什麼是模型建立器且其如何運作?
ML.NET 模型建立器是直覺式圖形化 Visual Studio 延伸模組,其用於建置、定型和部署自訂機器學習模型。 Model Builder 會使用自動化的機器學習服務 (AutoML) 來探索不同機器學習服務演算法和設定,協助您找出最適合您案例的組合。
就算不具機器學習專業知識,您也能使用 Model Builder。 您只需要一些資料和待解決的問題。 模型建立器會產生程式碼,將模型新增至您的 .NET 應用程式。

建立 Model Builder 專案
當您第一次啟動 Model Builder 時,其會要求您命名專案,然後在專案內建立 mbconfig 設定檔。 mbconfig 檔案會持續追蹤您在 Model Builder 中執行的一切動作,讓您重新開啟工作階段。
定型之後,會在 *.mbconfig 檔案底下產生三個檔案:
- Model.consumption.cs:此檔案包含
ModelInput和ModelOutput結構描述,以及為了取用模型而產生的Predict函式。 - Model.training.cs:此檔案包含 Model Builder 選擇用來定型模型的定型管線 (資料轉換、演算法、演算法超參數)。 您可以使用此管線來重新定型模型。
- Model.zip:這是代表已定型 ML.NET 模型的序列化 ZIP 檔案。
建立 mbconfig 檔案時,系統會提示您輸入名稱。 此名稱會套用至取用、定型和模型檔案。 在此案例中,使用的名稱為 Model。
案例
您可以在模型建立器中放入許多不同的案例,以產生應用程式的機器學習模型。
案例是您想要使用資料進行的預測類型描述。 例如:
- 根據歷史銷售資料預測未來的產品銷售量。
- 根據客戶評論將人氣分類為正面或負面。
- 偵測銀行交易是否為詐騙。
- 將客戶意見反應問題路由至公司的正確小組。
每個案例會對應至不同的機器學習工作,包括:
| Task | 案例 |
|---|---|
| 二元分類 | 資料分類 |
| 多類別分類 | 資料分類 |
| 影像分類 | 影像分類 |
| 文字分類 | 文字分類 |
| 迴歸 | 預測值 |
| 建議 | 建議 |
| 預測 | 預測 |
例如,將情感分類為正面或負面的案例,會歸類在二元分類工作下。
若要深入了解 ML.NET 所支援的不同 ML 工作,請參閱 ML.NET 中的機器學習工作。
哪種機器學習服務案例適合我?
在 Model Builder 中,您必須選取案例。 案例型別取決於您嘗試進行的預測型別。
表格式
資料分類
分類可用來為資料區分類別。
範例輸入
範例輸出
| SepalLength | SepalWidth | 花瓣長度 | 花瓣寬度 | 種類 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 預測物種 |
|---|
| setosa |
預測值
值預測 (屬於迴歸工作) 可用來預測數值。
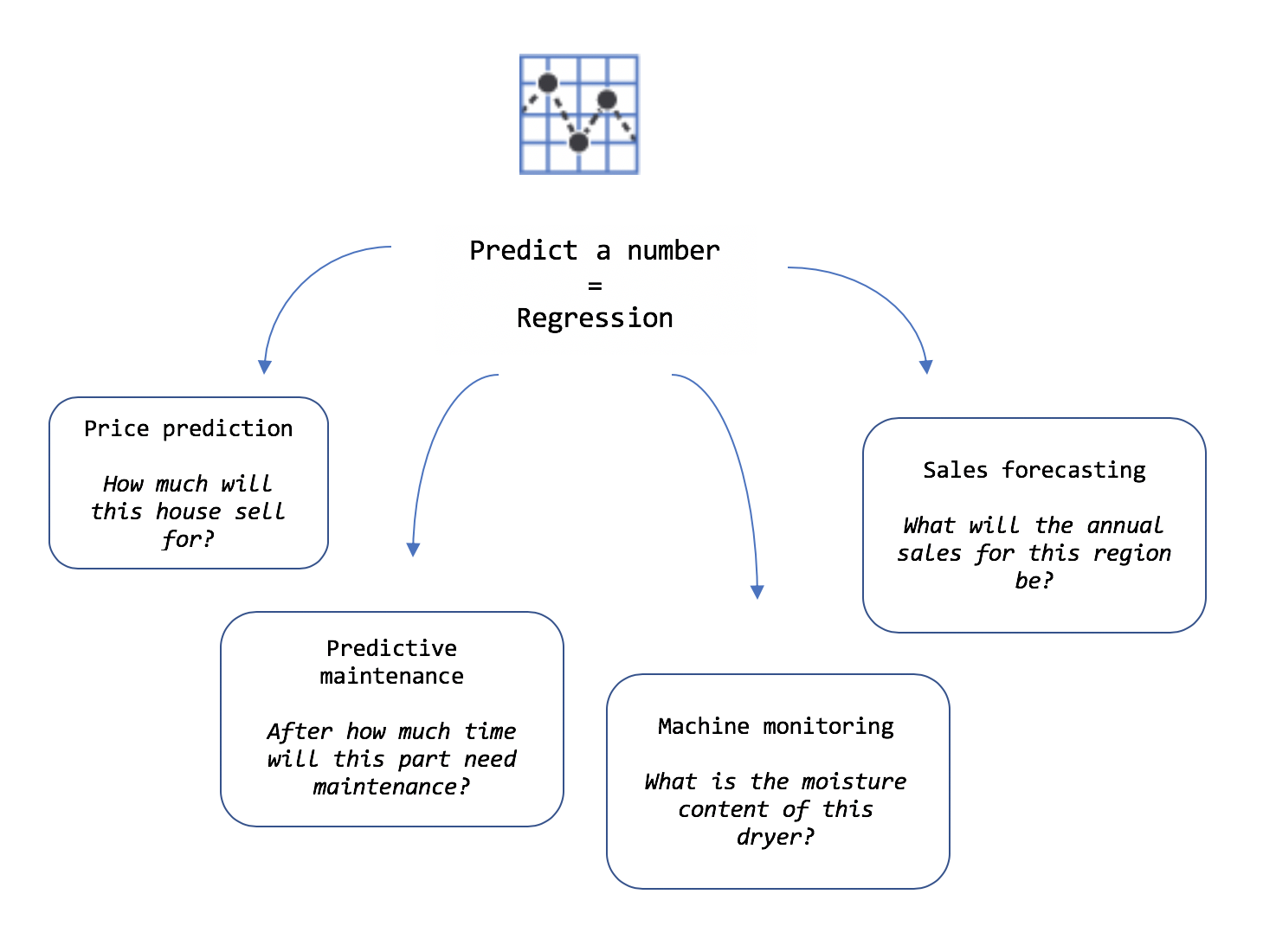
範例輸入
範例輸出
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| 預測費用 |
|---|
| 4.5 |
建議
建議案例會根據特定使用者的喜好與其他使用者的相似程度,為他們預測建議項目清單。
若您有一組使用者和一組「產品」(例如要購買的商品、電影、書籍或電視節目),以及一組使用者對這些產品的「評等」,即可使用建議案例。
範例輸入
範例輸出
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| 預測評等 |
|---|
| 4.5 |
預測
預測案例會使用具有時間序列或季節性成分的歷史資料。
您可以使用預測案例來預測產品的需求或銷售量。
範例輸入
範例輸出
| Date | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| 3 天預測 |
|---|
| [1000,1001,1002] |
電腦視覺
影像分類
影像分類可用來識別不同類別的影像。 例如,不同型別的地形、動物或製造瑕疵。
如果您有一組影像,且您想要將影像分類成不同的類別,您可以使用影像分類案例。
範例輸入
範例輸出

| 預測標籤 |
|---|
| 狗 |
物件偵測
物件偵測可用來尋找及分類影像內的實體。 例如,尋找及識別影像中的汽車和人物。
當影像包含不同型別的多個物件時,您可以使用物件偵測。
範例輸入
範例輸出

自然語言處理
文字分類
文字分類會將原始文字輸入分類。
如果您有一組文件或註解,且您想要將其分類成不同的類別,可以使用文字分類案例。
範例輸入
範例輸出
| 檢閱 |
|---|
| 我真的很喜歡這牛排! |
| 情緒 |
|---|
| 正值 |
Environment
您可以在本機電腦或 Azure 上的雲端中定型機器學習模型,視案例而定。
在本機定型時,您將在電腦資源 (CPU、記憶體和磁碟) 的條件約束內工作。 在雲端中定型時,您可以擴大資源以符合案例的需求,特別是對於大型資料集。
| 案例 | 本機 CPU | 本機 GPU | Azure |
|---|---|---|---|
| 資料分類 | ✔️ | ❌ | ❌ |
| 預測值 | ✔️ | ❌ | ❌ |
| 建議 | ✔️ | ❌ | ❌ |
| 預測 | ✔️ | ❌ | ❌ |
| 影像分類 | ✔️ | ✔️ | ✔️ |
| 物件偵測 | ❌ | ❌ | ✔️ |
| 文字分類 | ✔️ | ✔️ | ❌ |
資料
選擇案例後,Model Builder 會要求您提供資料集。 資料用來定型、評估及選擇最適合您案例的模型。
Model Builder 支援 .tsv、.csv、.txt 和 SQL 資料庫格式的資料集。 如果您有 .txt 檔案,則應以 ,、; 或 \t 分隔資料行。
如果資料集是由影像組成的,支援的檔案型別為 .jpg 和 .png。
如需詳細資訊,請參閱將定型資料載入 Model Builder 中。
選擇要預測的輸出 (標籤)
資料集是定型範例資料列和屬性資料行的資料表。 每個資料列都有:
- 標籤 (您想要預測的屬性)
- 特性 (作為輸入用來預測標籤的屬性)
針對房價預測案例,可能的特性為:
- 房屋的坪數。
- 房間和衛浴數量。
- 郵遞區號。
標籤是坪數列、房間和衛浴值,以及郵遞區號資料列的歷史房價。
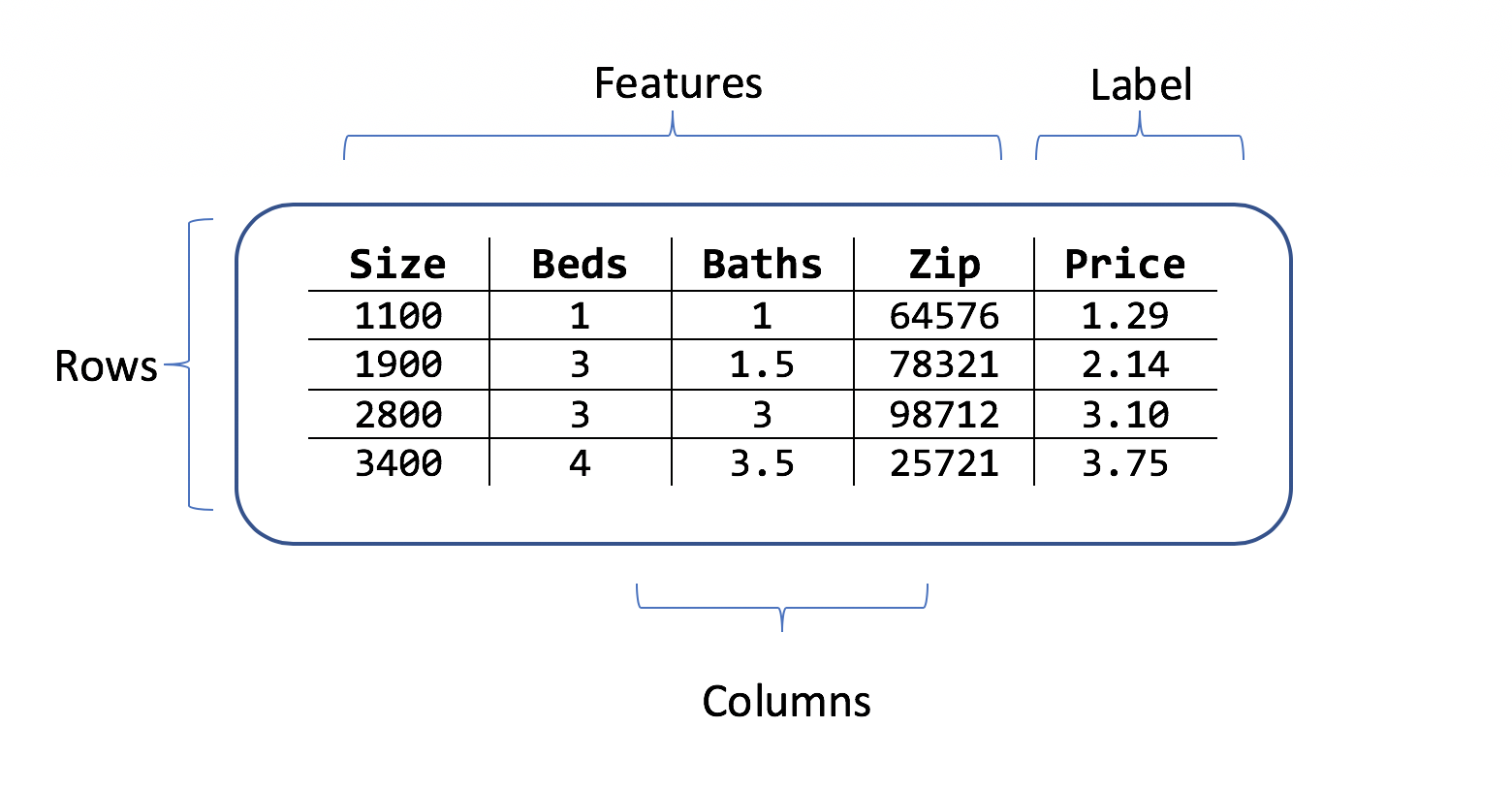
範例資料集
如果您還沒有自己的資料,請嘗試下列資料集之一:
| 案例 | 範例 | 資料 | 標籤 | 功能 |
|---|---|---|---|---|
| 分類 | 預測銷售異常 | 產品銷售資料 | 產品銷售 | 月 |
| 預測網站留言的情感 | 網站留言資料 | 標籤 (負面人氣時為 0,正面人氣時為 1) | 留言、年度 | |
| 預測詐騙信用卡交易 | 信用卡資料 | 類別 (詐騙時為 1,否則為 0) | 數量、V1-V28 (匿名特性) | |
| 預測 GitHub 存放庫中的問題型別 | GitHub 問題資料 | 區域 | 標題、描述 | |
| 預測值 | 預測計程車車資價格 | 計程車費用資料 | 費用 | 行車時間、距離 |
| 影像分類 | 預測花卉的類別 | 花卉影像 | 花卉型別:菊花、蒲公英、玫瑰、向日葵、鬱金香 | 影像資料本身 |
| 建議 | 預測某人喜歡的電影 | 電影評等 | 使用者、電影 | 分級 |
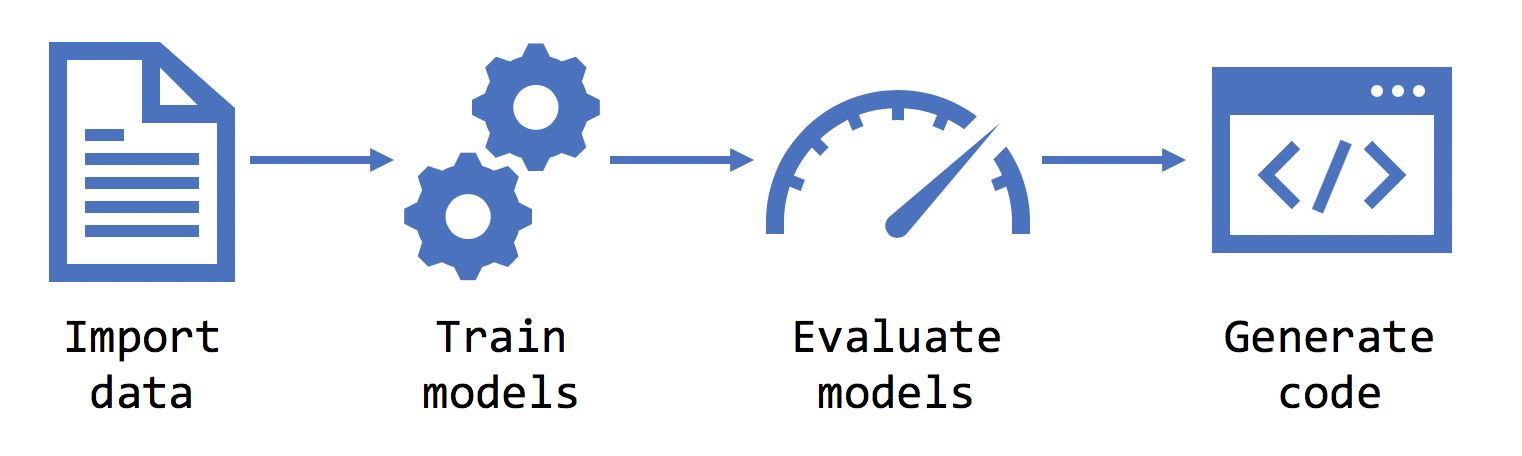
定型
在您選取案例、環境、資料和標籤後,Model Builder 就會定型模型。
什麼是定型?
定型模型建立器用來教導模型如何回答案例問題的自動化程序。 一旦定型,模型就可以使用之前未見過的輸入資料來建立預測。 例如,如果您要預測房價且有新屋上市,您就可以預測其銷售價格。
因為模型建立器使用自動化的機器學習服務 (AutoML),所以它不需要任何輸入,也不需要您在定型期間調整。
定型時間應該多長?
Model Builder 會使用 AutoML 探索多個模型,為您找出效能最佳的模型。
較長的定型期間可讓 AutoML 透過更廣泛的設定範圍探索更多模型。
下表摘要說明在本機電腦上以一套範例資料集取得良好效能所花費的平均時間。
| 資料集大小 | 定型的平均時間 |
|---|---|
| 0 - 10 MB | 10 秒 |
| 10 - 100 MB | 10 分鐘 |
| 100 - 500 MB | 30 分鐘 |
| 500 - 1 GB | 60 分鐘 |
| 1 GB+ | 3+ 小時 |
這些數字僅供指引之用。 定型的確切長度取決於:
- 作為模型輸入的特徵 (資料行) 數目。
- 資料行的類型。
- ML 工作。
- 用於定型的機器的 CPU、磁碟和記憶體效能。
一般情況下,建議使用超過 100 個資料列,因為低於此數的資料集可能不會產生任何結果。
評估
評估是測量模型表現優劣的程序。 Model Builder 會使用已定型的模型,以新的測試資料進行預測,然後測量預測的表現。
模型建立器會將定型資料分割為定型集和測試集。 定型資料 (80%) 用來定型模型,而測試資料 (20%) 則保留用於評估模型。
如何了解模型效能?
案例會對應至機器學習工作。 每個 ML 工作都有本身的一組評估計量。
預測值
值預測問題的預設計量是 RSquared,RSquared 的值介於 0 到 1 之間。 1 是可能的最佳值,換句話說,RSquared 的值愈接近 1,模型的執行效能就愈好。
報告的其他計量 (例如絕對損失、平方損失和 RMS 損失) 是額外的計量,可用來了解模型的表現,並將其與其他值預測模型比較。
分類 (2 個類別)
分類問題的預設計量為精確度。 精確度會定義您的模型對測試資料集做出正確預測的比例。 愈接近 100% 或 1.0 愈好。
報告的其他計量,例如測量確判為真率和誤判為真率的 AUC (曲線下的面積) 應大於 0.50,才是可接受的模型。
F1 分數等其他計量可用來控制精確度與召回率之間的平衡。
分類 (3 個以上的類別)
多元分類的預設計量為微精確度。 微精確度愈接近 100% 或 1.0 愈好。
多元分類的另一個重要計量是宏精確度,和微精確度一樣也是愈接近 1.0 愈好。 建議您以下列方式考量這兩種型別的精確度:
- 微精確度:傳入票證分類到正確小組的頻率為何?
- 宏準確度:對於普通小組而言,傳入票證對其小組正確的頻率為何?
評估計量的詳細資訊
如需詳細資訊,請參閱模型評估計量。
改善
如果您的模型效能分數不如預期,您可以:
延長定型時間。 有了較長的時間,自動化機器學習引擎就會以更多演算法和設定進行實驗。
新增更多資料。 有時資料數量不足,無法定型高品質的機器學習模型。資料集只有少量範例時尤其如此。
平衡資料。 針對分類工作,請務必平衡所有類別的定型集。 例如,如果您有四個類別的 100 個定型範例,有 90 筆記錄使用前兩個類別 (tag1 和 tag2),只有剩餘的 10 筆記錄使用其他兩個類別 (tag3 和 tag4),則資料失衡可能會導致模型難以正確預測 tag3 或 tag4。
取用
在評估階段後,模型建立器會輸出模型檔案,以及可用來將模型新增至應用程式的程式碼。 ML.NET 模型會儲存為 ZIP 檔案。 載入並使用模型的程式碼會新增為解決方案中新專案。 模型建立器也會新增範例主控台應用程式,您可以執行它以查看運行的模型。
此外,Model Builder 可讓您選擇建立取用模型的專案。 目前,Model Builder 會建立下列專案:
- 主控台應用程式:建立 .NET 主控台應用程式,以從模型進行預測。
- Web API:建立可讓您透過網際網路取用模型的 ASP.NET Core Web API。
接下來是什麼?
安裝 Model Builder Visual Studio 延伸模組。
請嘗試價格預測或任何迴歸案例。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應