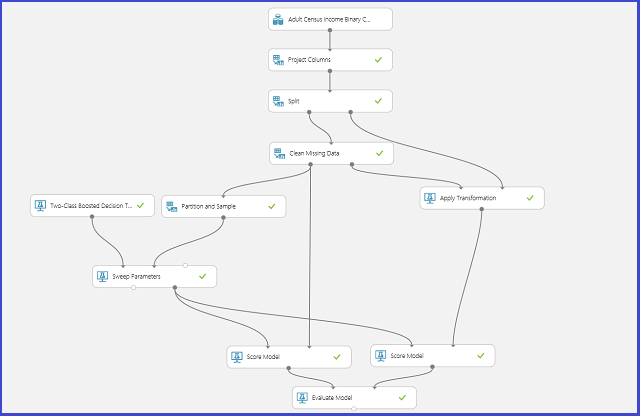
定義參數空間
您可以在進行模型初始化步驟時定義參數集。 所有機器學習演算法的參數窗格都有兩種定型模式:[單一參數] 和 [參數範圍]。 選擇 [參數範圍] 模式。 在參數範圍模式中,您可以針對每個參數輸入多個值。 您可以在文字方塊中輸入以逗號分隔的值。
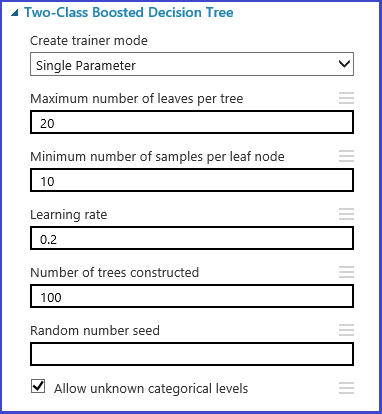
或者,您可以使用使用範圍產生器來定義網格的最大點數與最小點數,以及要產生的總點數。 參數值預設會以線性刻度產生。 但如果核取了 [對數刻度],值會以對數刻度產生 (也就是相鄰兩點的比率而不是其差異為常數)。 對於整數參數,您可以使用連字號來定義範圍。 例如,"1-10" 表示 1 到 10 (含兩者) 之間的所有整數構成參數集。 也支援使用混合的模式。 例如,此參數集 "1-10, 20, 50" 包括整數 1-10、20 和 50。
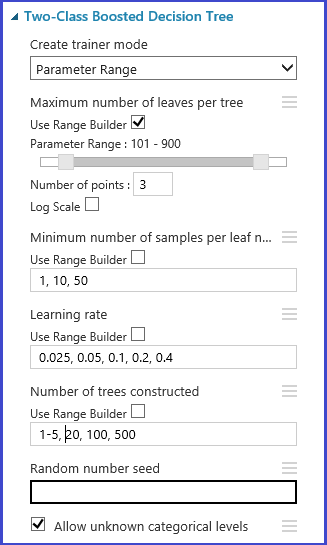
定義交叉驗證折數
資料分割和取樣模組可用來隨機指派資料的折數。 在下圖模組的範例組態中,我們定義五個折數,並且對樣本實例隨機指派折疊數目。
定義計量
調整模型超參數模組支援依據經驗為指定的演算法和資料集選擇一組最佳參數。 除了有關訓練模型的其他資訊,此模組的 [屬性] 窗格還包括用來判斷最佳參數集的計量。 分類和迴歸演算法分別有兩個不同的下拉式清單方塊。 如果考慮使用分類演算法,則會忽略迴歸計量,反之亦然。 在此特定範例中,計量是正確度。
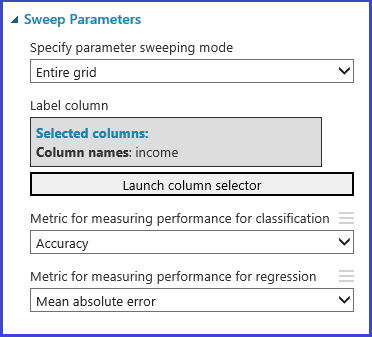
訓練、評估和比較
相同的微調模型超參數模組會訓練對應於參數集的所有模型、評估各種計量,然後根據您選擇的計量建立訓練最妥善的模型。 此模組有兩個必要的輸入項:
- 未訓練過的學習者
- 資料集
此模組也有一個選擇性資料集輸入項。 將具有折疊資訊的資料集連接到必要的資料集輸入。 如果資料集未被指派任何折疊資訊,則預設會自動執行 10 折交叉驗證。 如果尚未進行折疊指派,且在選擇性資料集區域提供了驗證資料集,則會使用選擇的訓練-測試模式和第一個資料集針對每一個參數組合訓練模型。
接著,會針對驗證資料集評估模型。 模組的左側輸出區域將不同的計量顯示為參數值的函數。 右側的輸出區域提供訓練過的模型,根據選擇的計量 (在此案例中為正確度) 對應到最佳的執行模型。
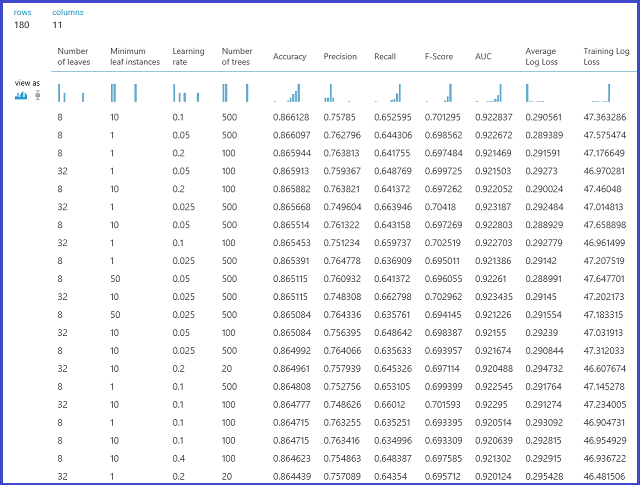
將右側輸出區域具體呈現之後,您可以看到所選擇的確切參數。 此模型在儲存為訓練過的模型之後,可用來對測試集計分,或者用在可運作的 Web 服務。