從內部部署的 HDFS 存放區遷移至具有 Azure 資料箱的 Azure 儲存體
您可使用資料箱裝置,將資料從 Hadoop 叢集的內部部署 HDFS 存放區移轉至 Azure 儲存體 (Blob 儲存體或 Data Lake Storage Gen2)。 您可選擇資料箱磁碟、80 TB 的資料箱或 770 TB 的 Data Box Heavy。
本文可協助您完成下列工作:
- 準備遷移您的資料
- 將您的資料複製到資料箱磁碟、資料箱或 Data Box Heavy 裝置
- 將裝置寄回給 Microsoft
- 將存取權限套用至檔案和目錄 (僅限 Data Lake Storage Gen2)
必要條件
您需要這些專案才能完成移轉。
Azure 儲存體帳戶。
包含來源資料的內部部署 Hadoop 叢集。
-
將您的資料箱或 Data Box Heavy 連接至內部部署網路。
準備好後就可以開始進行。
將您的資料複製到資料箱裝置
如果您的資料能放入單一資料箱裝置,請將資料複製到資料箱裝置。
如果您的資料大小超過資料箱裝置的容量,請使用選擇性程式將資料分割到多個資料箱裝置,然後執行此步驟。
若要將資料從內部部署 HDFS 存放區複製到資料箱裝置,您需要進行一些設定,然後使用 DistCp 工具。
請遵循下列步驟,透過 Blob/物件儲存體的 REST API 將資料複製到您的資料箱裝置。 REST API 介面會讓裝置顯示為叢集的 HDFS 存放區。
透過 REST 複製資料之前,請先找出安全性和連線基本型別,以連接到資料箱上的 REST 介面或 Data Box Heavy。 登入資料箱的本機 web UI,然後移至連線並複製頁面。 針對您裝置的 Azure 儲存體帳戶,在存取設定下找出並選取 [REST]。
從 [存取儲存體帳戶並上傳資料] 對話方塊中,複製 [Blob 服務端點] 和 [儲存體帳戶金鑰]。 從 Blob 服務端點,省略
https://和結尾的斜線。在此情況下,端點為:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/。 您使用的 URI 主機部分是:mystorageaccount.blob.mydataboxno.microsoftdatabox.com。 如需範例,請參閱如何透過 HTTP 連線 REST。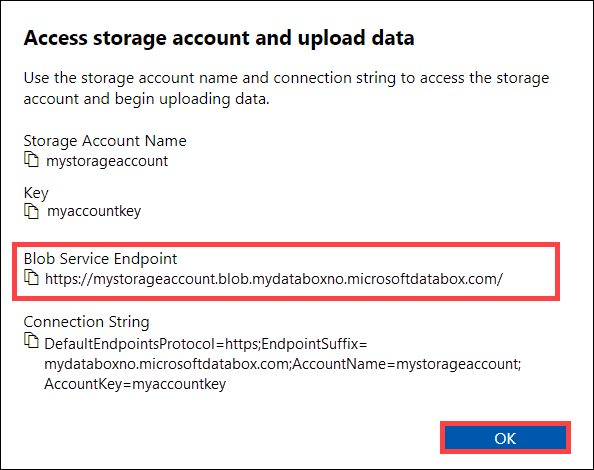
在每個節點上,將端點和資料箱或 Data Box Heavy 節點 IP 位址新增至
/etc/hosts。10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.com如果您使用 DNS 的其他機制,您應確認該機制可以解析資料箱端點。
將殼層變數
azjars設定為hadoop-azure和azure-storagejar 檔案的位置。 您可以在 Hadoop 安裝目錄下找到這些檔案。若要判斷這些檔案是否存在,請使用下列命令:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure。 將<hadoop_install_dir>預留位置取代為您已安裝 Hadoop 的目錄路徑。 請務必使用完整路徑。範例:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jar建立您想要用於資料複製的儲存體容器。 您也應該將目的地目錄指定為此命令的一部分。 這可能是虛擬目的地目錄。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>將
<blob_service_endpoint>預留位置取代為您 Blob 服務端點的名稱。將
<account_key>預留位置取代為您帳戶的存取金鑰。將
<container-name>預留位置取代為您的容器名稱。將
<destination_directory>預留位置取代為您想要將資料複製到其中的目錄名稱。
執行清單命令,以確保您的容器和目錄已建立。
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/將
<blob_service_endpoint>預留位置取代為您 Blob 服務端點的名稱。將
<account_key>預留位置取代為您帳戶的存取金鑰。將
<container-name>預留位置取代為您的容器名稱。
將資料從 Hadoop HDFS 複製到資料箱 Blob 儲存體,然後複製到您稍早建立的容器。 如果找不到您要複製的目錄,此命令會自動建立該目錄。
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>將
<blob_service_endpoint>預留位置取代為您 Blob 服務端點的名稱。將
<account_key>預留位置取代為您帳戶的存取金鑰。將
<container-name>預留位置取代為您的容器名稱。將
<exlusion_filelist_file>預留位置取代為包含您檔案排除清單的檔案名。將
<source_directory>預留位置取代為包含您要複製資料的目錄名稱。將
<destination_directory>預留位置取代為您想要將資料複製到其中的目錄名稱。
-libjars選項可用來讓hadoop-azure*.jar和相依azure-storage*.jar檔案可供distcp使用。 某些叢集可能已經發生此情況。下列範例顯示如何使用
distcp命令來複製資料。hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/data若要改善複製速度:
請嘗試變更對應程式數目。 (對應工具的預設數目為 20。上述範例使用
m= 4 對應工具。)嘗試
-D fs.azure.concurrentRequestCount.out=<thread_number>。 將<thread_number>取代為每個對應程式的執行緒數目。 對應工具數目和每個對應工具的執行緒數目m*<thread_number>不應超過 32。請嘗試以平行方式執行多個
distcp。請記住,大型檔案的執行效能優於小型檔案。
如果您有大於 200 GB 的檔案,建議您使用下列參數將區塊大小變更為 100MB:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
將資料箱寄送給 Microsoft
遵循下列步驟來準備資料箱裝置並寄送至 Microsoft。
裝置準備完成後,下載 BOM 檔案。 您稍後將會使用這些 BOM 或資訊清單檔來確認已上傳至 Azure 的資料。
關閉裝置電源並移除纜線。
與 UPS 排定取貨時間。
針對資料箱裝置,請參閱寄送資料箱。
針對 Data Box Heavy 裝置,請參閱寄送您的 Data Box Heavy。
Microsoft 收到您的裝置之後,便會連線到資料中心網路,並將資料上傳至您在下單時指定的儲存體帳戶。 針對您已將所有資料上傳至 Azure 的 BOM 檔案進行驗證。
將存取權限套用至檔案和目錄 (僅限 Data Lake Storage Gen2)
您在 Azure 儲存體帳戶中已有資料。 現在請將存取權限套用至檔案和目錄。
注意
只有當您使用 Azure Data Lake Storage Gen2 作為資料存放區時,才需要執行此步驟。 如果您只使用沒有階層命名空間的 Blob 儲存體帳戶作為資料存放區,則可以略過本節。
為您的 Azure Data Lake Storage Gen2 啟用帳戶建立服務主體
若要建立服務主體,請參閱操作說明:使用入口網站來建立可存取資源的 Microsoft Entra 應用程式和服務主體 (部分機器翻譯)。
在執行該文章的將應用程式指派給角色一節中的步驟時,請確實將 [儲存體 Blob 資料參與者] 角色指派給服務主體。
在執行該文章的取得值以便登入一節中的步驟時,請將應用程式識別碼和用戶端密碼值儲存在文字檔中。 您稍後會需要這些資料。
產生複製檔案及其權限的清單
從內部部署 Hadoop 叢集執行此命令:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
此命令會產生複製檔案及其權限的清單。
注意
視 HDFS 中的檔案數目而定,此命令可能需要很長的時間才能執行。
產生身分識別清單,並將其對應至 Microsoft Entra 身分識別
下載
copy-acls.py指令碼。 請參閱本文的下載協助程式指令碼,並設定您的邊緣節點來執行這些指令碼一節。執行此命令以產生唯一身分識別的清單。
./copy-acls.py -s ./filelist.json -i ./id_map.json -g此指令碼會產生名為
id_map.json的檔案,其中包含您需要對應至 ADD 型身分識別的身分識別。在文字編輯器中開啟
id_map.json檔案。針對出現在檔案中的每個 JSON 物件,使用適當的對應身分識別,更新 Microsoft Entra 使用者主體名稱 (UPN) 或 ObjectId (OID) 的
target屬性。 完成之後,請儲存檔案。 您會在下一個步驟中使用此檔案。
將權限套用至複製的檔案並套用身分識別對應
執行此命令,將權限套用至您複製到 Data Lake Storage Gen2 啟用帳戶中的資料:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
使用您的儲存體帳戶名稱取代
<storage-account-name>預留位置。將
<container-name>預留位置取代為您的容器名稱。以您在建立服務主體時所收集的應用程式識別碼和用戶端密碼取代
<application-id>和<client-secret>預留位置。
附錄:跨多個資料箱裝置分割資料
將資料移到資料箱裝置之前,您必須先下載一些協助程式指令碼,確定您的資料已經過整理可放入資料箱裝置,並排除任何不必要的檔案。
下載協助程式指令碼,並設定您的邊緣節點加以執行
從您內部部署 Hadoop 叢集的邊緣或前端節點,執行此命令:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loader此命令會複製包含協助程式指令碼的 GitHub 存放庫。
請確定您的本機電腦上已安裝 jq 封裝。
sudo apt-get install jq安裝要求 Python 套件。
pip install requests設定必要指令碼的 execute 權限。
chmod +x *.py *.sh
確定您的資料組織符合資料箱裝置
如果您的資料大小超過單一資料箱裝置的大小,則可以將檔案分割成多個群組,以便儲存至多個資料箱裝置。
如果您的資料未超過單一資料箱裝置的大小,則可以繼續進行下一節。
使用更高的權限,依照上一節中指導方針執行您下載的
generate-file-list指令碼。以下是命令參數的說明:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.將產生的檔案清單複製到 HDFS,提供 DistCp 作業存取。
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
排除不必要的檔案
您必須從 DisCp 作業中排除部分目錄。 例如,排除包含狀態資訊的目錄,讓叢集保持執行狀態。
在您打算起始 DistCp 作業的內部部署 Hadoop 叢集上,建立指定您要排除的目錄清單的檔案。
以下是範例:
.*ranger/audit.*
.*/hbase/data/WALs.*
下一步
瞭解 Data Lake Storage Gen2 與 HDInsight 叢集搭配運作的方式。 如需詳細資訊,請參閱搭配 Azure HDInsight 叢集使用 Azure Data Lake Storage Gen2。