適用於 PostgreSQL 的 Azure 資料庫 中的高可用性 – 單一伺服器
適用於: 適用於 PostgreSQL 的 Azure 資料庫 - 單一伺服器
適用於 PostgreSQL 的 Azure 資料庫 - 單一伺服器
重要
適用於 PostgreSQL 的 Azure 資料庫 - 單一伺服器位於淘汰路徑上。 強烈建議您升級至 適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器。 如需移轉至 適用於 PostgreSQL 的 Azure 資料庫 - 彈性伺服器的詳細資訊,請參閱單一伺服器 適用於 PostgreSQL 的 Azure 資料庫 發生什麼事?。
適用於 PostgreSQL 的 Azure 資料庫 – 單一伺服器服務為運行時間提供財務支援的服務等級協定 (SLA) 保證高可用性。 適用於 PostgreSQL 的 Azure 資料庫 在計劃性事件期間提供高可用性,例如使用者起始的調整計算作業,以及發生基礎硬體、軟體或網路失敗等非計劃性事件時。 適用於 PostgreSQL 的 Azure 資料庫 可以從大部分的嚴重情況下快速復原,確保使用此服務時幾乎不會有任何應用程式停機。
適用於 PostgreSQL 的 Azure 資料庫 適用於執行需要高運行時間的任務關鍵資料庫。 服務建置在 Azure 架構上,具有固有的高可用性、備援和復原功能,可降低計劃性和非計劃性中斷的資料庫停機時間,而不需要您設定任何其他元件。
適用於 PostgreSQL 的 Azure 資料庫 中的元件 – 單一伺服器
| 元件 | 說明 |
|---|---|
| Postgre SQL 資料庫 Server | 適用於 PostgreSQL 的 Azure 資料庫 提供資料庫伺服器的安全性、隔離、資源保護,以及快速重新啟動功能。 這些功能可協助調整和資料庫伺服器復原作業等作業,並在中斷後於數秒內發生。 資料庫伺服器中的數據修改通常發生在資料庫交易的內容中。 所有資料庫變更都會以 Azure 儲存體 上的預先寫入記錄 (WAL) 形式同步記錄-附加至資料庫伺服器。 在資料庫 檢查點 程式期間,資料庫伺服器記憶體中的數據頁也會排清到記憶體。 |
| 遠端 儲存體 | 所有 PostgreSQL 實體數據檔和 WAL 檔案都會儲存在 Azure 儲存體,其架構是將三份數據儲存在區域內,以確保數據備援、可用性和可靠性。 儲存層也與資料庫伺服器無關。 它可以從失敗的資料庫伺服器中斷連結,並在幾秒鐘內重新附加至新的資料庫伺服器。 此外,Azure 儲存體持續監視任何記憶體錯誤。 如果偵測到區塊損毀,則會藉由具現化新的記憶體複本來自動修正它。 |
| 閘道 | 網關可作為資料庫 Proxy,會將所有用戶端連線路由至資料庫伺服器。 |
計劃性停機風險降低
適用於 PostgreSQL 的 Azure 資料庫 已建構為在計劃性停機作業期間提供高可用性。
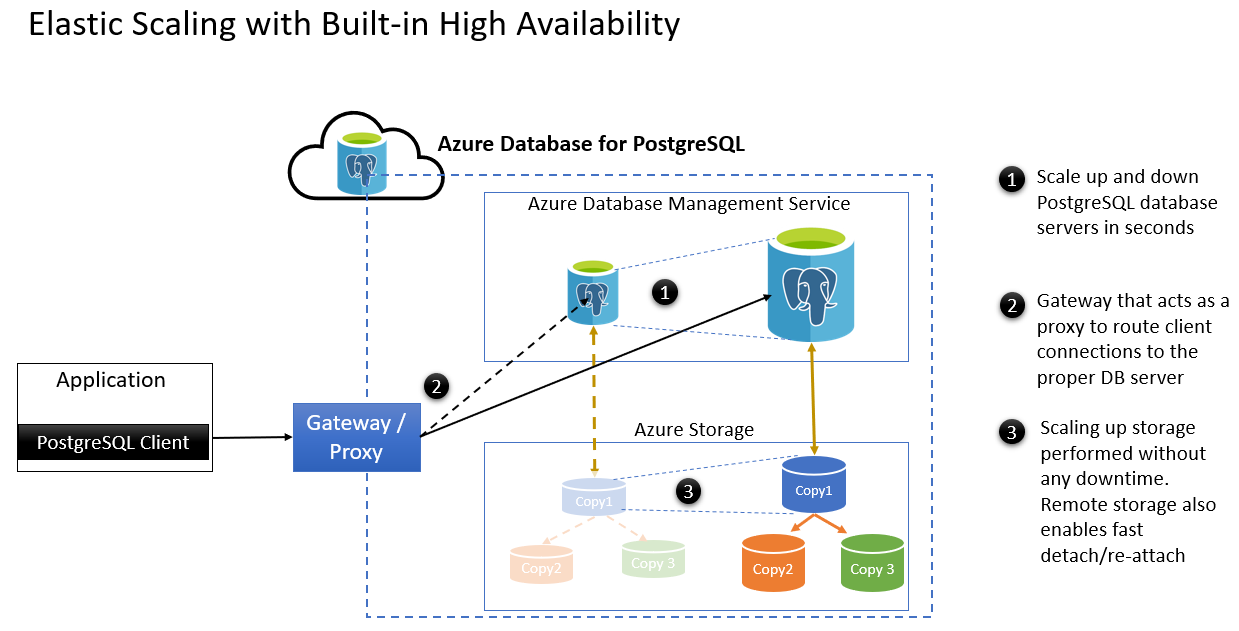
- 在幾秒內相應增加和減少PostgreSQL資料庫伺服器。
- 做為 Proxy 的閘道可路由客戶端連線到適當的資料庫伺服器。
- 您可以執行相應增加記憶體,而不需要停機。 遠端記憶體可在故障轉移之後快速中斷連結/重新連結。 以下是一些計劃性維護案例:
| 案例 | 說明 |
|---|---|
| 計算相應增加/減少 | 當使用者執行計算相應增加/減少作業時,會使用調整的計算組態來布建新的資料庫伺服器。 在舊資料庫伺服器中,允許使用中的檢查點完成、用戶端連線已清空、取消任何未認可的交易,然後關閉。 然後,記憶體會與舊的資料庫伺服器中斷連結,並附加至新的資料庫伺服器。 當用戶端應用程式重試連線或嘗試建立新的連線時,閘道會將連線要求導向至新的資料庫伺服器。 |
| 相應增加記憶體 | 相應增加記憶體是在線作業,不會中斷資料庫伺服器。 |
| 新的軟體部署 (Azure) | 新功能推出或 Bug 修正會在服務的計劃性維護期間自動發生。 如需詳細資訊,請參閱 檔,並檢查您的 入口網站。 |
| 次要版本升級 | 適用於 PostgreSQL 的 Azure 資料庫 會自動將資料庫伺服器修補至 Azure 所決定的次要版本。 這是服務計劃性維護的一部分。 這會在秒數方面產生短暫的停機時間,而且資料庫伺服器會以新的次要版本自動重新啟動。 如需詳細資訊,請參閱 檔,並檢查您的 入口網站。 |
非計劃性停機風險降低措施
非計劃性停機可能會因為未預期的失敗而發生,包括基礎硬體錯誤、網路問題,以及軟體錯誤。 如果資料庫伺服器意外關閉,系統便會在幾秒鐘內自動佈建新的資料庫伺服器。 遠端儲存體會自動連結至新的資料庫伺服器。 PostgreSQL 引擎會使用 WAL 和資料庫檔案來執行復原作業,並開啟資料庫伺服器讓用戶端得以連線。 未認可的交易會遺失,而且應用程式必須重試這些交易。 雖然無法避免非計劃性停機,但 適用於 PostgreSQL 的 Azure 資料庫 不需要人為介入,自動在資料庫伺服器和儲存層執行復原作業來減輕停機時間。

- 具有快速調整功能的 Azure PostgreSQL 伺服器。
- 作為 Proxy 的閘道,用來將用戶端連線路由至適當的資料庫伺服器。
- 具有三個複本的 Azure 記憶體,可提供可靠性、可用性和備援。
- 遠端記憶體也可在伺服器故障轉移之後快速中斷連結/重新連結。
非計劃性停機:失敗案例和服務復原
以下是一些失敗案例,以及 適用於 PostgreSQL 的 Azure 資料庫 如何自動復原:
| 案例 | 自動復原 |
|---|---|
| 資料庫伺服器失敗 | 如果資料庫伺服器因為某些基礎硬體錯誤而關閉,則會卸除作用中聯機,且任何執行中的交易都中止。 系統會自動部署新的資料庫伺服器,並將遠端資料記憶體附加至新的資料庫伺服器。 資料庫復原完成後,用戶端可以透過網關聯機到新的資料庫伺服器。 復原時間 (RTO) 取決於各種因素,包括錯誤時的活動,例如大型交易,以及資料庫伺服器啟動程式期間要執行的復原量。 使用 PostgreSQL 資料庫的應用程式必須以偵測和重試已卸除的連線和失敗交易的方式建置。 當應用程式重試時,閘道會以透明方式將連線重新導向至新建立的資料庫伺服器。 |
| 儲存體 失敗 | 應用程式不會看到任何記憶體相關問題的影響,例如磁碟失敗或實體區塊損毀。 當數據儲存在三個複本中時,數據複本會由倖存的記憶體提供。 封鎖損毀會自動更正。 如果數據復本遺失,則會自動建立新的數據複本。 |
| 計算失敗 | 計算失敗是罕見的事件。 當計算失敗時,會布建新的計算容器,且具有數據檔的記憶體會對應至該容器,然後 PostgreSQL 資料庫引擎會在新的容器上線,而網關服務可確保透明故障轉移,而不需要變更應用程式。 另請注意,當 AZ 計算失敗時,計算層已內建可用性區域復原功能,且新的計算會在不同的可用性區域中啟動。 |
以下是需要使用者動作才能復原的一些失敗案例:
| 案例 | 復原方案 |
|---|---|
| 區域失敗 | 區域失敗是罕見的事件。 不過,如果您需要保護區域失敗,您可以在其他區域中設定一或多個讀取複本以進行災害復原(DR)。 (如需詳細資訊,請參閱 這篇文章 ,以建立和管理讀取複本。 在發生區域層級失敗時,您可以手動將另一個區域上設定的讀取複本升階為生產資料庫伺服器。 |
| 可用性區域失敗 | 可用性區域的失敗也是罕見的事件。 不過,如果您需要保護可用性區域失敗,您可以設定一或多個讀取複本,或使用提供 區域備援高可用性的彈性伺服器 供應專案。 |
| 邏輯/用戶錯誤 | 從使用者錯誤中復原,例如意外卸除的數據表或不正確的更新數據,牽涉到執行 時間點復原 (PITR),方法是還原和復原數據,直到錯誤發生前的時間為止。 如果您想要只還原資料庫或特定數據表的子集,而不是資料庫伺服器中的所有資料庫,您可以在新的實例中還原資料庫伺服器、透過 pg_dump導出數據表,然後使用 pg_restore 將這些數據表還原到您的資料庫。 |
摘要
適用於 PostgreSQL 的 Azure 資料庫 提供資料庫伺服器的快速重新啟動功能、備援記憶體,以及從閘道進行有效率的路由。 如需其他數據保護,您可以將備份設定為異地複寫,並在其他區域中部署一或多個讀取複本。 使用固有的高可用性功能,適用於 PostgreSQL 的 Azure 資料庫 保護您的資料庫免於最常見的中斷,並提供領先業界且財務支援的 99.99% 運行時間 SLA。 所有這些可用性和可靠性功能可讓 Azure 成為執行任務關鍵性應用程式的理想平臺。
下一步
- 瞭解 Azure 區域
- 瞭解如何 處理暫時性連線錯誤
- 瞭解如何 使用讀取複本來復寫您的數據