多對多關聯性指引
本文以您作為使用 Power BI Desktop 的數據模型工具為目標。 它描述三個不同的多對多模型案例。 它也提供如何在模型中成功設計它們的指引。
注意
本文未涵蓋模型關聯性的簡介。 如果您不熟悉關聯性、其屬性或設定方式,建議您先閱讀 Power BI Desktop 中的模型關聯性一文。
您也必須瞭解星型架構設計。 如需詳細資訊,請參閱了解星型結構描述及其對 Power BI 的重要性。
事實上,有三個多對多案例。 當您需要執行此動作時,可能會發生這些動作:
注意
Power BI 現在原生支援多對多關聯性。 如需詳細資訊,請參閱 在Power BI Desktop中套用多對多關聯性。
建立多對多維度的關聯
讓我們以範例考慮第一個多對多案例類型。 傳統案例涉及兩個實體:銀行客戶和銀行帳戶。 請考慮客戶可以有多個帳戶,而帳戶可以有多個客戶。 當帳戶有多個客戶時,通常稱為 聯合帳戶持有人。
將這些實體模型化是直接的。 一個維度類型數據表會儲存帳戶,另一個維度類型數據表會儲存客戶。 如同維度類型數據表的特性,每個數據表都有一個標識符數據行。 若要建立兩個數據表之間的關聯性模型,則需要第三個數據表。 此數據表通常稱為 橋接數據表。 在此範例中,其目的是要為每個客戶帳戶關聯儲存一個數據列。 有趣的是,當此數據表只包含標識符數據行時,它稱為 「無事實事實數據表」。
以下是三個數據表的簡單模型圖表。
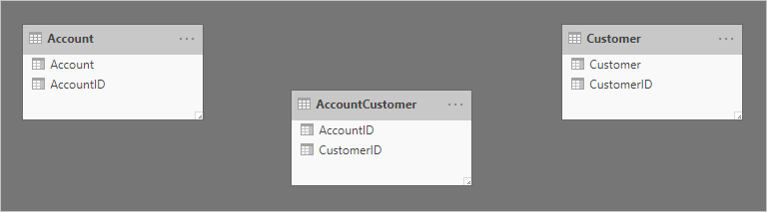
第一個數據表名為 Account,其中包含兩個數據行: AccountID 和 Account。 第二個數據表名為 AccountCustomer,其中包含兩個數據行:AccountID 和 CustomerID。 第三個數據表名為 Customer,其中包含兩個數據行: CustomerID 和 Customer。 任何數據表之間並不存在關聯性。
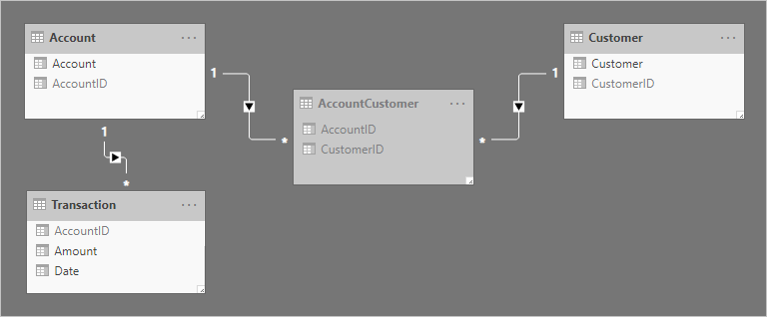
新增兩個一對多關聯性來關聯數據表。 以下是相關數據表的更新模型圖表。 已新增名為 Transaction 的事實類型數據表。 它會記錄帳戶交易。 橋接數據表和所有標識符數據行都已隱藏。
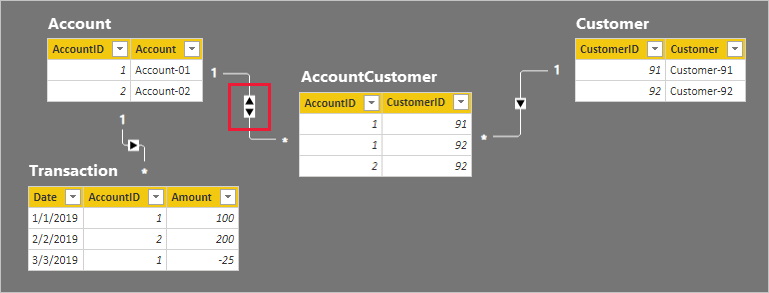
為了協助描述關聯性篩選傳播的運作方式,已修改模型圖表以顯示數據表數據列。
注意
您無法在 Power BI Desktop 模型圖表中顯示資料表資料列。 本文中已完成,可支援具有清楚範例的討論。

四個資料表的數據列詳細資料會在下列點符清單中描述:
- Account 數據表有兩個數據列:
- AccountID 1 適用於 Account-01
- AccountID 2 適用於 Account-02
- Customer 數據表有兩個數據列:
- CustomerID 91 適用於 Customer-91
- CustomerID 92 適用於 Customer-92
- AccountCustomer 數據表有三個數據列:
- AccountID 1 與 CustomerID 91 相關聯
- AccountID 1 與 CustomerID 92 相關聯
- AccountID 2 與 CustomerID 92 相關聯
- Transaction 數據表有三個數據列:
- 日期 2019 年 1 月 1 日, AccountID 1, 金額 100
- 日期 2019 年 2 月 2 日, AccountID 2, 金額 200
- 日期 2019 年 3 月 3 日, AccountID 1, 金額 -25
讓我們看看查詢模型時會發生什麼事。
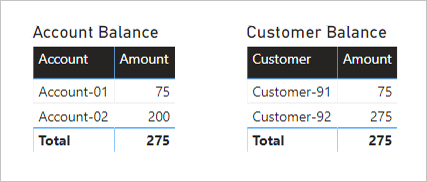
以下是摘要交易數據表中Amount數據行的兩個視覺效果。 依帳戶分組的第一個視覺群組,因此Amount數據行的總和代表帳戶餘額。 依客戶排序的第二個視覺群組,因此Amount數據行的總和代表客戶餘額。

第一個視覺效果標題為 [帳戶餘額],它有兩個數據行: Account 和 Amount。 它會顯示下列結果:
- 帳戶-01 餘額為75
- 帳戶-02 餘額為200
- 總計為 275
第二個視覺效果標題為 [客戶餘額],且有兩個數據行: Customer 和 Amount。 它會顯示下列結果:
- 客戶-91 餘額為275
- 客戶-92 餘額為275
- 總計為 275
快速查看數據表數據列和 帳戶餘額 視覺效果,會顯示每個帳戶和總金額的結果正確無誤。 這是因為每個帳戶群組會導致篩選傳播至該帳戶的交易數據表。
不過,客戶餘額視覺效果看起來不正確。 客戶餘額視覺效果中的每個客戶都有與總餘額相同的餘額。 只有當每位客戶都是每個帳戶的聯合帳戶持有人時,這個結果才能正確。 在此範例中,情況並非如此。 此問題與篩選傳播有關。 它不會一路流向 交易 數據表。
遵循從 Customer 數據表到交易數據表的關聯性篩選指示。 很明顯,Account 與 AccountCustomer 數據表之間的關聯性正以錯誤的方向傳播。 此關聯性的篩選方向必須設定為 [兩者]。
如預期般,帳戶餘額視覺效果沒有任何變更。
不過,客戶 餘額 視覺效果現在會顯示下列結果:
- 客戶-91 餘額為75
- 客戶-92 餘額為275
- 總計為 275
[ 客戶餘額] 視覺效果現在會顯示正確的結果。 請自行遵循篩選指示,並查看客戶餘額的計算方式。 此外,瞭解視覺效果總計表示 所有客戶。
不熟悉模型關聯性的人可能會得出結論,結果不正確。 他們可能會問:為什麼 Customer-91 和 Customer-92 的總餘額不等於 350 (75 + 275)?
他們問題的答案在於理解多對多關係。 每個客戶餘額都可以代表新增多個帳戶餘額,因此客戶餘額不 加總。
建立多對多維度指引的關聯
當您在維度類型數據表之間具有多對多關聯性時,我們提供下列指引:
- 將每個多對多相關實體新增為模型數據表,確保其具有唯一標識碼 (ID) 數據行
- 新增橋接數據表以儲存相關聯的實體
- 建立三個數據表之間的一對多關聯性
- 設定 一個 雙向關聯性,以允許篩選傳播繼續至事實類型數據表
- 當遺漏標識碼值不合適時,請將標識符數據行的Is Nullable 屬性設定為 FALSE -- 如果來源遺漏值,數據重新整理將會失敗
- 隱藏橋接資料表(除非它包含報告所需的其他資料行或量值)
- 隱藏任何不適合報告的識別碼資料列(例如,當識別子為代理索引鍵時)
- 如果讓標識符數據行保持可見,請確定它位於關聯性的「一」投影片上,一律隱藏「多」側欄。 其會產生最佳的篩選效能。
- 若要避免混淆或誤解,請將說明傳達給報表使用者—您可以使用文本框或 可視化標頭工具提示來新增描述
不建議您將多對多維度類型數據表直接關聯。 此設計方法需要設定與多對多基數的關聯性。 在概念上可以達成,但它表示相關數據行將包含重複的值。 不過,維度類型數據表具有標識符數據行,這是公認的設計做法。 維度類型數據表應該一律使用標識符數據行作為關聯性的「一」端。
將多對多事實關聯
第二個多對多案例類型涉及兩個事實類型數據表。 兩個事實類型數據表可以直接相關。 這項設計技術對於快速且簡單的數據探索很有用。 不過,為了清楚起明,我們通常不建議使用這種設計方法。 我們將在本節稍後說明原因。
讓我們考慮一個包含兩個事實類型數據表的範例: 訂單 和 履行。 Order 數據表包含每個訂單行一個數據列,而履行數據表可以包含每個訂單行的零或多個數據列。 Order 數據表中的數據列代表銷售訂單。 [履行] 數據表中的數據列代表已出貨的訂單專案。 多對多關聯性與兩個 OrderID 數據行相關,只有訂單數據表的篩選傳播(訂單篩選履行)。

關聯性基數設定為多對多,以支援在這兩個數據表中儲存重複 的 OrderID 值。 在 Order 資料表中,可能會有重複的 OrderID 值,因為訂單可以有多個行。 在 [履行] 數據表中,可能會有重複的 OrderID 值,因為訂單可能有多行,而且訂單行可以由許多出貨完成。
現在讓我們看看數據表數據列。 在 [履行] 數據表中,請注意,訂單明細可以由多個出貨完成。 (沒有訂單行意味著訂單尚未完成。
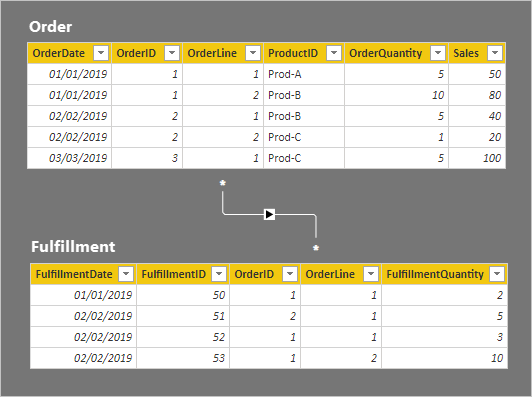
這兩個資料表的數據列詳細資料會在下列點符清單中描述:
- Order 資料表有五個資料列:
- OrderDate January 2019, OrderID 1, OrderLine 1, ProductID Prod-A, OrderQuantity 5, Sales 50
- OrderDate January 2019, OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- OrderDate 2019 年 2 月 2 日、OrderID 2、OrderLine 1、ProductID Prod-B、OrderQuantity 5、Sales 40
- OrderDate 2019 年 2 月 2 日、OrderID 2、OrderLine 2、ProductID Prod-C、OrderQuantity 1、Sales 20
- OrderDate March 2019, OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- 履行資料表有四個資料列:
- 履行日期 2019 年 1 月 1 日、履行標識碼 50、訂單標識碼 1、訂單行 1、履行數量 2
- 履行日期 2019 年 2 月 2 日,履行標識碼 51、訂單標識碼 2、訂單行 1、履行數量 5
- 履行日期 2019 年 2 月 2 日,履行標識碼 52、訂單標識碼 1、訂單行 1、履行數量 3
- 履行日期 2019 年 1 月 1 日、履行標識碼 53、訂單標識碼 1、訂單行 2、履行數量 10
讓我們看看查詢模型時會發生什麼事。 以下是依 [訂單數據表 OrderID] 數據行比較訂單和履行數量的數據表視覺效果。
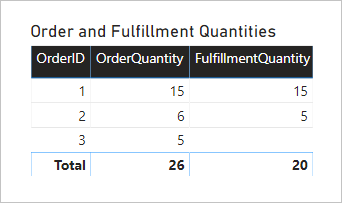
視覺效果會顯示精確的結果。 不過,模型的效用有限,您只能依 Order table OrderID 數據行進行篩選或分組。
建立多對多事實指引的關聯
一般而言,我們不建議使用多對多基數直接關聯兩個事實類型數據表。 主要原因是模型不會以報表視覺效果篩選或群組的方式提供彈性。 在此範例中,視覺效果只能依 Order table OrderID 數據行來篩選或分組。 另一個原因與您的數據質量有關。 如果您的數據有完整性問題,可能會因為關聯性有限而省略某些數據列。 如需詳細資訊,請參閱 Power BI Desktop 中的模型關聯性(關聯性評估)。
建議您採用 星型架構 設計原則,而不是直接關聯事實類型數據表。 您可以藉由新增維度類型資料表來執行此作業。 維度類型數據表接著會使用一對多關聯性來關聯事實類型數據表。 此設計方法很健全,因為它提供彈性的報告選項。 它可讓您使用任何維度類型數據行來篩選或分組,並摘要任何相關的事實類型數據表。
讓我們考慮一個更好的解決方案。
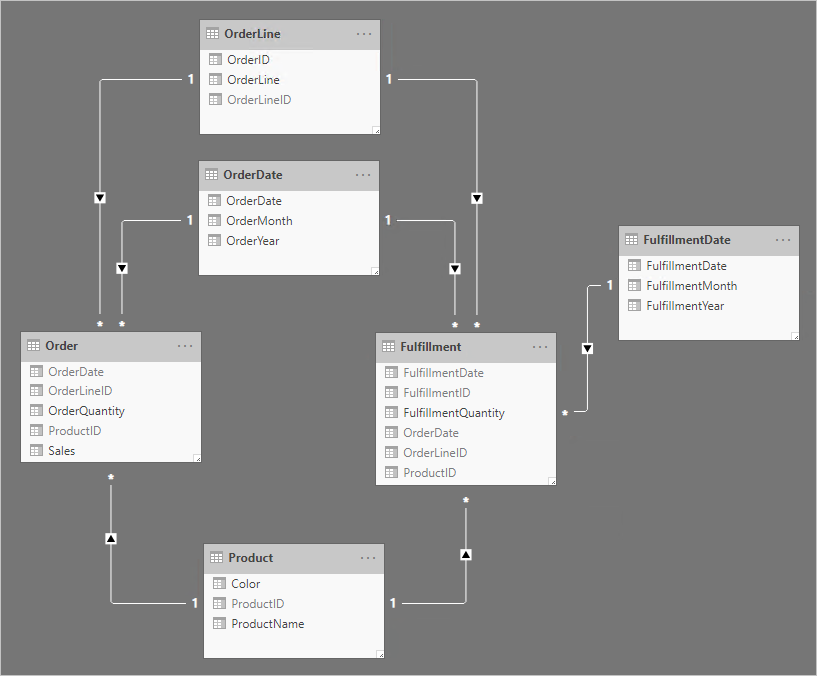
請注意下列設計變更:
- 模型現在有四個額外的數據表: OrderLine、 OrderDate、 Product 和 FulfillmentDate
- 四個額外的數據表都是維度類型數據表,而一對多關聯性會將這些數據表與事實類型數據表建立關聯
- OrderLine 資料表包含 OrderLineID 資料行,代表 OrderID 值乘以 100,加上 OrderLine 值,這是每個訂單行的唯一標識符
- Order 和 Fulfillment 資料表現在包含 OrderLineID 資料行,而且不再包含 OrderID 和 OrderLine 資料行
- 履行數據表現在包含 OrderDate 和 ProductID 數據行
- FulfillmentDate 數據表只與履行數據表相關
- 隱藏所有唯一標識碼數據行
花時間套用星型架構設計原則可提供下列優點:
- 報表視覺效果可以 篩選或分組 維度類型數據表中的任何可見數據行
- 報表視覺效果可以 匯總 事實類型數據表中的任何可見數據行
- 套用至 OrderLine、OrderDate 或 Product 數據表的篩選條件將會傳播至這兩個事實類型數據表
- 所有關聯性都是一對多,而且每個關聯性都是一般 關聯性。 不會遮罩數據完整性問題。 如需詳細資訊,請參閱 Power BI Desktop 中的模型關聯性(關聯性評估)。
建立較高粒紋事實的關聯
此多對多案例與本文所述的其他兩個案例非常不同。
讓我們考慮一個涉及四個數據表的範例: Date、 Sales、 Product 和 Target。 Date 和 Product 是維度類型資料表,而一對多關聯性則與 Sales 事實類型數據表相關。 到目前為止,它代表良好的星型架構設計。 不過,目標數據表尚未與其他數據表相關。
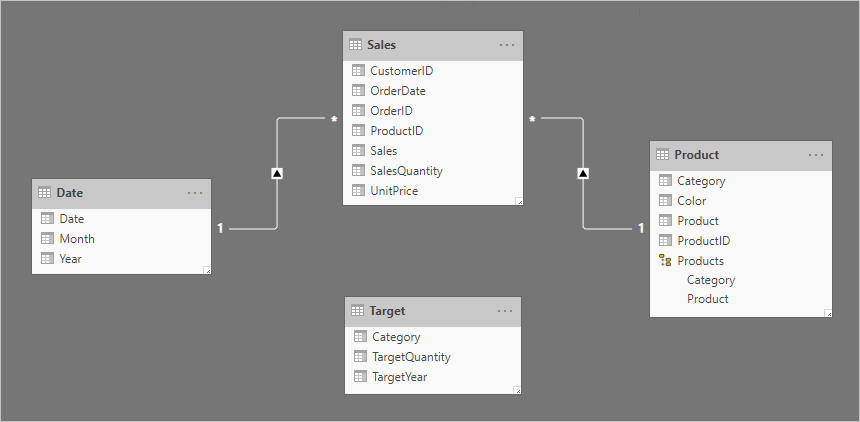
Target 數據表包含三個數據行:Category、TargetQuantity 和 TargetYear。 數據表數據列會顯示年份和產品類別的數據粒度。 換句話說,每個產品類別每年都會設定用來測量銷售績效的目標。
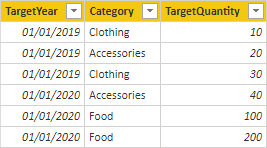
因為 Target 數據表會將數據儲存在高於維度類型數據表的層級,因此無法建立一對多關聯性。 嗯,只有其中一種關係是真的。 讓我們來探索目標數據表如何與維度類型數據表相關。
建立較高粒紋時間週期的關聯
Date 和 Target 數據表之間的關聯性應該是一對多關聯性。 這是因為 TargetYear 資料行值是日期。 在此範例中,每個 TargetYear 數據行值都是目標年份的第一個日期。
提示
將事實儲存在比日期更高的時間粒度時,請將數據行數據類型設定為 Date (或使用日期索引鍵時,神秘 個數位)。 在數據行中,儲存代表時間週期第一天的值。 例如,年份期間會記錄為年份的 1 月 1 日,而月份期間會記錄為該月的第一天。
不過,必須小心,以確保月份或日期層級篩選會產生有意義的結果。 如果沒有任何特殊的計算邏輯,報表視覺效果可能會報告目標日期實際上是每年的第一天。 除了 1 月之外,所有其他天數和所有月份都會將目標數量摘要為空白。
下列矩陣視覺效果顯示報表使用者從一年到月份鑽研時會發生什麼情況。 視覺效果會摘要 TargetQuantity 數據行。 (The 已針對矩陣數據列啟用沒有數據 選項的顯示專案。
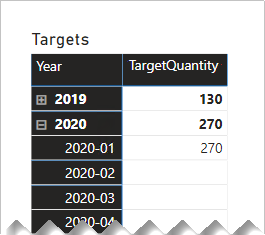
若要避免這種行為,建議您使用量值來控制事實數據的摘要。 控制摘要的其中一個方法是在查詢較低層級的時間週期時傳回BLANK。 另一個以一些複雜的DAX定義的方法是跨較低層級的時間週期分配值。
請考慮使用ISFILTERED DAX 函式的下列量值定義。 它只會在未篩選 Date 或 Month 資料行時傳回值。
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
下列矩陣視覺效果現在使用 Target Quantity 量值。 它會顯示所有每月目標數量都是空白的。
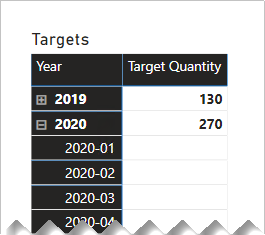
關聯較高的粒紋 (非日期)
將維度類型數據表的非日期數據行關聯至事實類型數據表時,需要不同的設計方法(而且其粒紋高於維度類型數據表)。
Category 資料行(來自 Product 和 Target 數據表)包含重複的值。 因此,一對多關係沒有「一對多」關係。 在此情況下,您必須建立多對多關聯性。 關聯性應該以單一方向傳播篩選,從維度類型數據表傳播到事實類型數據表。
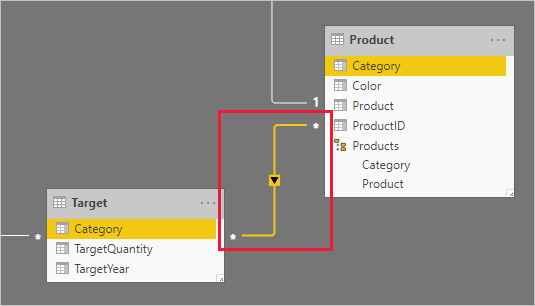
現在讓我們看看數據表數據列。
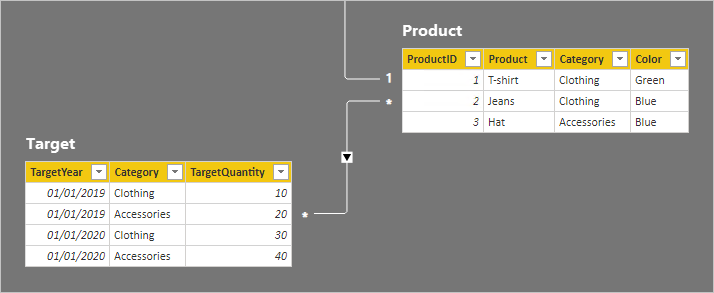
在 [目標] 數據表中,有四個數據列:每個目標年度的兩個數據列(2019 年和 2020 年),以及兩個類別(服裝和配件)。 在 Product 數據表中,有三個產品。 兩個屬於服裝類別,一個屬於配件類別。 其中一種服裝色彩是綠色,其餘兩種是藍色。
Product 資料表中 [類別] 資料行的數據表視覺效果群組會產生下列結果。
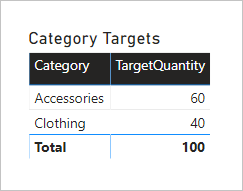
此視覺效果會產生正確的結果。 現在讓我們來考慮當 Product 數據表中的 Color 數據行用來將目標數量分組時會發生什麼事。

視覺效果會產生數據的歪曲。 這裏發生了什麼事?
Product 資料表中 [色彩] 資料行的篩選會產生兩個數據列。 其中一個數據列適用於 [服裝] 類別,另一個則用於 [配件] 類別。 這兩個類別值會以篩選條件的形式傳播至 目標 數據表。 換句話說,因為來自兩個類別 的產品會使用藍色,因此這些類別 會用來篩選目標。
若要避免此行為,如先前所述,建議您使用量值來控制事實數據的摘要。
請考慮下列量值定義。 請注意,類別層級底下的所有 Product 資料表數據行都會測試篩選條件。
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
下表視覺效果現在使用 目標數量 量值。 它會顯示所有色彩目標數量都是空白的。
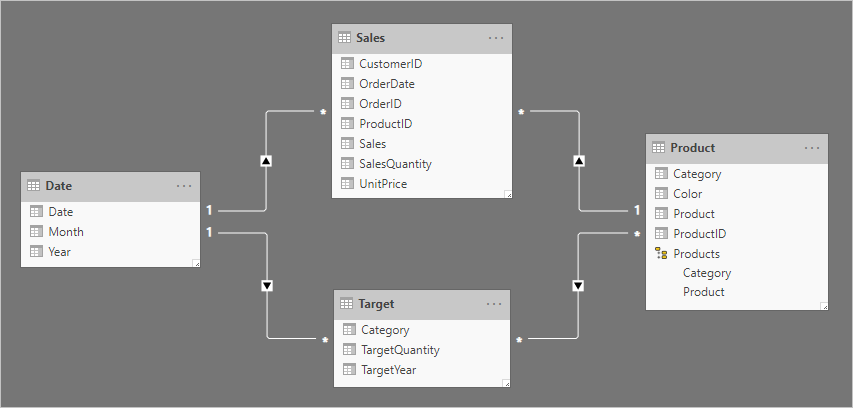
最終的模型設計如下所示。
建立較高粒紋事實指引的關聯
當您需要將維度類型數據表與事實類型數據表產生關聯,而事實類型數據表會將數據列儲存在比維度類型數據表數據列高的數據粒度時,我們提供下列指引:
- 針對更高的粒紋事實日期:
- 在事實類型數據表中,儲存時間週期的第一個日期
- 建立日期數據表與事實類型數據表之間的一對多關聯性
- 對於其他較高的粒紋事實:
- 建立維度類型數據表與事實類型數據表之間的多對多關聯性
- 針對這兩種類型:
- 使用量值邏輯控制摘要— 使用較低層級維度類型數據行來篩選或分組時傳回 BLANK
- 隱藏可摘要的事實類型數據表數據行-如此一來,只能使用量值來摘要事實類型數據表
相關內容
如需本文的詳細資訊,請參閱下列資源:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應