2 - 使用 JavaScript 建立及載入搜尋索引
請遵循下列步驟以繼續建置支援搜尋的網站:
- 建立搜尋資源
- 建立新的索引
- 使用 bulk_insert_books 指令碼 和 Azure SDK @azure/search-documents 透過 JavaScript 匯入資料。
建立 Azure AI 搜尋服務資源
使用 Azure CLI 或 Azure PowerShell,透過命令列建立新的搜尋資源。 您也需要擷取用於索引讀取權限的查詢金鑰,並取得用於新增物件的內建系統管理金鑰。
您必須在裝置上安裝 Azure CLI 或 Azure PowerShell。 如果您不是裝置上的本機系統管理員,請選擇 [Azure PowerShell],並使用 Scope 參數以目前使用者身分執行。
注意
此工作不需要適用於 Azure CLI 和 Azure PowerShell 的 Visual Studio Code 擴充功能。 Visual Studio Code 會辨識沒有擴充功能的命令列工具。
在 Visual Studio Code 的 [終端機] 底下,選取 [新增終端]。
連線至 Azure:
az login建立新的搜尋服務之前,請先列出您訂用帳戶的現有服務:
az resource list --resource-type Microsoft.Search/searchServices --output table如果您有想要使用的服務,請記下名稱,然後跳到下一節。
建立新的搜尋服務。 使用下列命令做為範本,將資源群組、服務名稱、服務層級、區域、分割區和複本替換為有效值。 下列陳述式會使用上一個步驟建立的「cognitive-search-demo-rg」資源群組,並指定「免費」層。 如果您的 Azure 訂用帳戶已經有免費的搜尋服務,請改為指定計費層,例如「基本」。
az search service create --name my-cog-search-demo-svc --resource-group cognitive-search-demo-rg --sku free --partition-count 1 --replica-count 1取得授與搜尋服務讀取權限的查詢金鑰。 搜尋服務會佈建兩個系統管理金鑰以及一個查詢金鑰。 將資源群組與搜尋服務替換為有效名稱。 將查詢金鑰複製到記事本,以便在稍後的步驟中貼到用戶端程式碼中:
az search query-key list --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc取得搜尋服務管理員 API 金鑰。 管理 API 金鑰會提供搜尋服務的寫入權限。 將其中一個系統管理金鑰複製到記事本,以便在建立及載入索引的大量匯入步驟中使用:
az search admin-key show --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc
準備用於 Azure AI 搜尋服務的大量匯入指令碼
此 ESM 指令碼會針對 Azure AI 搜尋服務使用 Azure SDK:
在 Visual Studio Code 中,開啟子目錄 (
search-website-functions-v4/bulk-insert) 中的bulk_insert_books.js檔案,用您自己的值取代下列變數,以向 Azure 搜尋服務 SDK 進行驗證:- YOUR-SEARCH-RESOURCE-NAME
- YOUR-SEARCH-ADMIN-KEY
import fetch from 'node-fetch'; import Papa from 'papaparse'; import { SearchClient, SearchIndexClient, AzureKeyCredential } from '@azure/search-documents'; // Azure AI Search resource settings const SEARCH_ENDPOINT = 'https://YOUR-RESOURCE-NAME.search.windows.net'; const SEARCH_ADMIN_KEY = 'YOUR-RESOURCE-ADMIN-KEY'; // Azure AI Search index settings const SEARCH_INDEX_NAME = 'good-books'; import SEARCH_INDEX_SCHEMA from './good-books-index.json' assert { type: 'json' }; // Data settings const BOOKS_URL = 'https://raw.githubusercontent.com/Azure-Samples/azure-search-sample-data/main/good-books/books.csv'; const BATCH_SIZE = 1000; // Create Search service client // used to upload docs into Index const client = new SearchClient( SEARCH_ENDPOINT, SEARCH_INDEX_NAME, new AzureKeyCredential(SEARCH_ADMIN_KEY) ); // Create Search service Index client // used to create new Index const clientIndex = new SearchIndexClient( SEARCH_ENDPOINT, new AzureKeyCredential(SEARCH_ADMIN_KEY) ); // Insert docs into Search Index // in batch const insertData = async (data) => { let batch = 0; let batchArray = []; for (let i = 0; i < data.length; i++) { const row = data[i]; // Convert string data to typed data // Types are defined in schema batchArray.push({ id: row.book_id, goodreads_book_id: parseInt(row.goodreads_book_id), best_book_id: parseInt(row.best_book_id), work_id: parseInt(row.work_id), books_count: !row.books_count ? 0 : parseInt(row.books_count), isbn: row.isbn, isbn13: row.isbn13, authors: row.authors.split(',').map((name) => name.trim()), original_publication_year: !row.original_publication_year ? 0 : parseInt(row.original_publication_year), original_title: row.original_title, title: row.title, language_code: row.language_code, average_rating: !row.average_rating ? 0 : parseFloat(row.average_rating), ratings_count: !row.ratings_count ? 0 : parseInt(row.ratings_count), work_ratings_count: !row.work_ratings_count ? 0 : parseInt(row.work_ratings_count), work_text_reviews_count: !row.work_text_reviews_count ? 0 : parseInt(row.work_text_reviews_count), ratings_1: !row.ratings_1 ? 0 : parseInt(row.ratings_1), ratings_2: !row.ratings_2 ? 0 : parseInt(row.ratings_2), ratings_3: !row.ratings_3 ? 0 : parseInt(row.ratings_3), ratings_4: !row.ratings_4 ? 0 : parseInt(row.ratings_4), ratings_5: !row.ratings_5 ? 0 : parseInt(row.ratings_5), image_url: row.image_url, small_image_url: row.small_image_url }); console.log(`${i}`); // Insert batch into Index if (batchArray.length % BATCH_SIZE === 0) { await client.uploadDocuments(batchArray); console.log(`BATCH SENT`); batchArray = []; } } // Insert any final batch into Index if (batchArray.length > 0) { await client.uploadDocuments(batchArray); console.log(`FINAL BATCH SENT`); batchArray = []; } }; const bulkInsert = async () => { // Download CSV Data file const response = await fetch(BOOKS_URL, { method: 'GET' }); if (response.ok) { console.log(`book list fetched`); const fileData = await response.text(); console.log(`book list data received`); // convert CSV to JSON const dataObj = Papa.parse(fileData, { header: true, encoding: 'utf8', skipEmptyLines: true }); console.log(`book list data parsed`); // Insert JSON into Search Index await insertData(dataObj.data); console.log(`book list data inserted`); } else { console.log(`Couldn\t download data`); } }; // Create Search Index async function createIndex() { SEARCH_INDEX_SCHEMA.name = SEARCH_INDEX_NAME; const result = await clientIndex.createIndex(SEARCH_INDEX_SCHEMA); } await createIndex(); console.log('index created'); await bulkInsert(); console.log('data inserted into index');在 Visual Studio 中開啟專案目錄子目錄 (
search-website-functions-v4/bulk-insert) 的整合式終端,然後執行下列命令以安裝相依項目。npm install
執行 Azure AI 搜尋服務的大量匯入指令碼
針對專案目錄的子目錄 (
search-website-functions-v4/bulk-insert),繼續使用 Visual Studio 中的整合式終端執行bulk_insert_books.js指令碼:npm start程式碼執行時,主控台會顯示進度。
上傳完成時,主控台最後列印的陳述式為「done (完成)」。
檢閱新的搜尋索引
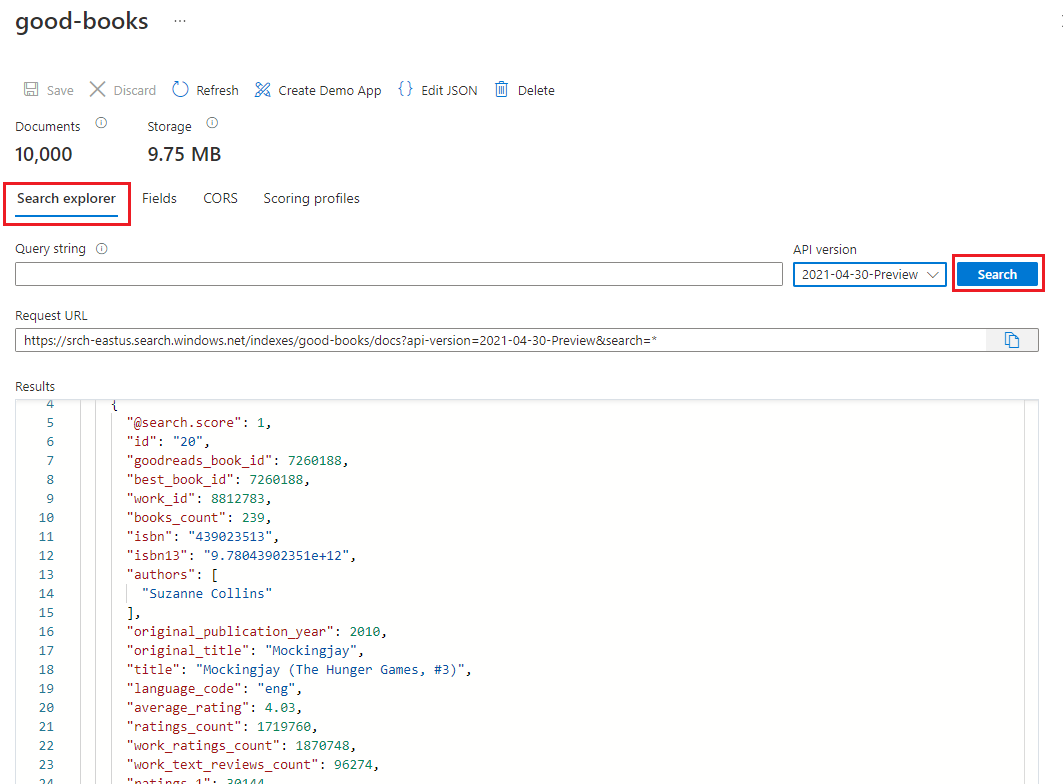
上傳完成之後,即可使用搜尋索引。 在 Azure 入口網站中檢閱您的新索引。
在 Azure 入口網站中,尋找您在上一個步驟中建立的搜尋服務。
在左側選取 [索引],然後選取好書索引。

根據預設,索引會在 [搜尋總管] 索引標籤中開啟。選取 [搜尋] 以從索引傳回文件。


復原大量匯入檔案變更
在 bulk-insert 目錄的 Visual Studio Code 整合式終端機中,使用下列 git 命令可復原變更。 本教學課程後續不會用到這些檔案,您不應將這些檔案秘密儲存或推送至您的存放庫。
git checkout .
複製您的 Azure 搜尋服務資源名稱
記下您的搜尋資源名稱。 您需要使用此名稱才能將 Azure Function 應用程式連線到您的搜尋資源。
警告
雖然您可能會想要在 Azure Function 中使用搜尋系統管理員密鑰,但這不符合最低權限原則。 Azure Function 會使用查詢金鑰以遵守最低權限。