在互動部署期間存取 Azure 雲端儲存體的資料
適用於: Python SDK azure-ai-ml v2 (目前)
Python SDK azure-ai-ml v2 (目前)
機器學習專案通常會以探索資料分析 (EDA)、資料前置處理 (清理、特徵工程) 開始,並且包含建置 ML 模型的原型來驗證假設。 此專案的原型設計階段本質上具備高度互動性,其本身有助於在 Jupyter Notebook 或具有 Python 互動式主控台的 IDE 中進行開發。 在本文章中,您將了解如何:
- 從 Azure Machine Learning 資料存放區 URI 存取資料,如同存取檔案系統一樣。
- 使用
mltablePython 程式庫將資料具體化為 Pandas。 - 使用
mltablePython 程式庫將 Azure Machine Learning 資料集具體化為 Pandas。 - 透過
azcopy公用程式明確下載來具體化資料。
必要條件
- Azure Machine Learning 工作區。 如需詳細資訊,請參閱在入口網站中或使用 Python SDK (v2) 來管理 Azure Machine Learning 工作區。
- Azure Machine Learning 資料存放區。 如需詳細資訊,請參閱建立資料存放區。
提示
本文中的指導說明互動式開發期間的資料存取。 其適用於任何可執行 Python 工作階段的主機。 這可以包含您的本機電腦、雲端 VM、GitHub Codespace 等。我們建議使用 Azure Machine Learning 計算執行個體 - 完全受控且預先設定的雲端工作站。 如需詳細資訊,請參閱建立 Azure Machine Learning 計算執行個體。
重要
請確定您已在 Python 環境中安裝最新的 azure-fsspec 和 mltable Python 程式庫:
pip install -U azureml-fsspec mltable
從資料存放區 URI 存取資料,例如檔案系統
Azure Machine Learning 資料存放區是現有 Azure 儲存體帳戶的參考。 建立和使用資料存放區的優點包括:
- 常見、易於使用的 API,可與不同的儲存體類型互動 (Blob/檔案/ADLS)。
- 在小組作業中輕鬆探索有用的資料存放區。
- 支援認證型 (例如 SAS 權杖) 和身分識別型 (使用 Microsoft Entra ID 或受控識別) 存取來存取資料。
- 針對認證型存取,連線資訊會受到保護,避免在指令碼中公開金鑰。
- 在 Studio UI 中瀏覽資料並複製貼上資料存放區 URI。
資料存放區 URI 是統一資源識別項,這是 Azure 儲存體帳戶上儲存體位置 (路徑) 的參考。 資料存放區 URI 具有下列格式:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
這些資料存放區 URI 是檔案系統規格 (fsspec) 的已知實作:本機、遠端和內嵌檔案系統和位元組儲存體的統一且具 Python 特色的介面。
您可以 pip 安裝 azureml-fsspec 套件及其相依性 azureml-dataprep 套件。 然後,您可以使用 Azure Machine Learning 資料存放區 fsspec 實作。
Azure Machine Learning 資料存放區 fsspec 實作會自動處理 Azure Machine Learning 資料存放區所使用的認證/身分識別傳遞。 您可以在計算執行個體上避免指令碼和其他登入程序中的帳戶金鑰曝光。
例如,您可以直接在 Pandas 中使用資料存放區 URI。 此範例說明如何讀取 CSV 檔案:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
提示
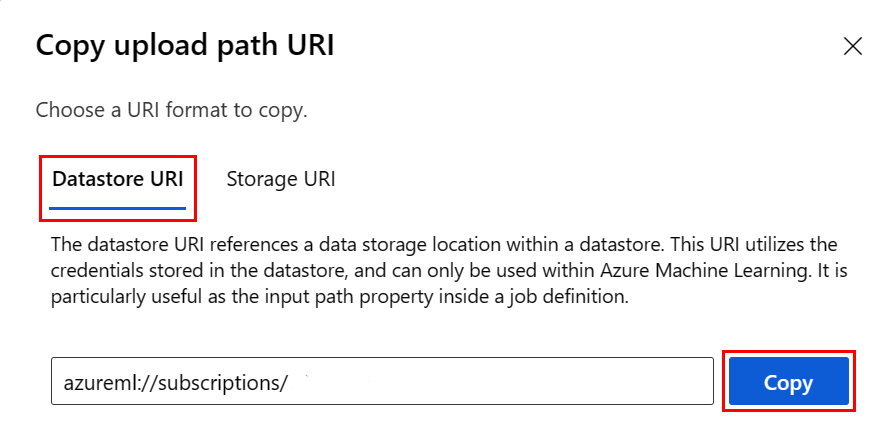
您可以透過下列步驟,從 Studio UI 複製並貼上資料存放區 URI,而不是記住資料存放區 URI 格式:
- 從左側功能表中選取 [資料],然後選取 [資料存放區] 索引標籤。
- 選取資料存放區名稱,然後選取 [瀏覽]。
- 尋找您想要讀取至 Pandas 的檔案/資料夾,選取其旁邊的省略號 (...)。 從功能表選取 [複製 URI]。 您可以選取 [資料存放區 URI] 以複製到您的筆記本/指令碼。
您也可以具現化 Azure Machine Learning 檔案系統來處理類似檔案系統的命令,例如 ls、glob、exists、open。
ls()方法會列出特定目錄中的檔案。 您可以使用 ls()、ls(.)、ls (<<folder_level_1>/<folder_level_2>) 來列出檔案。 我們在相對路徑中同時支援 '.' 和 '..'。glob()方法支援 '*' 和 '**' 萬用字元。exists()方法會傳回布林值,指出指定檔案是否存在於目前的根目錄中。open()方法會傳回類似檔案的物件,此物件可以傳遞至任何其他預期使用 Python 檔案的程式庫。 您的程式碼也可以使用這個物件,就像是一般的 Python 檔案物件一樣。 這些類似檔案的物件會遵守使用with內容,如下列範例所示:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
透過 AzureMachineLearningFileSystem 上傳檔案
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath 是本機路徑,rpath 是遠端路徑。
如果您在 rpath 中指定的資料夾尚不存在,我們將會為您建立資料夾。
我們支援三種「覆寫」模式:
- APPEND:如果目的地路徑中已有同名的檔案,這會保留原始檔案
- FAIL_ON_FILE_CONFLICT:如果目的地路徑中已有同名的檔案,這會擲回錯誤
- MERGE_WITH_OVERWRITE:如果目的地路徑中已有同名的檔案,這會以新檔案覆寫現有檔案
透過 AzureMachineLearningFileSystem 下載檔案
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
範例
這些範例示範在常見案例中使用檔案系統規格的使用方式。
將單一 CSV 檔案讀入 Pandas
您可以將單一 CSV 檔案讀入 Pandas,如下所示:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
將 CSV 檔案的資料夾讀入 Pandas
Pandas read_csv() 方法不支援讀取 CSV 檔案的資料夾。 您必須 glob csv 路徑,並使用 Pandas concat() 方法將其串連至資料框架。 下一個程式碼範例示範如何透過 Azure Machine Learning 檔案系統達成此串連:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
將 CSV 檔案讀入 Dask
此範例說明如何將 CSV 檔案讀入 Dask 資料框架:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
將 parquet 檔案的資料夾讀入 Pandas
在 ETL 程序中,Parquet 檔案通常會寫入資料夾,然後可以發出與 ETL 相關的檔案,例如進度、認可等。此範例顯示從 ETL 程序建立的檔案 (從 _ 開始的檔案),然後產生一個 parquet 檔案的資料。

在這些案例中,您只會讀取資料夾中的 parquet 檔案,並忽略 ETL 程序檔案。 此程式碼範例示範 glob 模式如何只能讀取資料夾中的 parquet 檔案:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
透過 Azure Databricks 檔案系統存取資料 (dbfs)
檔案系統規格 (fsspec) 具有已知實作的範圍,包括 Databricks 檔案系統 (dbfs)。
若要透過 dbfs 存取資料,您需要:
- 執行個體名稱,格式為
adb-<some-number>.<two digits>.azuredatabricks.net。 您可以在 Azure Databricks 工作區的 URL 中找到此值。 - 個人存取權杖 (PAT),如需建立 PAT 的詳細資訊,請參閱使用 Azure Databricks 個人存取權杖進行驗證
有了這些值,您必須在 PAT 權杖的計算執行個體上建立環境變數:
export ADB_PAT=<pat_token>
然後,您可以在 Pandas 中存取資料,如下列範例所示:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
使用 pillow 讀取影像
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
PyTorch 自訂資料集範例
在此範例中,您會建立 PyTorch 自訂資料集以處理影像。 我們假設有註釋檔案 (CSV 格式) 存在,且具有此整體結構:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
子資料夾會根據其標籤儲存這些映像:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
自訂 PyTorch 資料集類別必須實作三個函式:__init__、__len__ 和 __getitem__,如下所示:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
接著,您可以如下所示將資料集具現化:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
使用 mltable 程式庫將資料具體化為 Pandas
mltable 程式庫也可以協助存取雲端儲存空間中的資料。 使用 mltable 將資料讀取至 Pandas 的一般格式如下:
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
支援的路徑
mltable 程式庫支援從不同的路徑類型讀取表格式資料:
| Location | 範例 |
|---|---|
| 本機電腦上的路徑 | ./home/username/data/my_data |
| 公用 HTTP 伺服器的路徑 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure 儲存體上的路徑 | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| 完整格式 Azure Machine Learning 資料存放區 | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
注意
mltable 負責針對 Azure 儲存體和 Azure Machine Learning 資料存放區上的路徑處理使用者認證傳遞。 若您沒有基礎儲存體中的資料存取權限,則無法存取資料。
檔案、資料夾和 Glob
mltable 支援透過下列項目讀取:
- 檔案 - 例如:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - 資料夾 - 例如
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ - glob 模式 - 例如
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - 檔案、資料夾和/或萬用字元模式的組合
mltable 彈性可讓您從本機和雲端儲存空間資源的組合以及檔案/資料夾/globs 的組合,將資料具體化為單一資料框架。 例如:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
支援的檔案格式
mltable 支援下列檔案格式:
- 分隔符號文字 (例如:CSV 檔案):
mltable.from_delimited_files(paths=[path]) - Parquet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - JSON 行格式:
mltable.from_json_lines_files(paths=[path])
範例
讀取 CSV 檔案
使用特定詳細資料更新程式碼片段中的預留位置 (<>):
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
讀取資料夾中的 parquet 檔案
此範例示範 mltable 如何使用 glob 模式 (例如萬用字元),確保僅讀取 parquet 檔案。
使用特定詳細資料更新程式碼片段中的預留位置 (<>):
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
讀取資料資產
本節說明如何在 Pandas 中存取 Azure Machine Learning 資料資產。
資料表資產
如果您先前已在 Azure Machine Learning 中建立資料表資產 (mltable 或 V1 TabularDataset),您可以使用下列程式碼將該資料表資產載入 Pandas:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
檔案資產
如果您註冊檔案資產 (例如 CSV 檔案),您可以使用下列程式碼將該資產讀入 Pandas 資料框架:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
資料夾資產
如果您註冊檔案資產 (uri_folder 或 V1 FileDataset),例如包含 CSV 檔案的資料夾,您可以使用下列程式碼將該資產讀入 Pandas 資料框架:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
使用 Pandas 讀取及處理大型資料磁碟區的注意事項
提示
Pandas 並非設計用於處理大型資料集- Pandas只能處理可放入計算執行個體記憶體的資料。
針對大型資料集,我們建議使用 Azure Machine Learning 受控 Spark。 這會提供 PySpark Pandas API。
您可能想要在擴大至遠端非同步作業之前,快速逐一查看大型資料集的較小子集。 mltable 提供內建的功能,可使用 take_random_sample 方法來取得大型資料的範例:
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
您也可以使用下列作業來取得大型資料的子集:
使用 azcopy 公用程式下載資料
使用 azcopy 公用程式將資料下載到主機的本機 SSD (本機電腦、雲端 VM、Azure Machine Learning 計算執行個體),下載到本機檔案系統。 預先安裝在 Azure Machine Learning 計算執行個體上的 azcopy 公用程式會處理這項作業。 如果您並未使用 Azure Machine Learning 計算執行個體或資料科學虛擬機器 (DSVM),您可能需要安裝 azcopy。 如需詳細資訊,請參閱 azcopy。
警告
不建議將資料下載至計算執行個體的 /home/azureuser/cloudfiles/code 位置。 此位置是設計用於儲存筆記本和程式碼成品,並非用於儲存資料。 透過這個位置讀取資料會在訓練時產生顯著的效能額外負荷。 因此建議您改為將資料儲存在 home/azureuser 中,這是計算節點的本機 SSD。
開啟終端機並建立新的目錄,例如:
mkdir /home/azureuser/data
使用下列項目來登入 AzCopy:
azcopy login
接下來,您可以使用儲存體 URI 複製資料
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST