設計和原則的復原
最常與「災害復原」一起出現的字詞就是「商務持續性」,「持續性」有正面含意。 這個字詞的含意是,將災害事件的範圍或範圍更小的任何事件限制在資料中心的牆內。
雖然試圖將「持續性」做為工程字詞使用,但它實際上並不屬於工程字詞。 商務持續性沒有一公式、方法或配方。 對任何組織而言,他們都可能會有一組獨特的最佳做法,並與其從事的業務類型和方式相關。 持續性是這些最佳做法的成功應用,以獲得正面成果。
復原能力的意義
工程師了解「復原」的概念。 當系統在不同情況下都執行良好時,就表示具有復原性。 當企業已實作保全機制、安全性措施和災害程序,準備好回應可能面臨的任何不良影響時,風險管理員即認為該企業已做好充分的準備。 工程師可能無法以「正常」和「受威脅」、「安全」和「災害」這類非黑即白的字詞來感知系統運作所在環境。當支援企業的系統在面臨不利情況下提供持續且可預測的服務等級時,此人便會意識到該系統處於正確的執行順序。
在 2011 年,隨著雲端運算在資料中心呈現上升趨勢,歐盟網路與資訊安全局 (ENISA,一個歐盟單位) 發表了一份報告,以回應歐盟政府的要求,提供對資訊收集系統復原能力的深入解析。 這份報告直接指出,在其 ICT 員工 (在歐洲,"ICT" 是指 "IT",其中包括通訊) 之間尚未就「復原」的實際含義及其測量方式達成任何共識。
這使得 ENISA 發現到一個由堪薩斯大學 (KU) 研究小組所發起的專案,該小組的組長為 James P. G. Sterbenz 教授,其目的是要部署在美國國防部。 該專案稱為復原性和可存活的網路方案 (ResiliNets)1,這是一種方法,可將資訊系統中復原在各種情況下的變動狀態視覺化。 ResiliNets 是組織中復原原則的共識模型原型。
KU 模型利用許多熟悉且易於說明的計量,有部分已在本章中介紹過。 其中包含:
容錯 - 如先前所述,能夠讓系統在發生故障時保持應有的服務等級
中斷容錯 - 能夠讓同一個系統在面臨無法預期且通常是極端 (但不是由系統本身所造成) 的運作情況下 (例如,電力中斷、網際網路頻寬不足和流量激增),保持應有的服務等級
生存能力 - 在所有可能的情況下 (包括自然災害),對系統能夠提供合理 (如果不一定是名義上) 服務效能層級的預估
ResiliNets 提出的主要理論是,透過系統工程和人力工作的組合,讓資訊系統在量化方面更具有復原性。 人們所做的事會使系統變得更加強大,更重要的是,人們在日常實務中會「繼續」做的事。
KU 小組從現役戰區的士兵、水手和陸戰隊如何學習並記住戰術部署原則中獲得啟示,並提議了一種餐巾纸背面記憶法,用來記住 ResiliNets 實務的生命週期:D2R2 + DR。 如圖 9 所示,此處的變數會按以下順序表示:**
保護系統免於遭受對其正常運作的威脅
在可能的錯誤和外部情況下,偵測不利影響的發生
補救 (Remediate) 這些效果可能會對系統造成的後續影響,即使該影響尚未持續存在也一樣
復原為一般服務等級
診斷事件的根本原因
視需要調整 (Refine) 未來行為,以便更好地為再次發生的狀況做好準備
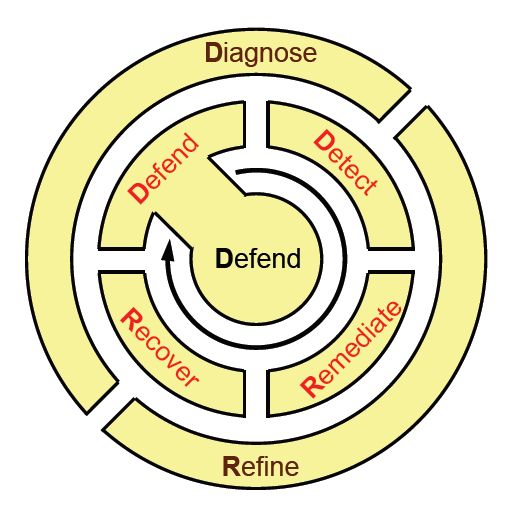
圖 9:在利用 ResiliNets 環境中最佳做法活動的生命週期。
在每個階段中,都會取得人員和系統的特定效能和運作計量。 這些計量組合所產生的點可以使用歐幾里德幾何平面進行繪製,如圖 9.10 所示。 每個計量都可以縮減為兩個一維值:一個反映服務等級參數「P」,另一個則代表運作狀態「N」。由於均已實作並重複執行 ResiliNets 週期中的所有六個階段,因此會在圖表的座標 (N, P) 上繪製服務狀態「S」。
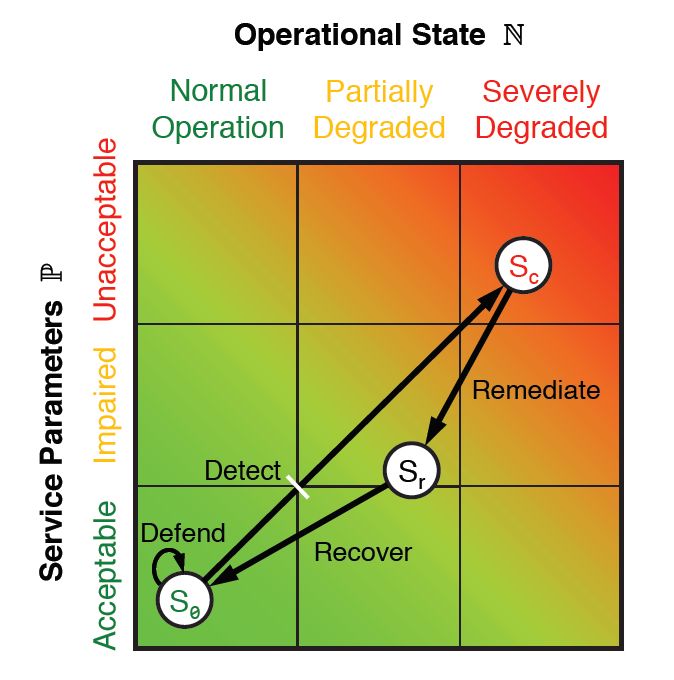
圖 10:ResiliNets 狀態空間和策略內部迴圈。
符合服務目標的組織會將其「S」狀態緊密地暫留在圖形的左下角,並有望在所謂的「內部迴圈」期間保持在該位置或該位置的附近。 當服務目標降級時,狀態會沿著不必要的向量朝右上方移動。
雖然 ResiliNets 模型尚未成為 IT 復原在企業中的普遍描述,但某些著名的組織 (特別是在公共部門中) 已採用該模型,觸發了一些推動雲端革命的變化:
效能視覺效果。 復原能力不一定是一種將其目前狀態傳達給相關利害關係人的原理。 事實上,復原能力可以用少於一個單字來表示。 納入雲端計量的新型效能管理平台結合了儀表板和類似的工具,使這些平台的案例變得更有效率。
復原措施和程序無需等到災害發生才執行。 縝密且精心設計的資訊系統 (有保持警惕的工程師和操作員隨時待命) 將會每天實作維護程序,這與危機期間的補救程序幾乎沒有任何差異。 例如,在熱待命的災害復原環境中,補救服務等級的問題實際上可能會變成自動,也就是主要路由器只是讓流量遠離受影響的元件。 換句話說,針對失敗做準備不一定等於等待失敗發生。
資訊系統是由人員所組成。 自動化可讓人們的工作更有效率,並讓他們產品的生產更有效率。 但若系統的設計旨在因應無法預期的狀況及環境變化,自動化功能便不能取代系統中的人員。
復原導向運算
ResiliNets 是 Microsoft 在進入新世紀不久後協助創造的一種概念實作,稱為「復原導向運算」(ROC)。2 其主要準則為錯誤和 Bug 是運算環境常年存在的事實。 與其花費太多時間對此環境進行消毒,不如讓組織採用有助環境預防接種的常識性措施,似乎更有助益。 這種運算相當於 20 世紀初之前提出的基本概念,即人們一天應該洗手數次。
公用雲端的復原能力
公用雲端服務提供者全都遵守復原能力的準則和架構,即使他們選擇以另一個名稱來稱呼此功能。 不過,除非雲端平台將組織的資訊資產吸納到整個雲端,否則該平台不會將復原能力新增至組織的資料中心。 混合式雲端實作的復原性只與其最不用心的系統管理員相同。 如果我們可以假設 CSP 系統管理員會努力遵守復原能力的規範 (否則會違反其 SLA 的條款),則維護完整系統復原能力就必須一律成為客戶的工作。
Azure 復原架構
「商務持續性策略」的國際標準指引是 ISO 22301。 與其他國際標準組織 (ISO) 架構一樣,該架構會指定最佳做法和作業的指導方針,符合其規範即可讓組織獲得專業認證。
此 ISO 架構實際上不會定義商務持續性,也沒有定義復原能力。 相反,這個架構會定義持續性在組織本身脈絡中有何含義。 其引導式文件寫道:「組織應該根據業務影響分析和風險評定的輸出,識別並選取商務持續性策略。 商務持續性策略應由一或多個解決方案組成。」該文件不會繼續列出那些解決方案可能是或應該是什麼。3
圖 11 是 Microsoft 對 Azure 多階段實作 ISO 22301 合規性的描述。 請注意,其中包含服務等級協定 (SLA) 的運作時間目標。 對於選擇此層級復原能力的客戶,Azure 會複寫其本機可用性區域內的虛擬資料中心,但接著會佈建地理位置相距數百英里的個別複本。 不過,基於法律因素 (尤其是為了遵守歐盟的隱私權法規),此地理位置分開的備援通常僅限於「資料落地界限」,例如北美洲或歐洲。
![Figure 11: Azure Resiliency Framework, which protects active components on multiple levels, in accordance with ISO 22301. [Courtesy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
圖 11:Azure 復原架構,其根據 ISO 22301 來保護多個層級的使用中元件。 [圖片由 Microsoft 提供]
雖然 ISO 22301 會與復原能力建立關聯,且通常會描述為一組復原方針,但已測試過 Azure 的復原能力層級僅適用於 Azure 平台,而不適用於該平台上託管的客戶資產。 客戶仍需負責管理、維護和經常改善其處理序,包括其資產在 Azure 雲端和其他地方的複寫方式。
Google Container Engine
直到最近,軟體才被視為是功能與硬體相同,不過是以數位形式存在的電腦狀態。 在這種角度來看,軟體被視為是資訊系統中相對靜態的元件。 安全性通訊協定規定軟體要定期更新,而「定期」通常表示隨著更新和 Bug 修正而每年推出幾次幾次。
雲端動態使其變得可行,但許多 IT 工程師沒有預料到的是,軟體能夠以累加方式 (但卻經常) 進化。 「持續整合與持續傳遞」(CI/CD) 是一組新興的準則,其中自動化可供在伺服器和用戶端上經常 (通常是每日) 對軟體分段進行累加式變更。 智慧型手機使用者可透過在應用程式存放區中以每週數次頻率更新的應用程式,定期體驗 CI/CD。 CI/CD 所帶來的每項變更幅度可能都很小,但是能夠毫無困難地快速部署微幅變更的事實,導致產生了非預期但受歡迎的副作用:更具復原能力的資訊系統。
使用 CI/CD 部署模型時,通常會在公用雲端基礎結構上佈建及維護完全備援的伺服器叢集,專門用來測試新產生的軟體元件是否有 Bug,然後在模擬的工作環境中暫存這些元件,以找出潛在錯誤。 如此一來,即可在安全的環境中執行補救處理序,在該環境中,於套用、測試及核准補救措施進行部署之前,都不會直接影響與客戶互動或與使用者互動的服務層級。
Google Container Engine (GKE,其中「K」代表「Kubernetes」) 是 Google Cloud Platform 環境,供客戶部署容器型應用程式和服務,而不是以 VM 型應用程式。 完整的容器化部署可能包括微服務 (「µ-services」)、與工作負載分開並設計成獨立操作的資料庫 (「具狀態的資料集」)、相依的程式碼程式庫,以及應用程式程式碼必須利用容器本身的檔案系統事件時所使用小型作業系統。 圖 9.12 描述採用 Google 實際為其 GKE 客戶所建議樣式的這類部署。
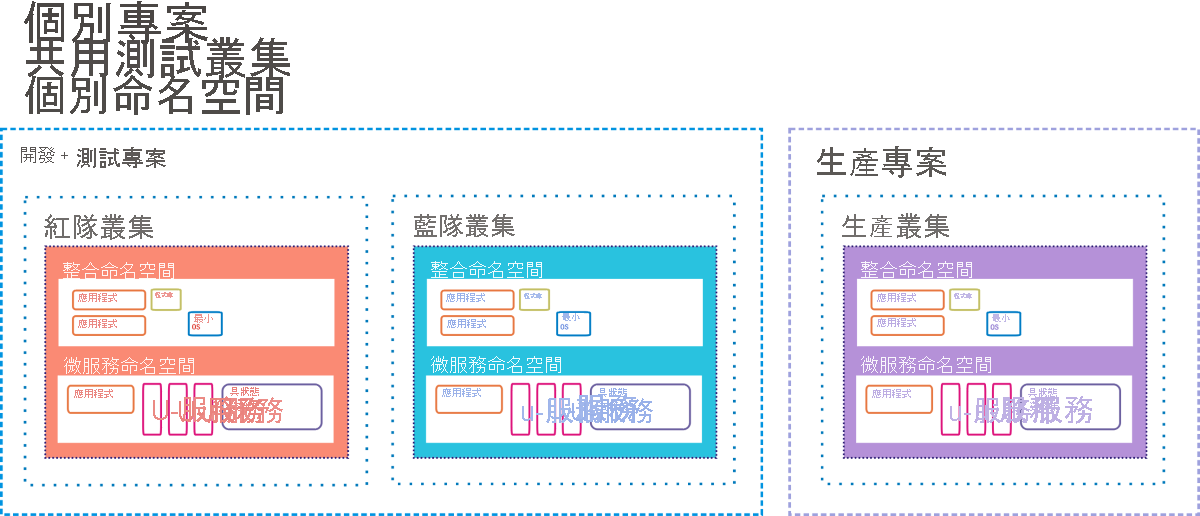
圖 12:作為 Google Container Engine CI/CD 預備環境的熱待命選項。
在 GKE 中,「專案」類似於資料中心,因為專案被視為具有資料中心通常擁有的所有資源 (只是採用虛擬形式)。 可能有一或多個伺服器叢集指派到專案。 容器化元件存在於其本身的「命名空間」中,這些命名空間就像是其原宇宙一樣。 每個命名空間都是由其成員容器允許存取的所有可定址元件所組成,而命名空間外部的任何項目都必須使用遠端 IP 位址來定址。 Google 的工程師建議,舊式用戶端/伺服器應用程式 (容器開發人員稱之為「單體式系統」) 可以與容器化應用程式並存,只要每個類別都利用自己的命名空間來保證安全性,同時共用相同的專案即可。
在此建議的部署圖中,有三個使用中的叢集,每個叢集各有兩個命名空間:一個用於舊軟體,一個用於新軟體。 其中兩個叢集受委派進行測試:一個用於初始開發測試,另一個則用於最終預備環境。 在 CI/CD「管線」中,新的程式碼容器會插入到其中一個測試叢集。 該容器必須通過一系列自動化測試來證明其中沒有 Bug,才能轉移到預備環境。 第二個測試系列會在該處等候新的軟體容器。 只有通過第二層預備環境測試的程式碼,才可以插入到終端客戶所使用的即時生產環境叢集。
不過,即使在該處也設有保全措施。 在 A/B 部署案例中,新程式碼會在指定的時間內與舊程式碼共存。 如果新程式碼無法依規格執行,或將錯誤引入系統中,則可以將其撤銷,並留下舊程式碼。 如果假釋期滿,而新程式碼執行狀況良好,則會撤銷舊程式碼。
這是一種有系統的半自動化流程,可讓資訊系統避免引入會導致失敗的錯誤。 不過,除非生產環境叢集本身是以熱待命模式進行複寫,否則該叢集本身並不是一種防範災害的設定。 當然,這種複寫配置會耗用許多雲端式資源。 不過,涉及的成本可能還是遠低於組織因系統中斷導致未受保護而產生的費用。
參考資料
Sterbenz, James P.G. 等人「ResiliNets: Multilevel Resilient and Survivable Networking Initiative」(ResiliNets:多層級復原性和可存活的網路方案)https://resilinets.org/main_page.html。
Patterson、David 等人「Recovery Oriented Computing: Motivation, Definition, Principles, and Examples」(復原導向運算:動機、定義、準則和範例)。Microsoft Research,2002 年 3 月。 https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO。 「Security and resilience - Business continuity management systems - Requirements」(安全性和復原能力 - 商務持續性管理系統 - 需求)https://dri.ca/docs/ISO_DIS_22301_(E).pdf。