搭配 Synapse SQL 使用外部資料表
外部資料表會指向 Hadoop、Azure 儲存體 Blob 或 Azure Data Lake 儲存體 中的資料。 您可以使用外部資料表從檔案讀取資料,或將資料寫入Azure 儲存體中的檔案。
透過 Synapse SQL,您可以使用外部資料表,使用專用 SQL 集區或無伺服器 SQL 集區來讀取外部資料。
根據外部資料源的類型,您可以使用兩種類型的外部資料表:
- 您可以用來讀取和匯出各種資料格式的 Hadoop 外部資料表 ,例如 CSV、Parquet 和 ORC。 Hadoop 外部資料表可在專用 SQL 集區中使用,但無法在無伺服器 SQL 集區中使用。
- 原生外部資料表 ,可用來讀取和匯出各種資料格式的資料,例如 CSV 和 Parquet。 原生外部資料表可在無伺服器 SQL 集區中使用,而且它們處於 專用 SQL 集區中的公開預覽狀態 。 使用 CETAS 和原生外部資料表寫入/匯出資料僅適用于無伺服器 SQL 集區,但不適用於專用 SQL 集區。
Hadoop 與原生外部資料表之間的主要差異:
| 外部資料表類型 | Hadoop | 原始 |
|---|---|---|
| 專用 SQL 集區 | 線上 | 公開預覽 版中 只能使用 Parquet 資料表。 |
| 無伺服器 SQL 集區 | 無法使用 | 可提供服務 |
| 支援的格式 | 分隔/CSV、Parquet、ORC、Hive RC 和 RC | 無伺服器 SQL 集區:分隔/CSV、Parquet 和 Delta Lake 專用 SQL 集區:Parquet (預覽) |
| 資料夾分割區刪除 | No | 資料分割消除僅適用于從 Apache Spark 集區同步處理的 Parquet 或 CSV 格式所建立的資料分割資料表。 您可能會在 Parquet 資料分割資料夾上建立外部資料表,但無法存取和忽略資料分割資料行,但不會套用資料分割刪除。 請勿在 Delta Lake 資料夾 上建立 外部資料表,因為它們不受支援。 如果您需要查詢分割的 Delta Lake 資料,請使用 差異資料分割檢視 。 |
| 檔案刪除 (述詞下推) | No | 是,在無伺服器 SQL 集區中。 針對字串下推,您必須在資料行上使用 Latin1_General_100_BIN2_UTF8VARCHAR 定序來啟用下推。 如需定序的詳細資訊,請參閱 Synapse SQL 支援的定序類型。 |
| 位置的自訂格式 | No | 是,針對 Parquet 或 CSV 格式使用通 /year=*/month=*/day=* 配符。 Delta Lake 中無法使用自訂資料夾路徑。 在無伺服器 SQL 集區中,您也可以使用遞迴萬用字元 /logs/** ,參考參考資料夾下任何子資料夾中的 Parquet 或 CSV 檔案。 |
| 遞迴資料夾掃描 | Yes | 是。 在無伺服器 SQL 集區中,必須在位置路徑的結尾指定 /** 。 在專用集區中,資料夾一律會以遞迴方式掃描。 |
| 儲存體驗證 | 儲存體 Access Key(SAK)、Microsoft Entra 傳遞、受控識別、自訂應用程式 Microsoft Entra 身分識別 | 共用存取簽章(SAS) 、 Microsoft Entra 傳遞 、 受控識別 、 自訂應用程式 Microsoft Entra 身分識別 。 |
| 資料行對應 | 序數 - 外部資料表定義中的資料行會依位置對應至基礎 Parquet 檔案中的資料行。 | 無伺服器集區:依名稱。 外部資料表定義中的資料行會依資料行名稱比對對應到基礎 Parquet 檔案中的資料行。 專用集區:序數比對。 外部資料表定義中的資料行會依位置對應至基礎 Parquet 檔案中的資料行。 |
| CETAS (匯出/轉換) | Yes | 以原生資料表作為目標的 CETAS 僅適用于無伺服器 SQL 集區。 您無法使用專用 SQL 集區,使用原生資料表匯出資料。 |
注意
原生外部資料表是集區中一般可用的建議解決方案。 如果您需要存取外部資料,請一律在無伺服器集區中使用原生資料表。 在專用集區中,您應該切換至原生資料表,以在 GA 中讀取 Parquet 檔案。 只有在您需要存取原生外部資料表中不支援的某些類型時,才使用 Hadoop 資料表(例如 - ORC、RC),或無法使用原生版本時。
專用 SQL 集區和無伺服器 SQL 集區中的外部資料表
您可以使用外部資料表來:
- 使用 Transact-SQL 語句查詢Azure Blob 儲存體和 Azure Data Lake Gen2。
- 使用 CETAS 將查詢結果儲存至 Azure Blob 儲存體 或 Azure Data Lake 儲存體中的檔案。
- 從 Azure Blob 儲存體 和 Azure Data Lake 匯入資料儲存體,並將其儲存在專用 SQL 集區中(僅限專用集區中的 Hadoop 資料表)。
注意
搭配 CREATE TABLE AS SELECT 語句使用時,從外部資料表選取會將資料匯入專用 SQL 集區內的 資料表。
如果專用集區中的 Hadoop 外部資料表效能不符合您的效能目標,請考慮使用 COPY 語句 將外部資料載入 Datawarehouse 資料表。
如需載入教學課程,請參閱 使用 PolyBase 從Azure Blob 儲存體 載入資料。
您可以透過下列步驟在 Synapse SQL 集區中建立外部資料表:
- 建立 EXTERNAL DATA SOURCE 以參考外部 Azure 儲存體,並指定應該用來存取儲存體的認證。
- 建立 EXTERNAL FILE FORMAT 來描述 CSV 或 Parquet 檔案的格式。
- 使用相同檔案格式,在資料來源上放置的檔案上方建立 EXTERNAL TABLE 。
資料夾分割區刪除
Synapse 集區中的原生外部資料表可以忽略放置於與查詢無關之資料夾中的檔案。 如果您的檔案儲存在資料夾階層中(例如 - /year=2020/month=03/day=16 ),以及 、 和 day 的值 monthyear 公開為數據行,則包含篩選 year=2020 的查詢只會從資料夾內 year=2020 放置的子資料夾讀取這些檔案。 在這個查詢中,放置於其他資料夾的 year=2021year=2022 檔案和資料夾將會忽略。 此刪除稱為 分割區消除 。
從 Synapse Spark 集區同步處理的原生外部資料表中,可以使用資料夾資料分割刪除。 如果您已分割資料集,而且想要利用資料分割消除與您所建立的外部資料表,請使用 資料分割檢視 ,而不是外部資料表。
檔案刪除
Parquet 和 Delta 等某些資料格式包含每個資料行的檔案統計資料(例如,每個資料行的最小值/最大值)。 篩選資料的查詢不會讀取必要資料行值不存在的檔案。 查詢會先探索查詢述詞中使用的資料行最小值/最大值,以尋找不包含必要資料的檔案。 這些檔案將會被忽略,並從查詢計劃中排除。
這項技術也稱為篩選述詞下推,並可改善查詢的效能。 在 Parquet 和 Delta 格式的無伺服器 SQL 集區中,可以使用篩選下推。 若要利用字串類型的篩選下推,請使用 VARCHAR 類型搭配 Latin1_General_100_BIN2_UTF8 定序。 如需定序的詳細資訊,請參閱 Synapse SQL 支援的定序類型。
安全性
使用者必須具有 SELECT 外部資料表的許可權,才能讀取資料。
外部資料表會使用資料來源中定義的資料庫範圍認證,使用下列規則來存取基礎 Azure 儲存體:
- 沒有認證的資料來源可讓外部資料表存取 Azure 儲存體上的公開可用檔案。
- 資料來源可以有一個認證,可讓外部資料表只使用 SAS 權杖或工作區受控識別存取 Azure 儲存體上的檔案 - 如需範例,請參閱 開發儲存體檔案儲存體存取控制 一文。
CREATE EXTERNAL DATA SOURCE 的範例
下列範例會在指向紐約資料集的 Azure Data Lake Gen2 專用 SQL 集區中建立 Hadoop 外部資料源:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2018-03-28&ss=bf&srt=sco&sp=rl&st=2019-10-14T12%3A10%3A25Z&se=2061-12-31T12%3A10%3A00Z&sig=KlSU2ullCscyTS0An0nozEpo4tO5JAgGBvw%2FJX2lguw%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
下列範例會建立 Azure Data Lake Gen2 的外部資料源,指向可公開取得的紐約資料集:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
CREATE EXTERNAL FILE FORMAT 的範例
下列範例會建立人口普查檔案的外部檔案格式:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
CREATE EXTERNAL TABLE 範例
下列範例會建立外部資料表, 它會傳回第一個資料列:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
從 Azure Data Lake 中的檔案建立和查詢外部資料表
使用 Synapse Studio 的 Data Lake 探索功能,您現在可以使用 Synapse SQL 集區建立及查詢外部資料表,並以簡單的滑鼠右鍵按一下檔案。 只有 Parquet 檔案支援單鍵手勢,從 ADLS Gen2 儲存體帳戶建立外部資料表。
必要條件
您必須具有 ADLS
Storage Blob Data ContributorGen2 帳戶或存取控制清單 (ACL) 的存取角色,才能查詢檔案的工作區。您必須擁有至少 許可權,才能在 Synapse SQL 集區上建立外部資料表 並查詢外部資料表(專用或無伺服器)。
從 [資料] 面板中,選取您想要從下列專案建立外部資料表的檔案:
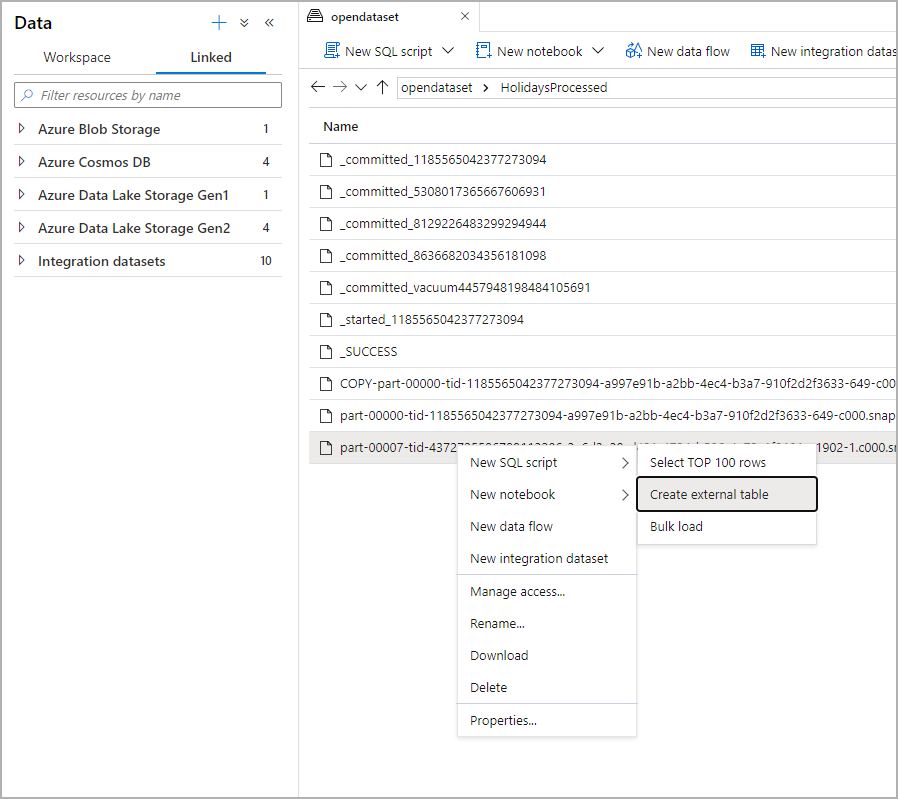
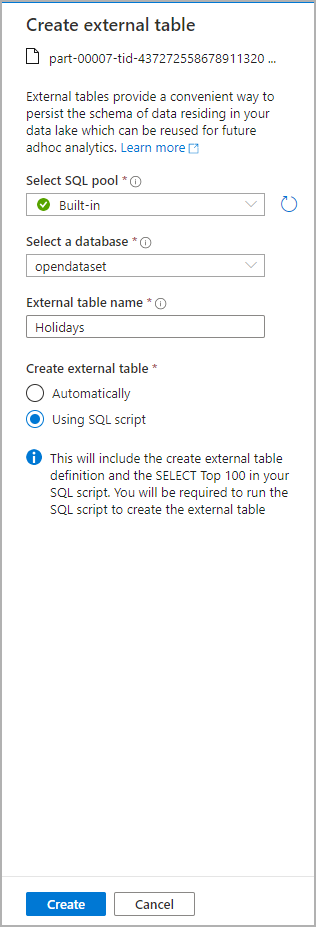
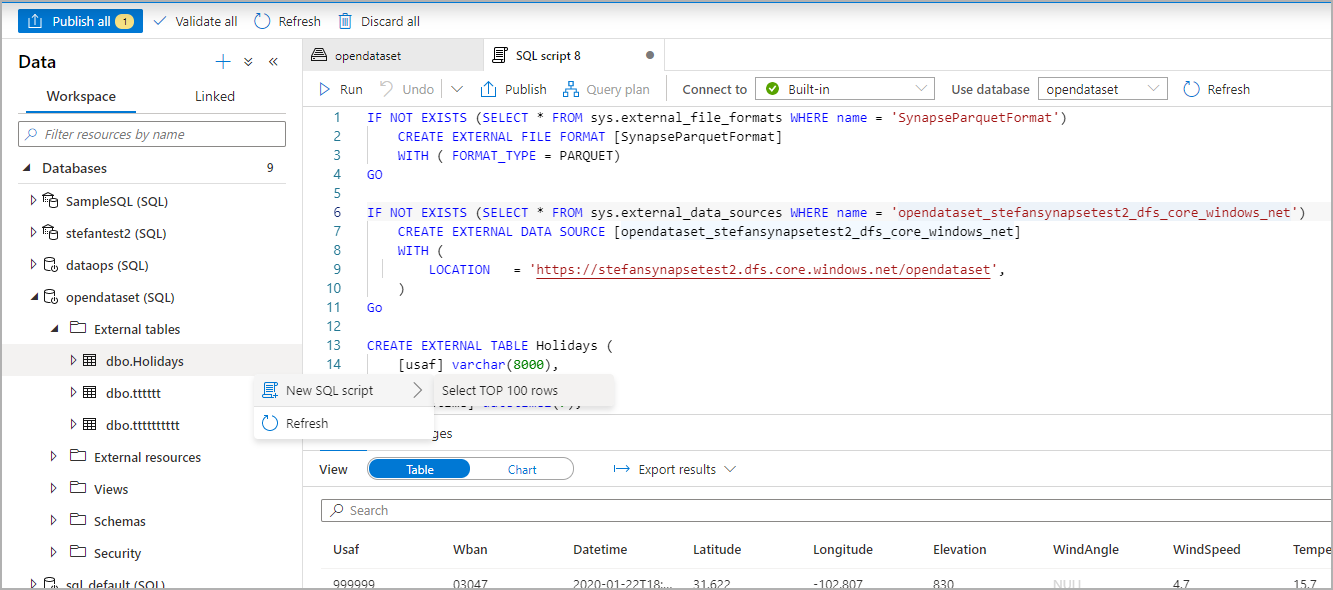
對話方塊視窗隨即開啟。 選取專用 SQL 集區或無伺服器 SQL 集區,為數據表指定名稱,然後選取開啟的腳本:
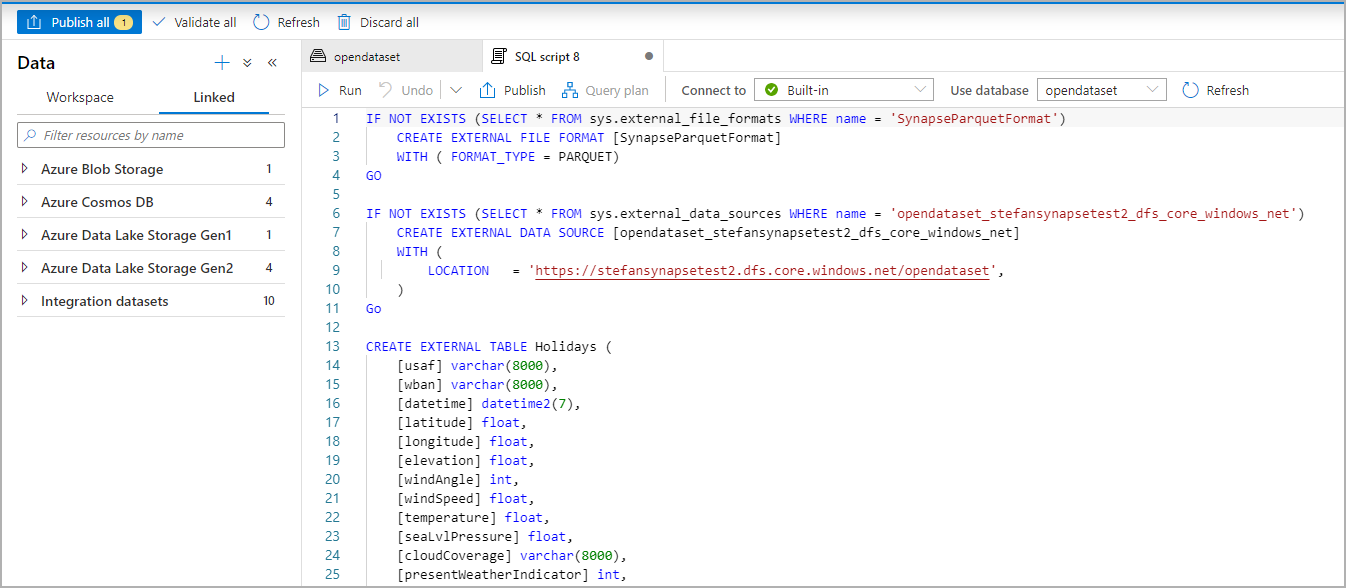
SQL 腳本會自動從檔案推斷架構:
執行指令碼。 腳本會自動執行選取前 100 名 *..
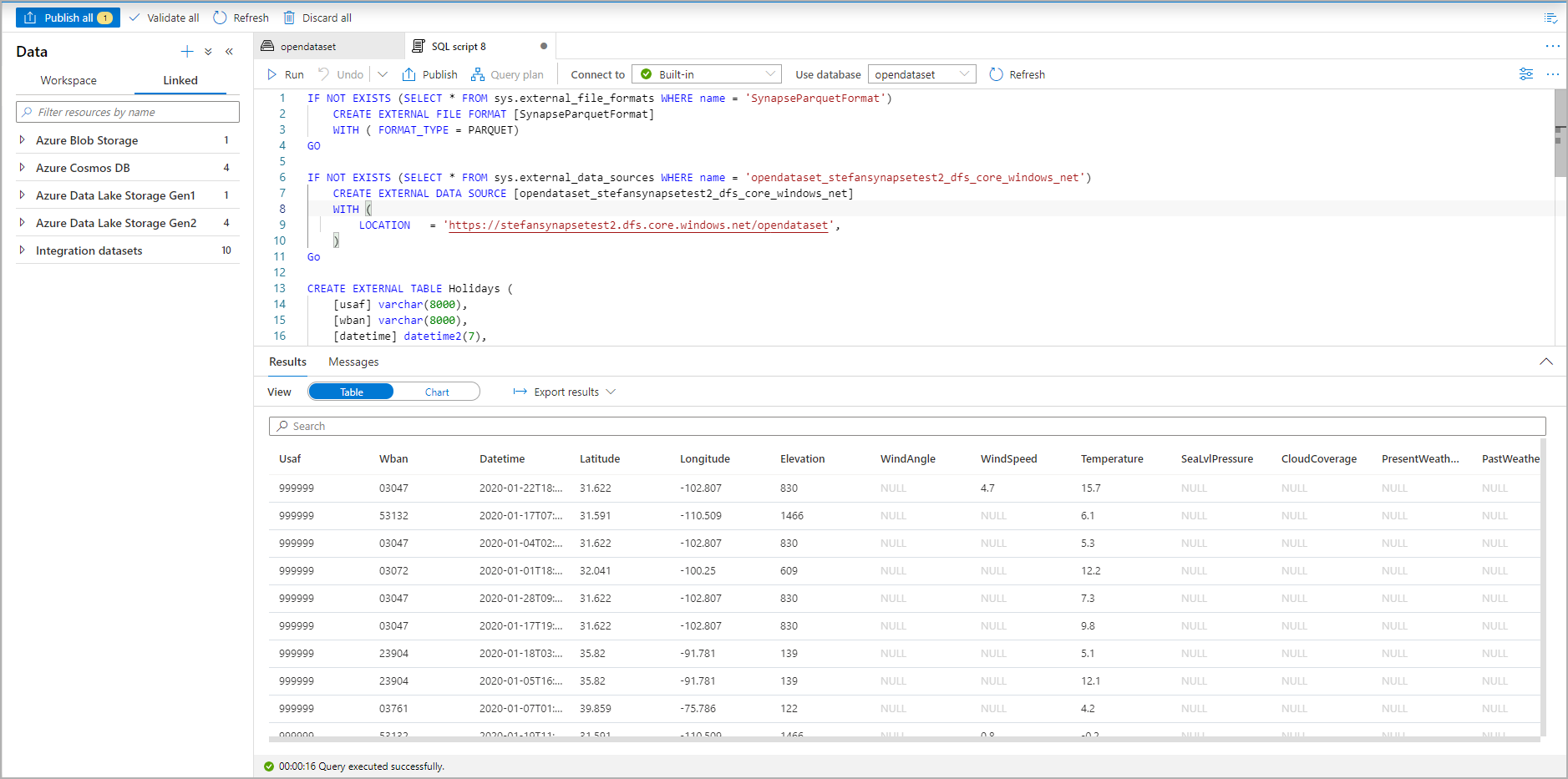
現在會建立外部資料表,以供未來探索此外部資料表的內容,使用者可以直接從 [資料] 窗格查詢它:
下一步
如需如何將查詢結果儲存至Azure 儲存體中的外部資料表,請參閱 CETAS 一文。 或者,您可以開始查詢 適用于 Azure Synapse 外部資料表 的 Apache Spark。