使用工作室 UI 來設定表格式資料的無程式碼 AutoML 定型
在本文中,您將瞭解如何不使用任何程式碼在 Azure Machine Learning 工作室 中以 Azure Machine Learning 自動化 ML 來設定 AutoML 定型作業。
自動化機器學習 (AutoML) 是針對特定資料來選取最佳機器學習服務演算法的流程。 此流程可讓您快速產生機器學習模型。 深入了解 Azure Machine Learning 如何實作自動化機器學習。
如需端對端範例,請參考教學課程:AutoML - 訓練無程式碼分類模型。
如需以 Python 程式碼為基礎的體驗,請使用 Azure Machine Learning SDK 設定自動化機器學習實驗。
必要條件
Azure 訂用帳戶。 如果您沒有 Azure 訂用帳戶,請在開始前建立免費帳戶。 立即試用免費或付費版本的 Azure Machine Learning。
Azure Machine Learning 工作區。 請參閱建立工作區資源。
開始使用
選取訂用帳戶及工作區。
巡覽至左側窗格。 選取 [撰寫] 區段之下的 [自動化 ML]。

若這是第一次執行任何實驗,則會看到空白清單,以及前往文件的連結。
否則,您會看到最近的自動化 ML 實驗清單,包括使用 SDK 建立的實驗。
建立及執行實驗
選取 [+ 新增自動化 ML 作業] 並填入表單。
從儲存體容器選取資料集,或建立新資料集。 資料集可從本機檔案、Web URL、資料存放區或 Azure 開放資料集來建立。 深入瞭解資料集建立。
重要
定型資料的需求:
- 資料必須是表格形式。
- 您想要預測的值 (目標資料行) 必須存在於資料中。
若要從本機電腦上的檔案建立新資料集,請選取 [+ 建立資料集],然後選取 [從本機檔案]。
選取 [下一步] 來開啟 [資料存放區和檔案選取表單]。 您會選取上傳資料集的位置:與工作區一同自動建立的預設儲存體容器,或選取想要用於實驗的儲存體容器。
- 如果您的資料位於虛擬網路後方,您必須啟用 [略過驗證] 功能,以確保工作區可以存取您的資料。 如需詳細資訊,請參閱在 Azure 虛擬網路中使用 Azure Machine Learning 工作室。
選取 [瀏覽],為您的資料集上傳資料檔案。
檢閱 [設定和預覽] 表單以進行確認。 表單會根據檔案類型以智慧方式填入。
欄位 描述 File format 定義檔案中所儲存資料的版面配置和類型。 分隔符號 一或多個字元,其用來指定純文字或其他資料流中個別獨立區域之間的界限。 編碼方式 識別要用來讀取資料集之字元結構描述資料表的位元。 資料行標題 指出資料集標題 (如果有的話) 的處理方式。 跳過資料列 指出資料集內略過多少資料列 (如果有的話)。 選取 [下一步]。
[結構描述] 表單會根據在 [設定與預覽] 表單中選取的項目以智慧方式填入。 請在此處設定每個資料行的資料類型、檢閱資料行名稱,以及選取針對實驗不要包含哪些資料行。
選取 [下一步]。
[確認詳細資料] 表單上會顯示先前在 [基本資訊] 和 [設定與預覽] 表單中填入的資訊摘要。 您也可以選擇使用啟用分析的計算,為資料集建立資料設定檔。
選取 [下一步]。
在新建立的資料集出現後選取該資料集。 您也可以檢視資料集的預覽和範例統計資料。
在 [設定作業] 表單上,選取 [建立新項目],然後輸入 Tutorial-automl-deploy 作為實驗名稱。
選取目標資料行;這是將要進行預測的資料行。
從現有計算的下拉式清單中選取計算。 若要建立新的計算,請遵循步驟 8 中的指示。
選取 [建立新的計算] 來針對此實驗設定計算內容。
欄位 描述 計算名稱 輸入可識別您計算內容的唯一名稱。 虛擬機器優先順序 雖然低優先順序的虛擬機器較便宜,但無法保證計算節點。 虛擬機器類型 選取 CPU 或 GPU 作為虛擬機器類型。 虛擬機器大小 為您的計算選取虛擬機器大小。 最小/最大節點數 若要分析資料,您必須指定一個或多個節點。 輸入所計算的節點數上限。 預設值為 Azure Machine Learning Compute 的六個節點。 進階設定 這些設定可讓您為您的實驗設定使用者帳戶和現有虛擬網路。 選取 建立。 建立新的計算可能會需要數分鐘。
選取 [下一步]。
在 [工作類型和設定] 表單上,選取工作類型:分類、迴歸,或預測。 如需詳細資訊,請參閱支援的工作類型。
針對 [分類],您也可以啟用深度學習。
針對 [預測],您可以:
啟用深度學習。
選取時間資料行:這個資料行包含要使用的時間資料。
選取預測範圍:指出模型能夠預測未來多少時間單位 (分鐘/小時/天/週/月/年)。 模型需要預測的未來越遠,模型的正確性越低。 深入了解預測及預測範圍。
(選擇性) 檢視其他組態設定:可用來更進一步控制訓練作業的其他設定。 否則會根據實驗選取範圍和資料來套用預設值。
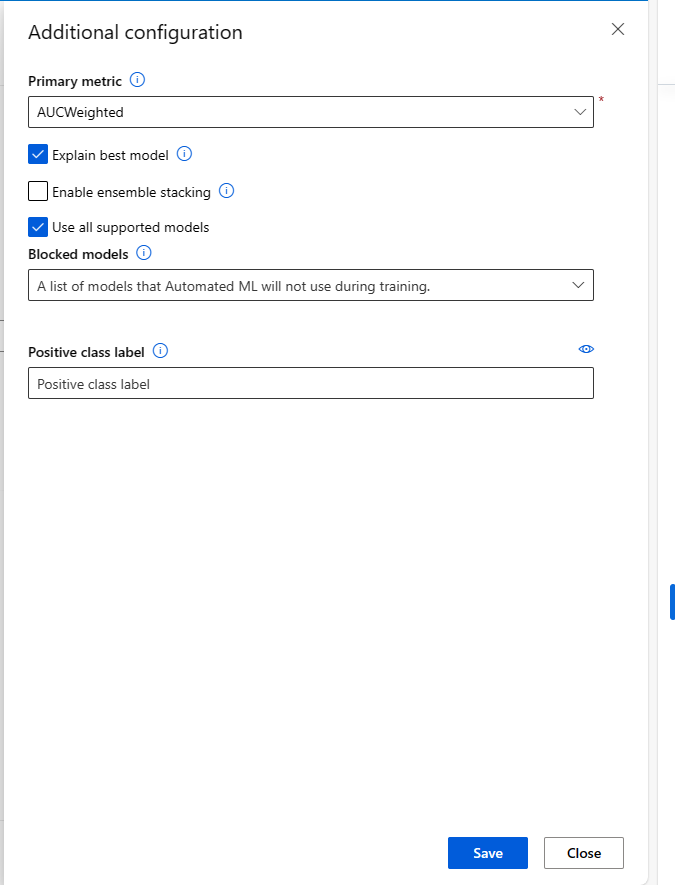
其他設定 描述 主要計量 用來評分模型的主要計量。 深入了解模型計量。 啟用集團堆疊 集團學習藉由結合多個模型來改善機器學習結果和預測效能,而不是使用單一模型。 深入了解集團模型。 已封鎖的模型 選取您要從定型作業中排除的模型。
允許模型僅用於 SDK 實驗。
請參閱每個工作類型支援的模型。解釋最佳模型 自動在自動化 ML 所建立的最佳模型上顯示可解釋性。 正面類別標籤 自動化 ML 將用於計算二進位計量的標籤。 (選擇性) 檢視特徵化設定:如果您選擇在 [其他設定] 表單中啟用 [自動特徵化],則會套用預設的特徵化技術。 在 [檢視特徵化設定] 中,您可以變更這些預設值,並據以進行自訂。 了解如何自訂特徵化。

[選擇性] 限制 表單可讓您執行下列動作。
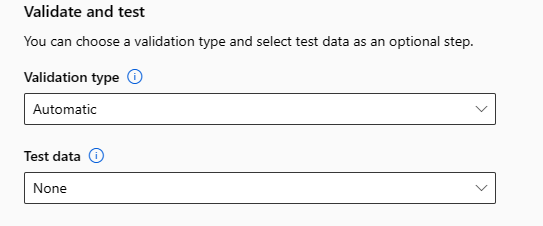
選項 描述 試用上限 在 AutoML 作業期間,每次試驗使用不同演算法和超參數組合嘗試的次數上限。 必須為介於 1 到 1000 之間的整數。 同時試用上限 可平行執行的試用作業數目上限。 必須為介於 1 到 1000 之間的整數。 最大節點數 此作業可從所選的計算目標使用的最大節點數。 計量分數閾值 當反覆運算計量達到此閾值時,定型作業將會終止。 請記住,有意義的模型具有相互關聯 > 0,否則其與猜測平均計量閾值應介於界限 [0, 10] 之間一樣好。 實驗逾時 (分鐘) 允許整個實驗執行的最長時間 (以分鐘為單位)。 一旦達到此限制,系統就會取消 AutoML 作業,包括其所有試用 (子作業)。 反覆運算逾時 (分鐘) 允許每個試用作業執行的最長時間 (以分鐘為單位)。 一旦達到此限制,系統就會取消試用。 啟用提前終止 如果分數未在短期內改善,選取此項以結束作業。 [選擇性] 驗證和測試表單可讓您執行下列作業。
a. 指定要用於訓練作業的驗證類型。 如果您未明確指定 validation_data 或 n_cross_validations 參數,則自動化 ML 會根據在單一資料集 training_data 中提供的資料列數目,套用預設的技巧。
| 定型資料大小 | 驗證技術 |
|---|---|
| 大於 20,000 個資料列 | 套用定型/驗證資料分割。 預設值是以 10% 的初始定型資料集做為驗證集。 接著,該驗證集會用於計量計算。 |
| 小於 20,000 個資料列 | 套用交叉驗證方法。 預設的摺疊數目取決於資料列數目。 如果資料集少於 1,000 個資料列,則會使用 10 個摺疊。 如果資料列介於 1,000 到 20,000 個之間,則會使用三個摺疊。 |
b. 提供測試資料集 (預覽) 來評估自動化 ML 在實驗結束時為您產生的建議模型。 您提供測試資料時,測試作業會在實驗結束時進行自動觸發。 此測試作業只會在自動化 ML 所建議的最佳模型上進行。 學習如何取得遠端測試作業的結果。
重要
提供測試資料集來評估產生的模型是預覽功能。 此功能是實驗性預覽功能,而且可能隨時變更。
* 測試資料會被視為與訓練和驗證不同,因此不會使得建議模型的測試作業結果產生偏差。 深入了解模型驗證期間的偏差。
* 您可以提供自己的測試資料集,或選擇使用訓練資料集的百分比。 測試資料的格式必須是 Azure Machine Learning TabularDataset。
* 測試資料集的結構描述應該符合訓練資料集。 目標資料行是選擇性的,但如果沒有指定目標資料行,則不會計算任何測試單位。
* 測試資料集不應與訓練資料集或驗證資料集相同。
* 預測作業不支援訓練/測試分割。
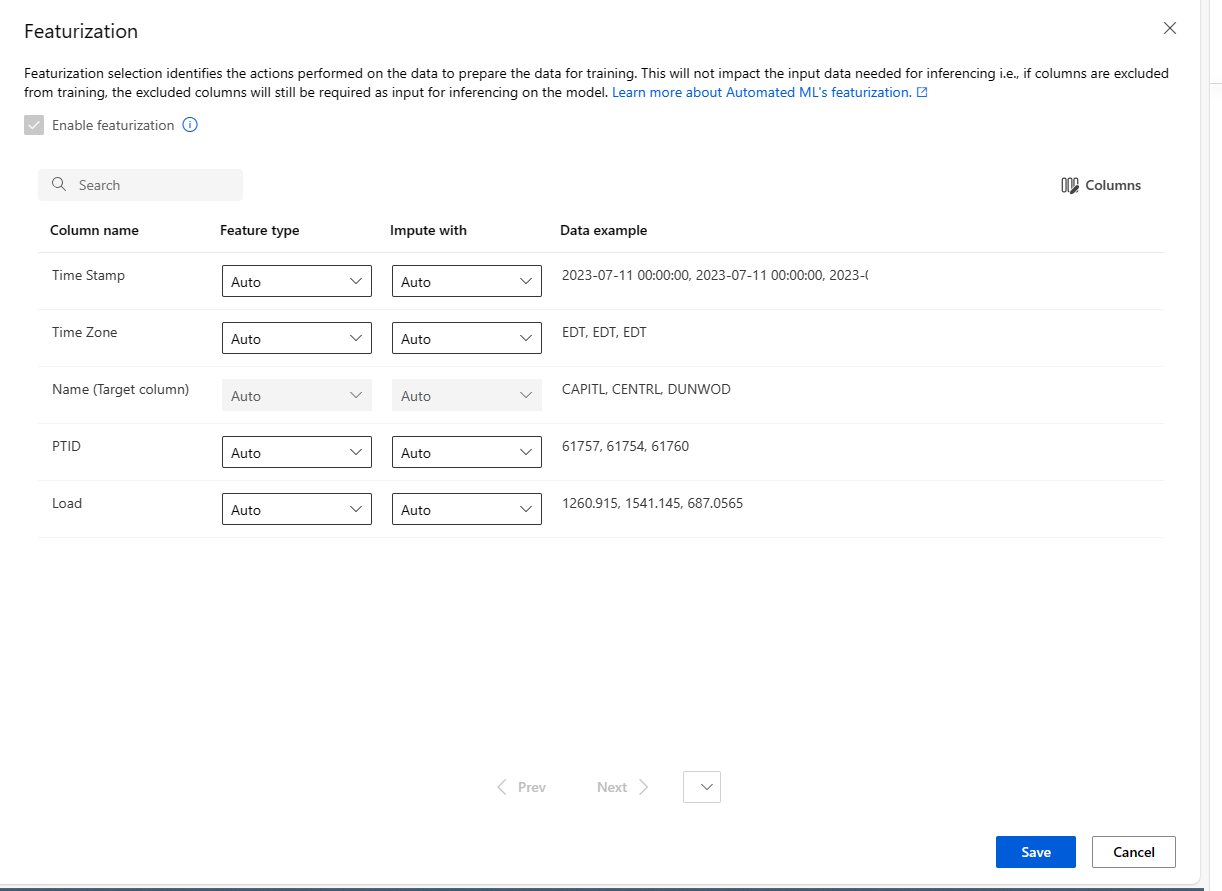
自訂特徵化
在特徵化表單中,您可以啟用/停用自動特徵化,以及為您的實驗自訂自動特徵化設定。 若要開啟此表單,請參閱建立和執行實驗一節中的步驟 10。
下表摘要說明目前可透過工作室完成的自訂。
| 資料行 | 自訂 |
|---|---|
| 功能類型 | 變更所選資料行的實值型別。 |
| 插補 | 選取要在資料中插補遺漏值的值。 |
執行實驗並檢視結果
選取 [完成] 以執行實驗。 實驗準備流程最多需要 10 分鐘。 訓練作業可能需要額外 2-3 分鐘不等,才能讓每個管線完成執行。 如果您已指定為最佳建議模型產生 RAI 儀表板,最多可能需要 40 分鐘的時間。
注意
自動化 ML 採用的演算法具有固有的隨機性,可能會導致建議模型的最終計量分數有些微變化,例如精確度。 自動化 ML 也會在必要時對資料 (例如,訓練測試分割、訓練驗證分割或交叉驗證) 執行作業。 因此,如果您以相同設定和主要計量多次執行實驗,您可能會在每個實驗的最終計量分數中看到這些因素造成的差異。
檢視實驗詳細資料
[作業詳細資料] 畫面會在 [詳細資料] 索引標籤中開啟。此畫面會顯示實驗作業的摘要,並會在頂端作業編號的旁邊包含狀態列。
[模型] 索引標籤包含依計量分數所建立的模型清單。 依預設,根據所選計量評分最高的模型會出現在清單頂端。 如果訓練作業嘗試多個模型,系統會將所有結果新增到清單中。 使用此方式快速比較到目前為止所產生的各個模型計量。
檢視訓練作業詳細資料
在任何已完成的模型上向下切入,以查看訓練作業的詳細資料。
您可以在 [計量] 索引標籤上看到模型特定的效能計量圖表。進一步了解圖表。
您也可在圖表中找到所有模型屬性的詳細資料,以及相關聯的程式碼、子作業和影像。
檢視遠端測試作業的結果 (預覽版)
如果您在實驗設定期間指定測試資料集或選擇訓練/測試分割--在 [驗證和測試] 表單上,自動化 ML 預設會自動測試建議的模型。 如此一來,自動化 ML 會計算測試計量,以判斷建議模型和其預測的品質。
重要
有一項預覽功能是使用測試資料集來測試模型以評估產生的模型。 此功能是實驗性預覽功能,而且可能隨時變更。
警告
下列自動化 ML 案例無法使用此功能
若要檢視建議模型的測試作業計量,
- 瀏覽至 [模型] 頁面,選取最佳模型。
- 選取 [測試結果 (預覽)] 索引標籤。
- 選取您想要的作業,然後檢視 [計量] 索引標籤。

若要檢視用來計算測試計量的測試預測,
- 瀏覽至頁面底部,然後選取 [輸出資料集] 底下的連結,以開啟資料集。
- 在 [資料集] 頁面上,選取 [探索] 索引標籤,以檢視該測試作業的預測。
- 或者,您也可以從 [輸出 + 記錄] 索引標籤檢視/下載預測檔案,您可以展開 [預測] 資料夾以找出您的
predicted.csv檔案。
- 或者,您也可以從 [輸出 + 記錄] 索引標籤檢視/下載預測檔案,您可以展開 [預測] 資料夾以找出您的
或者,您也可以從 [輸出 + 記錄] 索引標籤檢視/下載預測檔案,您可以展開 [預測] 資料夾來找出您的 predictions.csv 檔案。
模型測試作業會產生 predictions.csv 檔案,並儲存在與工作區一起建立的預設資料存放區。 具有相同訂用帳戶的所有使用者都可以看到此資料存放區。 如果測試作業所使用或所建立的任何資訊都必需保密,則不建議使用測試作業。
測試現有的自動化 ML 模型 (預覽)
重要
有一項預覽功能是使用測試資料集來測試模型以評估產生的模型。 此功能是實驗性預覽功能,而且可能隨時變更。
警告
下列自動化 ML 案例無法使用此功能
當您的實驗完成之後,您可以測試自動 ML 為您產生的模型。 如果您想要測試不同自動化 ML 產生的模型,而不是測試建議模型,您可以使用下列步驟來執行此作業。
選取現有的自動化 ML 實驗作業。
瀏覽至作業的 [模型] 索引標籤,然後選取想要測試的已完成模型。
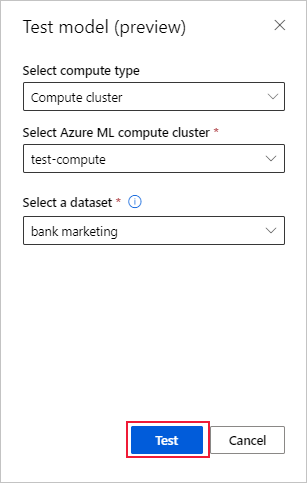
在模型的 [詳細資料] 頁面上,選取 [測試模型 (預覽)] 按鈕,以開啟 [測試模型] 窗格。
在 [測試模型] 窗格中,選取想要用於測試作業的計算叢集和測試資料集。
選取 [測試] 按鈕。 測試資料集的結構描述應該符合訓練資料集,但 [目標資料行] 是選用項目。
成功建立模型測試作業之後,[詳細資料] 分頁會顯示成功訊息。 選取 [測試結果] 索引標籤,以查看作業的進度。
若要檢視測試作業的結果,請開啟 [詳細資料] 分頁,並依照檢視遠端測試作業的結果一節的步驟執行。
負責任 AI 儀表板 (預覽)
若要進一步瞭解您的模型,您可以使用負責任 Ai 儀表板來查看模型的各種深入解析。 其可讓您評估最佳的自動化機器學習模型並予以偵錯。 負責任 AI 儀表板會評估模型錯誤和公平性問題、藉由評估定型和/或測試資料來診斷這些錯誤發生的原因,以及觀察模型說明。 這些深入解析可協助您建立與模型的信任並通過稽核程序。 無法為現有的自動化機器學習模型產生負責任的 AI 儀表板。 只有在建立新的 AutoML 作業時,才會建立最佳建議模型。 使用者應該繼續使用模型說明 (預覽),直到為現有模型提供支持為止。
若要針對特定模型產生負責任 AI 儀表板:
提交自動化 ML 作業時,請前往左側導覽列上的 [工作設定] 區段,然後選取 [檢視其他組態設定] 選項。
在選取後出現的新表單中,選取 [說明最佳模型] 核取方塊。
繼續前往安裝表單的 [計算] 頁面,然後針對您的計算選擇 [無伺服器] 選項。
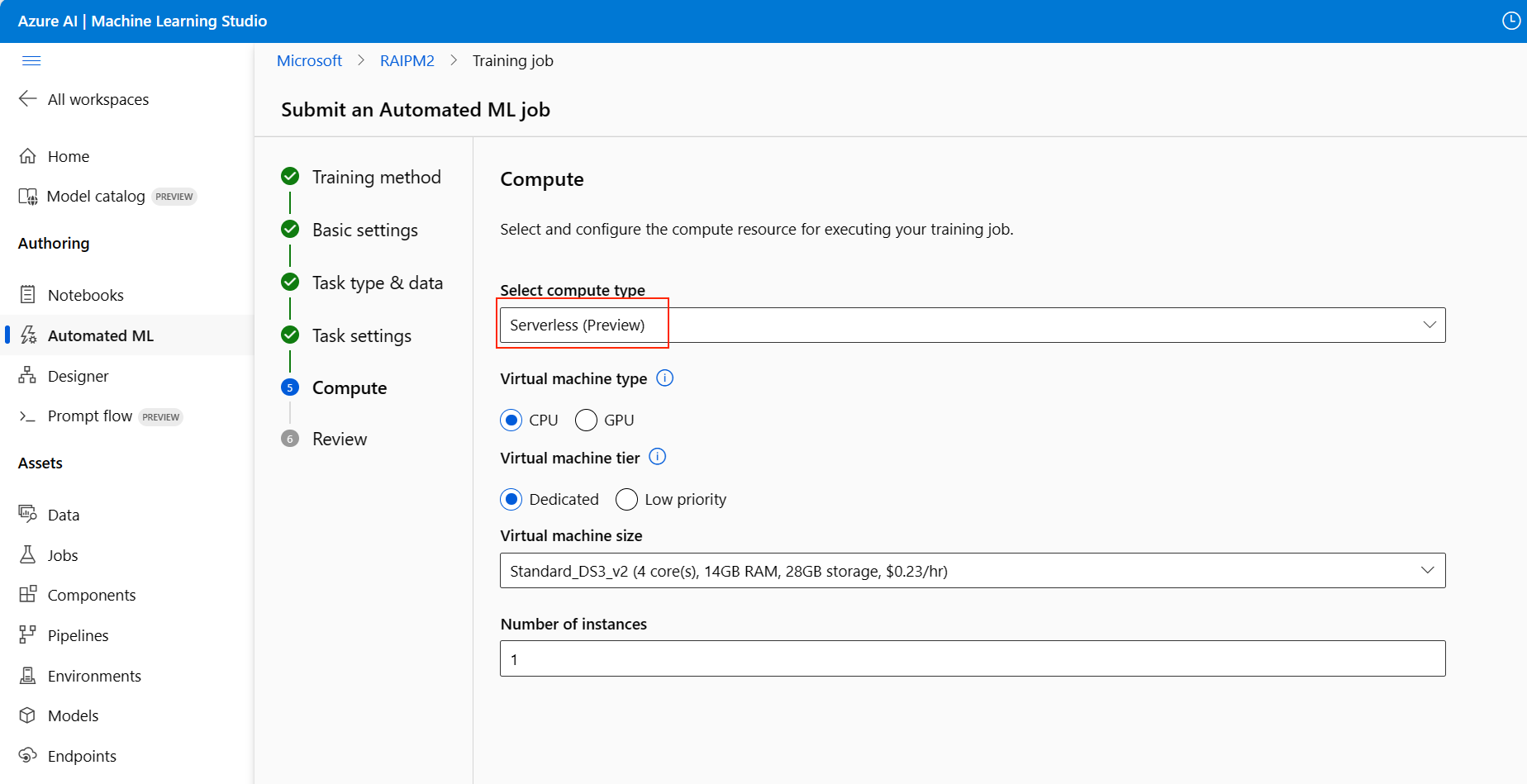
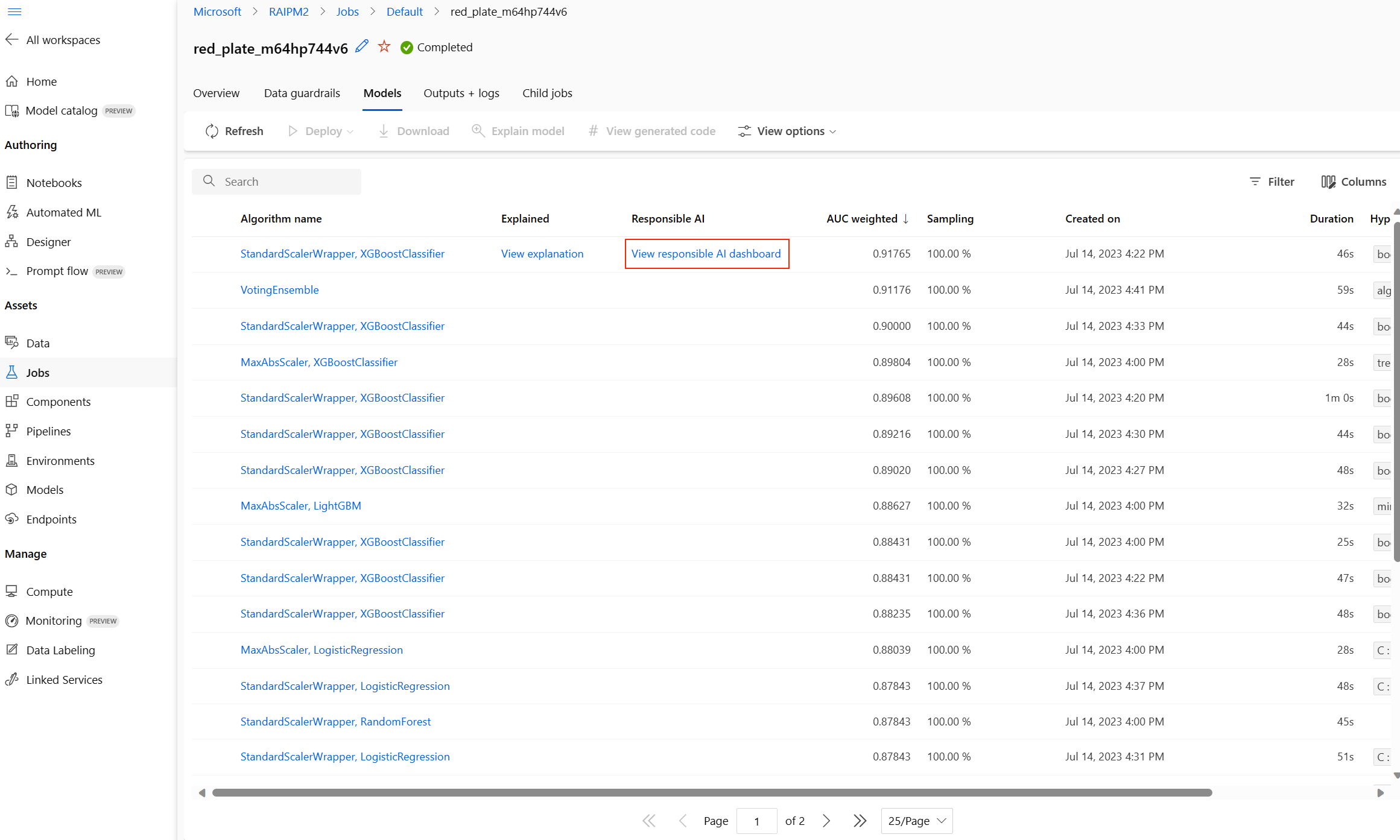
完成後,瀏覽至自動化 ML 作業的 [模型] 頁面,其中包含已定型的模型清單。 在 [檢視負責任 AI 儀表板] 連結上選取:
該模型的負責任 AI 儀表板隨即出現,如下圖所示:
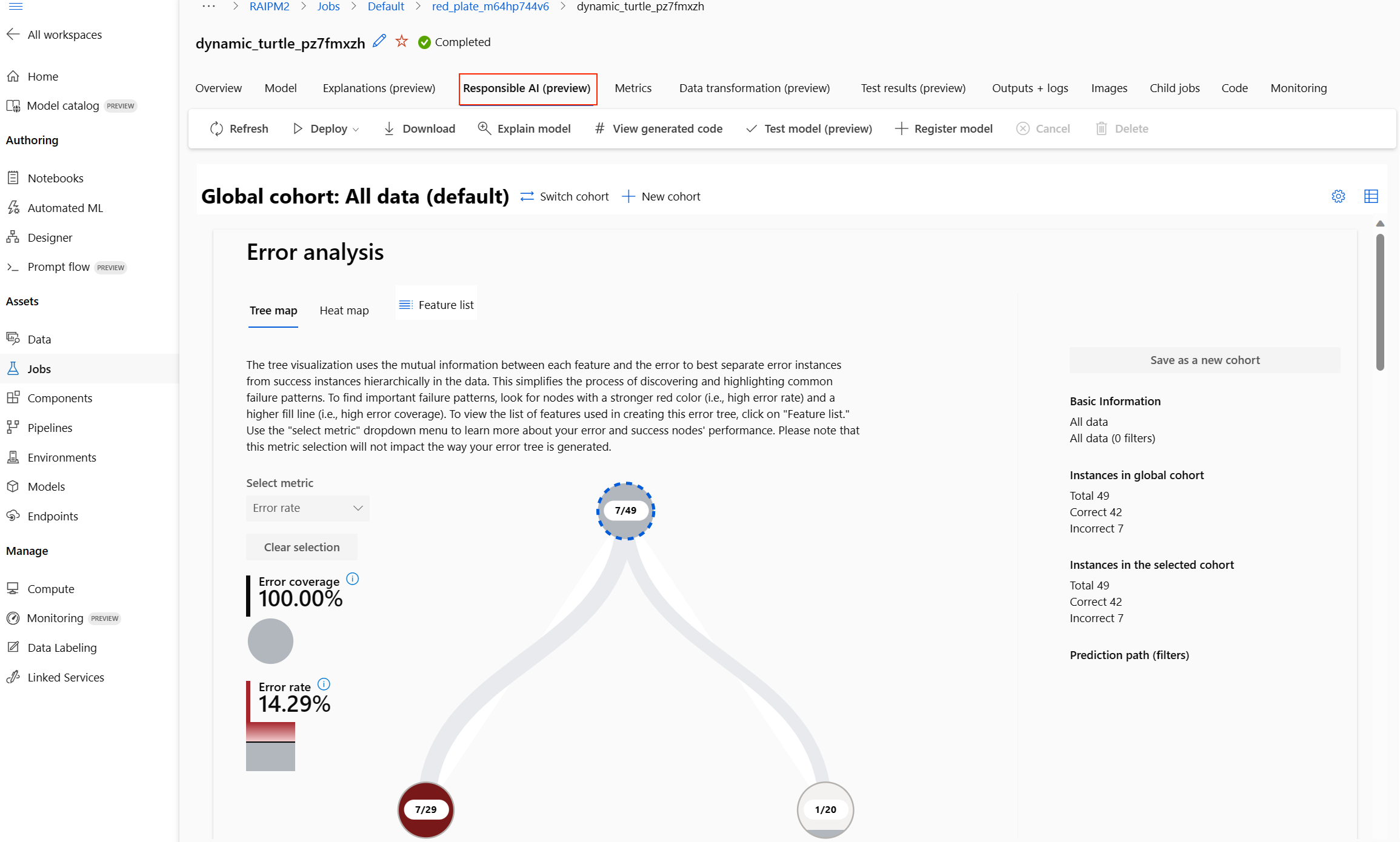
在儀表板中,您會看到四個針對自動化 ML 最佳模型啟用的元件:
| 元件 | 元件會顯示什麼? | 如何讀取圖表? |
|---|---|---|
| 錯誤分析 | 當您需要進行下列作業時,請使用錯誤分析: 深入了解模型失敗在某個資料集、數個輸入和特徵維度間的分佈情況。 細分彙總效能計量,以自動探索錯誤的世代,進而取得鎖定目標的風險降低步驟。 |
錯誤分析圖表 |
| 模型概觀和公平性 | 使用此元件來: 深入了解跨不同資料世代的模型效能。 查看差距計量,瞭解模型公平性問題。 這些計量可以評估及比較以敏感性 (或不敏感) 特徵識別的子群組間的模型行為。 |
模型概觀和公平性圖表 |
| 模型說明 | 使用模型說明元件,藉由查看下列各項來產生人類可理解的機器學習模型預測描述: 全域說明:例如,哪些特徵會影響貸款配置模型的整體行為? 局部說明:例如,客戶的貸款申請為何通過核准或遭到拒絕? |
模型說明能力圖表 |
| 資料分析 | 當您需要進行下列作業時,請使用資料分析: 選取各種篩選條件將資料切割成不同的維度 (也稱為世代),以探索資料集統計資料。 了解資料集在不同世代和特徵群之間的分佈。 判斷資料集的分佈是否影響您對公平性、錯誤分析和因果關係 (衍生自其他儀表板元件) 的調查結果。 決定在哪些方面收集更多資料,以減輕由代表性問題、標籤雜訊、特徵雜訊、標籤偏差等類似因素所引起的誤差。 |
資料總管圖表 |
- 您可以進一步建立世代 (即共用指定特性的資料點子群組),將分析焦點放在不同世代的每個元件上。 目前套用至儀表板的世代名稱一律會顯示在儀表板的左上方。 儀表板中的預設檢視為整個資料集,標題為「所有資料 (預設)」。 在此深入了解儀表板的全域控制。
編輯和提交作業 (預覽版)
重要
根據現有實驗複製、編輯和提交新實驗的功能是預覽功能。 此功能是實驗性預覽功能,而且可能隨時變更。
在您想要根據現有實驗的設定建立新實驗的情況下,自動化 ML 提供在 Studio UI 中使用 [編輯和提交] 按鈕的選項。
這項功能僅限於從 Studio UI 起始的體驗,而且需要新實驗的資料結構描述,以符合原始實驗的資料結構描述。
[編輯並提交] 按鈕會開啟 [建立新的自動化 ML 作業] 精靈,並預先填入資料、計算和實驗設定。 您可以視需要瀏覽每個表單,並視需要編輯新實驗的選取項目。
部署模型
當手邊具備最佳模型時,即可將其作為 Web 服務部署以預測新的資料。
提示
如果您想要使用 Python SDK 來部署透過 automl 套件產生的模型,您必須向工作區註冊您的模型。
當您註冊模型之後,請選取工作室左側窗格中的 [模型] 來尋找該模型。 開啟您的模型之後,您可以選取畫面頂端的 [部署] 按鈕,然後依照部署模型一節中步驟 2 所述的指示進行。
自動化 ML 可協助部署模型,而無須撰寫程式碼:
您有數個部署選項。
選項 1:根據您所定義的計量準則,部署最佳模型。
- 實驗完成後,請選取畫面控制項頂端的 [作業 1],瀏覽至父代執行分頁。
- 選取最佳模型摘要一節中所列的模型。
- 在視窗左上方選取 [部署]。
選項 2:若要從此實驗部署特定模型反覆項目。
- 從 [模型] 索引標籤中選取所需的模型
- 在視窗左上方選取 [部署]。
填入 [部署模型] 窗格。
欄位 值 名稱 輸入部署的唯一名稱。 描述 輸入描述以更清楚地識別此部署的用途。 計算類型 選取想要部署的端點類型:Azure Kubernetes Service (AKS) 或 Azure 容器執行個體 (ACI)。 計算名稱 僅適用於 AKS:選取您要部署至的 AKS 叢集名稱。 啟用驗證 選取允許以權杖為基礎或以金鑰為基礎的驗證。 使用自訂部署資產 若想要上傳自己的評分指令碼和環境檔案,請啟用此功能。 否則,自動化 ML 會依預設來為您提供這些資產。 深入了解評分指令碼。 重要
檔案名稱必須少於 32 個字元,且必須以英數字元開始及結束。 其中可包含虛線、底線、點和英數字元。 不允許空格。
「進階」功能表提供預設部署功能,例如資料收集和資源使用率設定。 若想要覆寫這些預設,請在此功能表中進行。
選取部署。 部署需要約 20 分鐘才能完成。 開始部署後,會出現 [模型摘要] 索引標籤。 請參閱部署狀態一節底下的部署進度。
現在您已擁有可運作的 Web 服務,可用來產生預測! 您可從 Power BI 內建的 Azure Machine Learning 支援以透過查詢服務來測試預測。
下一步
- 了解自動化機器學習結果。
- 深入了解自動化機器學習和 Azure Machine Learning。