從 AI 擴充中的影像擷取文字和資訊
透過 AI 擴充,Azure AI 搜尋提供數個選項,讓您從影像建立和擷取可搜尋的文字,包括:
透過 OCR,您可以從包含英數位元文字的相片或圖片中擷取文字,例如停止符號中的 “STOP” 一詞。 透過影像分析,您可以產生影像的文字表示法,例如 「dandelion」 作為丹公英相片或色彩 「yellow」。 您也可以擷取影像的相關元數據,例如其大小。
本文涵蓋使用影像的基本概念,也說明數個常見案例,例如處理原始影像的內嵌影像、自定義技能,以及重疊視覺效果。
若要在技能集中使用影像內容,您需要:
- 包含影像的來源檔案
- 針對影像動作設定的搜尋索引器
- 具有內建或自定義技能的技能集,可叫用 OCR 或影像分析
- 包含要接收分析文字輸出之欄位的搜尋索引,以及建立關聯之索引器中的輸出欄位對應。
您可以選擇性地定義投影,以接受影像分析輸出到 數據採礦案例的知識存放區 。
設定原始程序檔
影像處理是索引器驅動,這表示原始輸入必須位於支持的數據源中。
- 影像分析支援 JPEG、PNG、GIF 和 BMP
- OCR 支援 JPEG、PNG、BMP 和 TIF
影像是獨立的二進位檔或內嵌在檔案 (PDF、RTF 和 Microsoft 應用程式檔案) 中。 最多可以從指定的檔擷取 1000 個影像。 如果檔中有超過 1000 個影像,則會擷取前 1000 個影像,然後產生警告。
Azure Blob 儲存體 是 Azure AI 搜尋服務中影像處理最常使用的記憶體。 從 Blob 容器擷取映像有三個主要工作:
啟用容器中內容的存取權。 如果您使用包含金鑰的完整存取 連接字串,金鑰會提供您內容的許可權。 或者,您可以使用 Microsoft Entra ID 進行驗證,或 將 連線為受信任的服務。
建立類型為 「azureblob」 的數據源 ,以連線到儲存檔案的 Blob 容器。
檢閱 服務層級限制 ,以確定源數據的大小上限和索引器和擴充數量限制。
設定影像處理的索引器
設定來源檔案之後,請在索引器組態中設定 imageAction 參數,以啟用映射正規化。 影像正規化有助於讓影像更統一,以進行下游處理。 映射正規化包含下列作業:
- 大型影像的大小會調整為最大高度和寬度,使其統一。
- 對於方向具有元數據的影像,影像旋轉會調整為垂直載入。
元數據調整會擷取在每個映像所建立的複雜類型中。 您無法退出退出映像正規化需求。 逐一查看影像的技能,例如 OCR 和影像分析,預期會有正規化的影像。
建立或更新索引器 以設定組態屬性:
{ "parameters": { "configuration": { "dataToExtract": "contentAndMetadata", "parsingMode": "default", "imageAction": "generateNormalizedImages" } } }設定
dataToExtract為contentAndMetadata(必要)。確認 已
parsingMode設定為預設值 (必要)。此參數會決定索引中建立的搜尋檔粒度。 默認模式會設定一對一對應,讓一個 Blob 產生一個搜尋檔。 如果檔很大,或技能需要較小的文字區塊,您可以新增文字分割技能,將檔細分為分頁以供處理之用。 但在搜尋案例中,如果擴充包含影像處理,則需要每個檔一個 Blob。
設定
imageAction為在擴充樹狀結構中啟用 normalized_images 節點 (必要):generateNormalizedImages表示在檔破解時產生標準化影像數位。generateNormalizedImagePerPage(僅適用於 PDF)以產生標準化影像陣列,其中 PDF 中的每個頁面都會轉譯成一個輸出影像。 對於非 PDF 檔案,此參數的行為與您已設定 「generateNormalizedImages」 類似。 不過,請注意,設定 「generateNormalizedImagePerPage」 可讓索引編製作業的設計效能降低(尤其是大型檔),因為必須產生數個影像。
選擇性地調整產生的標準化影像的寬度或高度:
normalizedImageMaxWidth(以像素為單位)。 預設值為 2000。 最大值為 10000。normalizedImageMaxHeight(以像素為單位)。 預設值為 2000。 最大值為 10000。
標準化影像最大寬度和高度的預設值為 2000 像素,是根據 OCR 技能所支援的大小上限和影像分析技能而定。 OCR 技能支援非英文語言的最大寬度和高度為 4200,英文則為 10000。 如果您增加上限,處理可能會因為技能集定義和文件的語言而失敗。
選擇性地,如果工作負載以特定檔類型為目標, 請設定檔類型準則 。 Blob 索引器組態包括檔案包含和排除設定。 您可以篩選掉您不想要的檔案。
{ "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf, .docx", "excludedFileNameExtensions" : ".png, .jpeg" } } }
關於標準化影像
當 設定為 「none」 以外的值時 imageAction ,新的 normalized_images 欄位會包含影像陣列。 每個影像都是具有下列成員的複雜類型:
| 影像成員 | 描述 |
|---|---|
| data | 以 JPEG 格式標準化影像的 BASE64 編碼字串。 |
| width | 標準化影像的寬度,以像素為單位。 |
| 高度 | 標準化影像的高度,以像素為單位。 |
| originalWidth | 正規化之前影像的原始寬度。 |
| originalHeight | 正規化之前影像的原始高度。 |
| rotationFromOriginal | 以建立正規化影像時發生度為單位的逆時針旋轉。 介於 0 度和 360 度之間的值。 此步驟會從相機或掃描器所產生的影像讀取元數據。 通常是90度的倍數。 |
| contentOffset | 從中擷取影像的內容欄位中的字元位移。 此欄位僅適用於內嵌影像的檔案。 從 PDF 檔擷取之影像的 contentOffset 一律位於檔擷取自的頁面上文字結尾。 這表示影像會顯示在該頁面上的所有文字之後,不論該頁面上影像的原始位置為何。 |
| pageNumber | 如果從 PDF 擷取或轉譯影像,此字段會包含從 1 開始擷取或轉譯之 PDF 中的頁碼。 如果影像不是來自 PDF,則此字段為 0。 |
normalized_images的範例值:
[
{
"data": "BASE64 ENCODED STRING OF A JPEG IMAGE",
"width": 500,
"height": 300,
"originalWidth": 5000,
"originalHeight": 3000,
"rotationFromOriginal": 90,
"contentOffset": 500,
"pageNumber": 2
}
]
定義影像處理的技能集
本節藉 由提供與影像處理相關的技能輸入、輸出和模式的內容,來補充技能參考 文章。
建立或更新技能集 以新增技能。
從入口網站新增 OCR 和影像分析的範本,或從 技能參考 檔複製定義。 將它們插入技能集定義的技能陣列。
如有必要, 請在技能集的 Azure AI 服務屬性中包含多服務密鑰 。 Azure AI 搜尋會針對超過免費限制的交易呼叫可計費的 Azure AI 服務資源,以進行 OCR 和影像分析,這些交易超過每日 20 個索引器。 Azure AI 服務必須與搜尋服務位於相同的區域中。
如果原始影像內嵌在 PDF 或 PPTX 或 DOCX 等應用程式檔中,如果您想要一起輸出影像和文字輸出,則必須新增文字合併技能。 本文會進一步討論使用內嵌影像。
建立技能集的基本架構並設定 Azure AI 服務之後,您可以專注於每個個別的影像技能、定義輸入和來源內容,以及將輸出對應至索引或知識存放區中的字段。
注意
請參閱 REST 教學課程:使用 REST 和 AI 從 Azure Blob 產生可搜尋的內容,以取得結合影像處理與下游自然語言處理的範例技能集。 它示範如何將技能影像輸出饋送至實體辨識和關鍵片語擷取。
關於影像處理的輸入
如前所述,影像會在檔破解期間擷取,然後正規化為初步步驟。 標準化影像是任何影像處理技能的輸入,而且一律以兩種方式之一在擴充的檔樹狀結構中表示:
/document/normalized_images/*適用於已處理整個的檔。/document/normalized_images/*/pages適用於以區塊 (pages) 處理的檔。
無論您使用相同的 OCR 和影像分析,輸入幾乎具有相同的建構:
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
},
{
"@odata.type": "#Microsoft.Skills.Vision.ImageAnalysisSkill",
"context": "/document/normalized_images/*",
"visualFeatures": [ "tags", "description" ],
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [ ]
}
將輸出對應至搜尋欄位
在技能集中,影像分析和 OCR 技能輸出一律為文字。 輸出文字會以內部擴充檔樹狀結構中的節點表示,而且每個節點都必須對應至搜尋索引中的字段,或對應至知識存放區中的投影,才能在應用程式中提供內容。
在技能集中,檢閱
outputs每個技能的 區段,以判斷哪些節點存在於擴充檔中:{ "@odata.type": "#Microsoft.Skills.Vision.OcrSkill", "context": "/document/normalized_images/*", "detectOrientation": true, "inputs": [ ], "outputs": [ { "name": "text", "targetName": "text" }, { "name": "layoutText", "targetName": "layoutText" } ] }建立或更新搜尋索引 ,以新增欄位以接受技能輸出。
在下列欄位集合範例中,“content” 是 Blob 內容。 “Metadata_storage_name” 包含檔案的名稱(請確定其為「可擷取」)。 “Metadata_storage_path” 是 Blob 的唯一路徑,而且是預設的文件索引鍵。 “Merged_content” 是文字合併的輸出(當影像內嵌時很有用)。
“Text” 和 “layoutText” 是 OCR 技能輸出,而且必須是字串集合,才能擷取整個檔的所有 OCR 產生的輸出。
"fields": [ { "name": "content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "filterable": true, "retrievable": true, "searchable": true, "sortable": false }, { "name": "metadata_storage_path", "type": "Edm.String", "filterable": false, "key": true, "retrievable": true, "searchable": false, "sortable": false }, { "name": "merged_content", "type": "Edm.String", "filterable": false, "retrievable": true, "searchable": true, "sortable": false }, { "name": "text", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true }, { "name": "layoutText", "type": "Collection(Edm.String)", "filterable": false, "retrievable": true, "searchable": true } ],更新索引器 ,將技能集輸出(擴充樹狀結構中的節點)對應至索引字段。
擴充的文件是內部檔。 若要將擴充檔樹中的節點外部化,請設定輸出欄位對應,指定哪些索引欄位接收節點內容。 您的應用程式會透過索引欄位存取擴充的數據。 下列範例顯示搜尋索引中對應至「文字」欄位之擴充檔中的「文字」節點(OCR 輸出)。
"outputFieldMappings": [ { "sourceFieldName": "/document/normalized_images/*/text", "targetFieldName": "text" }, { "sourceFieldName": "/document/normalized_images/*/layoutText", "targetFieldName": "layoutText" } ]執行索引器以叫用源檔擷取、影像處理和編製索引。
驗證結果
對索引執行查詢,以檢查影像處理的結果。 使用 搜尋總 管做為搜尋用戶端,或任何傳送 HTTP 要求的工具。 下列查詢會選取包含影像處理輸出的欄位。
POST /indexes/[index name]/docs/search?api-version=[api-version]
{
"search": "*",
"select": "metadata_storage_name, text, layoutText, imageCaption, imageTags"
}
OCR 會辨識圖像檔案中的文字。 這表示如果源文檔是純文本或純影像,OCR 欄位 (“text” 和 “layoutText”) 是空的。 同樣地,如果源文檔輸入嚴格為文字,則影像分析欄位 (“imageCaption” 和 “imageTags”) 是空的。 如果影像輸入是空的,索引器執行就會發出警告。 當擴充檔中未填入節點時,預期會有這類警告。 回想一下,如果您想要隔離使用內容類型,Blob 索引可讓您包含或排除檔類型。 您可以使用這些設定來減少索引器執行期間的雜訊。
檢查結果的替代查詢可能包含「內容」和「merged_content」欄位。 請注意,這些欄位包含任何 Blob 檔案的內容,即使是沒有執行影像處理的欄位也一樣。
關於技能輸出
技能輸出包括“text”(OCR)、“layoutText”(OCR)、“merged_content”、“標題”(影像分析)、“標記”(影像分析):
“text” 會儲存 OCR 產生的輸出。 此節點應該對應至 類型的
Collection(Edm.String)欄位。 每個搜尋檔都有一個「文字」字段,其中包含包含多個影像之檔的逗號分隔字串。 下圖顯示三份檔的 OCR 輸出。 第一個是包含沒有影像之檔案的檔。 第二個是包含一個單字「Microsoft」的文件(圖像檔)。 第三個是包含多個影像的檔,有些沒有文字("",)。"value": [ { "@search.score": 1, "metadata_storage_name": "facts-about-microsoft.html", "text": [] }, { "@search.score": 1, "metadata_storage_name": "guthrie.jpg", "text": [ "Microsoft" ] }, { "@search.score": 1, "metadata_storage_name": "Azure AI services and Content Intelligence.pptx", "text": [ "", "Microsoft", "", "", "", "Azure AI Search and Augmentation Combining Microsoft Azure AI services and Azure Search" ] } ]“layoutText” 會儲存頁面上文字位置的 OCR 產生的資訊,如標準化影像的周框方塊和座標所述。 此節點應該對應至 類型的
Collection(Edm.String)欄位。 每個搜尋檔都有一個 「layoutText」 字段,其中包含逗號分隔字串。“merged_content” 會儲存文字合併技能的輸出,而且應該是包含源文檔原始文字的大型類型
Edm.String欄位,內嵌的「文字」取代影像。 如果檔案是純文本的,則 OCR 和影像分析沒有任何作用,而 “merged_content” 與 “content” 相同(包含 Blob 內容的 Blob 屬性)。“imageCaption” 會將影像的描述擷取為個別標記和較長的文字描述。
“imageTags” 會將影像的相關標記儲存為關鍵詞集合,這是源文檔中所有影像的一個集合。
下列螢幕快照是包含文字和內嵌影像的 PDF 圖例。 檔裂縫偵測到三個內嵌圖像:海鷗群,地圖,鷹。 範例中的其他文字(包括標題、標題和本文文字)會擷取為文字,並排除在影像處理之外。
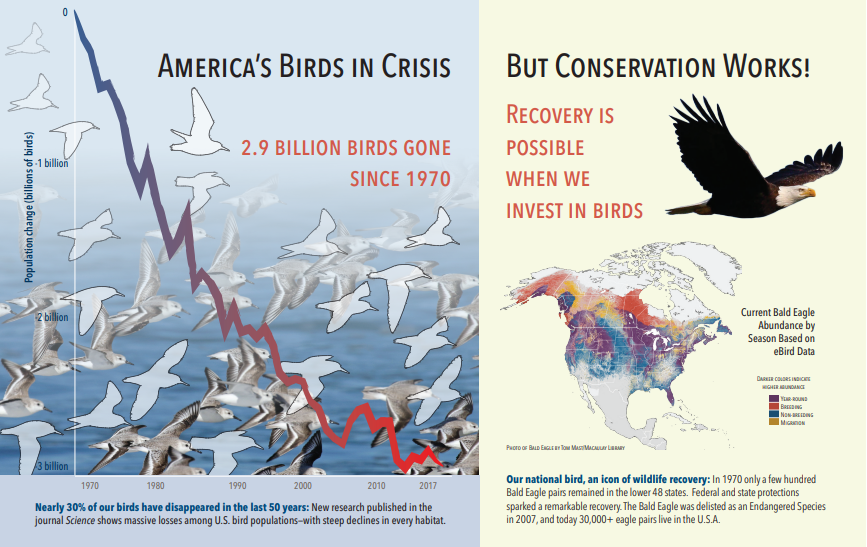
下圖說明影像分析輸出(搜尋結果)。 技能定義可讓您指定 感興趣的視覺功能 。 在此範例中,會產生標記和描述,但有更多輸出可供選擇。
“imageCaption” 輸出是描述陣列,每一個影像一個,由描述影像的單一單字和較長的詞組所表示。 請注意由「海鷗群在水中游泳」或「鳥的特寫」所組成的標記。
“imageTags” 輸出是單一標記的陣列,會依建立順序列出。 請注意,標籤會重複。 沒有匯總或群組。
"imageCaption": [
"{\"tags\":[\"bird\",\"outdoor\",\"water\",\"flock\",\"many\",\"lot\",\"bunch\",\"group\",\"several\",\"gathered\",\"pond\",\"lake\",\"different\",\"family\",\"flying\",\"standing\",\"little\",\"air\",\"beach\",\"swimming\",\"large\",\"dog\",\"landing\",\"jumping\",\"playing\"],\"captions\":[{\"text\":\"a flock of seagulls are swimming in the water\",\"confidence\":0.70419257326275686}]}",
"{\"tags\":[\"map\"],\"captions\":[{\"text\":\"map\",\"confidence\":0.99942880868911743}]}",
"{\"tags\":[\"animal\",\"bird\",\"raptor\",\"eagle\",\"sitting\",\"table\"],\"captions\":[{\"text\":\"a close up of a bird\",\"confidence\":0.89643581933539462}]}",
. . .
"imageTags": [
"bird",
"outdoor",
"water",
"flock",
"animal",
"bunch",
"group",
"several",
"drink",
"gathered",
"pond",
"different",
"family",
"same",
"map",
"text",
"animal",
"bird",
"bird of prey",
"eagle"
. . .
案例:PDF 中的內嵌影像
當您要處理的影像內嵌在其他檔案中,例如 PDF 或 DOCX 時,擴充管線只會擷取影像,然後將影像傳遞至 OCR 或影像分析進行處理。 影像擷取會在檔破解階段發生,而且一旦影像分開,除非您明確地將處理過的輸出合併回來源文字,否則它們會保持分開。
文字合併 是用來將影像處理輸出放回檔中。 雖然文字合併並非硬式需求,但經常叫用它,因此影像輸出(OCR 文字、OCR 版面配置文字、影像卷標、影像 標題)可以重新引入檔。 視技能而定,影像輸出會將內嵌二進位影像取代為就地文字對等專案。 影像分析輸出可以在影像位置合併。 OCR 輸出一律會出現在每個頁面的結尾。
下列工作流程概述影像擷取、分析、合併的程式,以及如何擴充管線,將影像處理的輸出推送至其他以文字為基礎的技能,例如實體辨識或文字翻譯。
連接到數據源之後,索引器會載入並破解源檔、擷取影像和文字,以及佇列每個內容類型進行處理。 只建立包含根節點 (
"document") 的擴充檔。佇列中的影像會 正規化 ,並傳遞至擴充的檔做為
"document/normalized_images"節點。影像擴充會執行,使用
"/document/normalized_images"做為輸入。影像輸出會傳遞至擴充的檔樹狀結構,並將每個輸出當作個別節點。 輸出會因技能而異(OCR 的文字和版面配置文字、標籤和影像分析 標題)。
選擇性但建議使用搜尋檔同時包含文字和影像原始文字, 則 Text Merge 會執行,並將這些影像的文字表示與從檔案擷取的原始文字結合。 文字區塊會合併成單一大型字串,其中文字會先插入字串中,然後再將 OCR 文字輸出或影像標記和 標題。
文字合併的輸出現在是要分析任何執行文字處理的下游技能的最終文字。 例如,如果您的技能集同時包含 OCR 和實體辨識,則實體辨識的輸入應該是
"document/merged_text"(文字合併技能輸出的 targetName)。執行所有技能之後,擴充的檔就會完成。 在最後一個步驟中,索引器會參考 輸出欄位對應 ,以將擴充內容傳送至搜尋索引中的個別欄位。
下列範例技能集會建立一個 "merged_text" 字段,其中包含含有內嵌 OCRed 文字的檔原始文字,以取代內嵌影像。 它也包含做為輸入的 "merged_text" 實體辨識技能。
要求本文語法
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"description": "Extract text (plain and structured) from image.",
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text", "source": "/document/content"
},
{
"name": "itemsToInsert", "source": "/document/normalized_images/*/text"
},
{
"name":"offsets", "source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText", "targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"context": "/document",
"categories": [ "Person"],
"defaultLanguageCode": "en",
"minimumPrecision": 0.5,
"inputs": [
{
"name": "text", "source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons", "targetName": "people"
}
]
}
]
}
既然您有merged_text欄位,您可以將它對應為索引器定義中的可搜尋欄位。 檔案的所有內容,包括影像的文字,都可以搜尋。
案例:可視化周框方塊
另一個常見案例是可視化搜尋結果配置資訊。 例如,您可能會想要反白顯示影像中找到一段文字的位置,做為搜尋結果的一部分。
由於 OCR 步驟是在標準化影像上執行,因此配置座標位於標準化影像空間中,但如果您需要顯示原始影像,請將配置中的座標點轉換為原始影像座標系統。
下列演算法說明模式:
/// <summary>
/// Converts a point in the normalized coordinate space to the original coordinate space.
/// This method assumes the rotation angles are multiples of 90 degrees.
/// </summary>
public static Point GetOriginalCoordinates(Point normalized,
int originalWidth,
int originalHeight,
int width,
int height,
double rotationFromOriginal)
{
Point original = new Point();
double angle = rotationFromOriginal % 360;
if (angle == 0 )
{
original.X = normalized.X;
original.Y = normalized.Y;
} else if (angle == 90)
{
original.X = normalized.Y;
original.Y = (width - normalized.X);
} else if (angle == 180)
{
original.X = (width - normalized.X);
original.Y = (height - normalized.Y);
} else if (angle == 270)
{
original.X = height - normalized.Y;
original.Y = normalized.X;
}
double scalingFactor = (angle % 180 == 0) ? originalHeight / height : originalHeight / width;
original.X = (int) (original.X * scalingFactor);
original.Y = (int)(original.Y * scalingFactor);
return original;
}
案例:自定義映像技能
影像也可以傳入並從自定義技能傳回。 技能集 base64 編碼要傳遞至自定義技能的影像。 若要使用自定義技能內的影像,請將 設定 "/document/normalized_images/*/data" 為自定義技能的輸入。 在您的自定義技能程序代碼中,base64-decode 字串之後,再將它轉換成影像。 若要將影像傳回至技能集,請在將影像傳回至技能集之前,先將影像編碼為base64。
影像會以具有下列屬性的物件傳回。
{
"$type": "file",
"data": "base64String"
}
Azure 搜尋服務 Python 範例存放庫具有在 Python 中實作的完整範例,其中包含可擴充影像的自定義技能。
將影像傳遞至自定義技能
針對需要自定義技能來處理影像的案例,您可以將影像傳遞至自定義技能,並讓它傳回文字或影像。 下列技能集來自範例。
下列技能集會採用標準化影像(在檔破解期間取得),並輸出影像的配量。
範例技能集
{
"description": "Extract text from images and merge with content text to produce merged_text",
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "ImageSkill",
"description": "Segment Images",
"context": "/document/normalized_images/*",
"uri": "https://your.custom.skill.url",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 100,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "slices",
"targetName": "slices"
}
],
"httpHeaders": {}
}
]
}
自定義技能範例
自定義技能本身是技能集外部的。 在此情況下,它是 Python 程式代碼,會先以自定義技能格式循環處理要求記錄批次,然後將base64編碼的字串轉換成影像。
# deserialize the request, for each item in the batch
for value in values:
data = value['data']
base64String = data["image"]["data"]
base64Bytes = base64String.encode('utf-8')
inputBytes = base64.b64decode(base64Bytes)
# Use numpy to convert the string to an image
jpg_as_np = np.frombuffer(inputBytes, dtype=np.uint8)
# you now have an image to work with
類似於傳回影像,在 JSON 物件中傳回 base64 編碼字串,其 屬性為 $typefile。
def base64EncodeImage(image):
is_success, im_buf_arr = cv2.imencode(".jpg", image)
byte_im = im_buf_arr.tobytes()
base64Bytes = base64.b64encode(byte_im)
base64String = base64Bytes.decode('utf-8')
return base64String
base64String = base64EncodeImage(jpg_as_np)
result = {
"$type": "file",
"data": base64String
}