什麼是自動化機器學習 (AutoML)?
適用於: Python SDK azure-ai-ml v2 (目前)
Python SDK azure-ai-ml v2 (目前)
自動化機器學習 (亦稱為自動化 ML 或 AutoML) 是使機器學習模型開發中耗時的反覆工作自動化的流程。 這可以讓資料科學家、分析師和開發人員建置規模龐大、有效率且富生產力的 ML 模型,同時維持模型的品質。 Azure Machine Learning 中的自動化 ML 以我們 Microsoft Research 部門的突破為基礎。
- 針對有程式碼體驗的客戶,提供 Azure Machine Learning Python SDK。 如要開始使用,請參閱教學課程:使用 AutoML 和 Python 將物件偵測模型定型 (預覽)。
AutoML 的運作方式為何?
在定型期間,Azure Machine Learning 會以平行方式建立數個管道,這些管道分別會為您嘗試不同的演算法與參數。 服務會逐一查看與您所選取特徵配對的 ML 演算法、且每一次的反覆運算都會產生一個模型及定型分數。 您想要最佳化的計量所得到的分數越好,模型越會被視為「符合」您的資料。 一旦達到實驗中定義的結束準則,它就會停止。
使用 Azure Machine Learning,您可以使用下列步驟來設計和執行自動化 ML 定型實驗:
識別要解決的 ML 問題:分類、預測、迴歸或電腦視覺或 NLP。
選擇您想要使用程式碼優先體驗還是無程式碼 Studio Web 體驗:偏好程式碼優先體驗的使用者可以使用 Azure Machine Learning SDKv2 或 Azure Machine Learning CLIv2。 如要開始使用,請參閱教學課程:使用 AutoML 和 Python 將物件偵測模型定型 偏好有限/無程式碼體驗的使用者,可以使用位於 https://ml.azure.com 的 Azure Machine Learning 工作室中的 Web 介面。 藉由教學課程:在 Azure Machine Learning 中使用自動化 ML 建立分類模型開始使用。
指定標示定型資料的來源:您可以透過許多不同的方式將資料帶入 Azure Machine Learning。
設定自動化機器學習參數,這些參數決定不同模型上有多少反覆項目、超參數設定、進階前置處理/特徵化,以及決定最佳模型時要查看的計量。
提交定型作業。
檢閱結果
下圖說明此流程。
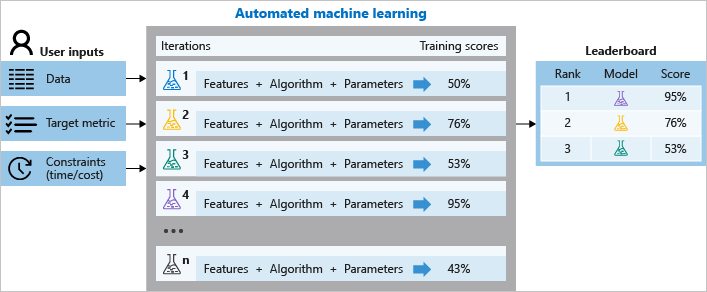
您也可以檢查所記錄的作業資訊,其中包含了計量 (於作業執行期間所收集)。 定型作業會產生 Python 序列化物件 (.pkl 檔案),其中包含模型與資料前置處理。
在自動化模型建置的同時,您還可以了解對產生的模型而言,功能的重要性或相關性。
使用 AutoML 的時機:分類、迴歸、預測、電腦視覺和 NLP
在想要 Azure Machine Learning 為您定型和調整模型時套用自動化 ML,並使用您指定的目標計量。 自動化 ML 普及機器學習模型的開發流程,並讓其使用者可以針對任何問題尋找端對端的機器學習服務管線,無論其資料科學的專長為何。
跨產業的 ML 專業人員和開發人員可以使用自動化 ML 來執行下列動作:
- 實作 ML 服務解決方案,無須豐富的程式設計知識
- 節省時間與資源
- 利用資料科學的最佳做法
- 提供敏捷的解決問題方式
分類
分類是一種監督式學習,其中模型會學習使用定型資料,並將那些學習套用至新的資料。 Azure Machine Learning 特別針對這些工作提供特徵化,例如用於分類的深度類神經網路文字功能。 深入了解特徵化選項。 您也可以在這裡找到 AutoML 支援的演算法清單。
分類模型的主要目標,是根據從其定型資料中的學習,來預測新資料將屬於哪些類別。 常見的分類範例包括詐騙偵測、手寫辨識和物件偵測。
請參閱此 Python 筆記本中的分類和自動化機器學習範例:銀行行銷。
迴歸
與分類類似,迴歸工作也是常見的監督式學習工作。 Azure Machine Learning 提供迴歸問題特有的特徵工程。 深入了解特徵化選項。 您也可以在這裡找到 AutoML 支援的演算法清單。
不同於預測輸出值為類別的分類,迴歸模型會根據獨立的預測指標來預測數值輸出值。 在迴歸中,目標是藉由評估一個變數如何影響其他變數,來協助您建立那些獨立預測變數之間的關聯性。 例如,以諸如油耗、安全等級等特徵為基礎的汽車價格。
請參閱下列 Python 筆記本中的迴歸和自動化機器學習範例以進行預測:硬體效能。
時間序列預測
建置預測是任何企業不可或缺的一部分,無論是收入、庫存、銷售還是客戶需求。 您可以使用自動化 ML 結合技術和方法,並取得建議的高品質時間序列預測。 您可以在這裡找到 AutoML 支援的演算法清單。
自動化時間序列實驗會被視為多重變數迴歸問題。 過去的時間序列值會「樞紐化」,以與其他預測值一起成為迴歸輸入變數的其他維度。 與傳統時間序列方法不同的是,這種方法的優點是在定型期間自然結合多個內容變數及其關聯性。 自動化 ML 會針對資料集和預測範圍中的所有項目,學習單一但通常是內部分支的模型。 因此,有更多資料可用來估計模型參數,並且可以實現對看不見的序列的一般化。
進階預測設定包括:
- 假日偵測和特徵化
- 時間序列和 DNN 學習者 (Auto-ARIMA、Prophet、ForecastTCN)
- 透過分組支援許多模型
- 移動原點交叉驗證
- 可設定延隔
- 移動時段彙總功能
請參閱此 Python 筆記本中的預測和自動化機器學習範例:能源需求。
電腦視覺
支援電腦視覺工作,可讓您針對影像分類和物件偵測等案例,輕鬆地產生針對影像資料定型的模型。
使用這項功能,您可以:
- 與 Azure Machine Learning 資料標記功能緊密整合
- 使用加上標籤的資料來產生影像模型
- 藉由指定模型演算法和微調超參數來最佳化模型效能。
- 將產生的模型下載或部署為 Azure Machine Learning 中的 Web 服務。
- 運用 Azure Machine Learning MLOps 和 ML Pipelines 功能大規模作業化。
您可以透過 Azure Machine Learning Python SDK 來支援製作視覺工作的 AutoML 模型。 產生的實驗作業、模型和輸出可以經由 Azure Machine Learning 工作室 UI 進行存取。
了解如何設定電腦視覺模型的 AutoML 定型。
 影像來源:http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
影像來源:http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
影像自動化 ML 支援下列電腦視覺工作:
| Task | 描述 |
|---|---|
| 多類別影像分類 | 僅使用一組類別的單一標籤來分類影像的工作,例如,每個影像都會分類為「貓」或「狗」或「鴨子」的影像 |
| 多標籤影像分類 | 影像可以有一組標籤中一或多個標籤的工作 (例如,影像可能會標記為「貓」和「狗」) |
| 物件偵測 | 用來識別影像中的物件及使用週框方塊找出每個物件的工作,例如找出影像中的所有狗和貓,並在每個方塊週圍繪製週框方塊。 |
| 執行個體分割 | 工作可在像素層級識別影像中的物件,並在影像中的每個物件週圍繪製多邊形。 |
自然語言處理:NLP
對於自動化 ML 中自然語言處理 (NLP) 工作的支援,可讓您輕鬆地針對文字分類和具名實體辨識案例產生文字資料定型的模型。 透過 Azure Machine Learning Python SDK 支援撰寫自動化 ML 定型 NLP 模型。 產生的實驗作業、模型和輸出可以經由 Azure Machine Learning 工作室 UI 進行存取。
NLP 功能支援:
- 使用最新的預先定型 BERT 模型進行端對端深度神經網路 NLP 定型
- 與 Azure Machine Learning 資料標記緊密整合
- 使用加上標籤的資料來產生 NLP 模型
- 具有 104 種語言的多語系支援
- 使用 Horovod 的分散式訓練
了解如何設定 NLP 模型的 AutoML 定型。
定型、驗證和測試資料
您可以使用自動化 ML 提供定型資料來定型 ML 模型,且您可以指定要執行哪種類型的模型驗證。 自動化 ML 會在定型過程中執行模型驗證。 也就是說,自動 ML 會使用驗證資料,根據套用的演算法來調整模型超參數,以找出最適合定型資料的組合。 不過,相同的驗證資料會用於每個微調反覆項目,這會引進模型評估偏差,因為模型會持續改善並符合驗證資料。
為了協助確認這類偏差未套用至最終的建議模型,自動化的 ML 支援使用測試資料來評估在您實驗結束時自動化 ML 建議的最終模型。 當您在自動化 ML 實驗設定中提供測試資料時,預設會在實驗結束時測試此建議的模型 (預覽)。
重要
有一項預覽功能是使用測試資料集來測試模型以評估產生的模型。 此功能是實驗性預覽功能,而且可能隨時變更。
了解如何設定 AutoML 實驗,以透過 SDK 或 Azure Machine Learning 工作室來使用測試資料 (預覽)。
功能工程
特徵工程是使用資料的網域知識來建立功能,以協助加強 ML 演算法學習的程序。 在 Azure Machine Learning 中,會套用規模調整和正規化技術來輔助特徵工程。 這些技術和特性工程統稱統稱為特徵化。
針對自動化機器學習實驗,特徵化會自動套用,但也可以根據您的資料進行自訂。 在您的模型中深入了解包含哪些特徵化 (SDK v1) 以及 AutoML 如何協助防止過度學習和不平衡的資料。
注意
自動化機器學習特徵化步驟 (功能標準化、處理遺漏的資料、將文字轉換為數值等等) 會成為基礎模型的一部分。 使用模型進行預測時,定型期間所套用的相同特徵化步驟會自動套用至您的輸入資料。
自訂特徵化
您也可以使用其他特徵工程技術,例如編碼和轉換。
啟用此設定的方式:
Azure Machine Learning 工作室:透過這些步驟,在 [檢視其他設定] 區段中啟用 [自動特徵化]。
集團模型
自動化機器學習支援預設會啟用的集團模型。 集團學習藉由結合多個模型來改善機器學習結果和預測效能,而不是使用單一模型。 集團反覆項目顯示為作業的最終反覆項目。 自動化機器學習會使用投票和堆疊集團方法兩者來結合模型:
- 投票:根據預測類別機率 (適用於分類工作) 或預測迴歸目標 (適用於迴歸工作) 的加權平均值進行預測。
- 堆疊:堆疊結合了異質性模型,並根據個別模型的輸出來定型中繼模型。 目前的預設中繼模型是用於分類工作的 LogisticRegression,和用於迴歸/預測工作的 ElasticNet。
包含排序集團初始化的 Caruana 集團選取項目演算法,用於決定要在集團中使用的模型。 概括而言,此演算法使用最多五個具有最佳個別分數的模型來初始化集團,並確認這些模型是否在最佳分數的 5% 閾值內,以避免不佳的初始集團。 然後,針對每個集團反覆項目,會將新的模型加入至現有的集團,並計算產生的分數。 如果新模型已改善現有的集團分數,則會更新集團以包含新的模型。
請參閱 AutoML 套件,以變更自動化機器學習中的預設集團設定。
AutoML 與 ONNX
使用 Azure Machine Learning,您可以使用自動化 ML 來建置 Python 模型,並將其轉換成 ONNX 格式。 一旦模型採用 ONNX 格式,就可以在各種不同的平台和裝置上執行。 深入了解使用 ONNX 加速 ML 模型。
在此 Jupyter 筆記本範例中 \(英文\),了解如何轉換為 ONNX 格式。 了解 ONNX 支援哪些演算法。
ONNX 執行階段也支援 C#,因此您可以使用在 C# 應用程式中自動建置的模型,而無需重新編碼或 REST 端點引入的任何網路延遲。 深入了解如何在 .NET 應用程式中使用 AutoML ONNX 模型,並搭配 ML.NET 和 使用 ONNX 執行階段 C# API 推斷 ONNX 模型。
下一步
有多個資源可讓您啟動並執行 AutoML。
教學課程/操作說明
教學課程是 AutoML 案例的端對端入門範例。
如需程式碼優先體驗,請遵循教學課程:使用 AutoML 和 Python 將物件偵測模型定型
如需低程式碼或無程式碼的體驗,請參閱教學課程:在 Azure Machine Learning 工作室中使用無程式碼自動化機器學習定型分類模型。
操作說明文章提供自動化 ML 所提供功能的其他詳細資料。 例如,
設定自動定型實驗的設定
了解如何使用 Python 定型電腦視覺模型。
Jupyter Notebook 範例
在自動化機器學習範例的 GitHub 筆記本存放庫中,檢閱詳細的程式碼範例和使用案例。
Python SDK 參考
使用 AutoML 作業類別參考文件,加深 SDK 設計模式與類別規格的專業知識。
注意
自動化機器學習功能也適用於其他 Microsoft 解決方案,例如 ML.NET、HDInsight、Power BI 和 SQL Server