Power BI Desktop 中的資料列層級安全性 (RLS) 指導方針
本文以您作為使用 Power BI Desktop 的數據模型工具為目標。 它描述在數據模型中強制執行數據列層級安全性 (RLS) 的良好設計做法。
請務必瞭解 RLS 篩選 數據表數據列。 它們無法設定為限制對模型物件的存取,包括數據表、數據行或量值。
注意
本文不會描述 RLS 或如何設定它。 如需詳細資訊,請參閱 使用Power BI Desktop的數據列層級安全性 (RLS) 來限制資料存取。
此外,它並不涵蓋使用 Azure Analysis Services 或 SQL Server Analysis Services 對外部裝載模型的即時連線強制執行 RLS。 在這些情況下,Analysis Services 會強制執行 RLS。 當 Power BI 使用單一登錄連線時,Analysis Services 會強制執行 RLS(除非帳戶具有系統管理員許可權)。
建立角色
可以建立多個角色。 當您考慮單一報表用戶的許可權需求時,請努力建立單一角色來授與所有這些許可權,而不是將報表使用者是多個角色成員的設計。 這是因為報表使用者可以直接使用其用戶帳戶,或間接地由安全組成員資格對應至多個角色。 多個角色對應可能會導致非預期的結果。
將報表使用者指派給多個角色時,RLS 篩選會變成加法。 這表示報表使用者可以看到代表這些篩選聯集的數據表數據列。 此外,在某些情況下,無法保證報表使用者看不到數據表中的數據列。 因此,不同於套用至 SQL Server 資料庫對象的許可權(和其他許可權模型),「一旦拒絕一律拒絕」原則並不適用。
請考慮具有兩個角色的模型:名為 Worker 的第一個角色會使用下列規則表示式來限制所有薪資數據表數據列的存取:
FALSE()
注意
當規則的表達式評估為 FALSE時,不會傳回任何數據表數據列。
然而,第二個角色,名為 Manager,允許使用下列規則表示式來存取所有 薪資 數據表數據列:
TRUE()
請小心:如果報表用戶對應至這兩個角色,他們會看到所有 薪資 數據表數據列。
優化 RLS
RLS 的運作方式是自動將篩選套用至每個 DAX 查詢,而這些篩選條件可能會對查詢效能產生負面影響。 因此,有效率的 RLS 歸結到良好的模型設計。 請務必遵循模型設計指引,如下列文章所述:
- 瞭解星型架構和Power BI的重要性
- Power BI 指引檔中找到 的所有關聯性指引文章
一般而言,在維度類型數據表上強制執行 RLS 篩選,而不是事實類型數據表通常更有效率。 而且,依賴設計良好的關聯性來確保 RLS 篩選會傳播至其他模型數據表。 RLS 篩選只會透過作用中關聯性傳播。 因此,當模型關聯性可能達到相同的結果時,請避免使用 LOOKUPVALUE DAX函式。
每當 DirectQuery 數據表上強制執行 RLS 篩選,而且與其他 DirectQuery 數據表有關聯性時,請務必優化源資料庫。 它可能涉及設計適當的索引或使用保存的計算數據行。 如需詳細資訊,請參閱 Power BI Desktop 中的 DirectQuery 模型指引。
測量 RLS 影響
您可以使用 效能分析器 來測量 Power BI Desktop 中 RLS 篩選的效能影響。 首先,判斷未強制執行 RLS 時的報表視覺查詢持續時間。 然後,使用 [模型化] 功能區索引標籤上的 [檢視身分] 命令來強制執行 RLS 並判斷和比較查詢持續時間。
設定角色對應
發佈至 Power BI 之後,您必須將成員對應至語意模型(先前稱為數據集)角色。 只有語意模型擁有者或工作區系統管理員可以將成員新增至角色。 如需詳細資訊,請參閱使用Power BI的數據列層級安全性 (RLS)(管理模型的安全性)。
成員可以是用戶帳戶、安全組、通訊群組或啟用郵件的群組。 建議您盡可能將安全組對應至語意模型角色。 它牽涉到在 Microsoft Entra ID 中管理安全組成員資格(先前稱為 Azure Active Directory)。 可能的話,它會將工作委派給您的網路管理員。
驗證角色
測試每個角色,以確保其正確篩選模型。 使用 [模型] 功能區索引標籤上的 [檢視身分] 命令,即可輕鬆完成。
當模型具有使用 USERNAME DAX 函式的動態規則時,請務必測試預期和未預期的值。 內嵌 Power BI 內容時,特別是針對您的客戶案例使用內嵌時,應用程式邏輯可以將任何值傳遞為有效的身分識別用戶名稱。 盡可能確保意外或惡意值會導致不會傳回任何數據列的篩選。
請考慮使用Power BI Embedded的範例,其中應用程式會將用戶的作業角色傳遞為有效的使用者名稱:其為「管理員」或「背景工作」。 管理員可以看到所有數據列,但背景工作角色只能看到類型數據行值為 「Internal」 的數據列。
定義下列規則表示式:
IF(
USERNAME() = "Worker",
[Type] = "Internal",
TRUE()
)
此規則表達式的問題在於除了 「Worker」 以外的所有值都會傳回 所有數據表數據列。 因此,不小心傳回所有數據表數據列的意外值,例如 「Wrker」。。 因此,撰寫會測試每個預期值的表達式會更安全。 在下列改善的規則表達式中,非預期的值會導致數據表傳回沒有數據列。
IF(
USERNAME() = "Worker",
[Type] = "Internal",
IF(
USERNAME() = "Manager",
TRUE(),
FALSE()
)
)
設計部分 RLS
有時候,計算需要不受 RLS 篩選條件限制的值。 例如,報表可能需要顯示報表用戶銷售區域所賺取收入的比率,以 取得所有收益。
雖然 DAX 運算式無法覆寫 RLS,但事實上,它甚至無法判斷 RLS 已強制執行,但您可以使用摘要模型數據表。 查詢摘要模型數據表以擷取「所有區域」的收入,且不受任何 RLS 篩選條件限制。
讓我們看看如何實作此設計需求。 首先,請考慮下列模型設計:
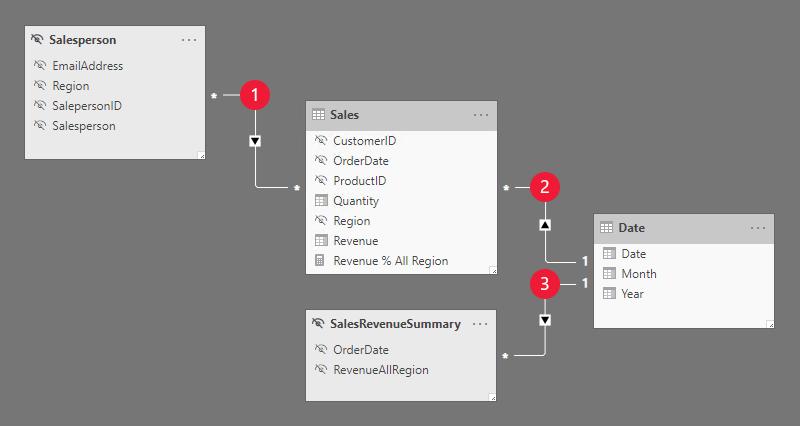
此模型包含四個資料表:
- Salesperson 數據表會為每個銷售人員儲存一個數據列。 其中包含 EmailAddress 數據行,其中會儲存每個銷售人員的電子郵件位址。 此資料表已隱藏。
- Sales 數據表會為每個訂單儲存一個數據列。 它包含 Revenue% All Region 量值,其設計目的是傳回報表用戶區域所賺取營收與所有區域所賺取收入的比率。
- Date 數據表會為每個日期儲存一個數據列,並允許篩選和分組年份和月份。
- SalesRevenueSummary 是計算數據表。 它會儲存每個訂單日期的總營收。 此資料表已隱藏。
下列運算式會 定義 SalesRevenueSummary 計算資料表:
SalesRevenueSummary =
SUMMARIZECOLUMNS(
Sales[OrderDate],
"RevenueAllRegion", SUM(Sales[Revenue])
)
注意
匯總數據表可以達到相同的設計需求。
下列 RLS 規則會套用至 Salesperson 數據表:
[EmailAddress] = USERNAME()
下表說明這三個模型關聯性:
| 關聯 | 描述 |
|---|---|
 |
Salesperson 和 Sales 數據表之間有多對多關聯性。 RLS 規則會使用 USERNAME DAX 函式來篩選隱藏 Salesperson 資料表的 EmailAddress 資料行。 Region 資料行值(適用於報表使用者)會傳播至 Sales 數據表。 |
 |
Date 和 Sales 數據表之間有一對多關聯性。 |
 |
Date 與 SalesRevenueSummary 數據表之間有一對多關聯性。 |
下列表示式會 定義 Revenue % All Region 量值:
Revenue % All Region =
DIVIDE(
SUM(Sales[Revenue]),
SUM(SalesRevenueSummary[RevenueAllRegion])
)
注意
請小心避免披露敏感性事實。 如果此範例中只有兩個區域,則報表使用者可能會計算其他區域的收入。
避免使用 RLS 的時機
有時候避免使用 RLS 是合理的。 如果您只有一些套用靜態篩選的簡單 RLS 規則,請考慮改為發佈多個語意模型。 語意模型都沒有定義角色,因為每個語意模型都包含特定報表用戶對象的數據,其具有相同的數據許可權。 然後,為每個物件建立一個工作區,並將訪問許可權指派給工作區或應用程式。
例如,只有兩個銷售區域的公司決定將每個銷售區域的語意模型發佈至不同的工作區。 語意模型不會強制執行 RLS。 不過,它們會使用 查詢參數 來篩選源數據。 如此一來,相同的模型就會發佈至每個工作區,它們只會有不同的語意模型參數值。 銷售人員只獲指派其中一個工作區的存取權(或已發佈的應用程式)。
有數個與避免 RLS 相關聯的優點:
- 改善查詢效能: 由於篩選條件較少,因此效能會改善。
- 較小的模型: 雖然會產生更多模型,但它們的大小較小。 較小的模型可以改善查詢和數據重新整理回應性,特別是當裝載容量遇到資源壓力時。 此外,更容易讓模型大小低於容量所施加的大小限制。 最後,您可以更輕鬆地平衡不同容量的工作負載,因為您可以建立工作區,或將工作區移至不同的容量。
- 其他功能: 無法使用 RLS 的 Power BI 功能,例如 發佈至 Web。
不過,有與避免 RLS 相關聯的缺點:
- 多個工作區: 每個報表用戶物件都需要一個工作區。 如果發佈應用程式,這也表示每個報表用戶物件都有一個應用程式。
- 內容重複: 報表和儀錶板必須在每個工作區中建立。 它需要更多精力和時間來設定和維護。
- 高許可權使用者: 屬於多個報表用戶物件的高許可權使用者看不到數據的合併檢視。 他們必須開啟多個報表(來自不同的工作區或應用程式)。
針對 RLS 進行疑難解答
如果 RLS 產生非預期的結果,請檢查下列問題:
- 在數據行對應和篩選方向方面,模型數據表之間存在不正確的關聯性。 請記住,RLS 篩選只會透過作用中關聯性傳播。
- 未正確設定雙向安全性篩選條件關聯性屬性。 如需詳細資訊,請參閱雙向關聯性指引。
- 數據表不包含任何數據。
- 不正確的值會載入數據表中。
- 用戶會對應至多個角色。
- 此模型包含匯總數據表,而 RLS 規則不會一致地篩選匯總和詳細數據。 如需詳細資訊,請參閱 在 Power BI Desktop 中使用匯總 (RLS for aggregations) 。
當特定使用者看不到任何數據時,可能是因為他們的UPN未儲存或輸入不正確。 可能會突然發生,因為其用戶帳戶因名稱變更而變更。
提示
為了進行測試,請新增傳回USERNAME DAX函式的量值。 您可能會將它命名為「神秘 我」。 然後,將量值新增至報表中的卡片視覺效果,並將其發佈至 Power BI。
只有語意模型讀取許可權的建立者和取用者只能檢視允許查看的數據(根據其 RLS 角色對應)。
當使用者在工作區或應用程式中檢視報表時,RLS 可能會或可能不會根據其語意模型許可權強制執行。 基於這個理由,必須強制執行 RLS 時,內容取用者和建立者才擁有基礎語意模型的讀取許可權。 如需決定是否強制執行 RLS 之許可權規則的詳細資訊,請參閱 報表取用者安全性規劃 一文。
相關內容
如需本文的詳細資訊,請參閱下列資源:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應