對資料集偵測資料漂移 (預覽版)

了解如何監視資料漂移,並在漂移過高時設定警示。
使用 Azure Machine Learning 資料集監視 (預覽版),您可以:
- 分析資料中的漂移,以了解其在一段時間內的變化。
- 監視模型資料,了解定型和服務資料集之間的差異。 從收集已部署模型的模型資料開始。
- 監視新資料,了解任何基準和目標資料集之間的差異。
- 剖析資料中的特徵,以追蹤統計屬性在一段時間內的變化。
- 設定資料漂移的警示,以便對潛在問題及早發出警告。
- 當您判斷資料漂移太多時,請建立新的資料集版本。
Azure Machine Learning 資料集用於建立監視。 資料集必須包含時間戳記資料行。
您可以使用 Python SDK 或在 Azure Machine Learning 工作室中來查看資料漂移計量。 其他計量和深入解析可透過與 Azure Machine Learning 工作區相關聯的 Azure Application Insights 資源來取得。
重要
資料集的資料漂移偵測目前處於公開預覽狀態。 此預覽版本會在沒有服務等級協定的情況下提供,不建議用於實際執行工作負載。 可能不支援特定功能,或可能已經限制功能。 如需詳細資訊,請參閱 Microsoft Azure 預覽版增補使用條款。
必要條件
若要建立及使用資料集監視,您需要:
- Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 立即試用免費或付費版本的 Azure Machine Learning。
- Azure Machine Learning 工作區。
- 已安裝適用於 Python 的 Azure Machine Learning SDK,其中包含 azureml-datasets 套件。
- 結構化 (表格式) 資料,包含檔案路徑中指定的時間戳記、檔案名稱,或資料中的資料行。
什麼是資料漂移?
模型精確度隨著時間而降低,主要是因為資料漂移。 針對機器學習模型,資料漂移是模型輸入資料中的變化導致模型效能降低。 監視資料漂移有助於偵測這些模型效能問題。
資料漂移的原因包括:
- 上游程序變更,例如,更換感應器,使得計量單位從英吋變更為公分。
- 資料品質問題,例如,一個損毀的感應器讀數總是為 0。
- 資料中的自然漂移,例如,隨季節變化的平均溫度。
- 功能之間關聯的變化,或變項偏移。
Azure Machine Learning 藉由計算單一計量,以抽象化比較的資料集複雜性,進而簡化漂移偵測。 這些資料集可能有數百個功能和數萬個資料列。 偵測到漂移之後,您可以向下切入到哪些功能造成漂移。 然後,檢查功能層級計量,以偵錯並找出漂移的根本原因。
這個由上而下的方法可讓您輕鬆地監視資料,而不是傳統以規則為基礎的技術。 以規則為基礎的技術 (例如,允許的資料範圍或允許的唯一值) 可能相當耗時且容易出錯。
在 Azure Machine Learning 中,您可以使用資料集監視以偵測資料漂移,並發出警示。
資料集監視
使用資料集監視,您可以:
- 偵測資料集內新資料的資料漂移,並發出警示。
- 分析漂移的歷程記錄資料。
- 剖析一段時間的新資料。
資料漂移演算法提供資料變化的整體量值,並指出哪些功能會負責進一步調查。 資料集監視會藉由剖析 timeseries 資料集中的新資料來產生許多其他計量。
您可以透過 Azure Application Insights,在監視產生的所有計量上設定自訂警示。 您可以使用資料集監視來快速攔截資料問題,並找出可能的原因,藉此縮短偵錯問題的時間。
就概念而言,在 Azure Machine Learning 中設定資料集監視有三個主要案例。
| 案例 | 描述 |
|---|---|
| 監視模型的服務資料與定型資料的漂移情況 | 此案例的結果可以解釋成監視模型精確度的 Proxy,因為當服務資料從定型資料漂移時,模型精確度會下降。 |
| 監視時間序列資料集與上一段時間的漂移情況。 | 這種情況更普遍,可用來監視模型建立之上游或下游的相關資料集。 目標資料集必須有時間戳記資料行。 基準資料集可以是任何與目標資料集有共通功能的任何表格式資料集。 |
| 對過去的資料進行分析。 | 您可以使用此案例來了解歷程記錄資料,並在資料集監視的設定中提供決策參考。 |
資料集監視取決於下列 Azure 服務而定。
| Azure 服務 | 描述 |
|---|---|
| 資料集 | 漂移使用 Machine Learning 資料集以擷取定型資料,並比較資料,以進行模型定型。 產生資料的設定檔是用來產生一些回報的計量,例如最小值、最大值、相異值、相異值計數。 |
| Azure Machine Learning 管線和計算 | 漂移計算作業裝載在 Azure Machine Learning 管線中。 此作業會視需要或依排程觸發,以在漂移監視建立時設定的計算上執行。 |
| Application insights | 漂移會將計量發出給屬於機器學習工作區的 Application Insights。 |
| Azure Blob 儲存體 | 漂移會將 json 格式的計量發出至 Azure blob 儲存體。 |
基準和目標資料集
您可以針對資料漂移監視 Azure Machine Learning 資料集。 建立資料集監視時,請參考:
- 基準資料集 - 通常是模型的定型資料集。
- 目標資料集 - 通常是模型輸入資料 - 會隨著時間與基準資料集進行比較。 這種比較表示您的目標資料集必須指定時間戳記資料行。
監視器會比較基準和目標資料集。
建立目標資料集
目標資料集需要藉由從資料中的資料行,或從衍生自檔案路徑模式的虛擬資料行,指定時間戳記資料行,以設定 timeseries 特徵。 透過 Python SDK 或 Azure Machine Learning 工作室,使用時間戳記建立資料集。 必須指定代表「時間戳記」的資料行,才能將 timeseries 特徵新增至資料集。 如果您的資料分割成具有時間資訊的資料夾結構,例如「{yyyy/MM/dd}」,請透過路徑模式設定來建立虛擬資料行,並將其設為「分割區時間戳記」,以啟用時間序列 API 功能。
Dataset類別with_timestamp_columns()方法定義資料集的時間戳記資料行。
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
提示
如需使用資料集之 timeseries 特徵的完整範例,請參閱範例筆記本或資料集 SDK 文件。

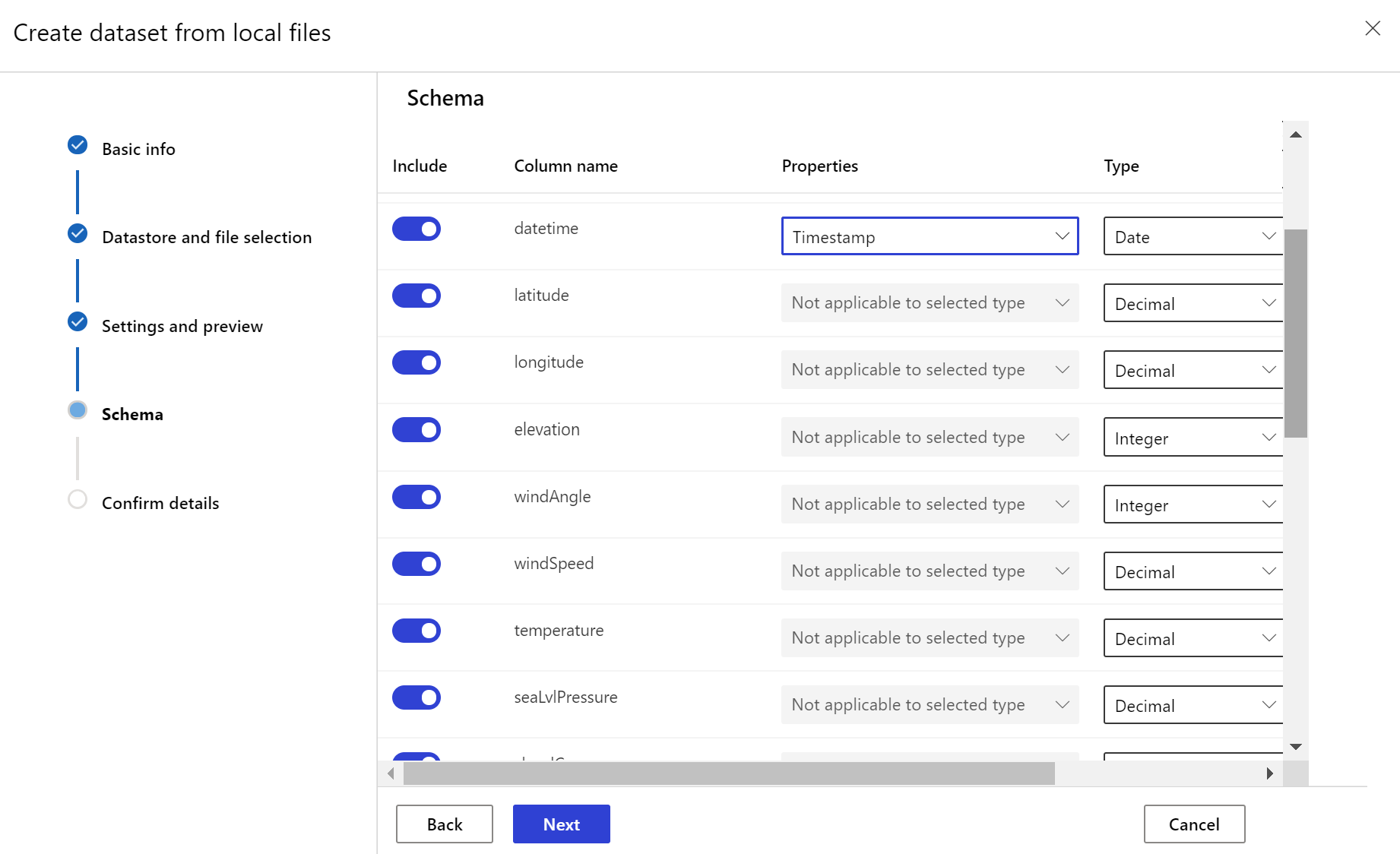
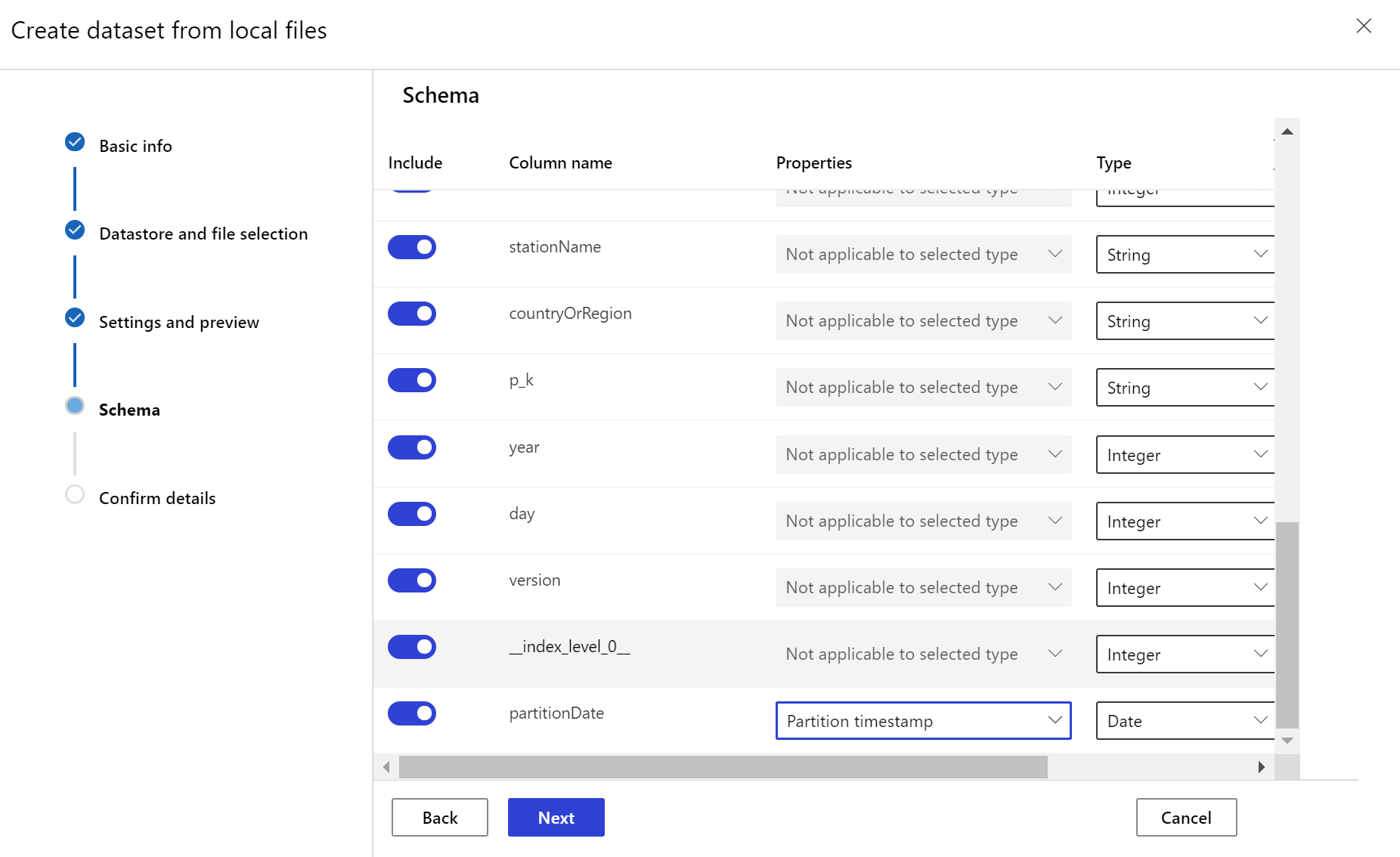
建立資料集監視
建立資料集監視來偵測新資料集的資料漂移,並發出警示。 請使用 Python SDK 或 Azure Machine Learning 工作室。
如稍後所述,資料集監視會以設定的頻率 (每日、每週、每月) 間隔執行。 其會分析自上次執行後目標資料集中可用的新資料。 在某些情況下,這樣分析最新資料可能不夠:
- 來自上游來源的新資料因資料管線中斷而延遲,且在執行資料集監視時還沒有這個新資料。
- 時間序列資料集只有歷程記錄資枓,而您想要分析資料集在一段時間內的資料漂移模式。 例如:比較冬季和夏季時流向網站的流量,以識別季節性模式。
- 您不熟悉資料集監視。 您想要先評估此功能與現有資料的運作方式,再進行設定以便於未來進行監視。 在這種情況下,您可以提交隨選執行,且為特定的目標資料集設定日期範圍,以便與基準資料集進行比較。
回填函式會在指定的開始和結束日期範圍執行回填作業。 回填作業會填入資料集中預期的遺漏資料點,以確保資料正確性和完整性。
如需完整的詳細資料,請參閱資料漂移上的 Python SDK 參考文件。
下列範例顯示如何使用 Python SDK 建立資料集監視
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
提示
如需設定 timeseries 資料集和資料漂移偵測器的完整範例,請參閱我們的範例筆記本。
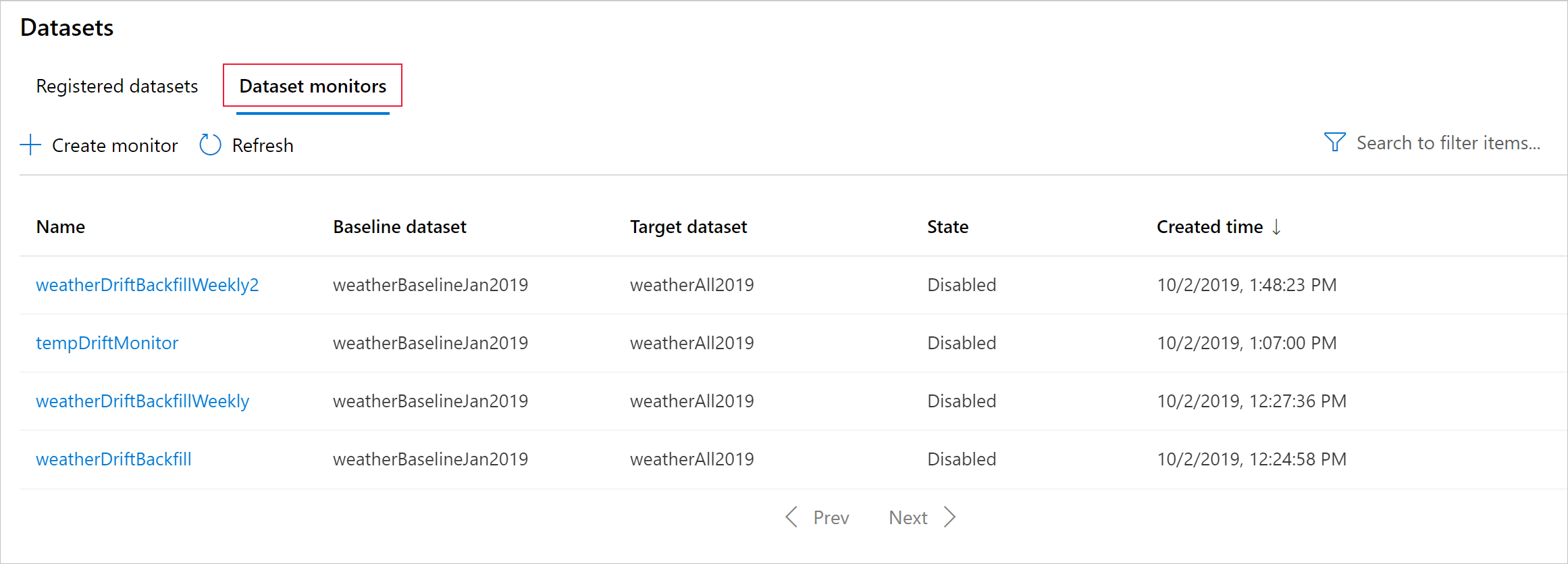

了解資料漂移結果
本節說明監視資料集的結果,可在 Azure Studio 的 [資料集] / [資料集監視] 頁面中找到。 透過此頁面,您可以更新特定時段的設定並分析現有資料。
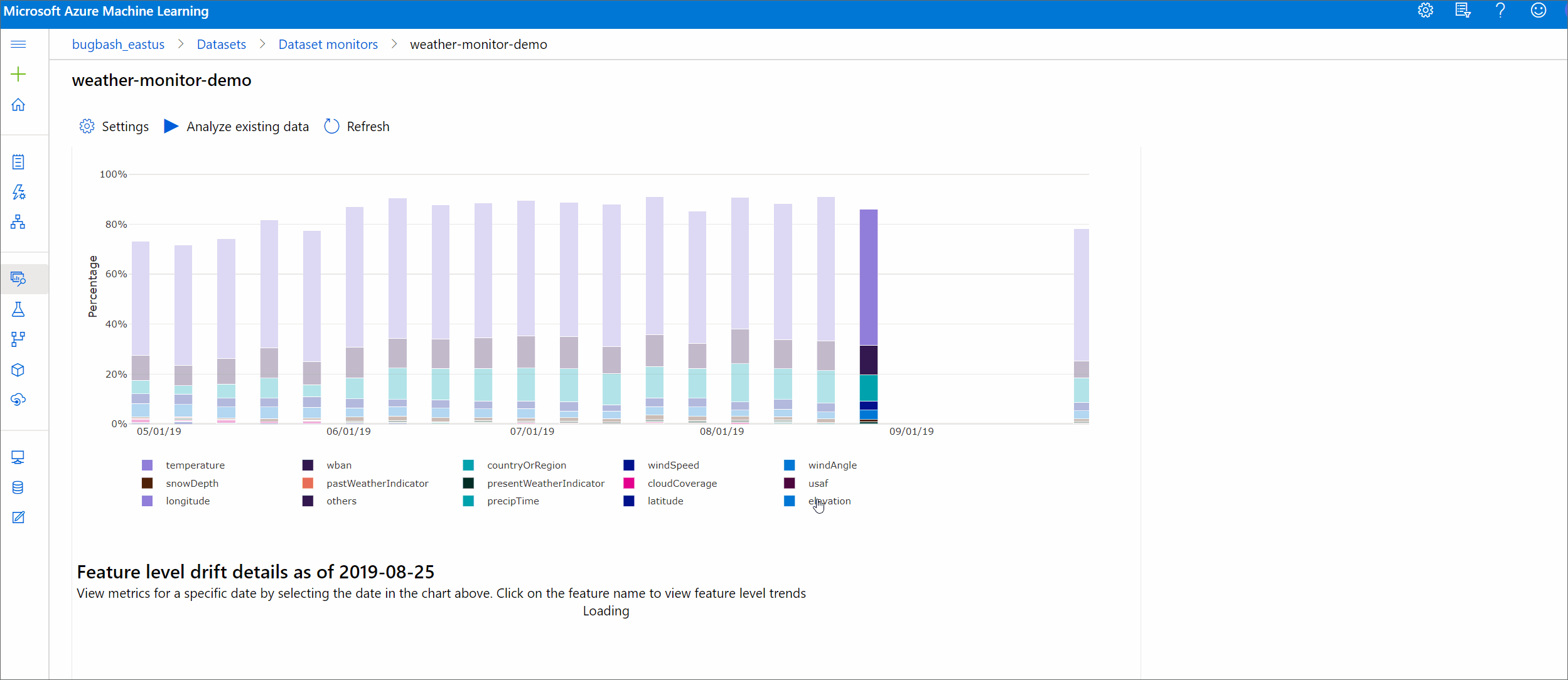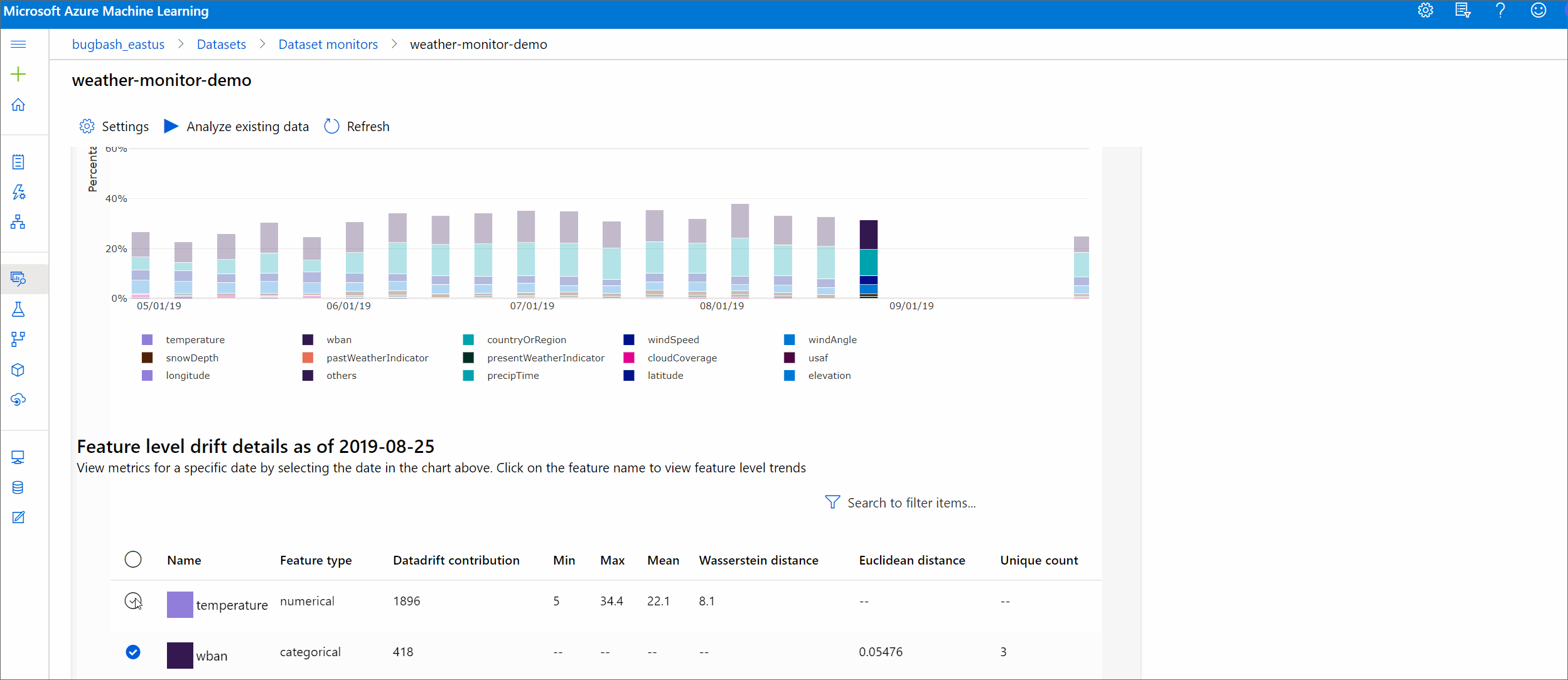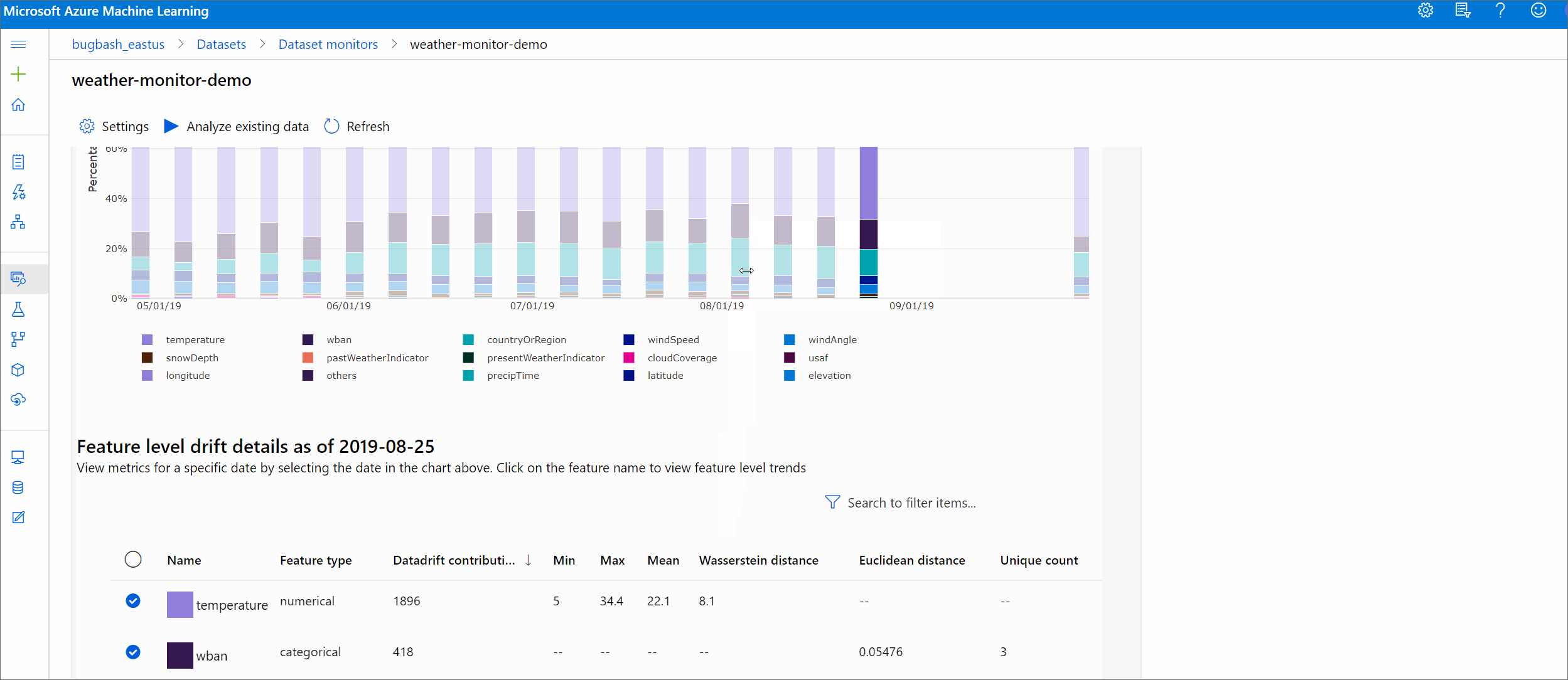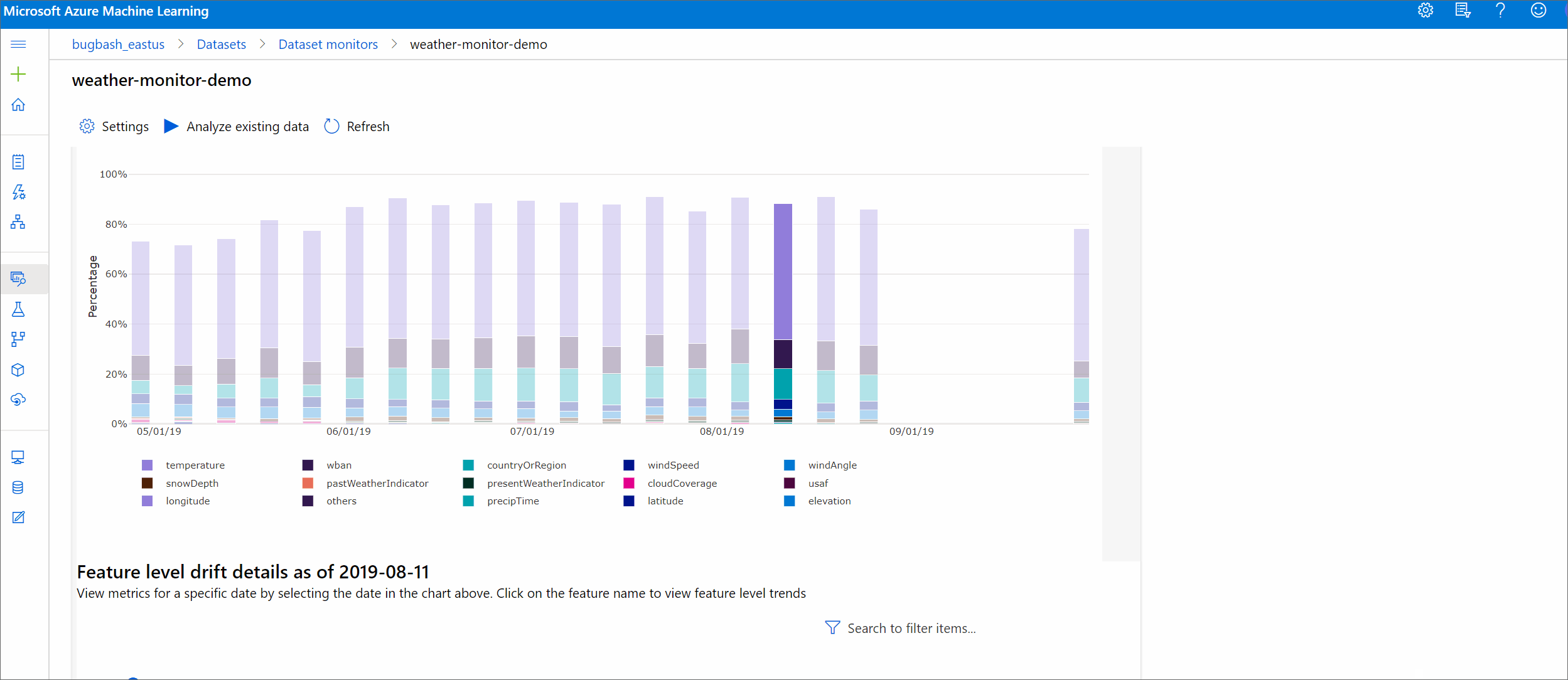
從最上層深入解析開始,到資料漂移範圍,以及要進一步調查的功能醒目提示。
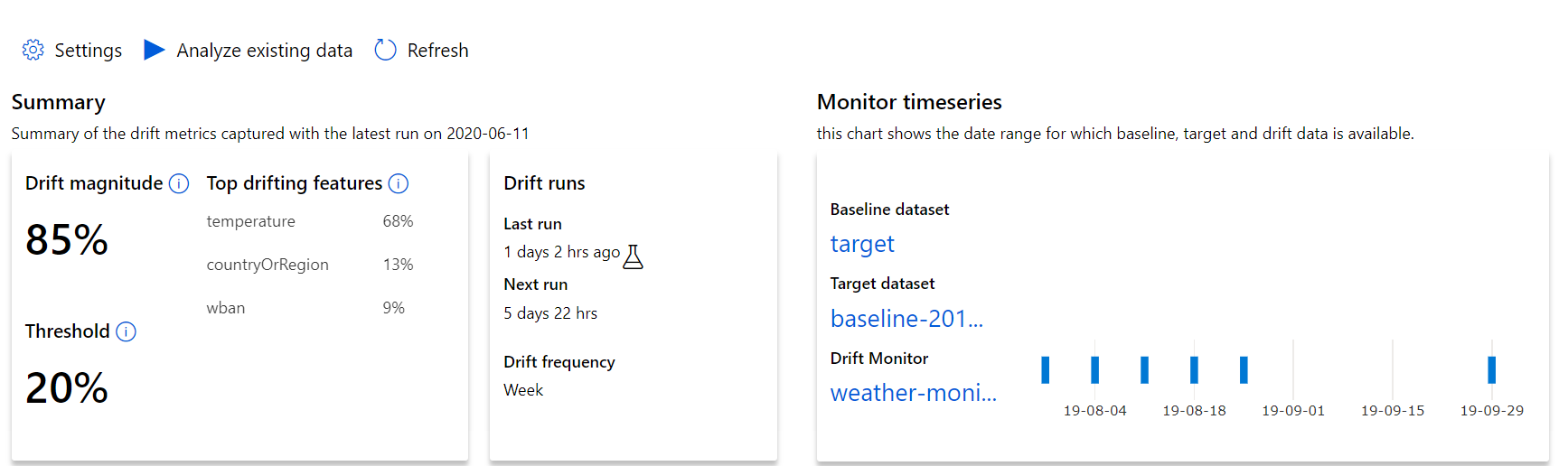
| 計量 | 描述 |
|---|---|
| 資料漂移範圍 | 基準和目標資料集一段時間的漂移百分比。 此百分比的範圍從 0 到 100,0 表示相同的資料集,而 100 表示 Azure Machine Learning 資料漂移模型可以完全分辨兩個資料集。 由於使用機器學習技術來產生此範圍,因此,預期測量的精確百分比有雜訊。 |
| 熱門漂移功能 | 顯示資料集中漂移程度最高的功能,因此在漂移範圍計量中比重最大。 由於變項偏移,功能的基礎分佈不一定需要變更為具有相當高的特徵重要度。 |
| 臨界值 | 資料漂移範圍超過設定的閾值,便會觸發警示。 設定監視設定中的閾值。 |
漂移範圍趨勢
請參閱資料集在指定的時間週期內與目標資料集的差異。 越接近 100%,這兩個資料集的差異越多。

漂移範圍 - 依功能
本節包含一段時間內,對所選功能發佈變更以及其他統計資料的功能層級深入解析。
目標資料集也會在一段時間內進行剖析。 每項功能的基準分佈之間的統計距離會與目標資料集進行一段時間的比較。 概念上,這類似於資料漂移範圍。 不過,此統計距離適用於個別功能,而不是所有功能。 最小值、最大值和平均值也可供使用。
在 Azure Machine Learning 工作室中,選取圖表中的橫條,以查看該日期的功能層級詳細資料。 根據預設,您會看到基準資料集的分佈,以及相同功能的最新工作分佈。
您也可以透過 DataDriftDetector 上的 get_metrics() 方法,在 Python SDK 中擷取這些計量。
功能詳細資料
最後,向下捲動以檢視每個個別功能的詳細資料。 使用圖表上方的下拉式清單來選取功能,並另外選取您要檢視的計量。
圖表中的計量取決於功能類型。
數值功能
計量 描述 Wasserstein 距離 將基準分佈轉換成目標分佈的最小工作量。 平均值 功能的平均值。 最小值 功能的最小值。 最大值 功能的最大值。 類別功能
計量 描述 Euclidian 距離 計算類別資料行。 歐幾里德距離是以兩個向量來計算,從兩個資料集的相同類別資料行的經驗分佈所產生。 0 表示經驗分佈沒有任何差異。 越偏離 0,此資料行的漂移愈多。 您可以從這個計量的時間序列繪圖來觀察趨勢,並在發現漂移功能時很有幫助。 唯一值 功能的唯一值 (基數) 數目。
在此圖表上,選取單一日期來比較所顯示功能之目標與該日期之間的功能分佈。 對於數值功能,此顯示兩個機率分佈。 如果功能是數值,則會顯示橫條圖。
計量、警示和事件
您可以在與機器學習工作區相關聯的 Azure Application Insights 資源中查詢計量。 您可以存取 Application Insights 的所有功能,包括設定自訂警示規則和動作群組以觸發動作,例如電子郵件/簡訊/推送/語音或 Azure Function。 如需詳細資料,請參閱完整的 Application Insights 文件。
若要開始使用,請瀏覽至 Azure 入口網站,並選取您工作區的 [概觀] 頁面。 相關的 Application Insights 資源位於最右邊:

在左側窗格的 [監視] 下,選取 [記錄 (分析]):
資料集監視計量會儲存為 customMetrics。 您可以在設定資料集監視之後,撰寫並執行查詢以查看這些計量:

識別要設定警示規則的計量之後,請建立新的警示規則:
您可以使用現有的動作群組,或建立一個新的動作群組,以定義符合設定條件時要採取的動作:
疑難排解
資料漂移監視的限制和已知問題:
分析歷程記錄資料的時間範圍限制為監視頻率設定的 31 個間隔。
限制 200 個功能,除非未指定功能清單 (使用的所有功能)。
計算大小必須夠大,才能處理資料。
請確保您的資料集在指定監視工作的開始和結束日期內有資料。
資料集監視僅適用於包含 50 個以上資料列的資料集。
資料集中的資料行或功能會根據下表中的條件,分類為類別或數值。 如果功能不符合這些條件-例如,含有 >100 個唯一值的類型字串資料行-則會從我們的資料漂移演算法中卸除該功能,但仍會進行剖析。
功能類型 資料類型 Condition 限制 類別 string 功能中唯一值的數目小於 100,且小於資料列數目的 5%。 Null 視為其本身的類別。 數值 int、float 功能中的值是數值資料類型,而且不符合分類功能的條件。 如果 >15% 的值為 Null,則會卸除功能。 如果您已建立資料漂移監視,但在 Azure Machine Learning 工作室的 [資料集監視] 頁面上看不到資料,請嘗試下列動作。
- 檢查您是否已在頁面頂端選取正確的日期範圍。
- 在 [資料集監視] 索引頁籤中,選取實驗連結以檢查工作狀態。 此連結位於資料表最右邊。
- 如果工作已成功完成,請檢查驅動程式記錄,藉以查看產生多少計量,或是否有任何警告訊息。 選取實驗之後,請在 [輸出 + 記錄] 索引標籤中尋找驅動程式記錄。
如果 SDK
backfill()函式未產生預期的輸出,可能是因為驗證問題所致。 建立要傳遞至此函式的計算時,請勿使用Run.get_context().experiment.workspace.compute_targets。 相反地,請使用 ServicePrincipalAuthentication (如下所示),以建立您要傳遞至該backfill()函式的計算:auth = ServicePrincipalAuthentication( tenant_id=tenant_id, service_principal_id=app_id, service_principal_password=client_secret ) ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx") compute = ws.compute_targets.get("xxx")從模型資料收集器中,最多可能需要 10 分鐘,資料就會抵達您的 Blob 儲存體帳戶。 不過,通常不需要這麼多時間。 在指令碼或 Notebook 中,等待 10 分鐘,以確保下方儲存格已成功執行。
import time time.sleep(600)
下一步
- 前往 Azure Machine Learning 工作室或 Python 筆記本,以設定資料集監視。
- 請參閱如何在部署至 Azure Kubernetes Service 的模型上設定資料漂移。
- 使用 Azure 事件方格來設定資料集漂移監視。