K-Means 叢集
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
設定和初始化 K-means 叢集模型
模組概觀
本文說明如何在 Machine Learning Studio 中使用 K-Means 叢集 模組, (傳統) 來建立未定型的 K-means 叢集模型。
K-means 是最簡單且最已知的 非監督式 學習演算法之一,可用於各種機器學習工作,例如 偵測異常數據、文字檔的叢集,以及使用其他分類或回歸方法分析數據集。 若要建立叢集模型,請將此課程模組新增至實驗、連接數據集,以及設定參數,例如您預期的叢集數目、建立叢集時要使用的距離計量等等。
設定模組超參數之後,請將未定型的模型連線到 定型叢集模型 或 掃掠叢集 模組,以在您提供的輸入數據上定型模型。 因為 K-means 演算法是非監督式的學習方法,所以標籤資料行可選擇性填寫。
- 如果您的資料包含標籤,您可以使用標籤值來引導選取叢集,並將模型最佳化。
- 如果您的資料沒有標籤,則演算法會僅根據資料來建立代表可能類別的叢集。
提示
如果您的定型數據具有標籤,請考慮使用Machine Learning 中提供的其中一種受監督 分類 方法。 例如,使用其中一種多類別判定樹演算法時,您可能會比較叢集的結果與結果。
瞭解 k-means 叢集
一般而言,群集使用反覆技巧,將資料集中的案例分組為含有類似特性的群集。 這些群組對於探索資料、識別資料的異常以及最後產生預測很有幫助。 群集模型也可協助您識別資料集內,可能無法透過瀏覽或一般觀察推論出的關係。 基於這些理由,群集通常用於在機器學習工作的早期階段,以探索資料並發現非預期的相關性。
當您使用 k-means 方法設定群集模型時,您必須指定目標數位 k ,指出您在模型中想要的 心 數。 心形是代表每個叢集的點。 K-means 演算法會將叢集內的平方總和降至最低,藉此將每個內送資料點指派給其中一個叢集。
處理定型數據時,K-means 演算法會從一組隨機選擇的心形開始,以作為每個叢集的起點,並套用 Lloyd 的演算法來反覆地精簡中心的位置。 在符合下列一或多個條件時,K-means 演算法就會停止組建及調整叢集:
心形穩定,這表示個別點的叢集指派不再變更,而且演算法已聚合在解決方案上。
演算法會完成執行指定的反覆運算次數。
完成定型階段之後,您可以使用 [將數據指派給叢集] 模組,將新案例指派給 k-means 演算法找到的其中一個叢集。 叢集指派是藉由計算新案例與每個叢集心之間的距離來執行。 每個新案例都會指派給最接近其距心的叢集。
如何設定 K-Means 叢集
將 K-Means 叢集 模組新增至實驗。
設定 [建立定型模式] 選項來指定要如何定型模型。
單一參數:如果您知道要在群集模型中使用的確切參數,便可以提供一組特定值做為引數。
參數範圍:如果您不確定最佳參數,您可以藉由指定多個值並使用 掃掠叢集 模組來尋找最佳設定,以尋找最佳參數。
定型器會逐一查看您提供之設定的多個組合,並判斷產生最佳群集結果的值組合。
針對 [中心數目],輸入您想要演算法開頭的叢集數目。
模型不保證會產生這個數目的叢集。 algorithn 從這個數據點數目開始,並逐一查看以尋找最佳設定,如 技術注意事項 一節中所述。
如果您要執行參數掃掠,屬性的名稱會變更為 Range for Number of Centroids。 您可以使用 Range Builder 來指定範圍,也可以輸入一系列數位,代表初始化每個模型時要建立的不同叢集數目。
掃掠的屬性初始化或初始化是用來指定用來定義初始叢集組態的演算法。
第一個 N:從數據集選擇一些初始數據點數目,並做為初始方法使用。
也稱為 Forgy 方法。
隨機:演算法會隨機將資料點放在群集中,然後再計算初始平均數做為群集隨機指派點的距心。
也稱為 隨機數據分割 方法。
K-Means++:這是初始化群集的預設方法。
K-means ++ 演算法是在 2007 年由 David Position 和 Sergei Vassilvitskii 提出,以避免標準 k-means 演演算法的叢集不佳。 K-means ++ 使用不同的方法來選擇初始叢集中心,藉此改善標準 K-means。
K-Means++Fast: K-means ++ 演演算法的變體,已針對更快速的叢集進行優化。
平均:距心位於 n 個數據點的 d 維空間中彼此相等。
使用標籤數據行:標籤數據列中的值是用來引導選取心心。
針對 [亂數散播],可選擇性輸入值以做為叢集初始化的種子。 此值對叢集選取可能會有重大影響。
如果您使用參數掃掠,您可以指定建立多個初始種子,以尋找最佳的初始種子值。 針對 要掃掠的種子數目,輸入要做為起點的隨機種子值總數。
針對 [計量],選擇要用來測量群集向量之間的距離,或是新的資料點和隨機選擇距心之間距離所使用的函數。 Machine Learning 支援下列叢集距離計量:
歐幾里德:歐幾里得距離通常做為 K-means 群集的群集散佈圖量數。 此為慣用度量,因為它可以將點與距心之間的平均距離縮到最短。
餘弦:余弦函數用來測量叢集相似度。 當您不關心向量的長度時,餘弦相似度很有用,只有其角度。
針對 反覆專案,輸入演算法應該逐一查看定型數據的次數,再完成中心選取。
您可以調整此參數,以平衡精確度與定型時間。
針對 [指派標籤模式],選擇選項,指定應該如何處理數據集中的標籤資料行。
因為 K-means 叢集是非監督式機器學習方法,因此標籤是選擇性項目。 不過,如果您的數據集已經有標籤數據行,您可以使用這些值來引導選取叢集,或者您可以指定忽略這些值。
略過標籤資料行:標籤資料行中的值將會忽略,且不會用於組建模型。
填入遺漏值:標籤資料行的值會做為特徵,協助組建叢集。 如果有任何資料列遺漏標籤,則會使用其他特徵來插補此值。
以最接近中心覆寫:標籤資料行值會以預測的標籤值取代,並使用最接近目前距心的點標籤。
定型模型。
結果
完成設定和定型模型之後,您有可用來產生分數的模型。 不過,有多種方法可以訓練模型,以及查看和使用結果:
在您的工作區中擷取模型的快照
如果您使用 定型叢集模型 模組
- 以滑鼠右鍵按兩下 [定型叢集模型] 模組。
- 選取 [定型模型 ],然後按兩下 [ 另存新定型模型]。
如果您使用 掃掠叢集 模組來定型模型
- 以滑鼠右鍵按兩下 掃掠叢集 模組。
- 選取 [最佳定型模型 ],然後按兩下 [ 另存新定型模型]。
儲存的模型會在您儲存模型時代表定型數據。 如果您稍後更新實驗中使用的定型數據,則不會更新儲存的模型。
查看模型中叢集的視覺化表示法
如果您使用 定型叢集模型 模組
- 以滑鼠右鍵按兩下模組,然後選取 [結果數據集]。
- 選取 [視覺化]。
如果您使用 掃掠叢集 模組
新增 指派數據至叢集 模組的實例,並使用 最佳定型模型產生分數。
以滑鼠右鍵按兩下 [ 將數據指派給叢集] 模組,選取 [結果數據集],然後選取 [ 可視化]。
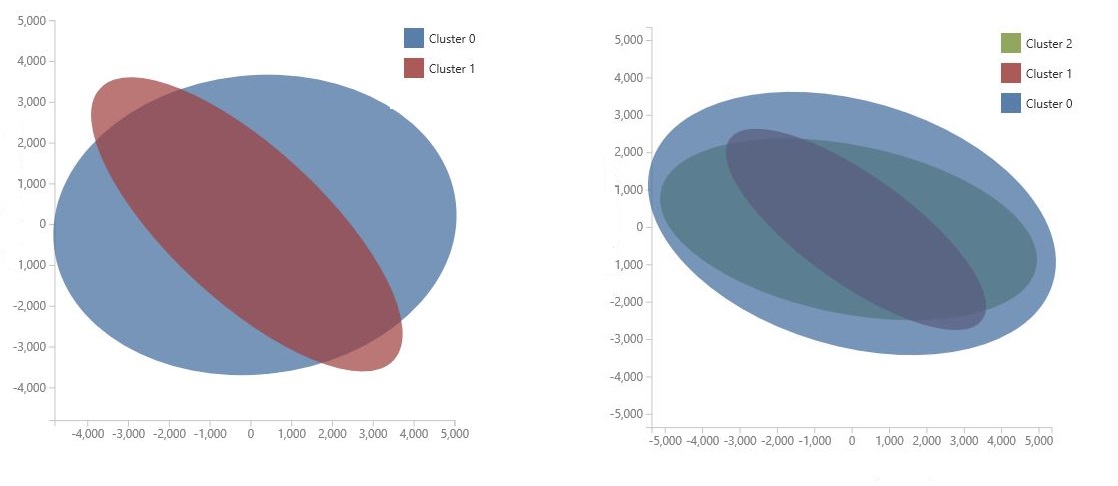
圖表是使用 主體元件分析來產生,這是壓縮模型特徵空間的數據科學技術。 此圖表顯示一組壓縮成兩個維度的功能,最能描述叢集之間的差異。 透過可視化方式檢閱每個叢集的功能空間一般大小,以及叢集重疊的程度,您可以瞭解模型可能執行的程度。
例如,下列 PCA 圖表代表使用相同數據定型的兩個模型的結果:第一個已設定為輸出兩個叢集,而第二個則設定為輸出三個叢集。 從這些圖表中,您可以看到增加叢集數目不一定會改善類別的分隔。
提示
使用 掃掠叢集 模組來選擇最佳超參數集合,包括隨機種子和起始距心的數目。
查看數據點及其所屬的叢集清單
視您定型模型的方式而定,有兩個選項可檢視具有結果的數據集:
如果您使用 掃掠叢集 模組來定型模型
- 使用 [掃掠叢集] 模組中的複選框來指定是否要與結果一起查看輸入數據,或只查看結果。
- 定型完成時,以滑鼠右鍵按兩下模組,然後選取 [ 結果數據集 ] (輸出數位 2)
- 按兩下 [可視化]。
如果您使用 定型叢集模型 模組
如果您包含輸入資料列,輸出會先包含輸入資料列,並針對每個輸入資料列包含下列資料列:
工作分派:指派是介於 1 到 n 之間的值,其中 n 是模型中的叢集總數。 每個數據列只能指派給一個叢集。
DistancesToClusterCenter no.n:此值會測量從目前數據點到叢集距心的距離。 定型模型中每個叢集輸出中的個別數據行。
叢集距離的值取決於您在選項中選取的距離計量: 測量叢集結果的計量。 即使您在叢集模型上執行參數掃掠,在掃掠期間只能套用一個計量。 如果您變更計量,可能會取得不同的距離值。
將叢集內部距離可視化
在上一節的結果數據集中,按兩下每個叢集的距離數據行。 Studio (傳統) 會顯示直方圖,以可視化方式呈現叢集內點的距離分佈。
例如,下列直方圖會使用四個不同的計量,顯示叢集距離與相同實驗的分佈。 參數掃掠的所有其他設定都相同。 變更計量會導致一個模型中的叢集數目不同。

一般而言,您應該選擇可將不同類別中數據點之間的距離最大化的計量,並將類別內的距離降到最低。 您可以使用 [ 統計數據 ] 窗格中的預先計算方式和其他值,引導您進行此決策。
產生最佳群集模型的秘訣
已知叢集期間所使用的 植入 程式可能會大幅影響模型。 植入表示點的初始放置到強心形中。
例如,如果數據集包含許多極端值,且選擇極端值來植入叢集,則其他數據點將無法與該叢集搭配使用,而且叢集可以是單一值:也就是說,只有一個點的叢集。
有各種方式可避免此問題:
使用參數掃掠來變更距心數目,並嘗試多個種子值。
建立多個模型、改變計量或反覆運算多次。
使用 PCA 之類的方法來尋找對叢集造成負面影響的變數。 如需這項技術的示範,請參閱 尋找類似的公司 範例。
一般而言,使用叢集模型時,任何指定的組態都可能導致本機優化的叢集集。 換句話說,模型所傳回的叢集集只適合目前的數據點,而且無法一般化給其他數據。 如果您使用不同的初始組態,K-means 方法可能會找到不同甚至是更好的組態。
重要
建議您一律試驗參數、建立多個模型,以及比較產生的模型。
範例
如需如何在Machine Learning 中使用 K-Means 叢集的範例,請參閱 Azure AI 資源庫中的這些實驗:
技術說明
K-means 演算法透過讓特定數目的群集 (K) 尋找一組含 N 個資料點的 D 維度資料點,以建立群集,如下所示:
此模組會使用定義找到 K 叢集的最終距心,初始化 K-by-D 陣列。
根據預設,模組會指派第一 個 K 數據點給 K 叢集。
此方法從一組初始的 K 個距心開始,再利用羅依演算法反覆地調整距心的位置。
距心穩定或完成指定的反覆運算次數時,演算法即會結束。
相似度度量 (預設為歐幾里得距離) 可用來將每個資料點指派給具有最接近之距心的群集。
警告
模組參數
| 名稱 | 範圍 | 類型 | 預設 | 描述 |
|---|---|---|---|---|
| 距心數目 | >=2 | 整數 | 2 | 距心數目 |
| 計量 | 清單 (子集) | 計量 | 歐幾里德 | 選取的度量 |
| 初始化 | 清單 | 距心初始化方法 | K-Means++ | 初始化演算法 |
| 反覆運算次數 | >=1 | 整數 | 100 | 反覆運算次數 |
輸出
| 名稱 | 類型 | Description |
|---|---|---|
| 未定型的模型 | ICluster 介面 | 未定型的 K-Means 群集模型 |
例外狀況
如需所有例外狀況的清單,請參閱 Machine Learning 模組錯誤碼。
| 例外狀況 | 描述 |
|---|---|
| 錯誤 0003 | 如果一或多個輸入為 Null 或空白,就會發生例外狀況。 |
另請參閱
Clustering (叢集)
將資料指派給叢集
將群集模型定型
掃掠叢集