教學課程:使用傳輸學習搭配 ML.NET 影像分類 API 進行自動化視覺檢查
瞭解如何使用傳輸學習、預先定型的 TensorFlow 模型和 ML.NET 影像分類 API 來將具象表面的影像分類為已破解或未建置。
在本教學課程中,您會了解如何:
- 了解問題
- 瞭解 ML.NET 影像分類 API
- 了解預先定型的模型
- 使用傳輸學習來定型自訂 TensorFlow 影像分類模型
- 使用自訂模型分類影像
必要條件
影像分類傳輸學習範例總覽
此範例是 C# .NET Core 主控台應用程式,可使用預先定型的深度學習 TensorFlow 模型來分類影像。 您可以在範例瀏覽器中找到此範例的程式碼。
了解問題
影像分類是電腦視覺問題。 影像分類會採用影像做為輸入,並將其分類為指定的類別。 影像分類模型通常會透過深度學習和神經網路進行定型。 如需詳細資訊,請參閱深度學習與機器學習。
影像分類具有實用性的一些案例包括:
- 臉部辨識
- 情緒偵測
- 醫療診斷
- 地標偵測
本教學課程會定型自訂影像分類模型,以執行橋面的自動化視覺檢查,以識別因破解而損毀的結構。
ML.NET 影像分類 API
ML.NET 提供各種執行影像分類的方式。 本教學課程會使用影像分類 API 來套用傳輸學習。 影像分類 API 會使用 TensorFlow.NET,這是提供 TensorFlow C++ API C# 系結的低階程式庫。
什麼是傳輸學習?
傳輸學習可將從解決一個問題所獲得的知識運用到另一個相關的問題。
若要從頭開始定型設定模型,將會需要設定數個參數、大量的標籤定型資料,以及大量的計算資源 (數以百計的 GPU 小時)。 使用預先定型的模型以及傳輸學習,可讓您以快捷方式進行定型程序。
定型程序
影像分類 API 會載入預先定型的 TensorFlow 模型,藉此啟動定型程序。 定型程序是由兩個步驟所組成:
- 瓶頸階段
- 定型階段
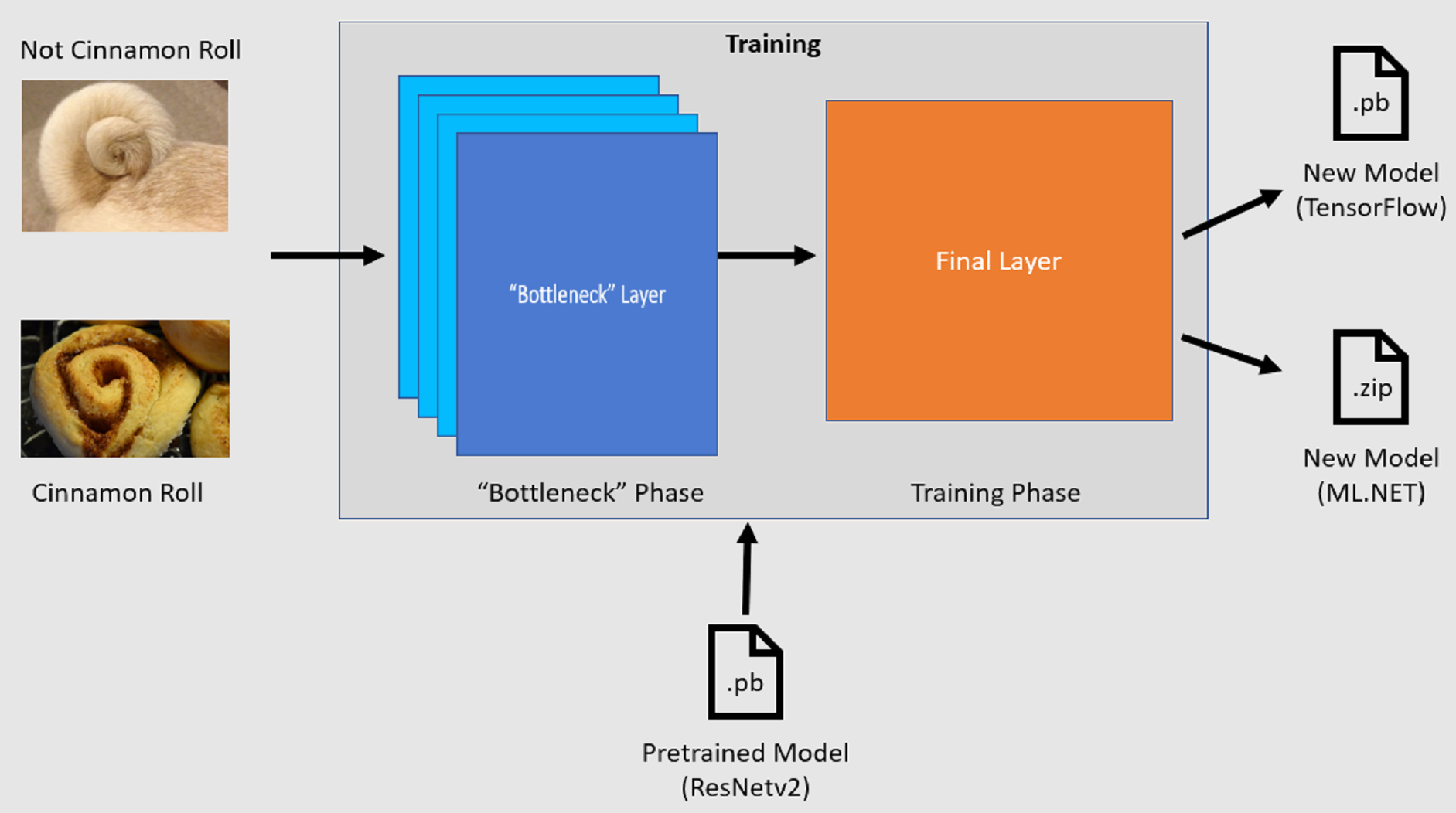
瓶頸階段
在瓶頸階段,會載入定型影像集,並針對預先定型模型的凍結層使用圖像素值,以做為輸入或特徵。 凍結層包含神經網路中所有層,最多至倒數第二層,通常稱為瓶頸層。 這些稱為凍結層,因為這些層上不會有任何定型,且作業會逕行傳遞。 其位於這些凍結層中,且會計算這層中可協助模型區分不同類別的較低層級模式。 層數愈多,此步驟的計算密集程度就越高。 幸運的是,由於這是一次性計算,因此在不同的參數進行實驗時,可在稍後執行中快取並使用結果。
定型階段
一旦計算瓶頸階段的輸出值之後,就會使用這些值當做輸入,以重新定型模型的最後一層。 此程序會反覆進行,並針對模型參數所指定的次數執行。 在每個執行期間,都會評估遺失和精確度。 然後,會進行適當的調整來改善模型,目標是將損失降至最低,並最大幅度提升精確度。 定型完成後,會輸出兩個模型格式。 其中一個是 .pb 模型的版本,另一個則是 .zip 模型 ML.NET 序列化版本。 在 ML.NET 支援的環境中工作時,建議使用 .zip 模型的版本。 不過,在不支援 ML.NET 的環境中,您可以選擇使用 .pb 版本。
了解預先定型的模型
本教學課程中使用的預先定型模型是剩餘網路 (ResNet) v2 模型的 101 層變體。 會定型原始模型,以將影像分類成千個類別。 模型會接受大小為 224 x 224 的影像做為輸入,並輸出其所定型每個類別的類別機率。 此模型的一部分會用來使用自訂影像定型新的模型,以在兩個類別之間進行預測。
建立主控台應用程式
現在您已大致了解傳輸學習和影像分類 API,接下來就可以建置應用程式。
建立名為「DeepLearning_ImageClassification_Binary」的 C# 主控台應用程式。 按 [下一步] 按鈕。
選擇 .NET 6 作為要使用的架構。 按一下 [ 建立 ] 按鈕。
安裝 Microsoft.ML NuGet 套件:
注意
除非另有說明,否則此樣本會使用所提及 NuGet 封裝的最新穩定版本。
- 在 [方案總管] 中,於您的專案上按一下滑鼠右鍵,然後選取 [管理 NuGet 套件]。
- 選擇「nuget.org」做為套件來源。
- 選取 [瀏覽] 索引標籤。
- 勾選 [包括發行前版本] 核取方塊。
- 搜尋 Microsoft.ML。
- 選取 [安裝] 按鈕。
- 在 [預覽變更] 對話方塊上,選取 [確定] 按鈕,然後在 [授權接受] 對話方塊上,如果您同意所列套件的授權條款,請選取 [我接受]。
- 針對 Microsoft.ML.Vision、SciSharp.TensorFlow.Redist2.3.1 版和 Microsoft.ML.ImageAnalytics NuGet 封裝重複這些步驟。
準備並了解資料
注意
本教學課程的資料集來源:Maguire, Marc; Dorafshan, Sattar; and Thomas, Robert J., "SDNET2018: A concrete crack image dataset for machine learning applications" (2018)。 瀏覽所有資料集。 平裝版 48。 https://digitalcommons.usu.edu/all_datasets/48
SDNET2018 是一個影像資料集,其中包含破解和非破解具體結構 (橋面、牆面和道路) 的註釋。

資料會組織為三個子目錄:
- D 包含橋面影像
- P 包含道路影像
- W 包含牆面影像
這些子目錄每個都包含兩個額外的前置子目錄:
- C 是用於破解表面的前置詞
- U 是用於非破解表面的前置詞
在本教學課程中,只會使用橋面影像。
- 下載資料集並進行解壓縮。
- 在專案中建立一個名為「assets」的目錄以儲存資料集檔案。
- 將最近解壓縮目錄中的 CD 和 UD 子目錄複製到「assets」目錄。
建立輸入及輸出類別
開啟 Program.cs 檔案,並以下列項目取代檔案頂端的現有
using狀態:using System; using System.Collections.Generic; using System.Linq; using System.IO; using Microsoft.ML; using static Microsoft.ML.DataOperationsCatalog; using Microsoft.ML.Vision;在 Program.cs 中的
Program類別下方,建立名為ImageData的類別。 這個類別會用來表示最初載入的資料。class ImageData { public string ImagePath { get; set; } public string Label { get; set; } }ImageData包含下列屬性:ImagePath是儲存影像的完整路徑。Label是影像所屬的實際類別。 這是要預測的值。
為您的輸入和輸出資料建立類別
在
ImageData類別下方,在名為ModelInput的新類別中定義輸入資料的結構描述。class ModelInput { public byte[] Image { get; set; } public UInt32 LabelAsKey { get; set; } public string ImagePath { get; set; } public string Label { get; set; } }ModelInput包含下列屬性:Image是影像的byte[]表示法。 模型會預期影像資料屬於此類型以進行定型。LabelAsKey是Label的數值表示法。ImagePath是儲存影像的完整路徑。Label是影像所屬的實際類別。 這是要預測的值。
只有
Image和LabelAsKey會用來定型模型並進行預測。 會保留ImagePath和Label屬性,以方便存取原始影像檔案名稱和類別。接著,在
ModelInput類別下方,在名為ModelOutput的新類別中,定義輸出資料的結構描述。class ModelOutput { public string ImagePath { get; set; } public string Label { get; set; } public string PredictedLabel { get; set; } }ModelOutput包含下列屬性:ImagePath是儲存影像的完整路徑。Label是影像所屬的原始類別。 這是要預測的值。PredictedLabel是模型所預測的值。
類似於
ModelInput,只需要PredictedLabel即可進行預測,因為其包含模型所做的預測。 會保留ImagePath和Label屬性,以方便存取原始影像檔案名稱和類別。
建立工作區目錄
當定型和驗證資料不常變更時,最好快取計算的瓶頸值,以進行進一步執行。
- 在您的專案中,建立名為 workspace 的新目錄,以儲存計算的瓶頸值和模型的
.pb版本。
定義路徑和初始化變數
在 using 陳述式下,定義資產的位置、計算的瓶頸值和模型的
.pb版本。var projectDirectory = Path.GetFullPath(Path.Combine(AppContext.BaseDirectory, "../../../")); var workspaceRelativePath = Path.Combine(projectDirectory, "workspace"); var assetsRelativePath = Path.Combine(projectDirectory, "assets");搭配 MLContext 的新執行個體來初始化
mlContext變數。MLContext mlContext = new MLContext();MLCoNtext類別是所有 ML.NET 作業的起點,初始化 mlCoNtext 會建立可在模型建立工作流程物件之間共用的新 ML.NET 環境。 就概念而言,類似於 Entity Framework 中的
DbContext。
載入資料
建立資料載入公用程式方法
影像會儲存在兩個子目錄中。 載入資料之前,必須先將其格式化為 ImageData 物件的清單。 執行方式是建立 LoadImagesFromDirectory 方法。
IEnumerable<ImageData> LoadImagesFromDirectory(string folder, bool useFolderNameAsLabel = true)
{
}
在
LoadImagesFromDirectory內,新增下列程式碼,以從子目錄取得所有檔案路徑:var files = Directory.GetFiles(folder, "*", searchOption: SearchOption.AllDirectories);然後,使用
foreach陳述式逐一查看每個檔案。foreach (var file in files) { }在
foreach陳述式中,檢查是否支援副檔名。 影像分類 API 支援 JPEG 和 PNG 格式。if ((Path.GetExtension(file) != ".jpg") && (Path.GetExtension(file) != ".png")) continue;然後,取得檔案的標籤。 如果將
useFolderNameAsLabel參數設定為true,則會使用儲存檔案的父目錄做為標籤。 否則,其會預期標籤為檔案名稱的前置詞或檔案名本身。var label = Path.GetFileName(file); if (useFolderNameAsLabel) label = Directory.GetParent(file).Name; else { for (int index = 0; index < label.Length; index++) { if (!char.IsLetter(label[index])) { label = label.Substring(0, index); break; } } }最後,建立
ModelInput的新執行個體。yield return new ImageData() { ImagePath = file, Label = label };
準備資料
呼叫
LoadImagesFromDirectory公用程式方法,以取得初始化mlContext變數之後,用於定型的影像清單。IEnumerable<ImageData> images = LoadImagesFromDirectory(folder: assetsRelativePath, useFolderNameAsLabel: true);然後,使用
LoadFromEnumerable方法將影像載入IDataView中。IDataView imageData = mlContext.Data.LoadFromEnumerable(images);資料會依目錄中的讀取順序載入。 若要平衡資料,請使用
ShuffleRows方法來隨機顯示資料。IDataView shuffledData = mlContext.Data.ShuffleRows(imageData);機器學習模型會預期輸入為數值格式。 因此,在定型之前,必須先對資料進行一些前置處理。 建立由
MapValueToKey和LoadRawImageBytes轉換組成的EstimatorChain。 轉換MapValueToKey會取得Label資料行中的類別值、將其轉換成數值KeyType,並將其儲存在名為LabelAsKey的新資料行中。 會從ImagePath資料行中擷取LoadImages值以及imageFolder參數,以載入要進行定型的影像。var preprocessingPipeline = mlContext.Transforms.Conversion.MapValueToKey( inputColumnName: "Label", outputColumnName: "LabelAsKey") .Append(mlContext.Transforms.LoadRawImageBytes( outputColumnName: "Image", imageFolder: assetsRelativePath, inputColumnName: "ImagePath"));使用
Fit方法,將資料套用至preprocessingPipelineEstimatorChain,隨後接著Transform方法,此方法會傳回包含預先處理資料的IDataView。IDataView preProcessedData = preprocessingPipeline .Fit(shuffledData) .Transform(shuffledData);若要定型模型,請務必具備定型資料集和驗證資料集。 模型會在定型集上進行。 其會根據驗證集的效能來測量對未顯示資料的預測程度。 根據該效能的結果,模型會調整其為了改善所習得的內容。 驗證集可取自分割原始資料集,或取自已針對此目的所設定的另一個來源。 在此情況下,預先處理的資料集會分割成定型、驗證和測試集。
TrainTestData trainSplit = mlContext.Data.TrainTestSplit(data: preProcessedData, testFraction: 0.3); TrainTestData validationTestSplit = mlContext.Data.TrainTestSplit(trainSplit.TestSet);上述程式碼範例會執行兩個分割。 首先,預先處理的資料會進行分割,其中 70% 用於定型,而剩餘的 30% 則用於驗證。 然後,30% 驗證集會進一步分割成驗證集和測試集,其中 90% 會用於驗證,10% 則用於測試。
思考這些資料分割用途的一種方式是進行測驗。 在研究測驗時,您可以檢閱筆記、書籍或其他資源,以掌握測驗中的概念。 這是定型集的用途。 然後,您可以進行模擬測驗來驗證您的知識。 這就是驗證集派上用場的地方。 您在進行實際測驗之前,需要先檢查是否已了解概念。 根據這些結果,您要記下犯錯或未充分了解的內容,並在檢閱實際測驗時,併入您的變更。 最後,您會進行測驗。 這是測試集的用途。 您從未看過測驗上的問題,現在請使用您自定型和驗證中學到的內容,將知識套用到手邊的工作。
為定型、驗證和測試資料指派其各自的值。
IDataView trainSet = trainSplit.TrainSet; IDataView validationSet = validationTestSplit.TrainSet; IDataView testSet = validationTestSplit.TestSet;
定義定型管線
模型定型包含幾個步驟。 首先,會使用影像分類 API 來定型模型。 然後,PredictedLabel 資料行中的編碼標籤會使用 MapKeyToValue 轉換,以轉換回到其原始類別值。
建立新的變數,以儲存 ImageClassificationTrainer 的一組必要和選擇性參數。
var classifierOptions = new ImageClassificationTrainer.Options() { FeatureColumnName = "Image", LabelColumnName = "LabelAsKey", ValidationSet = validationSet, Arch = ImageClassificationTrainer.Architecture.ResnetV2101, MetricsCallback = (metrics) => Console.WriteLine(metrics), TestOnTrainSet = false, ReuseTrainSetBottleneckCachedValues = true, ReuseValidationSetBottleneckCachedValues = true };ImageClassificationTrainer 可接受數個選擇性參數:
FeatureColumnName是做為模型輸入的資料行。LabelColumnName是要所要預測值的資料行。ValidationSet是包含驗證資料的IDataView。Arch會定義要使用的預先定型模型架構。 本教學課程使用 ResNetv2 模型的 101 層變體。MetricsCallback會繫結函式以在定型期間追蹤進度。TestOnTrainSet會告知模型在沒有任何驗證集存在時,針對定型集測量效能。ReuseTrainSetBottleneckCachedValues會告知模型是否要在後續執行中使用瓶頸階段的快取值。 瓶頸階段是一次性的傳遞計算,在第一次執行時會進行密集計算。 如果定型資料沒有變更,且您想要使用不同數目的 Epoch 或批次大小進行實驗,則使用快取的值可大幅減少定型模型所需的時間。ReuseValidationSetBottleneckCachedValues與ReuseTrainSetBottleneckCachedValues類似之處僅在其於本案例中適用於驗證資料集。WorkspacePath會定義目錄,其中儲存計算瓶頸值和模型的.pb版本。
定義包含
mapLabelEstimator和 ImageClassificationTrainer 的EstimatorChain定型管線。var trainingPipeline = mlContext.MulticlassClassification.Trainers.ImageClassification(classifierOptions) .Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));使用
Fit方法來定型模型。ITransformer trainedModel = trainingPipeline.Fit(trainSet);
使用模型
既然您已定型模型,隨即可使用模型來分類影像。
建立名為 OutputPrediction 的新公用程式方法,以在主控台中顯示預測資訊。
private static void OutputPrediction(ModelOutput prediction)
{
string imageName = Path.GetFileName(prediction.ImagePath);
Console.WriteLine($"Image: {imageName} | Actual Value: {prediction.Label} | Predicted Value: {prediction.PredictedLabel}");
}
分類單一影像
建立稱為
ClassifySingleImage的新方法,以製作及輸出單一影像預測。void ClassifySingleImage(MLContext mlContext, IDataView data, ITransformer trainedModel) { }在
ClassifySingleImage方法內PredictionEngine建立。PredictionEngine是一種便利的 API,可讓您傳遞並在單一資料執行個體上接著執行預測。PredictionEngine<ModelInput, ModelOutput> predictionEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(trainedModel);若要存取單一
ModelInput執行個體,請使用CreateEnumerable方法將dataIDataView轉換成IEnumerable,然後取得第一個觀察。ModelInput image = mlContext.Data.CreateEnumerable<ModelInput>(data,reuseRowObject:true).First();使用
Predict方法來分類影像。ModelOutput prediction = predictionEngine.Predict(image);使用
OutputPrediction方法,將預測輸出至主控台。Console.WriteLine("Classifying single image"); OutputPrediction(prediction);呼叫下列
ClassifySingleImage,以使用影像的測試集來呼叫Fit方法。ClassifySingleImage(mlContext, testSet, trainedModel);
分類多個影像
在
ClassifySingleImage方法下方新增名為ClassifyImages的新方法,以進行及輸出多個影像預測。void ClassifyImages(MLContext mlContext, IDataView data, ITransformer trainedModel) { }使用
Transform方法建立包含預測的IDataView。 將下列程式碼新增至ClassifyImages方法內。IDataView predictionData = trainedModel.Transform(data);若要逐一查看預測,請使用
CreateEnumerable方法將predictionDataIDataView轉換成IEnumerable,然後取前 10 個觀察。IEnumerable<ModelOutput> predictions = mlContext.Data.CreateEnumerable<ModelOutput>(predictionData, reuseRowObject: true).Take(10);逐一查看並輸出預測的原始和預測標籤。
Console.WriteLine("Classifying multiple images"); foreach (var prediction in predictions) { OutputPrediction(prediction); }最後,呼叫下列
ClassifyImages,以使用影像的測試集來呼叫ClassifySingleImage()方法。ClassifyImages(mlContext, testSet, trainedModel);
執行應用程式
執行主控台應用程式。 輸出應該類似如下所示。 您可能會看到警告或處理中訊息,但為了讓結果變得清楚,這些訊息已從下列結果中移除。 為求版面簡潔,輸出內容已經過壓縮。
瓶頸階段
不會列印任何影像名稱的值,因為影像會載入為 byte[],因此不會顯示任何影像名稱。
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 279
Phase: Bottleneck Computation, Dataset used: Train, Image Index: 280
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 1
Phase: Bottleneck Computation, Dataset used: Validation, Image Index: 2
定型階段
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 21, Accuracy: 0.6797619
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 22, Accuracy: 0.7642857
Phase: Training, Dataset used: Validation, Batch Processed Count: 6, Epoch: 23, Accuracy: 0.7916667
分類影像輸出
Classifying single image
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Classifying multiple images
Image: 7001-220.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-163.jpg | Actual Value: UD | Predicted Value: UD
Image: 7001-210.jpg | Actual Value: UD | Predicted Value: UD
在檢查「7001-220.jpg」影像時,您可以看到其實際上並未破解。

恭喜! 您現在已成功建置分類影像的深度學習模型。
改進模型
如果您不滿意模型的結果,可以嘗試下列一些方法,試著改善其效能:
- 更多資料:模型從中學習的範例越多,效能也就越好。 下載完整的 SDNET2018 dataset,並用其來定型。
- 增強資料:新增各種資料的常見技巧,是擷取影像並套用不同的轉換 (旋轉、翻轉、移位、裁剪) 來增強資料。 這會為模型新增更多不同的範例,以供您從中學習。
- 定型較長時間:您定型的時間越長,模型就會進行更多微調。 增加 Epoch 數目可能會改善模型的效能。
- 使用超參數進行實驗:除了本教學課程中使用的參數之外,還可以微調其他參數,以可能改善效能。 變更學習速率,以決定每個 Epoch 之後對模型所做的更新程度可能會改善效能。
- 使用不同的模型架構:視您的資料外觀而定,最能了解其特徵的模型可能會有所不同。 如果您不滿意您模型的效能,請嘗試變更架構。
下一步
在本教學課程中,您已瞭解如何使用傳輸學習、預先定型的影像分類 TensorFlow 模型和 ML.NET 影像分類 API 來建置自訂深度學習模型,將具體表面的影像分類為已破解或未分割。
前進到下一個教學課程來深入了解。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應