災害復原服務
雖然復原備份資料是備份服務的標準功能, 但災害情況並非僅限於資料遺失。 組織的伺服器若發生中斷而無法使用 (無論是發生在內部部署或雲端、虛擬或者實體),都有可能對組織造成負面甚至極為嚴重的影響。 災害復原 (DR) 服務的目的不僅僅是針對資料與個人資源,而是為整個系統提供備份,以便在這些系統停止運作或離線時,透過將流量重新導向至已準備好承擔負載的複本,以此恢復服務。
災害復原是一項能夠讓公用雲端真正起到作用的服務, 其帶來的效益遠超過一部龐大的磁帶機。 因為雲端資源是虛擬的,所以複本能夠在收到通知後便立即開始作業,以取代突然消失的資源。 除了本身的鏡像系統之外,複本甚至可以裝載於世界各地,以避免區域規模的中斷。 若與在實體資訊系統中維護實體複本 (且嘗試在不同地區實現這些維護) 所產生費用相比較,就更能夠體現在雲端中維護這些系統並使其持續運作的價值。
主要的雲端提供者提供災害復原即服務 (DRaaS),但這些服務必須經過詳細規劃和設定,才能提供客戶所需的容錯移轉支援。 因此,我們首先著重於影響這類規劃的目標與計量。
目標與計量
在災害事件期間,組織與其客戶可能會同時無法存取多個類別的數位資產,而其中最重要的資產為:
資料庫與資料存放區,除了記錄關於客戶與庫存貨物及/或服務的重要資訊之外,也負責為整個組織維護商務交易與流程的活躍狀態
大量資料,包含文件、媒體檔案,以及人們所使用應用程式產品的其他儲存記錄
通訊與連線能力,與人員和商務服務取得聯繫,從而構成任何潛在商務活動的重要部分
應用程式,代表面向客戶、贊助人以及組織利害關係人的組織店面
雖然災害復原是以單一服務的形式呈現給客戶,但上述各類別的復原程序皆各不相同且獨立。 在用戶端/伺服器的年代,許多組織會在個人電腦上處理日常業務。 如果電腦停止運作,且備份映像位於電腦的本機存放區,理論上可以將其復原到新的電腦上,使工作得以繼續。 在第一部透過 LAN 作業系統與乙太網路纜線連線至網路的電腦誕生後,人們便可以從備份映像還原連線至網路的每一部電腦,且恢復網路本身。
雲端並非以這種方式運作。 即使是作為組織應用程式伺服器的虛擬機器,也不會完全封裝其工作的所有部分。 備份服務可為大量資料,並在一定程度上為交易資料與資料庫提供安全網路。 然而,這些實體亦是構成其本身的元件,若要在災害期間還原業務機能,則需要從安全可靠位置重新建立每個元件的大部分 (若非全部) 功能。
因此,災害修復必須協調過程中所採取的每個程序,讓組織能夠再度正常運作。 此外,由於災害發生的關係,在此期間所進行的業務種類變得更加重要。 會導致重要基礎結構癱瘓的事件,亦可能會對公司在其他層面的運作帶來損害:倉儲、貨運、製造以及交貨。 尚在恢復中業務可能無法順暢地復原至災害事件發生之前的業務狀態。
常見且清楚定義的服務等級目標可將這些程序全部整合在一起。 AWS 與 Azure 的災害復原服務,以及建立於 Google Cloud 上的第三方服務,都能辨識下列各項目:
復原點目標 (RPO) - 為提供服務而回傳給用戶端所需的最小允許資料量,該資料量則根據要視為已復原的備份資產而定。 相反地,此資料量亦可代表可接受的最大資料遺失,將 100 減去該資料量的百分比即可得之。
復原時間目標 (RTO) - 允許還原程序進行的最大時間範圍,其亦可代表組織願意承受的停機時間量值。
保留期間 - 在需要重新整理和取代備份組之前,所允許保留的最長時間。
RTO 與 RPO 可視為相互平衡的選項,客戶可藉此決定是否要允許較長的復原時間來達到較高的復原點。 如果由於可用頻寬或停機風險,使客戶無法顧及恢復時間,則客戶可能無法達到較高的 RPO。
專業的風險建議程式或商務持續性建議程式可能會堅持使用這三個變數來建立災害復原原則。 在大部分的業務衝擊分析 (BIA) 報告中,RTO 與 RPO 的重要性皆名列前茅。 這些變數對於建議程式在評估因災害事件而產生的潛在損失時非常重要。 某些建議程式會使用稱為「服務等級目標」(SLO) 的彙總變數,然而目前尚無法透過任何單一公式取得 SLO。 CSP 能夠使用風險建議程式已經辨識和理解的術語來指定其服務等級,讓兩者能夠更輕鬆地合作,這通常是組織最終選擇災害復原提供者的方式。
方法和程序
在上一單元中提及了最基本的資訊系統復原形式,包括相關檔案、存放磁碟區,以及虛擬機器映像的備份。 雖然災害復原會持續提供這類服務選項,但實際上,適用於該選項的組織越來越少,主要原因為無法適當地維護 RTO 目標。
專業的災害復原服務可提供各種部署和管理方法,其中有些方法則需要在災害事件發生之前進行服務維護。 以下會摘要說明這些方法。 這三種方法都是前一個課程中所討論的各種備份選項為基礎,並同樣適用於所有服務提供者。 若客戶想要啟用其中一種復原模式,可選擇最適合該模式的複寫、地理位置和儲存類別。
指示燈
使用此方法 (圖 5),可提供完全待命資料中心所用的空間。 在這裡,部分核心服務和應用程式 (以及提供支援的資料),會保留在容錯移轉叢集中,並在發生災害事件時立即 (通常為自動)「亮起」。 同時,虛擬伺服器只會以能夠維持其運作的最基本功能進行部署,以便能夠回應呼叫。 這些停用的伺服器可能具備電子郵件和 Web 功能,可供與客戶及組織內的人員通訊。 啟用指示燈復原模式可能需要持續同步處理動態資料存放區,例如交易式資料庫和電子郵件磁碟區。
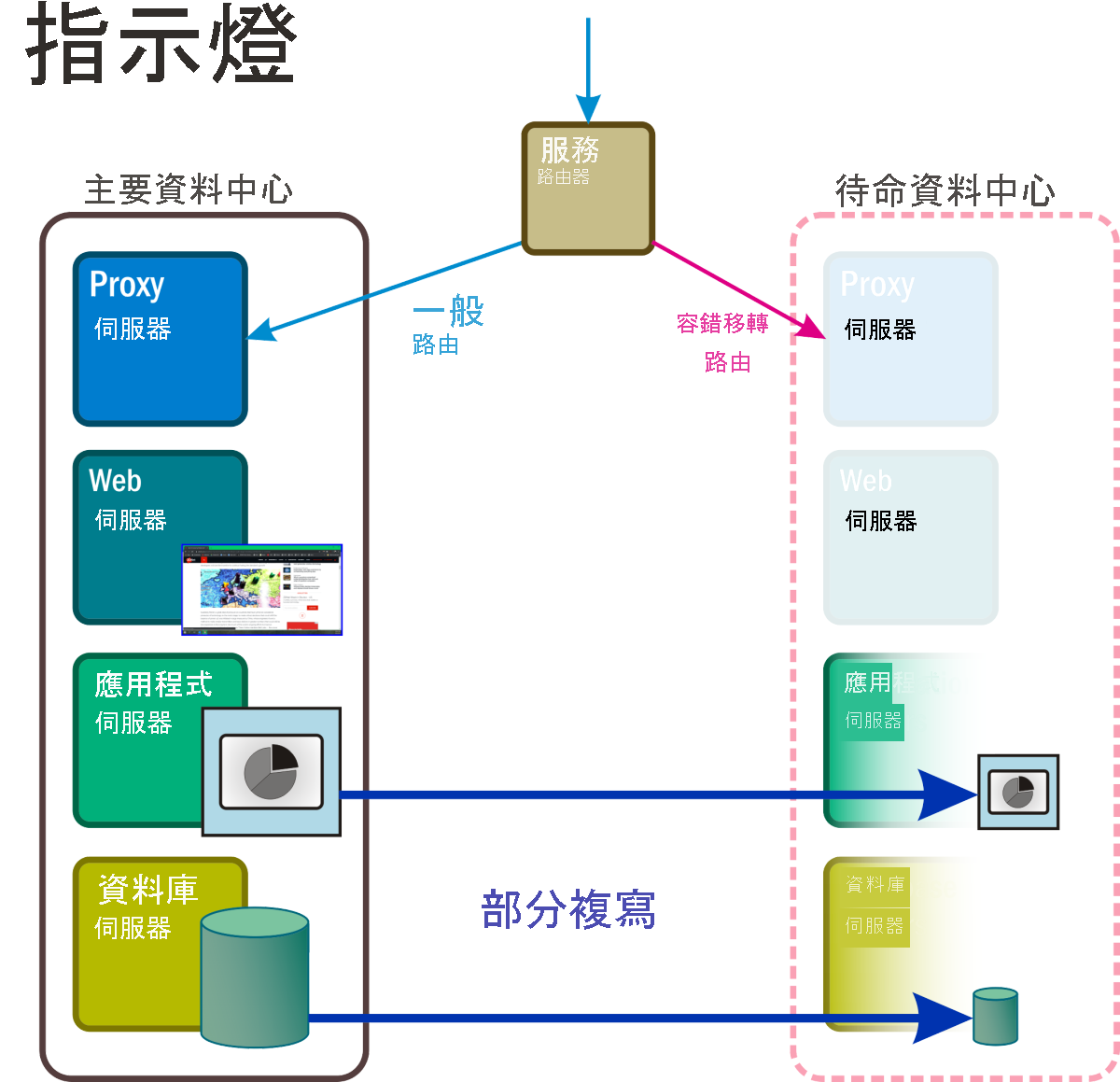
圖 5:指示燈修復案例的主動與被動元件。
暖待命
在此復原模式中 (如圖 6 所示),會持續執行所有系統服務和應用程式的複本,且所有重要商務資料都會保留在至少一個不同的地理位置中。 使用中路由器會略過此完整複本的存取權,直到災害事件觸發規則,其會將作用中網路的位址取代為略過路由上的位址。
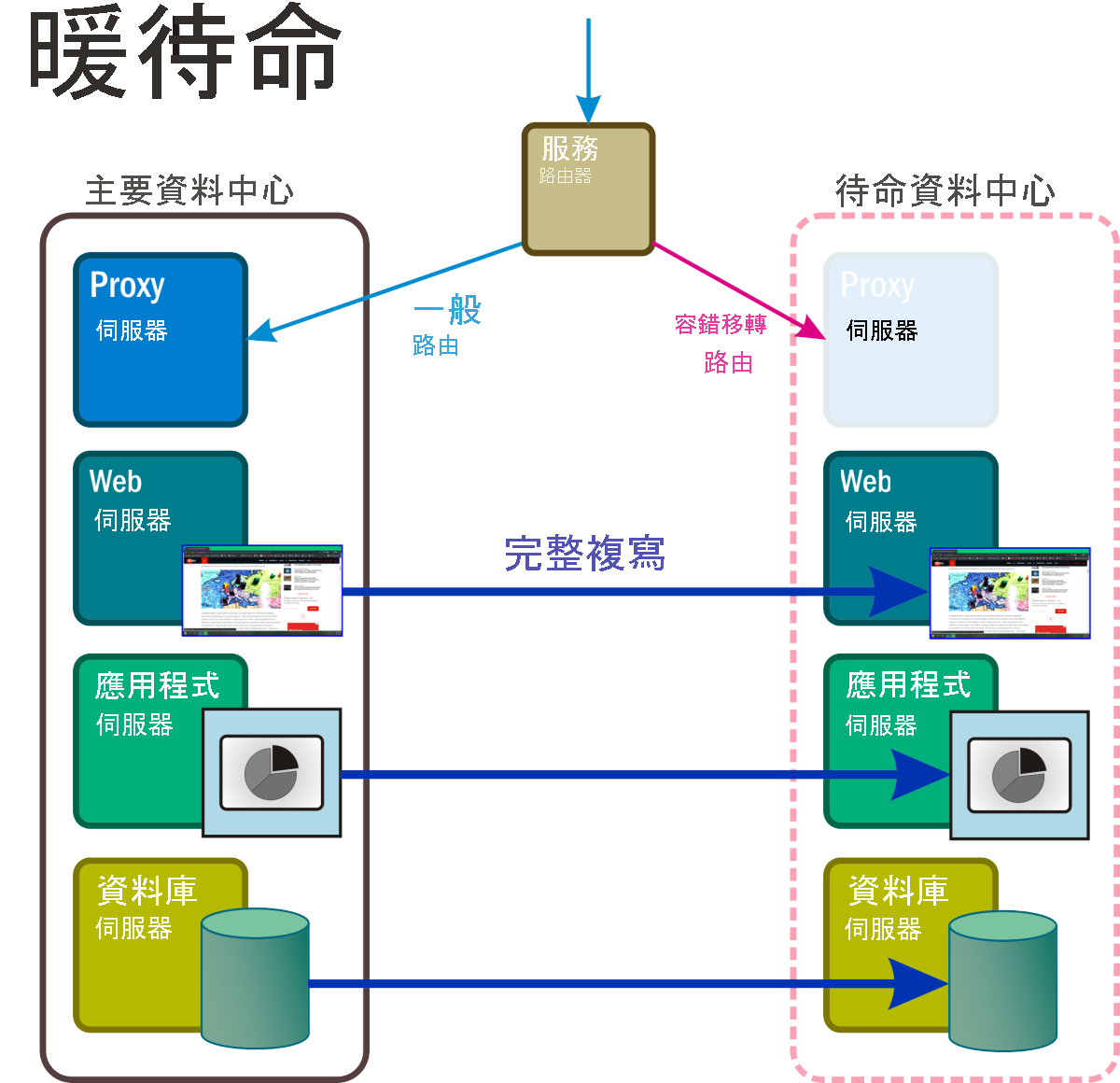
圖 6:暖待命復原案例,其中待命命名空間中的部分元件可完全正常運作。
熱待命
在此案例中 (圖 7),至少會持續執行兩個所有服務和應用程式的完整複本,且在複本之間會有完整且持續的資料同步處理。 主要路由器可作為一種主要負載平衡器,將要求以大約等比例散發至所有伺服器位置。 發生災害事件時會觸發類似防火牆的程序,並會從路由表中移除受影響的系統位址。
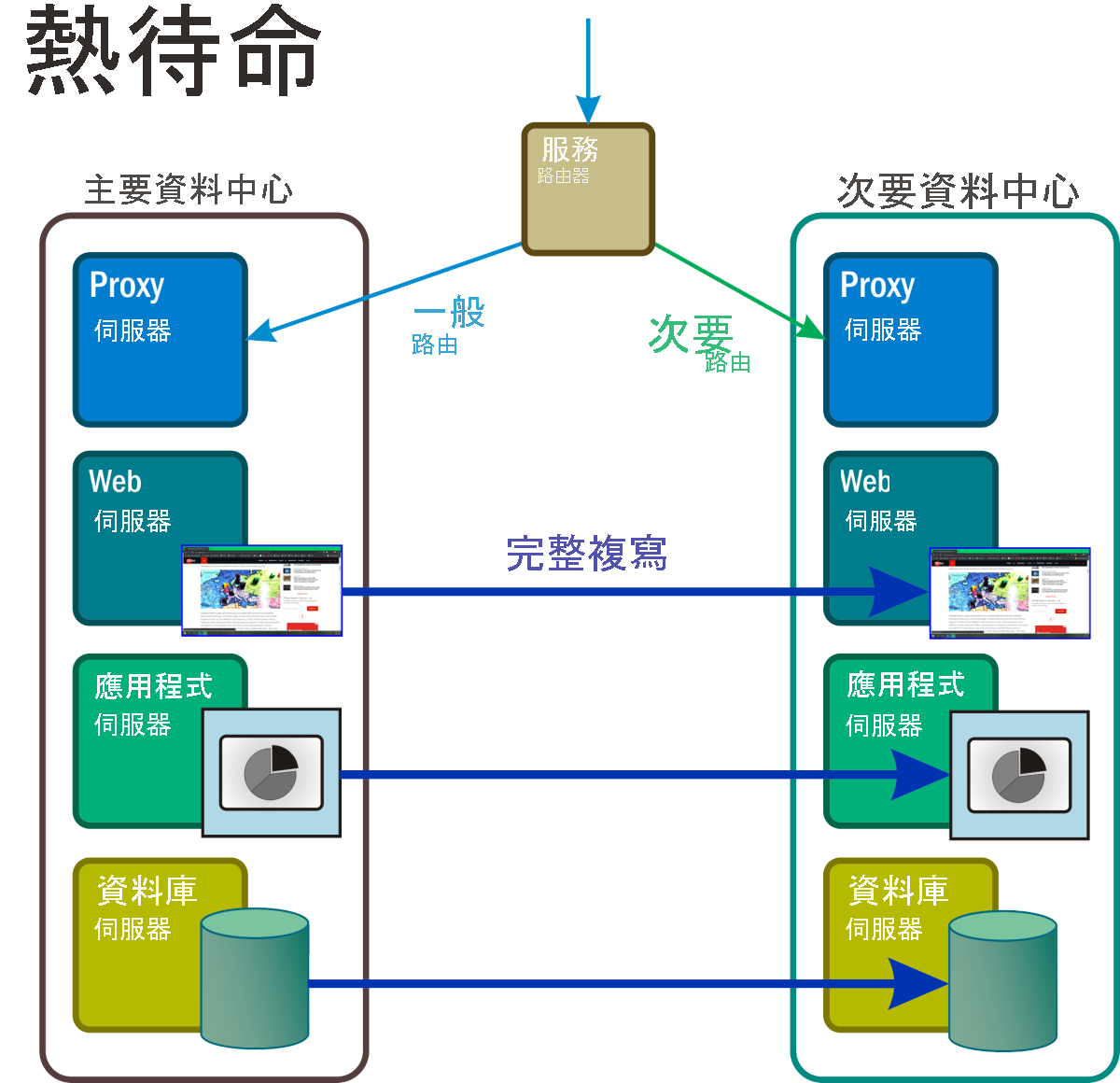
圖 7:使用熱待命時,命名空間中的所有元件 (通常為保留或待命空間) 皆為作用中、可完全正常運作,且會即時處理主要資料的複本。
雲端原生應用程式
理論上,組織可能會選擇一項提供者的災害復原服務,作為另一提供者所裝載服務的安全網路。 換句話說,如果 IT 人員給予適當的關注,則一個 CSP 的基礎結構 (例如 Google) 即可作為裝載於另一個 CSP 基礎結構 (例如 Azure) 的容錯移轉目的地,以供暖待命程序使用。 這類形式可能基於會計工作,或者,如果在企業內的計算資源是由位於世界各地的不同部門所管理而變得必要。
目前,內部部署資料中心以及雲端中的容器化基礎結構,對於這些災害復原方法的影響有顯著的影響。 所謂的「雲端原生應用程式」,是專門為在公用雲端平台,或是在以類似方式運作的平台 (例如,Microsoft Azure Stack) 上使用而開發,可將功能散發在多個複本容器中,且同時運作部分或全部功能。 其原因並非為了讓新類別的災害復原案例能夠在處理器之間散發工作負載。
雲端原生架構的另一個層面即為,可通過網絡位址與已自動複寫內容的資料庫聯繫 (該網路位址的地圖專用於當前應用程式)。 (換句話說,雖然使用網際網路通訊協定,但其位址並不在更廣泛的公用網際網路位置上。) 如此一來,在發生災害事件期間,連結至資料庫的部分節點可能會關閉 (大部分節點會保存),而其他節點則會取代無法使用的節點。 這也許仍不足以稱為內建災害復原,但也可以將其描述為災害抵禦手段。
災害復原即服務 (DRaaS)
對於公用雲端服務提供者,災害復原是一種使用其核心備份與資料傳輸服務的方法。 每個主要 CSP 都會執行不同策略,以協助其備份服務上的災害復原。
AWS CloudEndure
「服務移轉」指的是將虛擬工作負載從私人內部部署基礎結構重新放置到公用雲端基礎結構。 對於部分在公用雲端中執行的災害復原服務而言,必須執行重新放置,以便在災害事件發生後的幾分鐘內完成容錯移轉和復原等任務目標。
Amazon 於 2019 年 1 月取得私人的服務移轉服務 CloudEndure,該服務當時已使用 AWS 作為其基礎結構提供者。 自那時起,該服務已將 CloudEndure 整合至其主要服務內容中,以提供 Amazon 客戶免費的服務移轉。 現在,AWS 則將服務移轉作為快速啟用暖待命或熱待命程序的方法。 AWS 不會向客戶收取移轉程序的費用,而是針對每個災害復原案例所佈建的備援資源收費。 儘管如此,由於不需要額外的費用,CloudEndure 得以立即與近乎飽和的第三方災害復原服務競爭。
Azure Site Recovery
Microsoft 的災害復原服務,即 Azure Site Recovery,是暖待命復原方法的受控部署,適用於以 VM 為基礎的環境以及執行 Linux 或 Windows 的實體 (內部部署) 伺服器。 VM 會主動複寫到次要區域 (圖 9.8),只要在該區域中按一下按鈕,就可以開始執行容錯移轉。 客戶需按月支付由 Azure Site Recovery 所保護的每部伺服器或 VM (目前費用約為 25 美金)。
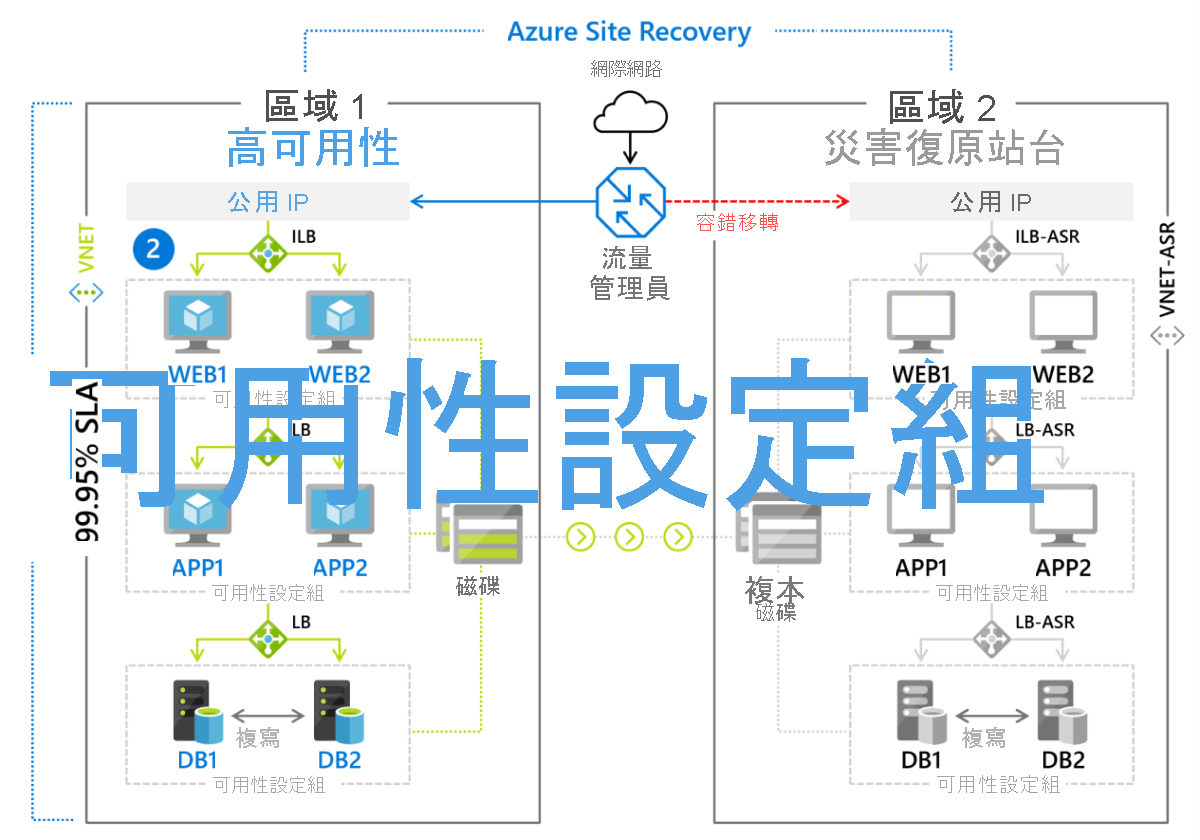
圖 8:使用 Azure Site Recovery 所執行的容錯移轉案例。
Google 雲端災害復原
如同備份,Google 並未針對災害復原特別提供品牌服務。 相反地,Google 提供資料儲存和資料傳輸所需的工具與資源,並為客戶提供指引,以了解如何在各種災害復原案例中取得最大協助。
由於 Google 提供 Coldline 儲存體選項與其折扣,使 GCP 得以用於各種不同的案例。 對於維護大量資料的組織而言,Coldline 是一項非常具有吸引力的選項。 在媒體檔案以平均大小數十 GB 為單位的情況下,旋轉磁碟就顯得相當不切實際。 網路連接儲存裝置 (NAS) 元件可為建立組織的媒體提供可存取性與管理性解決方案,但只能在區域範圍內使用。 這些元件具有內部備援,但不能作為災害抵禦手段。 而任何類似於先前三個圖表中所提及的災害復原案例,並不適用於這類客戶 (或者費用高昂)。 Coldline 能夠為這類客戶提供至少一種可行的方法,在名義上達成商務持續性保證的水準。