評估機率函數
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
使指定的機率分配函數符合資料集
類別: 統計函數
模組概觀
本文說明如何使用 機器學習 Studio 中的評估機率函式模組, (傳統) ,來計算描述資料行分佈的統計量值,例如 (點陣圖、Pareto 或 Poisson 分佈。
若要使用此模型,請連接包含至少一個數值資料行的資料集,然後選擇要測試的機率分佈。 模組會傳回包含指定機率函式值的資料表。
您可以計算所選機率分佈的任何這些值:
- cdf) 累積分配 函 式 (
- inverseCdf (inverseCdf)
- pdf) 的機率密度函式 (
為什麼機率分佈很有用?
當您根據機率分佈評估資料時,您會針對具有已知屬性的一組值對應資料行值。 藉由瞭解您的資料是否對應到這些已知散發的其中一個,您可能會推斷資料的其他屬性。 一般而言,當您可以識別最適合資料的分佈時,可以從模型取得更好的預測。
要使用哪種機率分佈函數的問題取決於要測量的資料及變數。 例如,某些分佈是設計來描述離散值的機率;其他專案僅供連續數值變數使用。 對於某些散發,您也必須事先知道預期的平均數、自由度等等。 如需詳細資訊,請參閱 支援的機率分佈
如何設定評估機率函式
所有選項都會根據您想要計算的機率分佈類型而變更。 如果您變更機率分配方法,您可能已進行的其他選取專案會重設。
因此,請務必先選擇 [散發 ] 選項!
做為輸入的資料集應該包含數值資料。 會忽略其他類型的資料。
針對每個分析,您可以套用單一機率分配方法。 若要計算不同的機率分佈,請為每個您想要測試的分佈新增個別的模組實例。
連線包含至少一個數位資料行的資料集。
使用 [ 分佈 ] 選項來選取您想要計算的機率分佈種類。 如需選項清單及其必要引數,請參閱 支援的機率分佈 。
設定分佈所需的任何參數。
選擇三個統計資料的其中一個:累積分配函數 (cdf) 、反向累計分配函數 (InverseCdf) 或 pdf) 的 Probability 密度 (函數。
使用資料行選取器來選擇用來計算所選機率分佈的資料行。
您選取的所有資料行都必須具有數值資料類型。
資料行中的資料範圍也必須有效 (假設有選取的機率函數)。 否則,可能會發生錯誤或 NaN 結果。
在疏鬆資料行中,將不會處理任何對應至背景零的值。
使用 [結果模式] 選項來指定如何輸出結果。 您可以將資料行值取代為機率分佈值,將新值附加至資料集,或者僅傳回機率分佈值。
執行實驗,或以滑鼠右鍵按一下 [評估機率函式 ] 模組,然後按一下 [ 執行] 選取。
結果
下表包含來自樹系Fires範例資料集的單一溫度資料行上,使用Append選項的結果範例。
| temp | StandardNormal.Cdf (temp) | StandardNormal.Pdf (暫存) | FFisher.cdf (temp | FFisher.cdf (temp |
|---|---|---|---|---|
| 8.2 | 1 | 1 | 0.984774 | 0.004349 |
| 18 | 1 | 1 | 0.997896 | 0.000311 |
| 14.6 | 1 | 1 | 0.996352 | 0.000648 |
| 8.3 | 1 | 1 | 0.985201 | 0.004187 |
| 11.4 | 1 | 1 | 0.993147 | 0.001502 |
產生的資料行標題包含使用的機率分佈。
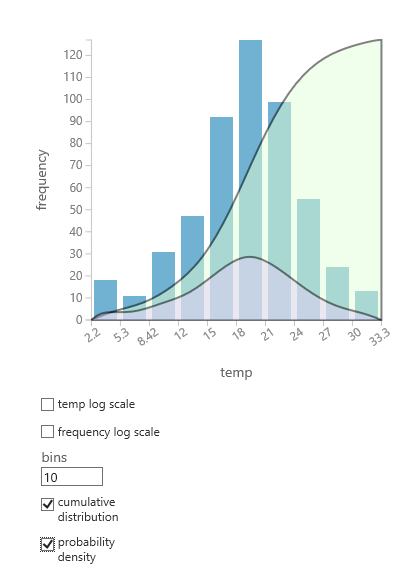
如果您不確定哪些機率分佈可能符合您的資料,您可以為任何數值資料行建立累積分佈和機率密度的快速圖表。
- 以滑鼠右鍵按一下資料集或模組輸出,然後選取 [ 視覺化]。
- 選取感興趣的資料行,然後在 [直 方圖] 窗格中,選取 累積分佈 或 機率密度。
- 分佈的圖表如下,會在代表資料的長條圖上加加。
支援的機率分佈
評估機率函式模組支援下列分佈:
白努利
當可能只有兩個值時,此散發是二進位值的分佈:換句話說,它只會建立預期分佈的模型。
若要計算,請選取 [Bernoulli],然後設定下列選項:
- 成功的機率
參數 p 指定產生 1 的機率。 輸入介於 0.0 與 1.0 之間的數字 (float),以指定成功的機率。 預設值為 0.5。
Beta
Beta 分佈是連續的單一分佈。
若要計算,請選取 [Beta],然後設定下列選項:
圖形
輸入值,以變更分佈的圖形。圖形參數是未定義其位置或範圍的任何機率分佈參數。 因此,當您輸入圖形的值時,參數會變更分佈的圖形,而不是移動、拉伸或收縮圖形。
此值必須是數字 (
double)。 預設值為 1.0。調整
輸入要用於調整分佈的數字。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
上限
輸入數字 (double),以代表分佈上限。 預設值為 1.0。下限
輸入數字 (double),以代表分佈下限。 預設值為 0.0。
二項式
二項分配是離散的單變數分佈。 二項式分佈用來建立樣本中成功次數的模型。 取樣時會使用置回。 在不置回取樣中,使用超幾何分佈。
若要計算,請選取 [二項],然後設定下列選項:
成功的機率
輸入介於 0.0 與 1.0 之間的數字 (float),以指出成功的機率。 預設值為 0.5。試驗次數
指定試驗的次數。integer使用 最小值為 1 的 。 預設值為 3。
柯西
柯西分佈是對稱的連續機率分佈。
若要計算,請選取 [Cauchy],然後設定下列選項:
位置
輸入代表第0 個專案位置的數位 (double) 。透過指定 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
卡方
chi-square 分佈是 k 獨立、標準、標準、隨機變數平方的總和。
若要計算,請選取 [ChiSquare],然後設定下列選項:
- 自由度數 輸入數位 (
double) 以指定自由度。 預設值為 1.0。
ChiSquareRightTailed
此選項提供右尾的 chi-squared 分佈。
若要計算,請選取 [ChiSquareRightTailed],然後設定下列選項:
- 自由度的數目
輸入數字 (double),以指定自由度。 預設值為 1.0。
指數
指數分佈是透過由一個非負數參數所參數化之實數進行的分佈。
若要計算,請選取 [指數],然後設定下列選項:
- Lambda
輸入數字 (double),以作為 Lambda 參數。 預設值為 1.0。
FFisher
產生樣本的雪地統計資料機率,也稱為「雪地 F 分佈」。 這是雙邊分佈。
若要計算,請選取 FFisher,然後設定下列選項:
分子自由度
輸入數字 (double),以指定在分子中使用的自由度。 預設值為 3.0。分母自由度
輸入數字 (double),以指定在分母中使用的自由度。 預設值為 6.0。
FFisherRightTailed
建立右尾的雪地分佈。 費雪分佈也稱為費雪 F 分佈、Snedecor 分佈或費雪 Snedecor 分佈。 這種特定形式的分佈是右尾分佈。
若要計算,請選取 FFisherRightTailed,然後設定下列選項:
分子自由度
輸入數字 (double),以指定在分子中使用的自由度。 預設值為 3.0。分母自由度
輸入數字 (double),以指定在分母中使用的自由度。 預設值為 6.0。
色差補正
Gamma 分佈是具有兩個參數的一系列連續機率分佈。 例如,卡方是一種特殊的 Gamma 分佈。
若要計算,請選取 [Gamma],然後設定下列選項:
調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
位置
輸入代表第0 個專案位置的數位 (double) 。透過指定 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
GeneralizedExtremeValues
建立開發以處理極端值的分佈。 廣義極值 (GEV) 分佈實際上是一組連續的機率分佈,其結合了耿貝爾、弗雷歇和韋伯分佈 (也稱為類型 I、II 和 III 極值分佈)。
如需極端值理論的詳細資訊,請參閱 Wikipedia: Fisher-Tippet-Gnedenko 定理中的這篇文章。
若要計算,請選取 [一般化][ExtremeValues],然後設定下列選項:
圖形
輸入值,以變更分佈的圖形。圖形參數是未定義其位置或範圍的任何機率分佈參數。 因此,當您輸入圖形的值時,參數會變更分佈的圖形,而不是移動、拉伸或收縮圖形。
此值必須是數字 (
double)。 預設值為 1.0。調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
位置
輸入代表第0 個元素位置的數位 (double) 。透過輸入 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
幾何
幾何分佈是透過一個正實數參數化之正整數的分佈。
若要計算,請選取 [幾何],然後設定下列選項:
- 成功的機率
輸入介於 0.0 與 1.0 之間的數字 (float),以指出成功的機率。 預設值為 0.5。
注意
幾何分佈的這個實作不會產生零。
GumbelMax
耿貝爾分佈是數個極值分佈中的一個。 [GumbelMax] 選項會實作最大極值類型 1 分佈。
若要計算,請選取 [一文][一節],然後設定下列選項:
調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
位置
輸入代表第0 個元素位置的數位 (double) 。透過輸入 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
GumbelMin
耿貝爾分佈是數個極值分佈中的一個。 耿貝爾分佈也稱為最小極值 (SEV) 分佈或最小極值 (類型 I) 分佈。 [!提示]BelMin選項會實作最小極端數值型別 1 分佈。
若要計算,請選取 [一律使用一次],然後必須設定下列選項:
調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
位置
輸入代表第0 個元素位置的數位 (double) 。透過輸入 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
超幾何
超對稱分佈是一種離散機率分佈,描述從有限母體中擷取而未取代的 n 序列成功次數,就像二項分配描述使用取代繪製的成功次數一樣。
若要計算,請選取 [超對稱],然後設定下列選項:
範例數
輸入整數,指出要使用的樣本數目。 預設值為 9。成功的次數
輸入整數,以定義成功的值。 預設值為 24。母體大小
指定在估計超幾何分佈時所要使用的母體大小。
拉普拉斯
Laplace 分佈是實數的分佈,以平均數和刻度參數來參數化。
若要計算,請選取 [Laplace 分佈],然後設定下列選項:
調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
位置
輸入代表第0 個元素位置的數位 (double) 。透過輸入 [位置] 參數的值,您可以將機率分佈向上或向下調整一個數值小數位數。
預設值為 0.0。
Logistic
羅吉斯分佈類似於常態分佈,但它沒有分配的左側限制。 羅吉斯分佈使用於羅吉斯迴歸和類神經網路模型中,可供對生命科學資料進行建模。
若要計算,請選取 [羅吉斯],然後設定下列選項:
調整
輸入要用於調整分佈的值。藉由將調整值套用至分佈,您可以將其收縮或拉伸。
預設值為 1.0。 值必須是正數。
平均數
輸入數字 (double),以指出分佈的估計平均值。 預設值為 0.0。
對數常態
對數常態分佈是連續的單一分佈。
若要計算,請選取 [Lognormal],然後設定下列選項:
平均數
輸入數位 (double) ,指出分佈的估計平均值。 預設值為 0.0。標準差
輸入正數 (double),以指出分佈的估計標準差。 預設值為 1.0。
NegativeBinomial
負二項式分佈是具有兩個參數 (r、p) 的自然數分佈。 在整數的特殊案例 r 中,當前端的 機率為 p 時,您可以將分佈解譯為第 r 個前端之前的尾數。
若要計算,請選取 [NegativeBinomial],然後設定下列選項:
成功的機率
輸入介於 0.0 與 1.0 之間的數字 (float),以指出成功的機率。 預設值為 0.5。成功的次數
輸入整數,以指定成功的值。 預設值為 24。
正常
常態分佈也稱為 Gaussian 分佈。
若要計算,請選取 [一般],然後設定下列選項:
平均數
輸入數位 (double) ,指出分佈的估計平均值。 預設值為 0.0。標準差
輸入正數 (double),以指出分佈的估計標準差。 預設值為 1.0。
帕累托
帕累托分佈是一種冪次定律機率分佈,與社會、科學、地球物理、保險和許多其他類型的可觀察現象吻合。
若要計算,請選取 [Pareto],然後設定下列選項:
圖形
輸入值 (選擇性),以變更分佈的圖形。圖形參數是未定義其位置或範圍的任何機率分佈參數。 因此,當您輸入圖形的值時,參數會變更分佈的圖形,而不是移動、拉伸或收縮圖形。
此值必須是數字 (
double)。 預設值為 1.0。調整
輸入值 (選擇性) 來變更分佈的規模。 藉由將調整值套用至分佈,您可以將其收縮或拉伸。此值必須是數字 (
double)。 預設值為 1.0。
波氏
在這個實作中,Knuth 的方法用來產生波氏分佈隨機變數。 如需 Poisson 分佈的詳細資訊,請參閱 Poisson 回歸。
若要計算,請選取 [Poisson],然後設定下列選項:
- 平均數
輸入數位 (double) ,指出分佈的估計平均值。 預設值為 0.0。
瑞利
瑞利分佈是連續的機率分佈。 如果二維風速向量的構成要素是互不相關的,且以相等的變異數呈現常態分佈,則風速會呈現瑞利分佈。這是瑞利分佈的典型發生方式。
若要計算,請選取 [Ray],然後設定下列選項:
- 下限
輸入數字 (double),以代表分佈下限。 預設值為 0.0。
StandardNormal
此選項提供標準常態分配,沒有其他參數。
若要計算,請選取 [StandardNormal],然後選取資料行。
TStudent
此選項會實作單變數 Student 的 t 分佈。
若要計算,請選取 [TStudent],然後設定下列選項:
- 自由度的數目
輸入數字 (double),以指定自由度。 預設值為 1.0。
TStudentRightTailed
使用一個右尾實作單變量 Student t 分佈。
若要計算,請選取 [TStudentRightTailed],然後設定下列選項:
- 自由度的數目
輸入數字 (double),以指定自由度。 預設值為 1.0。
TStudentTwoTailed
實作雙尾 Student T 分佈。
若要計算,請選取 [TStudentTwoTailed],然後設定下列選項:
- 自由度的數目
輸入數字 (double),以指定自由度。 預設值為 1.0。
Uniform
統一分佈也稱為矩形分佈。
若要計算,請選取 [統一],然後設定下列選項:
下限
輸入數字 (double),以代表分佈下限。 預設值為 0.0。上限
輸入數字 (double),以代表分佈上限。 預設值為 1.0。
韋伯
韋伯分佈廣泛使用於可靠性工程。 您可以使用其 Shape 參數來建立許多其他分佈的模型。
若要計算,請選取 [Weibull],然後設定下列選項:
圖形
輸入值 (選擇性),以變更分佈的圖形。圖形參數是未定義其位置或範圍的任何機率分佈參數。 因此,當您輸入圖形的值時,參數會變更分佈的圖形,而不是移動、拉伸或收縮圖形。
此值必須是數字 (
double)。 預設值為 1.0。調整
輸入值 (選擇性) 來變更分佈的規模。 藉由將調整值套用至分佈,您可以將其收縮或拉伸。此值必須是數字 (
double)。 預設值為 1.0。
技術說明
本節包含實作詳細資料、提示和常見問題集的解答。
實作詳細資料
這個模組支援開放原始碼 MATH.NET 數值程式庫中提供的所有分佈。 如需詳細資訊,請參閱 Math.Net.Numerics.Distribution 程式庫的檔。
右尾和雙尾散發會顯示為不同的散發,而不是基底散發的參數化版本。 目前的作法是保留與 Excel 的相容性。
定義
此課程模組支援計算指定分佈的任何值:
cdf或 累加分配函數
傳回復合事件的機率,當隨機變數採用小於某些特定值 x 的值時,定義為 ocurrence 的總和。
換句話說,它會回答「樣本小於或等於此值的常見程度?」
此函式可以搭配連續和離散數值變數使用。
InverseCdf或 反向累加分配函數
傳回與特定累計機率值相關聯的值, (cdf) 。
換句話說,它會回答問題:「cdf 函式傳回累加機率 y 的 x 值為何?」
pdf或 機率密度函數
描述隨機變數為特定值的相對可能性。
換句話說,它會回答「範例在確切此值上的常見程度?」
預期的輸入
| 名稱 | 類型 | 描述 |
|---|---|---|
| 資料集 | 資料表 | 輸入資料集 |
模組參數
| 名稱 | 範圍 | 類型 | 預設 | 描述 |
|---|---|---|---|---|
| 散發 | 任意 | ProbabilityDistribution | StandardNormal | 選取要產生的機率分佈類型。 |
| 方法 | 任意 | ProbabilityDistributionMethod | Cdf | 選取在計算所選取的機率分佈時要使用的方法。 選項是累積分佈函數 (cdf)、反向累積分佈函數 (InverseCdf) 及機率密度函數或質量函數 (pdf)。 |
| 負二項式分佈方法 | 任意 | ProbabilityDistributionMethodForNegativeBinomial | Cdf | 如果您選取負二項式分佈,請指定用於評估分佈的方法。 |
| 成功的機率 | [0.0;1.0] | Float | 0.5 | 輸入要用作成功機率的值。 |
| 圖形 | 任意 | Float | 1.0 | 輸入值,以修改分佈的圖形。 |
| 調整 | >=0.0 | Float | 1.0 | 輸入值,以變更分佈的範圍,擴充或收縮其大小。 |
| 試驗次數 | >=1 | 整數 | 3 | 指定試驗的次數。 |
| 下限 | 任意 | Float | 0.0 | 輸入要用作分佈下限的數字 |
| 上限 | 任意 | Float | 1.0 | 輸入要用作分佈上限的數字 |
| Location | 任意 | Float | 0.0 | 輸入分佈中零項目的位置。 |
| 自由度的數目 | 任意 | Float | 1.0 | 指定自由度的數目。 |
| 分子自由度 | 任意 | Float | 3.0 | 指定分子中自由度的數目。 |
| 分母自由度 | 任意 | Float | 6.0 | 指定分母中自由度的數目。 |
| Lambda | >=0.0 | Float | 1.0 | 指定 Lambda 參數的值。 |
| 範例數 | 任意 | 整數 | 9 | 指定樣本的數目。 |
| 成功的次數 | 任意 | 整數 | 24 | 輸入要用作成功次數的值。 |
| 母體大小 | 任意 | 整數 | 52 | 指定母體大小。 |
| 平均數 | 任意 | Float | 0.0 | 輸入估計的平均值。 |
| 標準差 | >=0.0 | Float | 1.0 | 輸入估計的標準差。 |
| 資料行集 | 任意 | ColumnSelection | 選擇要計算機率分佈的資料行。 | |
| 結果模式 | 任意 | OutputTo | ResultOnly | 指定結果在輸出資料集中如何儲存。 選項包括附加新資料行、取代現有資料行或僅輸出結果。 |
輸出
| 名稱 | 類型 | 描述 |
|---|---|---|
| 結果資料集 | 資料表 | 輸出資料集 |
例外狀況
如需錯誤訊息的完整清單,請參閱 模組錯誤碼。
| 例外狀況 | 描述 |
|---|---|
| 錯誤 0017 | 如果一或多個指定的資料行具有目前的模組不支援的型別,就會發生例外狀況。 |
如需 Studio (傳統) 模組特有的錯誤清單,請參閱錯誤碼機器學習。
如需 API 例外狀況的清單,請參閱機器學習 REST API 錯誤碼。