使用文字轉換語音 API
類似於 Azure AI 語音服務的 語音轉換文字 API,Azure AI 語音提供其他 REST API 以用於語音合成:
- 文字轉換語音 API,此為執行語音合成的主要方式。
- Batch 合成 API,目的在支援將大量文字轉換成音訊的批次作業,例如,從來源文字產生有聲書。
您可以在 Azure 文字轉換語音 REST API 文件 中深入了解 REST API。 實際上,大部分支援語音功能的互動式應用程式都是透過 (程式設計) 語言專用的 SDK 使用 Azure AI 語音服務。
使用 Azure AI 語音 SDK
如同語音辨識,實際上,大部分支援語音功能的互動式應用程式都是使用 Azure AI 語音 SDK 建立而成。
實作語音合成的模式類似於語音辨識:
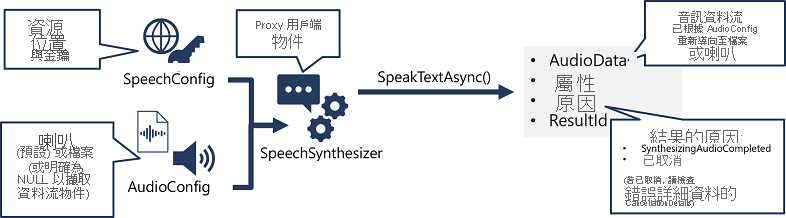
- 使用 SpeechConfig 物件,封裝連線至您的 Azure AI 語音資源所需的資訊。 具體而言,該資源的 [位置] 和 [金鑰]。
- 您也可以選擇使用 AudioConfig 定義輸出裝置,以利進行語音合成。 根據預設,這是預設的系統說話者,但您也可以指定音訊檔案,或明確地將此值設為 null 值;您可以處理直接傳回的音訊串流物件。
- 使用 SpeechConfig 和 AudioConfig 建立 SpeechSynthesize 物件。 此物件是文字轉換語音 API 的 Proxy 用戶端。
- 使用 SpeechSynthesizer 物件的方法呼叫基礎 API 函式。 例如,SpeakTextAsync() 方法會使用 Azure AI 語音服務將文字轉換成說話音訊。
- 處理來自 Azure AI 語音服務的回應。 在 SpeakTextAsync 方法的案例中,結果是 SpeechSynthesisResult 物件,其中包含下列屬性:
- AudioData
- 屬性
- 原因
- ResultId
語音成功合成後,Reason 屬性會設為 SynthesizingAudioCompleted 列舉,而 AudioData 屬性則包含音訊串流 (視 AudioConfig 是否已自動傳送至喇叭或檔案而定)。