教學課程:設計工具 - 定型無程式碼迴歸模型
使用 Azure Machine Learning 設計工具來定型線性迴歸模型,以預測汽車價格。 本教學課程是兩部分系列的第一部分。
本教學課程使用 Azure Machine Learning 設計工具,如需詳細資訊,請參閱什麼是 Azure Machine Learning 設計工具?
注意
設計工具支援兩種類型的元件:傳統預先建置的元件 (v1) 和自訂元件 (v2)。 這兩種類型的元件互不相容。
傳統預先建置元件主要提供用於資料處理和傳統機器學習工作 (例如迴歸和分類) 的預先建置元件。 此類型的元件會繼續受到支援,但將不會新增任何新元件。
自訂元件可讓您包裝自己的程式碼作為元件。 它支援跨工作區共用元件,及跨 Studio、CLI v2 和 SDK v2 介面的無縫製作。
對於新專案,我們強烈建議您使用與 AzureML V2 相容的自訂元件,並且會持續接收新的更新。
本文適用於傳統預先建置元件,且與 CLI v2 和 SDK v2 不相容。
在教學課程的第一部分,您將瞭解如何:
- 建立新管線。
- 匯入資料。
- 準備資料。
- 將機器學習模型定型。
- 評估機器學習模型。
在教學課程的第二部分,您會將模型部署為即時推斷端點,以根據傳送的技術規格預測任何汽車的價格。
注意
本教學課程完成後,將可作為範例管線。
若要尋找此範例,請移至工作區中的設計工具。 在 [新管線] 區段中,選取 [範例 1 - 迴歸:汽車價格預測 (基本)]。
重要
如果您看不到這份文件中提及的圖形元素,例如工作室或設計工具中的按鈕,可能是您沒有工作區的正確權限層級。 請洽詢您的 Azure 訂用帳戶管理員,以確認您已獲得授與正確的存取層級。 如需詳細資訊,請參閱管理使用者和角色。
建立新管線
Azure Machine Learning 管線會將多個機器學習和資料處理步驟組織成單一資源。 管線可讓您在不同的專案和使用者間組織、管理和重複使用複雜的機器學習工作流程。
若要建立 Azure Machine Learning 管線,您必須要有 Azure Machine Learning 工作區。 在本節中,您將了解如何建立這些資源。
建立新工作區
您需要 Azure Machine Learning 工作區,才能使用設計工具。 工作區是 Azure Machine Learning 的最上層資源,其提供一個集中位置來處理您在 Azure Machine Learning 中建立的所有成品。 如需建立工作區的指示,請參閱建立工作區資源。
注意
如果您的工作區使用虛擬網路,您必須使用其他設定步驟來使用設計工具。 如需詳細資訊,請參閱在 Azure 虛擬網路中使用 Azure Machine Learning 工作室
建立管線
注意
設計工具支援兩種類型的元件:傳統預先建置的元件和自訂元件。 這兩種類型的元件互不相容。
傳統預先建置的元件主要提供用於資料處理和傳統機器學習工作 (例如迴歸和分類) 的預先建置元件。 此類型的元件會繼續受到支援,但將不會新增任何新元件。
自訂元件可讓您提供自己的程式碼作為元件。 其支援跨工作區共用,且可跨 Studio、CLI 和 SDK 介面順暢製作。
此文章適用於傳統預先建置的元件。
登入 ml.azure.com,並選取您要使用的工作區。
選取 [設計工具] > [傳統預建]>
選取 [使用傳統預建元件建立新管線]。
在自動產生的管線草稿名稱旁按一下鉛筆圖示,將其重新命名為「汽車價格預測」。 此名稱不必是唯一的。

匯入資料
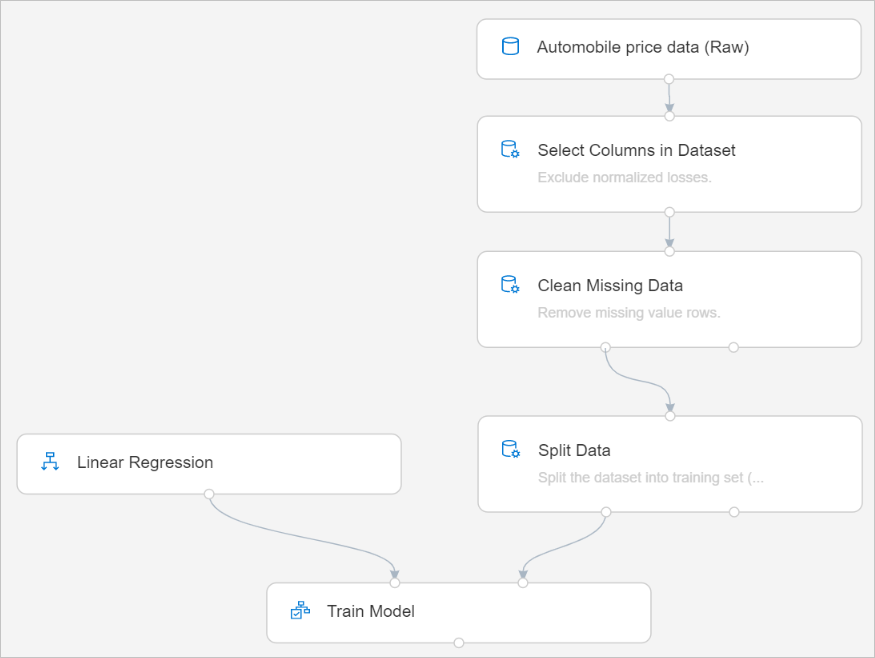
設計工具中包含數個範例資料集,可供您在實驗時使用。 在本教學課程中,使用汽車價格資料 (未經處理)。
管線畫布左側是資料集和元件的選擇區。 選取 [元件] > [範例資料]。>
選取資料集汽車價格資料 (原始),並將其拖曳到畫布上。

將資料視覺化
您可以將資料視覺化,以了解您將使用的資料集。
以滑鼠右鍵按一下 [汽車價格資料 (未經處理)],然後選取 [預覽資料]。
選取資料視窗中的不同資料行,以檢視各個資料行的相關資訊。
每個資料列分別代表一款汽車,而與每款汽車相關聯的變數會顯示為資料行。 此資料集中有 205 個資料列和 26 個資料行。
準備資料
資料集在分析之前通常需進行一些前置處理。 您在檢查資料集時,可能會發現有某些遺漏值。 必須清除這些遺漏的值,才能讓模型正確地分析資料。
移除資料行
當您定型模型時,您必須對遺漏的資料採取某些動作。 在此資料集中,自負虧損資料行遺漏了許多值,因此您會將該資料行完全排除於模型外。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋選取資料集中的資料行元件。
將 [選取資料集中的資料行] 元件拖曳至畫布上。 將元件放在資料集元件下方。
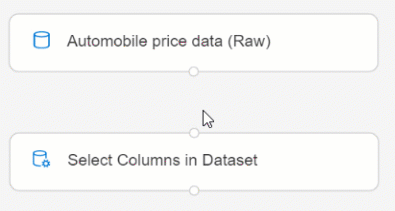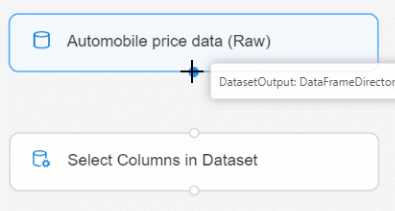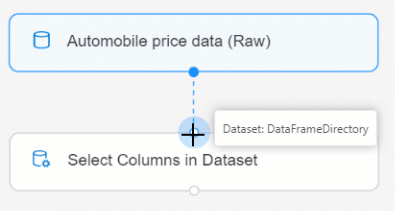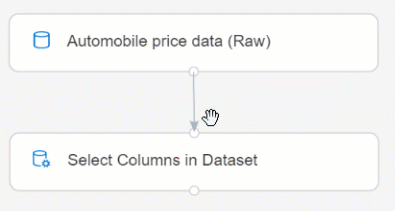
將 [汽車價格資料 (v)] 資料集連線至 [選取資料集中的資料行] 元件。 從資料集的輸出連接埠 (即畫布上位於資料集底部的小圓圈) 拖曳至 [選取資料集中的資料行] 的輸入連接埠 (即元件頂端的小圓圈)。
提示
將某個元件的輸出連接埠連線至另一個元件的輸入連接埠時,系統便會透過管線建立資料流程。
選取 [選取資料集中的資料行] 元件。
在畫布右側的 [設定] 下,按一下箭號圖示,開啟元件詳細資料窗格。 您也可以按兩下 [選取資料集中的資料行] 元件,開啟詳細資料窗格。
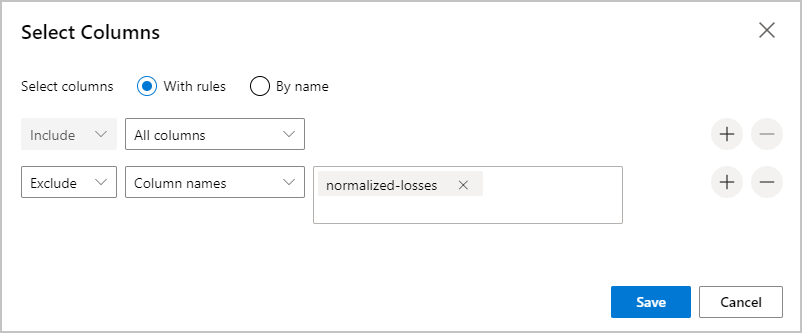
在窗格右側,選取 [編輯資料行]。
展開 [包含] 旁的 [資料行名稱] 下拉式清單,然後選取 [所有資料行]。
選取 + 以新增規則。
從下拉式功能表中,選取 [排除] 和 [資料行名稱]。
在文字方塊中輸入自負虧損。
在右下方選取 [儲存] 按鈕,以關閉資料行選取器。
在 [選取資料集中的資料行] 元件詳細資料窗格中,展開 [節點資訊]。
選取 [註解] 文字輸入框,然後輸入「排除正常損失」。
圖形上會出現註解,以協助您組織管線。
清除遺漏的資料
移除自負虧損資料行之後,您的資料集仍有遺漏值。 您可以使用 [清除遺漏的資料] 元件來移除其餘遺漏的資料。
提示
在使用設計工具中大部分的元件時,都必須從輸入資料中清除遺漏值。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋清除遺漏資料元件。
將 [清除遺漏的資料] 元件拖曳至管線畫布上。 將其連線至 [選取資料集中的資料行] 元件。
選取清除遺漏資料元件。
在畫布右側的 [設定] 下,按一下箭號圖示,開啟元件詳細資料窗格。 或者,您可以按兩下 [清除遺漏資料] 元件,開啟詳細資料窗格。
在窗格右側,選取 [編輯資料行]。
在顯示的 [要清除的資料行] 視窗中,展開 [包含] 旁的下拉式功能表。 選取 [所有資料行]
選取儲存
在 [清除模式] 下的 [清除遺漏資料] 元件詳細資料窗格中,選取 [移除整個資料列]。
在 [清除遺漏資料] 元件詳細資料窗格中,展開 [節點資訊]。
選取 [註解] 文字輸入框,然後輸入 [移除遺漏的值資料列]。
您的管線此時應會顯示如下:

將機器學習模型定型
現在您已備妥用來處理資料的元件,接下來即可設定定型元件。
因為要預測價格,也就是一個數字,因此您將使用迴歸演算法。 在此範例中,您將使用線性迴歸模型。
分割資料
分割資料是機器學習服務中常見的工作。 您會將資料分割成兩個不同的資料集。 一個資料集會定型模型,另一個則會測試模型的執行效果。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋分割資料元件。
將 [分割資料] 元件拖曳至管線畫布上。
將 [清除遺漏的資料] 元件的左側連接埠,連線至 [分割資料] 元件。
重要
請確定清除遺漏資料的左側輸出連接埠連接至分割資料。 左側連接埠包含已清除的資料。 右側連接埠包含已捨棄的資料。
選取 [分割資料] 元件。
在畫布右側的 [設定] 下,按一下箭號圖示,開啟元件詳細資料窗格。 或者,您可以按兩下 [分割資料] 元件,開啟詳細資料窗格。
在 [分割資料] 詳細資料窗格中,將第一個輸出資料集的資料列比例設為 0.7。
此選項會分割 70% 的資料來定型模型,而 30% 供測試之用。 70% 的資料集將透過左側輸出連接埠來存取。 其餘資料可透過右側輸出連接埠取得。
在 [分割資料] 詳細資料窗格中,展開 [節點資訊]。
選取 [註解] 文字輸入框,然後輸入將資料集分割為訓練集 (0.7) 和測試集 (0.3)。
定型模型
藉由提供一個包含價格的資料集,將模型定型。 此演算法會建立一個模型,用以說明定型資料所呈現的特性與價格之間的關聯性。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋線性迴歸元件。
拖曳 [線性回歸] 元件至管線畫布。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋定型模型元件。
拖曳 [定型模型] 元件至管線畫布。
將 [線性迴歸] 元件的輸出,連線至 [定型模型] 元件的左側輸入。
將 [分割資料] 元件的定型資料輸出 (左側連接埠),連線至 [定型模型] 元件的右側輸入。
重要
請確定分割資料的左側輸出連接埠已連接至定型模型。 左側連接埠包含定型集。 右側連接埠包含測試集。
選取 [定型模型] 元件。
在畫布右側的 [設定] 下,按一下箭號圖示,開啟元件詳細資料窗格。 或者,您可以按兩下 [定型模型] 元件,開啟詳細資料窗格。
在窗格右側,選取 [編輯資料行]。
在顯示的 [標籤資料行] 視窗中展開下拉式功能表,然後選取 [資料行名稱]。
在文字方塊中輸入價格,以指定您的模型要預測的值。
重要
請確定您輸入的資料行名稱完全相符。 price 的首字母請勿使用大寫。
您的管線應會顯示如下:
新增評分模型元件
使用 70% 的資料來定型模型後,您即可將該模型用來為其他 30% 的資料評分,以了解模型的運作是否理想。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋計分模型元件。
拖曳 [計分模型] 元件至管線畫布。
將 [定型模型] 元件的輸出,連線至 [評分模型] 的左側輸入連接埠。 將 [分割資料] 元件的測試資料輸出 (右側連接埠),連線至 [評分模型] 的右側輸入連接埠。
新增評估模型元件
使用 [評估模型] 元件,評估模型在測試資料集下的評分。
在畫布左側的資料集和元件選擇區中,按一下 [元件],然後搜尋評估模型元件。
拖曳 [評估模型] 元件至管線畫布。
將 [評分模型] 元件的輸出,連線至 [評估模型] 的左側輸入。
最終的管線應會顯示如下:
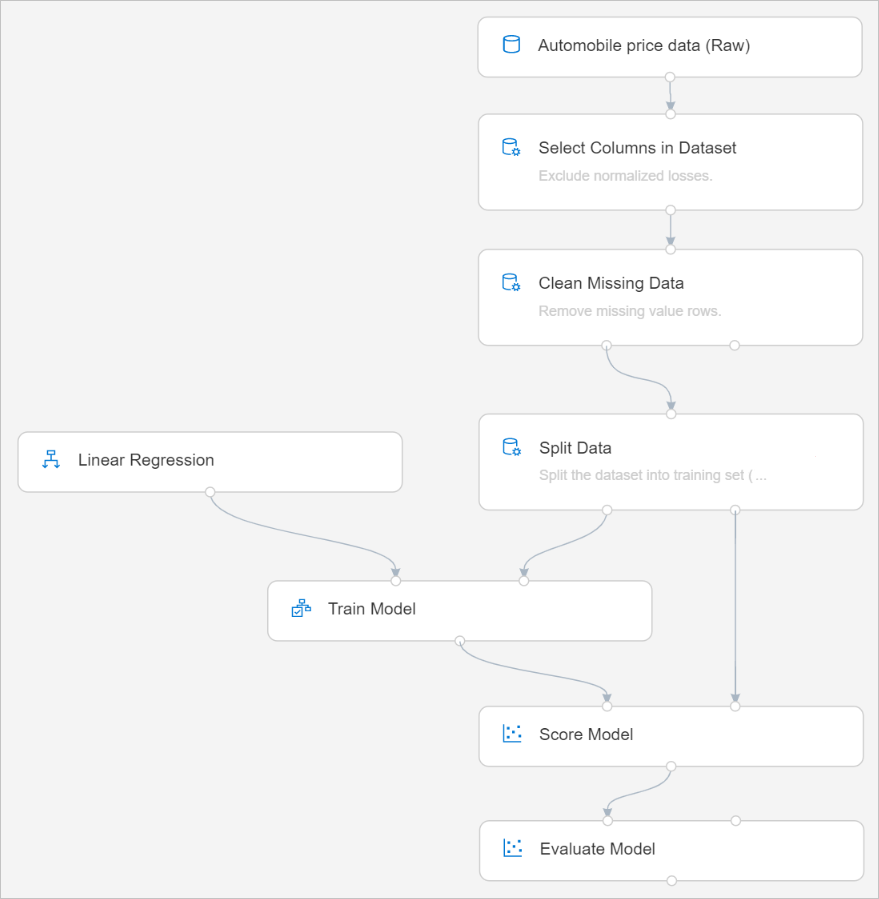
提交管線
選取右上角的 [設定與提交] 以提交管線。

接著您會看到逐步精靈,請遵循精靈來提交管線作業。


在 [基本] 步驟中,您可以設定實驗、作業顯示名稱、作業描述等。
在 [輸入與輸出] 步驟中,您可以指派值給升階為管線層級的輸入/輸出。 在此範例中,這會是空的,因為我們未將任何輸入/輸出升階為管線層級。
在 [執行階段設定] 中,您可以設定管線的預設資料存放區和預設計算。 這是管線中所有元件的預設資料存放區/計算。 不過,如果您明確為元件設定不同的計算或資料存放區,則系統會遵守元件層級設定。 否則會使用預設值。
[檢閱 + 提交] 步驟是提交之前檢閱所有設定的最後一個步驟。 如果您曾經提交管線,精靈會記住您最後的設定。
提交管線作業之後,頂端會有一則訊息,其中包含作業詳細資料的連結。 您可以選取此連結來檢閱作業詳細資料。

檢視評分標籤
在 [作業詳細資料] 頁面中,您可以檢查管線作業狀態、結果和記錄。
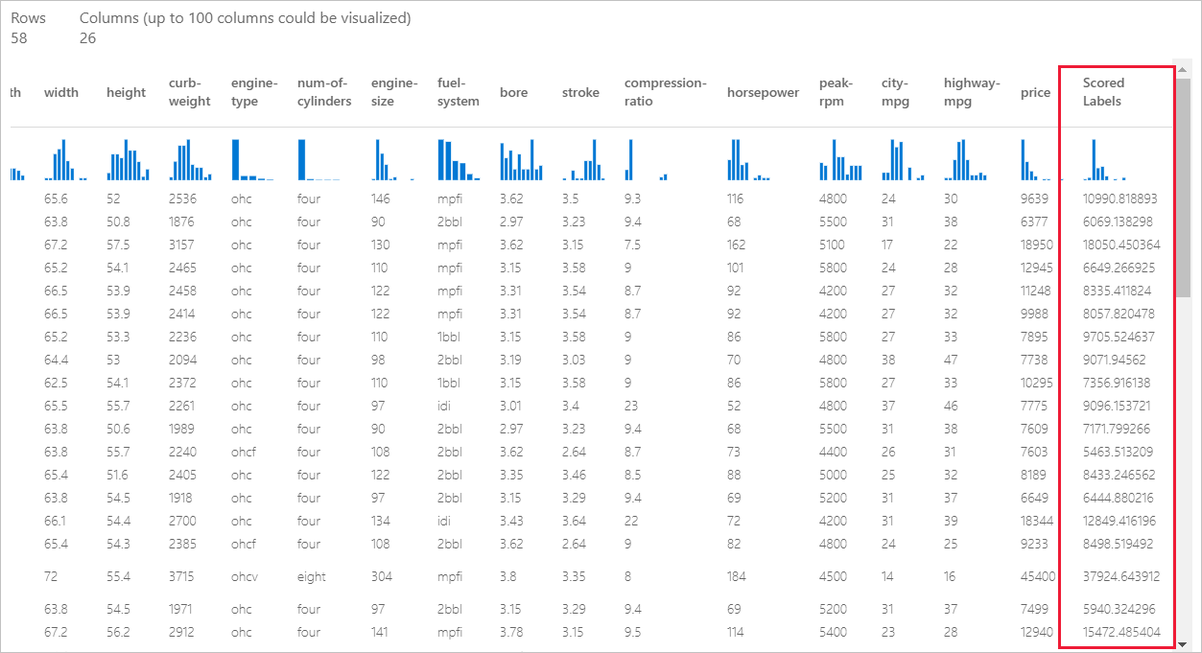
作業完成後,您可以檢視管線作業的結果。 首先,請查看迴歸模型產生的預測。
以滑鼠右鍵按一下 [評分模型] 元件,然後選取 [預覽資料]>[評分資料集] 以檢視其輸出。
您可以在這裡看到測試資料中的預測價格和實際價格。
評估模型
使用評估模型,查看定型模型對測試資料集的執行效果。
- 以滑鼠右鍵按一下 [評估模型] 元件,然後選取 [預覽資料]>[評估結果] 以檢視其輸出。
您的模型會顯示下列統計資料:
- 平均絕對誤差 (MAE):絕對誤差的平均值。 誤差是指預測值與實際值之間的差異。
- 均方根誤差 (RMSE):對測試資料集所做之預測的平方誤差的評分根平均值。
- 相對絕對誤差:相對於實際值與所有實際值之平均值之間的絕對差異的絕對誤差平均值。
- 相對平方誤差:相對於實際值與所有實際值之平均值之間的平方差異的平方誤差平均值。
- 決定係數:也稱為 R 平方值,這是一個統計度量,可指出模型對於資料的適用程度。
針對每個誤差統計資料,越小越好。 值越小,表示預測越接近實際值。 就決定係數而言,其值愈接近一 (1.0),預測就愈精準。
清除資源
如果您想要繼續進行本教學課程的第2部分:部署模型,請略過本節。
重要
您可以使用您所建立的資源,作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
刪除所有內容
如果您不打算使用所建立的任何資源,請刪除整個資源群組,以免產生任何費用。
在 Azure 入口網站中,於視窗左側選取 [資源群組]。

在清單中,選取您所建立的資源群組。
選取 [刪除資源群組]。
刪除資源群組同時會刪除您在設計工具中建立的所有資源。
刪除個別資產
在建立實驗的設計工具中,藉由選取個別資產,再選取 [刪除] 按鈕,即可刪除個別資產。
您在這裡建立的計算目標會在不使用時自動調整為零個節點。 如此可將費用降至最低。 如果您想要刪除計算目標,請採取下列步驟:

您可以選取每個資料集並選取 [取消註冊],從工作區中將資料集取消註冊。

若要刪除資料集,請使用 Azure 入口網站或 Azure 儲存體總管移至儲存體帳戶,並手動刪除這些資產。
下一步
在第二部分中,您將了解如何將模型部署為即時端點。