分散式可用性群組
適用於:![]() SQL Server
SQL Server
分散式可用性群組 (AG) 是跨兩個不同可用性群組之特殊類型的可用性群組。 從 SQL Server 2016 開始,即可使用分散式可用性群組。
本文說明分散式可用性群組功能。 若要設定分散式可用性群組,請參閱設定分散式可用性群組。
概觀
分散式可用性群組是跨兩個不同可用性群組之特殊類型的可用性群組。 參與分散式可用性群組的可用性群組不需要位於相同的位置中。 群組可以實體、虛擬、內部部署形式,存在於公用雲端或任何支援可用性群組部署的位置。 這包括跨網域,甚至跨平台,例如介於一個裝載於 Linux、一個裝載於 Windows 的可用性群組之間。 只要兩個可用性群組可以通訊,您就可以設定包含它們的分散式可用性群組。
傳統可用性群組具有在 Windows Server 容錯移轉叢集 (WSFC) 上設定的資源 (在 Linux 上則設定於 Pacemaker)。 分散式可用性群組不會在基礎叢集 (WSFC 或 Pacemaker) 中設定任何項目。 在 SQL Server 內維護它的所有相關項目。 若要了解如何檢視分散式可用性群組的資訊,請參閱檢視分散式可用性群組資訊。
分散式可用性群組需要基礎可用性群組具有接聽程式。 當您建立分散式可用性群組時,可以使用 ENDPOINT_URL 參數指定它的已設定接聽程式,而不是像使用傳統可用性群組一樣地提供獨立執行個體的基礎伺服器名稱 (或者,如果是 SQL Server 容錯移轉叢集執行個體 [FCI],則是與網路名稱資源建立關聯的值)。 雖然分散式可用性群組的每個基礎可用性群組都具有接聽程式,但是分散式可用性群組沒有接聽程式。
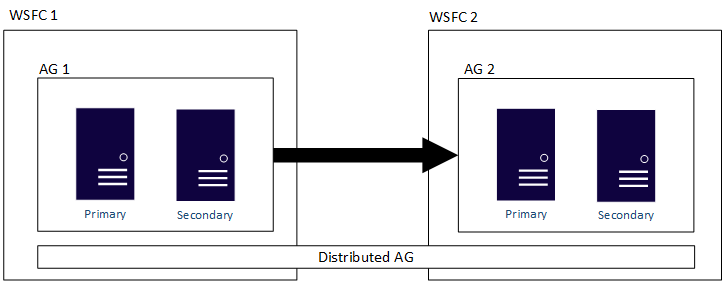
下圖顯示跨兩個可用性群組 (AG 1 和 AG 2) 之分散式可用性群組的高階檢視,而這兩個可用性群組都設定於其專屬 WSFC 上。 分散式可用性群組共有四個複本,而每個可用性群組各有兩個複本。 每個可用性群組皆可支援最大複本數,因此分散式可用性群組最多可以有總共 18 個複本。
您可以將分散式可用性群組中的資料移動設定為同步或非同步。 不過,相較於傳統可用性群組,資料移動在分散式可用性群組內略有不同。 雖然每個可用性群組都有主要複本,但是參與可接受插入、更新和刪除之分散式可用性群組的資料庫只能有一個複本。 如下圖所示,AG 1 是主要可用性群組。 其主要複本會將交易傳送至次要複本 AG 1 和主要複本 AG 2。 AG 2 的主要複本也稱為「轉寄站」。 轉寄站是分散式可用性群組的次要可用性群組中的主要複本。 轉寄站會接收來自主要可用性群組中主要複本的交易,並將它們轉寄至其專屬可用性群組中的次要複本。 轉寄站接著會持續更新 AG 2 的次要複本。
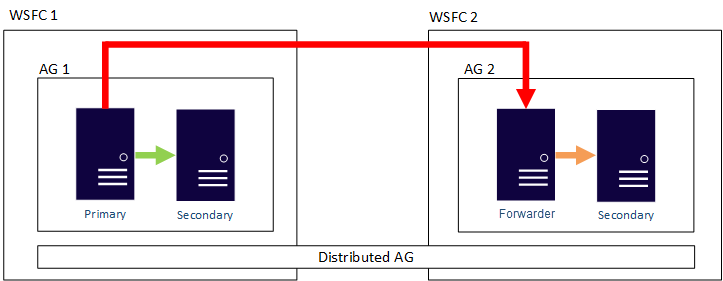
將 AG 2 的主要複本設為接受插入、更新和刪除的唯一方式,是從 AG 1 手動容錯移轉分散式可用性群組。 在上圖中,因為 AG 1 包含資料庫的可寫入複本,所以發出容錯移轉時會將 AG 2 設為可處理插入、更新和刪除的可用性群組。 如需如何將某個分散式可用性群組容錯移轉至另一個可用性群組的資訊,請參閱容錯移轉至次要可用性群組。
注意
SQL Server 2016 中的分散式可用性群組只支援使用 FORCE_FAILOVER_ALLOW_DATA_LOSS 選項從某個可用性群組容錯移轉至另一個可用性群組。
注意
搭配使用異動複寫與分散式可用性群組時,無法將轉寄站複本設定為發行者。
版本和版本需求
SQL Server 2017 或更新版本中分散式可用性群組可以混合相同分散式可用性群組中的主要 SQL Server 版本。 包含讀取/寫入主要複本的 AG 版本,可以與參與分散式 AG 的其他 AG 版本相同或更低。 其他 AG 可以是相同版本或更新版本。 此案例是以升級和移轉案例為目標。 例如,如果包含讀取/寫入主要複本的 AG 為 SQL Server 2016,但您想要升級/移轉至 SQL Server 2017 或更新版本,則可以使用 SQL Server 2017 設定參與分散式 AG 的其他 AG。
因為 SQL Server 2012 或 2014 中沒有分散式可用性群組功能,所以使用這些版本所建立的可用性群組不能參與分散式可用性群組。
注意
根據 SQL Server 的版本,連線到 Azure 服務時(例如 受控執行個體 連結),您可以設定具有 Standard Edition 的分散式可用性群組,或混合使用 Standard 和 Enterprise 版本。 若要深入了解,請詳閱 KB3009974。
因為有兩個不同的可用性群組,所以在參與分散式可用性群組的複本上安裝 Service Pack 或累積更新的程序會與傳統可用性群組的程序略有不同:
請從更新分散式可用性群組中第二個可用性群組的複本開始。
修補分散式可用性群組中主要可用性群組的複本。
與標準可用性群組相同,將主要可用性群組容錯移轉至它自己的其中一個複本 (而不是容錯移轉至第二個可用性群組的主要複本),並進行修補。 如果沒有主要複本以外的複本,則需要手動容錯移轉至第二個可用性群組。
Windows Server 版本和分散式可用性群組
分散式可用性群組跨多個可用性群組,各在其專屬基礎 WSFC 上,而且分散式可用性群組是僅限 SQL Server 建構。 這表示裝載個別可用性群組的 WSFC 可以有不同的 Windows Server 主要版本。 SQL Server 的主要版本必須相同,如上節所討論。 與初始圖非常類似,下圖顯示參與分散式可用性群組的 AG 1 和 AG 2,但每個 WSFC 都是不同版本的 Windows Server。
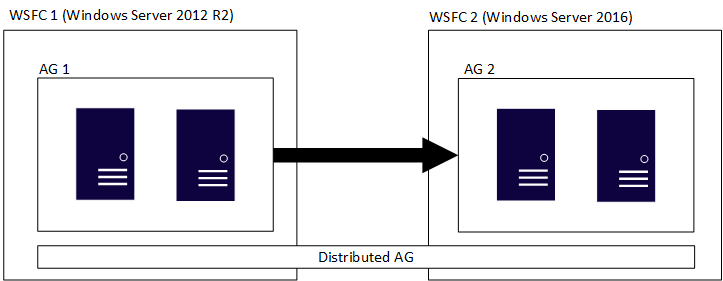
個別 WSFC 和其對應可用性群組都遵循傳統規則。 也就是說,它們可以加入網域或不加入網域 (Windows Server 2016 或更新版本)。 在單一分散式可用性群組中合併兩個不同的可用性群組時,有四個案例:
- 這兩個 WSFC 都已加入相同的網域。
- 每個 WSFC 都會加入不同的網域。
- 一個 WSFC 會加入網域,而一個 WSFC 未加入網域。
- 兩個 WSFC 都未加入網域。
如果將這兩個 WSFC 加入相同的網域 (非受信任的網域),則在您建立分散式可用性群組時不需要執行特殊作業。 針對未加入相同網域的可用性群組和 WSFC,使用憑證讓分散式可用性群組運作,這種方式與建立可用性群組作為網域獨立可用性群組的方式極為相同。 若要查看如何設定分散式可用性群組的憑證,請遵循建立網域獨立的可用性群組下的步驟 3-13。
使用分散式可用性群組時,每個基礎可用性群組中的主要複本都必須要有對方的憑證。 如果您已經有未使用憑證的端點,請使用 ALTER ENDPOINT 重新設定這些端點,以反映憑證的使用。
使用方式情節
以下是分散式可用性群組的三個主要使用案例:
災害復原和多網站案例
傳統可用性群組需要所有伺服器都屬於相同的 WSFC,這樣可讓跨多個資料中心更具挑戰。 下圖顯示傳統多網站可用性群組架構的樣子,包含資料流程。 有一個主要複本會將交易傳送至所有次要複本。 此設定在某些方面較分散式可用性群組不具彈性。 例如,您必須在 WSFC 中實作 Active Directory (如果適用) 和仲裁見證這類事物。 您也可能需要考量 WSFC 的其他方面,例如改變節點投票。

分散式可用性群組針對跨多個資料中心的可用性群組,提供更具彈性的部署案例。 您甚至可以使用分散式可用性群組,過去會針對災害復原等情況,使用它的記錄傳送等功能。 不過,與記錄傳送不同,分散式可用性群組不能延遲套用交易。 這表示可用性群組或分散式可用性群組對於錯誤地更新或刪除資料的人為錯誤沒有任何幫助。
分散式可用性群組是鬆散偶合的,在此情況下,表示其不需要單一 WSFC,而且是由 SQL Server 進行維護。 因為 WSFC 叢集是個別進行維護,而且兩個可用性群組之間的同步處理主要是不同步的,所以可以更輕鬆地在另一個網站上設定災害復原。 每個可用性群組中的主要複本都會同步處理其專屬次要複本。
- 只有分散式可用性群組支援手動容錯移轉。 在切換資料中心的災害復原狀況中,您不應該設定自動容錯移轉 (極少數的例外狀況)。
- 您很可能不需要為多網站或子網路 WSFC 設定一些傳統項目或參數 (例如 CrossSubnetThreshold),但仍然需要了解資料傳輸之不同層的網路延遲。 差異在於每個 WSFC 都會維持其本身的可用性;叢集不是四個節點的一個巨型實體。 如上圖所示,您有兩個不同的雙節點 WSFC。
- 建議非同步資料移動,因為這個方法是用於災害復原。
- 如果您在主要複本與第二個可用性群組之至少一個次要複本間設定同步資料移動,並且在分散式可用性群組上設定同步移動,則分散式可用性群組會等待,直到所有同步複本都認可它們具有資料。 如果多個分散式可用性群組是菊花鏈結 (AG1 - > AG2 - > AG3) 並設定為同步,分散式可用性群組會等到最後一個可用性群組的最後一個複本更新為止。
移轉
因為分散式可用性群組支援兩個完全不同的可用性群組組態,所以它們不僅可啟用較輕鬆的災害復原和多網站案例,也可以啟用移轉案例。 不論移轉至新硬體還是虛擬機器 (公用雲端中的內部部署或 IaaS),設定分散式可用性群組都允許進行移轉,而在過去,您可能會使用備份、複製和還原,或記錄傳送。
在您要變更或升級基礎 OS 但同時保留相同 SQL Server 版本的情況下,移轉能力特別有用。 雖然 Windows Server 2016 確實允許在相同的硬體上從 Windows Server 2012 R2 進行輪流升級,但是大部分使用者都會選擇部署新的硬體或虛擬機器。
若要完成移轉至新的組態,請在程序結束時停止原始可用性群組的所有資料流量,並將分散式可用性群組變更為同步資料移動。 此動作確保完全同步處理第二個可用性群組的主要複本,因此不會遺失任何資料。 確認同步處理之後,請將分散式可用性群組容錯移轉至次要可用性群組。 如需詳細資訊,請參閱容錯移轉至次要可用性群組。
移轉後,其中,第二個可用性群組現在是新的主要可用性群組,您可能需要執行下列任一步驟:
- 重新命名次要可用性群組上的接聽程式 (而且可能會刪除或重新命名原始主要可用性群組上的舊接聽程式),或使用原始主要可用性群組中的接聽程式來重新建立它,讓應用程式和使用者可以存取新的組態。
- 如果無法重新命名或重新建立,請將應用程式和使用者指向第二個可用性群組上的接聽程式。
移轉至更新的 SQL Server 版本
在移轉情節期間,雖然您可以設定分散式 AG,將資料庫移轉至比來源更高版本的 SQL Server 目標,但有一些限制。
當您使用比來源更高版本的 SQL Server 移轉目標來設定分散式 AG 時,不支援自動植入模式,因此必須將植入模式設定為 MANUAL。 如果您未停用 AUTO-SEEDING,您的移轉將會失敗,而且您會看到錯誤 946「無法開啟資料庫 』DistributionAG' 版本 xxx。 請將資料庫升級成最新的版本。 您必須將植入模式設定為 MANUAL,並手動從主要 AG 執行源資料庫的完整和事務歷史記錄備份。 然後,將它連同事務歷史記錄手動還原至次要 AG。 若要深入了解,請檢閱手動植入步驟,以設定分散式 AG,以及撰寫指令碼,將資料庫從主要 AG 備份和還原至次要 AG。
假設次要 AG (AG2) 是移轉目標,且版本高於主要 AG (AG1),請考量下列限制:
- 只要主要 AG 的版本較低,您就沒有次要 AG 上任何複本資料庫的讀取存取權限。
- 在這段期間,更新會繼續從主要 AG (AG1) 流向次要 AG (AG2),但次要 AG 的狀態會顯示為「部分狀況良好」,而次要 AG (AG2) 次要複本上的資料庫仍會顯示為同步處理/復原中 (即使 AG 處於同步處理認可也一樣)。
- 一旦分散式 AG 容錯移轉至較高版本 (AG2),AG2 應該會變成狀況良好。
- 在此期間,因為版本較低,無法容錯回復至 AG1。
- AG1 版本較低,因此在容錯移轉至 AG2 之後,AG2 的更新將不會複寫至 AG1。
- 從這裡選擇您是否要解除委任原始 (主要) AG,或是否要升級 AG1 並維護分散式 AG。
- 如果您選擇解除委任 AG1,請從分散式 AG 移除原始的主要 AG,此流程便已完成。
- 如果您選擇維護分散式 AG,請將 AG1 的 SQL Server 版本升級為符合 AG2。 一旦 AG1 完成升級,AG1 就會變成狀況良好、分散式 AG 變成狀況良好、複本趕上同步處理,而能夠進行容錯回復。
擴增可讀取複本
單一分散式可用性群組視需要最多可以有 16 個次要複本。 因此,它最多可以有 18 個複本可供讀取,包括不同可用性群組的兩個主要複本。 這個方法表示多個網站可以有各種應用程式報告的接近即時存取權。
分散式可用性群組協助您相應放大唯讀伺服器陣列的程度,高於只使用單一可用性群組。 分散式可用性群組可以使用兩種方式相應放大可讀取複本:
- 您可以在分散式可用性群組中使用第二個可用性群組的主要複本,來建立另一個分散式可用性群組,即使資料庫未處於復原狀態也是一樣。
- 您也可以使用第一個可用性群組的主要複本來建立另一個分散式可用性群組。
也就是說,主要複本可以參與不同的分散式可用性群組。 下圖顯示 AG 1 和 AG 2 參與分散式 AG 1,而 AG 2 和 AG 3 參與分散式 AG 2。 AG 2 的主要複本 (或轉寄站) 是分散式 AG 1 的次要複本,也是分散式 AG 2 的主要複本。
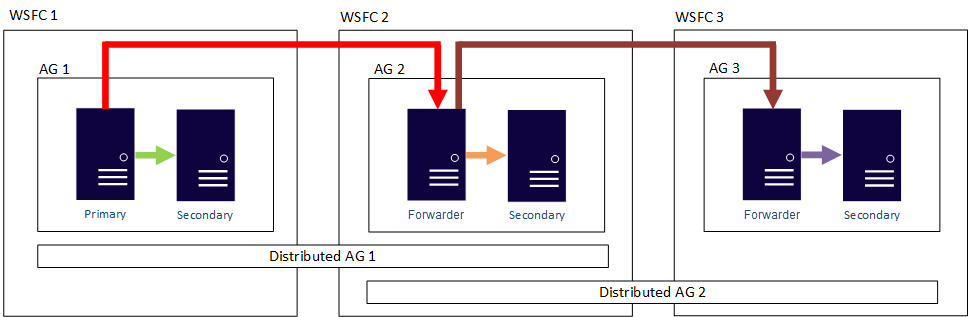
下圖顯示 AG 1 作為兩個不同分散式可用性群組的主要複本:分散式 AG 1 (包含 AG 1 和 AG2) 和分散式 AG 2 (包含 AG 1 和 AG 3)。
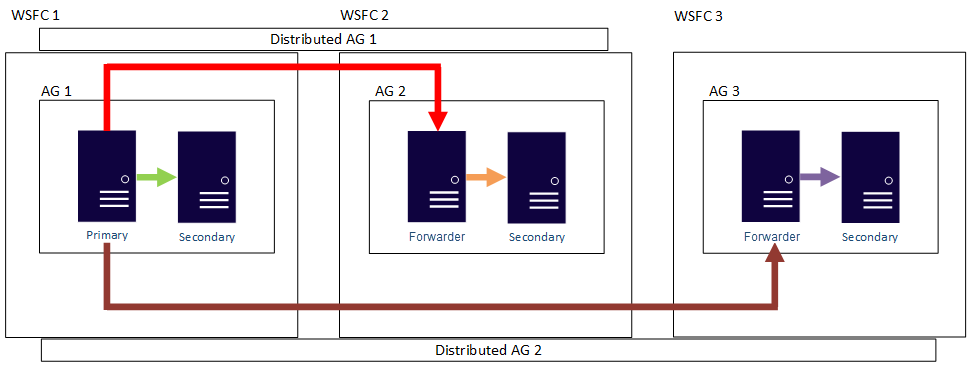
在這兩個上述範例中,這三個可用性群組最多可能共會有 27 個複本,而且全部都可以用於唯讀查詢。
唯讀路由無法完全與分散式可用性群組搭配運作。 具體而言:
- 唯讀路由可加以設定,並用於分散式可用性群組的主要可用性群組。
- 唯讀路由可加以設定,但無法用於分散式可用性群組的次要可用性群組。 查詢若使用接聽程式連線到次要可用性群組,則會全部移至次要可用性群組的主要複本。 否則,您必須設定每個複本都允許次要複本的所有連接,並直接存取它們。 不過,如果次要可用性群組在容錯移轉之後成為主要,則可以使用唯讀路由。 在 SQL Server 2016 更新或 SQL Server 的未來版本中,可能會變更此行為。
初始化次要可用性群組
分散式可用性群組過去是使用自動植入所設計,而自動植入是用來初始化第二個可用性群組上主要複本的主要方法。 如果您執行下列作業,才能對第二個可用性群組的主要複本進行完整資料庫還原:
- 使用 WITH NORECOVERY 還原資料庫備份。
- 若有必要,請使用 WITH NORECOVERY 還原正確的交易記錄備份。
- 在未指定資料庫名稱並將 SEEDING_MODE 設定為 AUTOMATIC 的情況下,建立第二個可用性群組。
- 使用自動植入來建立分散式可用性群組。
當您將第二個可用性群組的主要複本新增至分散式可用性群組時,會對第一個可用性群組的主要資料庫檢查該複本,而且植入會將資料庫快取到來源。 有一些警示:
第二個可用性群組之主要複本上的
sys.dm_hadr_automatic_seeding中所顯示的輸出,會將current_state顯示為 FAILED,且原因為「植入檢查訊息逾時」。第二個可用性群組之主要複本上的目前 SQL Server 記錄會顯示植入已運作,並且已同步處理 LSN。
第一個可用性群組之主要複本上的
sys.dm_hadr_automatic_seeding中所顯示的輸出,會將 current_state 顯示為 COMPLETED。分散式可用性群組的植入也會有不同的行為。 若要在第二個複本上開始植入,您必須在複本上發出
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASE命令。 雖然這個條件仍然適用於參與基礎可用性群組的任何次要複本,但是第二個可用性群組的主要複本在將新增至分散式可用性群組之後已有允許開始植入的正確權限。
監視健康情況
分散式可用性群組是僅限 SQL Server 的建構,而且在基礎 WSFC 中看不到它。 下列程式代碼範例顯示兩個不同的 WSFC(CLUSTER_A和CLUSTER_B),每個 WSFC 都有自己的可用性群組。 這裡只討論 CLUSTER_A 中的 AG1 以及 CLUSTER_B 中的 AG2。
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
分散式可用性群組的所有詳細資訊皆位在 SQL Server 檢視中,特別是在可用性群組動態管理檢視中。 目前,SQL Server Management Studio 中顯示的唯一分散式可用性群組資訊,是可用性群組的主要複本相關資訊。 如下圖所示,在 [可用性群組] 資料夾底下,SQL Server Management Studio 顯示有分散式的可用性群組。 此圖顯示 AG1 是本機執行個體之個別可用性群組的主要複本,不是分散式可用性群組的主要複本。
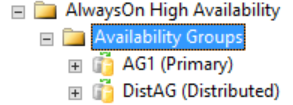
不過,如果您以滑鼠右鍵按一下分散式的可用性群組,沒有選項可用 (請參閱下圖),展開 [可用性資料庫],[可用性群組接聽程式],以及 [可用性複本] 資料夾也都是空的。 SQL Server Management Studio 16 會顯示此結果,但未來的 SQL Server Management Studio 版本可能會變更。
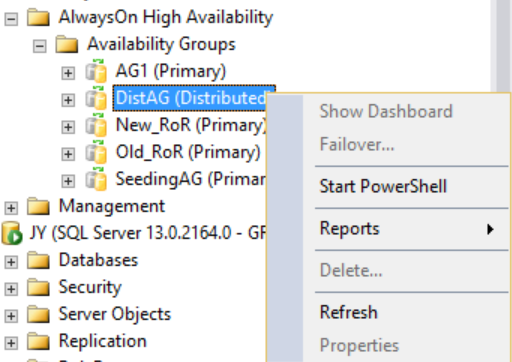
如下圖所示,次要複本在 SQL Server Management Studio 中不顯示與分散式可用性群組相關的任何資訊。 這些可用性群組名稱會對應至上一個 CLUSTER_A WSFC 映像中所示的角色。
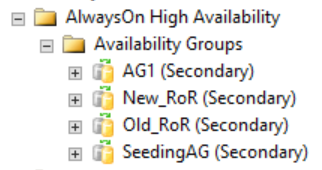
列出所有可用性複本名稱的 DMV
使用動態管理檢視時,適用相同的概念。 使用下列查詢,您可以看到所有可用性群組 (一般和分散式) 和加入它們的節點。 只有當您在其中一個參與分散式可用性群組的 WSFC 中查詢主要複本時,才會顯示此結果。 在動態管理檢視 sys.availability_groups 中有個名為 is_distributed 的新資料行,當可用性群組是分散式可用性群組時,它會是 1。 查看此資料行:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
下圖顯示參與分散式可用性群組之第二個 WSFC 的輸出範例。 SPAG1 是由兩個複本組成:DENNIS 和 JY。 不過,名為 SPDistAG 的分散式可用性群組,和傳統的可用性群組一樣,有兩個加入的可用性群組名稱 (SPAG1 和 SPAG2),而不是執行個體的名稱。
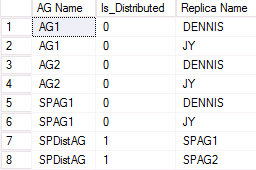
列出分散式 AG 健康狀態的 DMV
在 SQL Server Management Studio 中,儀表板和其他區域顯示的任何狀態都只供該可用性群組內本機同步處理之用。 若要顯示分散式可用性群組的健康狀態,請查詢動態管理檢視。 下列範例查詢會延伸並縮小上一個查詢:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

檢視基礎效能的 DMV
若要進一步延伸前一個查詢,您也可新增 sys.dm_hadr_database_replicas_states,透過動態管理檢視查看基礎效能。 動態管理檢視目前只儲存有關第二個可用性群組的資訊。 下列範例查詢,針對主要可用性群組執行,會產生如下所示的範例輸出:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

檢視分散式 AG 之效能計數器的 DMV
下列查詢顯示與特定分散式可用性群組相關聯的效能計數器。
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
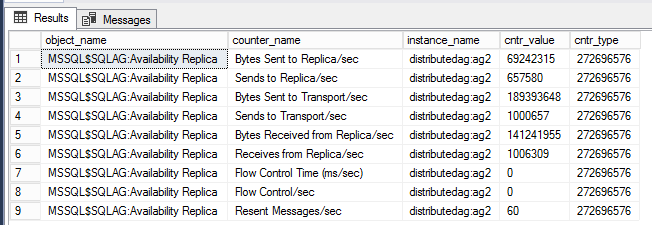
注意
LIKE 篩選應該具有分散式可用性群組的名稱。 在此範例中,分散式可用性群組的名稱為 'distributedag'。 請變更 LIKE 修飾詞以反映您的分散式可用性群組名稱。
顯示 AG 和分散式 AG 之健全狀況的 DMV
下列查詢顯示可用性群組和分散式可用性群組之健全狀況的相關豐富資訊。 (從 Tracy Bogg 權限重現。)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

檢視分散式 AG 之中繼資料的 DMV
下列查詢顯示可用性群組 (包括分散式可用性群組) 所使用之端點 URL 的相關資訊。 (從 David Barbarin 權限重現。)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

顯示目前植入狀態的 DMV
下列查詢顯示目前植入狀態的相關資訊。 這可用於針對複本之間的同步處理錯誤進行疑難排解。 (從 David Barbarin 權限重現。)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO

相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應