查詢處理結構指南
適用於:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體
SQL Server 資料庫引擎會處理各種資料儲存結構上的查詢,例如本機資料表、資料分割資料表,以及分散到多部伺服器的資料表。 下列各節涵蓋 SQL Server 如何處理查詢,以及透過執行計畫快取來將查詢重複使用最佳化。
執行模式
SQL Server 資料庫引擎可以使用兩種不同的處理模式來處理 Transact-SQL 陳述式:
- 資料列模式執行
- 批次模式執行
資料列模式執行
「資料列模式執行」是可搭配傳統 RDBMS 資料表使用的查詢處理方法,其中資料是以資料列格式儲存。 當查詢執行並存取資料列存放區資料表中的資料時,執行樹狀目錄運算子和子運算子會在資料表結構描述中指定的所有資料行之間,讀取每個必要的資料列。 從所讀取的每個資料列,SQL Server 會接著擷取結果集所需的資料行,以供 SELECT 陳述式、聯結述詞或篩選述詞參考。
注意
資料列模式執行針對 OLTP 案例非常有效率,但在掃描大量資料時 (例如在資料倉儲案例中) 可能比較沒有效率。
批次模式執行
「批次模式執行」是用來同時處理多個資料列的查詢處理方法 (如批次一詞所指)。 批次內的每個資料行會儲存為不同儲存體區域中的向量,因此批次模式處理是以向量為基礎。 批次模式處理也會使用演算法,這些演算法已針對現代硬體上發現的多核心 CPU 和增加的記憶體輸送量進行最佳化。
在首次引進時,批次模式執行已針對資料行存放區儲存格式最佳化並與其密切整合。 不過從 2019 SQL Server 2019 (15.x) 開始,在 Azure SQL 資料庫中,批次模式執行不再需要資料行存放區索引。 如需詳細資訊,請參閱資料列存放區上的批次模式。
當情況允許時,批次模式處理會在壓縮的資料上作業,並排除資料列模式執行所使用的 Exchange 運算子。 結果會是較佳的平行處理原則與更快的效能。
當查詢以批次模式執行並存取資料行存放區索引中的資料時,執行樹狀目錄運算子和子運算子會同時讀取資料行區段中的多個資料列。 SQL Server 只會讀取結果所需的資料行,以供 SELECT 陳述式、聯結述詞或篩選述詞參考。 如需資料行存放區索引的詳細資訊,請參閱資料行存放區索引結構。
注意
批次模式執行對於資料倉儲案例非常有效率,其中會讀取及彙總大量資料。
SQL 陳述式處理
處理單一 Transact-SQL 陳述式是 SQL Server 執行 Transact-SQL 陳述式的最基本方式。 用於處理僅參考本機基底資料表 (非檢視表或遠端資料表) 之單一 SELECT 陳述式的步驟可說明這個基本程序。
邏輯運算子優先順序
當陳述式中使用一個以上的邏輯運算子,NOT 會第一個計算,接下來是 AND,最後才是 OR。 先處理算術以及位元運算子,接著才處理邏輯運算子。 如需詳細資訊,請參閱運算子優先順序。
在下列範例中,色彩條件與產品型號 21 相關,但不與產品型號 20 相關,原因是 AND 的優先順序高於 OR。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
您可以加上括號,強迫陳述式先執行 OR 來變更查詢的意義。 下列查詢只會尋找型號 20 和 21 下的紅色產品。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
即使非必要,也建議您使用括號以改善查詢的可讀性,並減少因為運算子優先順序而導致細部錯誤的可能性。 使用括號對效能不會有太大的負面影響。 下面的範例與原始範例雖然在句法上並無不同,但其可讀性更高。
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
最佳化 SELECT 陳述式
SELECT 陳述式為非程序性,無法敘述資料庫伺服器應用來擷取所需資料的正確步驟。 這是表示資料庫伺服器應該先分析陳述式,才能判斷出取得所需資料的最有效方式。 這稱為將 SELECT 陳述式最佳化。 執行此動作的元件稱為「查詢最佳化工具」。 查詢最佳化工具的輸入是由查詢、資料庫結構描述 (資料表和索引定義) 以及資料庫統計資料所組成。 查詢最佳化工具的輸出是查詢執行計畫,有時稱為查詢計畫或執行計畫。 本文後續將更詳盡地描述執行計畫的內容。
下圖說明在單一 SELECT 陳述式最佳化期間,查詢最佳化工具的輸入與輸出:
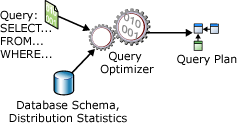
SELECT 陳述式僅定義下列項目:
- 結果集的格式。 這大部份是在選取清單中指定。 不過,其他如
ORDER BY和GROUP BY等子句也會影響結果集的最後格式。 - 包含來源資料的資料表。 這指定於
FROM子句中。 - 資料表如何在邏輯上與
SELECT陳述式的目的產生關聯。 這定義於聯結規格中,其可能出現在WHERE後面的ON子句或FROM子句中。 - 來源資料表中的資料列必須滿足才能符合
SELECT陳述式的條件。 這些條件指定於WHERE和HAVING子句中。
查詢執行計畫是用以定義下列項目:
存取來源資料表的順序。
一般而言,資料庫伺服器存取基底資料表以建立結果集的順序有很多種。 例如,如果SELECT陳述式參考三個資料表,則資料庫伺服器會先存取TableA、使用TableA中的資料來擷取TableB中相符的資料列,然後使用TableB中的資料來擷取TableC中的資料。 資料庫伺服器可以存取資料表的其他順序如下:
TableC、TableB、TableA或
TableB、TableA、TableC或
TableB、TableC、TableA或
TableC、TableA、TableB用來從每個資料表擷取資料的方法。
一般而言,有各種不同的方式可存取每個資料表中的資料。 如果僅需要特定索引鍵值的一些資料列,則資料庫伺服器可以使用索引。 如果需要資料表中的所有資料列,則資料庫伺服器可以忽略索引,並執行資料表掃描。 如果需要資料表中的所有資料列,但其中有一個索引的索引鍵資料行是在ORDER BY中,則執行索引掃描來替代資料表掃描,就能儲存不同排序的結果集。 如果資料表非常小,則資料表掃描可能是所有資料表存取中最有效率的方式。用來計算計算,以及如何篩選、彙總及排序每個資料表中的資料的方法。
從資料表存取資料時,有不同的方法可以針對資料執行計算 (例如計算純量值),以及彙總和排序查詢文字中定義的資料 (例如使用GROUP BY或ORDER BY子句時),以及如何篩選資料 (例如使用WHERE或HAVING子句時)。
從許多可能的計畫中選擇其中一個執行計畫的程序,便稱為最佳化。 查詢最佳化工具是資料庫引擎中最重要的元件之一。 因為查詢最佳化工具使用部份負擔來分析查詢並選取計畫,所以當查詢最佳化工具挑出最有效率的執行計畫時,這個負擔通常已經儲存了好幾層。 例如,兩家營造公司可能對同一間房屋有相同的藍圖。 如果有一家公司在剛開始時,願意花幾天的時間計畫將如何建造房屋,而另一家公司則不計畫就開始建造,那麼有花時間規劃其專案的公司,最有可能在第一時間完成。
SQL Server 查詢最佳化工具是成本型最佳化工具。 每個可能的執行計畫都有計算所使用資源量的相關成本。 查詢最佳化工具必須分析可能的計畫並選擇最低估計成本的計畫。 有些複雜的 SELECT 陳述式具備數千個可能的執行計畫。 在這些情況中,查詢最佳化工具不會分析所有可能的組合。 相反的,它會使用複雜的演算法來尋找最接近最小可能成本的執行計畫。
SQL Server 查詢最佳化工具不僅能選擇最低資源成本的執行計畫,也能選擇以資源成本合理為使用者提供結果的計畫,還有最快傳回結果的計畫。 例如,一般平行處理查詢時,需使用比循序處理時使用更多的資源,但完成的速度較快。 在不會嚴重伺服器負載的前提下,SQL Server 查詢最佳化工具將會使用平行執行計畫來傳回結果。
在評估從資料表或索引擷取的不同方法成本時,SQL Server 查詢最佳化工具會根據散發統計資料進行判斷。 系統會保留資料行和索引的散發統計資料,其中包含基礎資料密度1 的相關資訊。 這可用來指出特定索引或資料行中值的選擇性。 例如,在表示車種的資料表中,許多車種的製造商都是相同的,但每輛車都有一個唯一的汽車識別號碼。 由於 VIN 的密度比製造商低,因此 VIN 的索引會比製造商的索引更具選擇性。 如果索引統計資料過期,查詢最佳化工具可能無法為資料表的目前狀態做出最佳選擇。 如需密度的詳細資訊,請參閱統計資料。
1 密度會定義資料中唯一值的分佈,或指定資料行中重複值的平均數。 當密度降低時,值的選擇性會增加。
SQL Server 查詢最佳化工具的關鍵用途在於讓資料庫伺服器能夠動態調整,直接變更資料庫內的條件,而不需要程式設計師或資料庫管理員進行輸入。 這樣程式設計師便不用將焦點集中在描述查詢的最後結果。 他們可以相信每次執行陳述式時,SQL Server 查詢最佳化工具將依資料庫的狀態建立最有效率的執行計畫。
注意
SQL Server Management Studio 有三個選項可顯示執行計畫:
處理 SELECT 陳述式
SQL Server 用來處理單一 SELECT 陳述式的基本步驟如下:
- 剖析器會掃描
SELECT陳述式,並將其分成數個邏輯單位,例如關鍵字、運算式、運算子和識別碼。 - 然後系統會建立查詢樹 (有時也稱為序列樹),描述將來源資料轉換成結果集所需格式的邏輯步驟。
- 查詢最佳化工具會分析可存取來源資料表的數種方式。 接著會選取一系列使用較少資源,但能最快傳回結果的步驟。 將會更新查詢以記錄所有的系列步驟。 查詢樹的最後最佳版本就稱為執行計畫。
- 關聯式引擎開始執行執行計畫。 當在處理需要基底資料表中資料的步驟時,關聯式引擎會要求儲存引擎,從取自關聯式引擎的資料列集中傳回資料。
- 關聯式引擎處理從儲存引擎傳回的資料,並將其設定成結果集所定義的格式,然後將結果集傳回給用戶端。
常數摺疊和運算式評估
SQL Server 會在早期評估某些常數運算式,以改進查詢效能。 這個作業稱為常數摺疊 (Constant Folding)。 常數是 Transact-SQL 常值,例如3、'ABC'、'2005-12-31'、1.0e3 或 0x12345678。
可摺疊運算式
SQL Server 會在下列運算式類型中使用常數摺疊:
- 只包含常數的算術運算式,例如
1 + 1和5 / 3 * 2。 - 只包含常數的邏輯運算式,例如
1 = 1和1 > 2 AND 3 > 4。 - SQL Server 視為可摺疊的內建函數,包括
CAST和CONVERT。 如果內建函數只包含其輸入,並且不含其他內容資訊 (例如 SET 選項、語言設定、資料庫選項和加密金鑰) 時,此內建函數通常是可摺疊。 非決定性函數不可摺疊。 決定性內建函數可摺疊,但有一些例外。 - 由 CLR 使用者定義之類型的決定性方法,以及由 CLR 使用者定義,具決定性純量值 CLR 的函式 (自 SQL Server 2012 (11.x) 起)。 如需詳細資訊,請參閱 CLR 使用者定義之函式與方法的常數摺疊。
注意
例外之一是大型物件類型。 若摺疊處理序的輸出類型為大型物件類型 (text、ntext、image、nvarchar(max)、varchar(max)、varbinary(max),或 XML),則 SQL Server 不會摺疊此運算式。
不可摺疊運算式
所有其他運算式類型都不可摺疊, 尤其是下列運算式類型不可折疊:
- 非常數運算式,例如結果相依於資料行值的運算式。
- 結果相依於本機變數或參數 (例如 @x) 的運算式。
- 非決定性函數。
- 使用者定義的 Transact-SQL 函數 1。
- 結果相依於語言設定的運算式。
- 結果相依於 SET 選項的運算式。
- 結果相依於伺服器組態選項的運算式。
1 在 SQL Server 2012 (11.x) 之前無法摺疊由 CLR 使用者定義,具決定性純量值 CLR 的 函數及 CLR 使用者定義之類型的方法。
可摺疊和不可摺疊常數運算式的範例
請考慮下列查詢:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
如果這個查詢的 PARAMETERIZATION 資料庫選項不是設為 FORCED,則會評估運算式 117.00 + 1000.00 並替換成其結果 1117.00,再編譯查詢。 這項常數摺疊作業的好處包含下列幾點:
- 執行階段不必重複評估運算式。
- 查詢最佳化工具可使用評估後的運算式值,來估計
TotalDue > 117.00 + 1000.00查詢部分的結果集大小。
另一方面,如果 dbo.f 是純量使用者定義函數,則運算式 dbo.f(100) 不可摺疊,因為 SQL Server 不會摺疊含有使用者定義函數的運算式,即使它們是決定性函數也是如此。 如需參數化的詳細資訊,請參閱本文後面的強制參數化。
運算式評估
此外,在最佳化期間,結果集大小 (基數) 估計工具 (此為最佳化工具的一部份) 會評估部份運算式,這些運算式不是常數摺疊,但在編譯時間其引數為已知 (不論引數是參數或常數)。
特別是在編譯時間會評估下列這些內建函式和特殊運算子,如果其所有輸入皆為已知:UPPER、LOWER、RTRIM、DATEPART( YY only )、GETDATE、CAST 和 CONVERT。 下列運算子的所有輸入若為已知,在編譯時間也會加以評估:
- 算術運算子:+、-、*、/、一元減號 -
- 邏輯運算子:
AND、OR、NOT - 比較運算子:<、>、<=、>=、<>、
LIKE、IS NULL、IS NOT NULL
在基數估計期間,查詢最佳化工具不會評估任何其他函式或運算子。
編譯時間運算式評估的範例
請看此段預存程序:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
在此程序的 SELECT 陳述式最佳化期間,查詢最佳化工具會嘗試評估條件 OrderDate > @d+1 之結果集的預期基數。 運算式 @d+1 不是常數摺疊,因為 @d 是參數。 然而,在最佳化時間內,此參數的值為已知。 這可讓查詢最佳化工具正確估計結果集的大小,協助它選取良好的查詢計畫。
現在看另一個類似範例,但在查詢中以本機變數 @d2 取代上一個範例中的 @d+1,並改為在 SET 陳述式 (而不是查詢) 中評估運算式。
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
在 SQL Server 最佳化 MyProc2 中的 SELECT 陳述式時,@d2 的值未知。 因此,查詢最佳化工具會針對 OrderDate > @d2 的選擇性,使用預設估計值 (本例中為 30%)。
處理其他的陳述式
這裡描述來用以處理 SELECT 陳述式的基本步驟適用於其他 Transact-SQL 陳述式,例如 INSERT、UPDATE 及 DELETE。 UPDATE 與 DELETE 陳述式都必須將目標設定為要修改或刪除的資料列集合。 識別這些資料列的處理序,與用以識別參與 SELECT 陳述式結果集之來源資料列的處理序相同。 UPDATE 和 INSERT 陳述式可能都包含內嵌的 SELECT 陳述式,其可提供要更新或插入的資料值。
即使資料定義語言 (DDL) 陳述式 (例如 CREATE PROCEDURE 或 ALTER TABLE) 最後會解析為系統目錄資料表上一連串的關聯式作業,但有時還是會根據資料表來解析 (例如 ALTER TABLE ADD COLUMN)。
工作資料表
關聯式引擎在執行 Transact-SQL 陳述式中所指定的邏輯作業前,可能需要先建立一個工作資料表。 工作資料表屬於內部資料表,可用來保存中繼結果。 工作資料表會針對特定的 GROUP BY、 ORDER BY或 UNION 查詢而產生。 例如,若 ORDER BY 子句參考的資料行不在任何索引範圍內,關聯式引擎便須產生工作資料表,將結果集排序成要求的順序。 工作資料表有時候也當作多工緩衝處理使用,可暫時保存執行部份查詢計畫的結果。 工作資料表建置於 tempdb 中,並且會在不再需要時自動卸除。
檢視解析
SQL Server 查詢處理器對待索引及非索引檢視表的方式不同:
- 索引檢視的資料列是儲存在資料表庫中,並使用與資料表相同的格式。 如果查詢最佳化工具決定使用查詢計畫中的索引檢視,將以處理基底資料表的相同方式來處理索引檢視。
- 只會儲存非索引檢視的定義,而不會儲存檢視的資料列。 查詢最佳化工具會將檢視表定義中的邏輯合併到為 Transact-SQL 陳述式所建立的執行計畫中,該陳述式會參考非索引檢視表。
SQL Server 查詢最佳化工具用來決定何時使用索引檢視表的邏輯,類似於用以決定何時使用資料表中索引的邏輯。 如果索引檢視表中的資料涵蓋了全部或部分的 Transact-SQL 陳述式,並且查詢最佳化工具判斷出檢視表中的索引是低成本的存取路徑,那麼查詢最佳化工具便會選擇該索引,而不論查詢中是否有依名稱參考此檢視表。
當 Transact-SQL 陳述式參考無索引的檢視時,剖析器與查詢最佳化工具會分析 Transact-SQL 陳述式和檢視的來源,接著解析成單一執行計畫。 Transact-SQL 陳述式沒有計畫,而檢視也沒有單獨的計畫。
例如,請考慮下列檢視:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
根據此檢視,這兩個 Transact-SQL 陳述式會在基底資料表上執行相同的作業,並產生相同的結果:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
SQL Server Management Studio 的執行程序表功能顯示關聯式引擎為這兩個 SELECT 陳述式建立相同的執行計畫。
使用檢視的提示
在查詢中檢視所放置的提示可能與在擴充檢視以存取基底資料表時所發現的其他提示衝突。 當這種情況發生時,查詢會傳回錯誤: 例如,請考慮下列在其定義中包含資料表提示的檢視:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
現在假設您輸入以下查詢:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
查詢會失敗,因為查詢中 SERIALIZABLE 檢視表上所套用的 Person.AddrState 提示,會在展開該檢視表時傳播至檢視表的 Person.Address 與 Person.StateProvince 資料表中。 不過,展開檢視表也會顯示 NOLOCK 上的 Person.Address提示。 由於 SERIALIZABLE 提示與 NOLOCK 提示相衝突,因此會產生不正確的查詢。
PAGLOCK、 NOLOCK、 ROWLOCK、 TABLOCK或 TABLOCKX 資料表提示彼此衝突,如同 HOLDLOCK、 NOLOCK、 READCOMMITTED、 REPEATABLEREAD、 SERIALIZABLE 資料表提示。
提示可以透過巢狀檢視層級來傳播。 例如,假設查詢在 HOLDLOCK 檢視表中套用 v1提示。 展開 v1 時,發現 v2 檢視是其定義的一部份。 v2的定義包括其中一個基底資料表上的 NOLOCK 提示。 但此資料表也會繼承 HOLDLOCK 檢視表中查詢的 v1提示。 因為 NOLOCK 與 HOLDLOCK 提示相衝突,所以查詢會失敗。
在包含檢視表的查詢中使用 FORCE ORDER 提示時,檢視表中資料表的聯結順序將由依序建構中的檢視表位置來決定。 例如,下列查詢會從三個資料表和一個檢視中選取:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
而 View1 的定義如下所示:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
查詢計畫中的聯結順序為 Table1、 Table2、 TableA、 TableB、 Table3。
解析檢視表上的索引
對於任何索引,只有在查詢最佳化工具認為有所助益時,SQL Server 才會選擇在其查詢計畫中使用索引檢視表。
所有版本的 SQL Server 中均可建立索引檢視表。 在某些 SQL Server 早期版本的部分版次中,查詢最佳化工具會自動考量索引檢視表。 在某些 SQL Server 早期版本的部分版次中,若要使用索引檢視表,必須使用 NOEXPAND 資料表提示。 在 SQL Server 2016 (13.x) Service Pack 1 之前,只有特定版本的 SQL Server 支援由查詢最佳化工具自動使用索引檢視表。 因為,所有版本都支援自動使用索引檢視表。 Azure SQL 資料庫和 Azure SQL 受控執行個體支援在不指定 NOEXPAND 提示的情況下自動使用索引檢視表。
SQL Server 查詢最佳化工具會在符合下列條件時使用索引檢視:
- 下列工作階段選項會設定為
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
NUMERIC_ROUNDABORT工作階段選項會設定為 OFF。- 查詢最佳化工具會從檢視索引資料行與查詢中的元素之間找出相符之處,例如:
- 位於 WHERE 子句中的搜尋條件述詞
- 聯結作業
- 彙總函式
GROUP BY子句- 資料表參考
- 使用索引時的預估成本,擁有最佳化工具所考量的任何存取機制成本的最低值。
- 在對應於索引檢視中之資料表參考的查詢中,每個參考的資料表 (直接參考,或藉由展開檢視以存取其基礎資料表) 都必須在查詢中套用同一組提示。
注意
無論目前的交易隔離等級為何,在此內容中,永遠都會將 READCOMMITTED 和 READCOMMITTEDLOCK 提示視為不同的提示。
除了 SET 選項與資料表提示的需求以外,這些也是查詢最佳化工具用來判斷資料表索引是否涵蓋查詢的相同規則。 不需在查詢中指定其他項目,即可使用索引檢視。
查詢不一定要在 FROM 子句中明確參考索引檢視表,才能讓最佳化工具使用索引檢視表。 如果查詢中包含了基底資料表中的資料行的參考,而這些資料行也同時出現於索引檢視中,且最佳化工具的估計結果是使用索引檢視提供最低成本的存取機制,那麼最佳化工具便選擇索引檢視,這和查詢中並未直接參考基底資料表的索引時,最佳化工具選擇這些索引的方式類似。 當檢視包含查詢所未參考到的資料行,只要檢視針對涵蓋在查詢中所指定的一個或多個資料行提供最低的成本選項,最佳化工具可能就會選擇該檢視。
查詢最佳化工具會將 FROM 子句中參考的索引檢視表視為標準檢視表。 在最佳化程序開始時,查詢最佳化工具會將檢視的定義擴充到查詢中。 接著,會執行索引檢視比對。 索引檢視表可用在查詢最佳化工具所選取的最終執行計畫中,或者,此計畫可存取檢視表所參考的基底資料表,藉以從檢視表具體化必要的資料。 查詢最佳化工具會選擇成本最低的方式。
搭配索引檢視表使用提示
您可以使用 EXPAND VIEWS 查詢提示來防止在查詢中使用檢視表索引,或者可以使用 NOEXPAND 資料表提示,針對查詢的 FROM 子句所指定的索引檢視表強制使用索引。 然而,您應該讓查詢最佳化工具動態判斷每個查詢最適用的存取方法。 只有在測試已顯現出其大幅改善效能的特定情況下,才能使用 EXPAND 和 NOEXPAND 。
EXPAND VIEWS選項指定查詢最佳化工具在整個查詢中不會使用任何檢視表索引。針對檢視表指定
NOEXPAND時,查詢最佳化工具就會考慮使用檢視表中所定義的任何索引。 (透過選擇性NOEXPAND子句來指定INDEX()) 將強制查詢最佳化工具使用指定的索引。NOEXPAND只能指定給索引檢視表,且不得指定給尚未編製索引的檢視表。 在 SQL Server 2016 (13.x) Service Pack 1 之前,只有特定版本的 SQL Server 支援由查詢最佳化工具自動使用索引檢視表。 因為,所有版本都支援自動使用索引檢視表。 Azure SQL 資料庫和 Azure SQL 受控執行個體支援在不指定NOEXPAND提示的情況下自動使用索引檢視表。
如果未在含有檢視表的查詢中指定 NOEXPAND 或 EXPAND VIEWS ,即會展開檢視表以存取基礎資料表。 若構成檢視的查詢中含有任何資料表提示,這些提示便會傳播到基礎資料表。 (此處理序在<檢視解析>中有較為詳盡的說明。)只要檢視的基礎資料表上所存在的多個提示彼此相同,則查詢即可與索引檢視比對。 這些提示大多會彼此相符,因為它們都直接繼承自檢視。 然而,若查詢參考資料表 (而非檢視表) 以及直接套用於這些資料表的提示不相同,這種查詢將無法與索引檢視表進行比對。 若 INDEX、PAGLOCK、ROWLOCK、TABLOCKX、UPDLOCK 或 XLOCK 提示會在檢視表展開後套用到查詢中所參考的資料表,查詢就無法與索引檢視表進行比對。
如果格式為 INDEX (index_val[ ,...n] ) 的資料表提示會參考查詢中的檢視表,而您也未指定 NOEXPAND 提示,則會忽略索引提示。 若要指定使用特定的索引,請使用 NOEXPAND。
一般而言,當查詢最佳化工具將索引檢視表比對到查詢時,查詢中的資料表或檢視表上指定的任何提示,都會直接套用到索引檢視表。 若查詢最佳化工具選擇不使用索引檢視,則所有提示都會直接傳播到檢視中所參考的資料表。 如需詳細資訊,請參閱<檢視解析>。 這種傳播方式不適用於聯結提示。 只會套用在查詢中的原始位置。 將查詢比對到索引檢視時,查詢最佳化工具不會考慮使用聯結提示。 若查詢計畫所使用的索引檢視表符合含有聯結提示的部分查詢,則計畫中不會使用此聯結提示。
不允許在索引檢視表的定義中使用提示。 在 80 與更高的相容性模式中,SQL Server 會在維護索引檢視表定義時,或在執行使用索引檢視表的查詢時,忽略定義中的提示。 雖然在 80 相容性模式下使用索引檢視表定義中的提示並不會產生語法錯誤,但這些提示還是會被忽略。
如需詳細資訊,請參閱資料表提示 (Transact-SQL)。
解析分散式分割區檢視
SQL Server 查詢處理器會將分散式資料分割檢視表的效能最佳化。 分散式資料分割檢視效能最重要的一點,便是將在成員伺服器間傳輸的資料量最小化。
SQL Server 會建置智慧型動態計畫,有效使用分散式查詢來存取遠端成員資料表的資料:
- 查詢處理器會先使用 OLE DB 來擷取各成員資料表中的 CHECK 條件約束定義。 這可以讓查詢處理器將索引鍵值的散發對應到每個成員資料表中。
- 查詢處理器會將 Transact-SQL 陳述式
WHERE子句中指定的索引鍵範圍,與顯示成員資料表中資料列分散情況的對應進行比較。 然後,查詢處理器會建立查詢執行計畫,而此計畫的分散式查詢僅會擷取那些完成 Transact-SQL 陳述式所需的遠端資料列。 執行計畫也會以系統取得所需的資訊前,對資料或中繼資料延遲遠端成員資料表存取的方法執行。
例如,假設系統中的 Customers 資料表是跨 Server1 (從 1 到 3299999 的 CustomerID)、Server2 (從 3300000 到 6599999 的 CustomerID),以及 Server3 (從 6600000 到 9999999 的 CustomerID) 進行資料分割。
請考慮針對這個在 Server1 上執行之查詢所建置的執行計畫:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
這個查詢的執行計畫會擷取本機成員資料表中 CustomerID 索引鍵值從 3200000 到 3299999 之間的資料列,並提交分散式查詢以擷取 Server2 中索引鍵值從 3300000 到 3400000 之間的資料列。
SQL Server 查詢處理器也可以在 Transact-SQL 陳述式的查詢執行計畫中建置動態邏輯,在必須建置該計畫時,將其中的索引鍵值保持未知。 例如,請參考這個預存程序:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server 無法預測每次執行程序時,@CustomerIDParameter 參數將提供的索引鍵值。 由於索引鍵值無法預測,因此查詢處理器也無法預測必須存取哪個成員資料表。 為了處理這種情形,SQL Server 建立了具有條件式邏輯的執行計畫 (稱為動態篩選),可根據輸入參數值來控制要存取的成員資料表。 假設 GetCustomer 預存程序是在 Server1 上執行,則執行計畫邏輯就能以下列形式來表示:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server 有時甚至會為尚未參數化的查詢建置這些類型的動態執行計畫。 查詢最佳化工具可能會參數化查詢以重複使用執行計畫。 如果查詢最佳化工具將對參考資料分割檢視的查詢進行參數化,則查詢最佳化工具不會再假設需要的資料列將取自指定的基底資料表。 接著在執行計畫中必須使用動態篩選。
預存程序與觸發程序執行
SQL Server 只會儲存預存程序和觸發程序的來源。 當先執行預存程序或觸發程序時,會將來源編譯成執行計畫。 如果在執行計畫從儲存體中淘汰之前,再執行一次預存程序或觸發程序,關聯式引擎會偵測到現有的計畫並重複使用它。 如果計畫已從儲存體淘汰,就會建立新計畫。 此處理序與 SQL Server 對於所有 Transact-SQL 陳述式所依循的處理序類似。 在 SQL Server 中,相較於動態 Transact-SQL 的批次,預存程序與觸發程序的主要效能優點在於其 Transact-SQL 陳述式永遠保持相同。 因此,關聯式引擎可以輕易地將這些陳述式與任何現有的執行計畫配對。 就可以輕易地重複使用預存程序及觸發程序計畫
預存程序及觸發程序的執行計畫,將分別自呼叫預存程序,或引發觸發程序之批次的執行計畫中執行。 這可以允許更多次重複使用預存程序及觸發程序執行計畫。
執行計畫快取與重複使用
SQL Server 具有一個記憶體集區,可用來儲存執行計畫及資料緩衝區。 配置給執行計畫或資料緩衝區的集區百分比,會依系統的狀態而動態調整。 記憶體集區中用來儲存執行計畫的那一部分,稱為計畫快取。
計畫快取有兩個可用於存放經過編譯的計畫:
- 物件計畫快取存放區 (OBJCP) 用於持續性物件 (預存程序、函數和觸發程序) 相關的計畫。
- SQL 計畫快取存放區 (SQLCP) 用於與自動參數化、動態或預查詢相關的計畫。
下列查詢提供這兩個快取存放區的憶體使用量相關資訊:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
注意
計畫快取有兩個額外存放區,但不會用於存放計畫:
- 繫結樹狀結構快取存放區 (PHDR) 用於檢視、條件約束與預設值計畫編譯期間所使用的資料結構。 這些結構稱為繫結樹狀結構或 Algebrizer 樹狀結構。
- 擴充預存程序快取存放區 (XPROC) 用於預先定義的系統程序,例如
sp_executeSql,或是使用 DLL 而不是 Transact-SQL 陳述式定義的xp_cmdshell。 快取的結構只包含程序實作的函式名稱與 DLL 名稱。
SQL Server 執行計畫具有下列主要元件:
已編譯計畫 (或查詢計畫)
編譯程序產生的查詢計畫,大多是可重複使用的唯讀資料結構,可供任意數量的使用者使用。 該計畫會儲存下列資訊:執行內容
目前執行查詢的每位使用者都有資料結構,其中保存了與其執行相關的特定資料,例如參數值。 此資料結構即稱為執行內容。 執行內容資料結構會重複使用,但內容不會。 若其他使用者執行相同的查詢,將會為新使用者的內容重新初始化資料結構。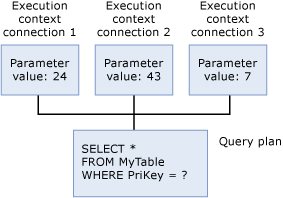
在 SQL Server 中執行任何 Transact-SQL 陳述式時,資料庫引擎會先尋找整個計畫快取,以確認相同 Transact-SQL 陳述式的現有執行計畫是否存在。 如果 Transact-SQL 陳述式與先前以快取計畫執行的 Transact-SQL 陳述式完全相符 (一字不差),則符合存在的定義。 如果 SQL Server 找到任何現有的計畫便會重複使用,如此可省下重新編譯 Transact-SQL 陳述式的負擔。 如果執行計畫不存在,SQL Server 會為查詢產生新的執行計畫。
注意
部分 Transact-SQL 陳述式的執行計畫不會保存在計畫快取中,例如對資料列存放區執行的大量作業陳述式,或包含大於 8 KB 字串常值的陳述式。 這些計畫只會存在於查詢執行過程之中。
SQL Server 有一個非常有效率的演算法,可為任何特定 Transact-SQL 陳述式尋找任何現有的執行計畫。 在大部分的系統中,這個掃描所使用的最少資源,比能夠重複使用現有計畫來取代編譯每個 Transact-SQL 陳述式所節省下來的資源還少。
此演算法要能比對新的 Transact-SQL 陳述式與現有的陳述式,計畫快取中未使用執行計畫的所有物件參考都必須完整。 例如,假設對於執行以下 Person 陳述式的使用者,SELECT 是預設結構描述。 但是在此範例中,Person 不需要是完整的,這表示第二個陳述式與現有的計畫不相符合,但第三個是相符合的:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
變更指定執行的下列任何 SET 選項,將會影響重複使用計畫的能力。這是因為資料庫引擎會執行常數摺疊,而這些選項將會影響這類運算式的結果:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
為相同的查詢快取多個計畫
查詢與執行計畫在資料庫引擎中都是獨一無二的,與指紋非常類似:
- 查詢計畫雜湊是針對指定查詢之執行計畫計算所得的二進位雜湊值,可用於專門識別類似的執行計畫。
- 查詢雜湊是針對 Transact-SQL 查詢文字計算所得的二進位雜湊值,可用於專門識別查詢。
您可以使用計畫控制代碼,從計畫快取中擷取經過編譯的計畫,但該代碼只是暫時性識別碼,只在計畫仍保留在快取中時,才會保持不變。 計畫控制代碼是從整個批次中經過編譯之計畫衍生而來的雜湊值。 即使在批次中有一或多個陳述式重新編譯,經過編譯之計畫的計畫控制代碼仍維持不變。
注意
若是針對批次編譯計畫,而不是針對單一陳述式,可以使用計畫控制代碼與陳述式位移,擷取批次中個別陳述式的計畫。
sys.dm_exec_requests DMV 包含每一筆記錄的 statement_start_offset 與 statement_end_offset 資料行,而這些記錄會參考目前正在執行之批次或保存物件目前正在執行的陳述式。 如需詳細資訊,請參閱 sys.dm_exec_requests (Transact-SQL)。
sys.dm_exec_query_stats DMV 也包含每一筆記錄的這些資料行,而這些記錄會參考批次中的陳述式位置或保存物件的位置。 如需詳細資訊,請參閱 sys.dm_exec_query_stats (Transact-SQL)。
批次的實際 Transact-SQL 文字會儲存在計畫快取的個別記憶體空間中,稱為 SQL 管理員快取 (SQLMGR)。 您可以使用 SQL 控制代碼,從 SQL 管理員快取中擷取已編譯計畫的 Transact-SQL 文字。這是暫時性的識別碼,只在計畫快取中至少有一個計畫仍在參考該代碼時,才會保持不變。 SQL 控制代碼是從整個批次文字衍生而來的雜湊值,而且在每個批次都是獨一無二。
注意
正如經過編譯的計畫,每個批次的 Transact-SQL 文字包括註解在內,均會加以儲存。 SQL 控制代碼包括整個批次文字的 MD5 雜湊值,而且在每個批次都是獨一無二。
下列查詢提供 SQL 管理員快取之記憶體使用量的相關資訊:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
SQL 控制代碼與計畫控制代碼之間存在 1:N 的關聯性。 當經過編譯之計畫的快取索引鍵不同時,就會出現此情況。 若同一批次在兩次執行時 SET 選項有所變更,就可能會出現此情況。
請考慮下列預存程序:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
您可以使用下列查詢,確認可以在計畫快取中找到的內容:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
以下為結果集。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
現在,請使用不同的參數執行預存程序,但不變更執行內容:
EXEC usp_SalesByCustomer 8
GO
再次確認可以在計畫快取中找到的內容。 以下為結果集。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
請注意,usecounts 已增加至 2。這表示因為重複使用了執行內容資料結構,所以重複使用了相同內容的快取計畫。 現在,請變更 SET ANSI_DEFAULTS 選項,並使用相同的參數執行預存程序。
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
再次確認可以在計畫快取中找到的內容。 以下為結果集。
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
請注意,現在 sys.dm_exec_cached_plans DMV 輸出中有兩個項目:
usecounts資料行顯示第一筆記錄中1的值,這是使用SET ANSI_DEFAULTS OFF執行一次的計畫。usecounts資料行顯示第二筆記錄中2的值,這是使用SET ANSI_DEFAULTS ON執行的計畫,因為其執行了兩次。- 不同的
memory_object_address指向計畫快取中的不同執行計畫項目。 但這兩個項目因為參考了同一批次,所以兩者的sql_handle值都相同。- 執行設定為 OFF 的
ANSI_DEFAULTS有一個新的plan_handle,而且可以重複用於呼叫具有相同 SET 選項集合。 由於執行內容已因為 SET 選項的變更而重新初始化,所以需要新的計畫控制代碼。 這並不會觸發重新編譯:由同一query_plan_hash及query_hash值可證,這兩個項目都會參考相同的計畫與查詢。
- 執行設定為 OFF 的
實際上,這表示在快取中我們會有兩個計畫項目對應到至相同的批次,顯示確認會對 SET 選項造成影響的計畫快取相同十分重要,當重複執行相同的查詢時,須最佳化以利計畫重複使用,以及將計畫快取大小維持在其所需的最小值。
提示
常見的缺點是,不同的用戶端可能會有不同的 SET 選項預設值。 例如,透過 SQL Server Management Studio 所建立的連線,會自動將 QUOTED_IDENTIFIER 設定為 ON,而 SQLCMD 會將 QUOTED_IDENTIFIER 設定為 OFF。 從這兩個用戶端執行相同的查詢,將會產生多個計畫 (如上述範例所述)。
從計畫快取中移除執行計畫
只要記憶體足以存放執行計畫,執行計畫就會保留在計畫快取中。 當記憶體壓力存在時,SQL Server 資料庫引擎就會使用以成本為基礎的方法,來判斷要從計畫快取中移除哪些執行計畫。 為了進行以成本為基礎的決策,SQL Server 資料庫引擎會根據下列因素,針對每個執行計畫增加和減少目前的成本變數。
當使用者處理序將執行計畫插入快取時,該使用者處理序會將目前的成本設定為等於原始查詢編譯成本。若為特定執行計畫,使用者處理序則會將目前成本設定為零。 因此,使用者程序參考每次執行計畫時,都會將目前成本重設為原始編譯成本;如果是特定執行計畫,使用者程序會增加目前成本。 對於所有計畫而言,目前成本的最大值就是原始編譯成本。
當記憶體壓力存在時,SQL Server 資料庫引擎會從計畫快取中移除執行計畫,藉此進行回應。 為了判斷要移除哪些計畫,SQL Server 資料庫引擎會重複檢查每個執行計畫的狀態,然後移除目前成本為零的計畫。 如果存在記憶體壓力,系統不會自動移除目前成本為零的執行計畫。只有當 SQL Server 資料庫引擎檢查計畫並發現目前成本為零時,才會移除此計畫。 檢查執行計畫時,如果查詢目前未使用該計畫,SQL Server 資料庫引擎就會減少目前成本,藉此將目前成本推向零。
SQL Server 資料庫引擎會重複檢查執行計畫,直到移除足夠的計畫,可滿足記憶體需求為止。 當記憶體壓力存在時,執行計畫可能會多次增加和減少其成本。 在記憶體壓力解除後,SQL Server 資料庫引擎就會停止減少未使用之執行計畫的目前成本,而所有執行計畫都會保留在計畫快取中,即使其成本為零也一樣。
為了回應記憶體壓力,SQL Server 資料庫引擎會使用資源監視器和使用者背景工作執行緒來釋放計畫快取中的儲存體。 資源監視器和使用者背景工作執行緒可以檢查計畫並同時執行,以便針對每個未使用的執行計畫減少目前成本。 當全域記憶體壓力存在時,資源監視器就會從計畫快取中移除執行計畫。 它會釋放記憶體,以便強制執行系統儲存體、處理序記憶體、資源集區記憶體和所有快取大小上限的原則。
所有快取大小上限是緩衝集區大小的函數,而且不能超過伺服器儲存體的最大值。 如需設定最大伺服器儲存體的詳細資訊,請參閱 max server memory 中的 sp_configure 設定。
當單一快取記憶體壓力存在時,使用者背景工作執行緒就會從計畫快取中移除執行計畫。 它們會強制執行最大單一快取大小和最大單一快取項目的原則。
下列範例說明要從計畫快取中移除哪些執行計畫:
- 執行計畫經常被參考,所以它的成本永遠都不會變成零。 計畫依然在計畫快取中,而且除非有記憶體壓力且目前成本為零,否則不會移除計畫。
- 系統會插入特定執行計畫,但在記憶體壓力存在之前,不會再次參考該計畫。 由於特定計畫會以目前成本為零來初始化,所以當 SQL Server 資料庫引擎檢查執行計畫時,將會看到目前成本為零,並從計畫快取中移除此計畫。 當記憶體壓力不存在時,特定執行計畫會留在計畫快取中,且目前成本為零。
若要手動從快取中移除單一計畫或所有計畫,請使用 DBCC FREEPROCCACHE。 DBCC FREESYSTEMCACHE 也可用來清除任何快取,包括計畫快取。 從 SQL Server 2016 (13.x) 開始,ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE 可清除範圍中資料庫的程序 (計畫) 快取。
透過 sp_configure 和 reconfigure 變更部分組態設定也會導致從計畫快取中移除方案。 您可在 DBCC FREEPROCCACHE 一文其<備註>一節中找到這些組態設定的清單。 這類組態變更會將下列資訊訊息記錄在錯誤記錄檔中:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
重新編譯執行計畫
資料庫的特定變更可能會導致執行計畫沒有效率或無效,端視資料庫的新狀態而定。 SQL Server 會偵測讓執行計畫失效的變更並將該計畫標示為無效。 然後系統會根據執行查詢的下一個連接,重新編譯新的計畫。 會使計畫無效的狀況包括:
- 對查詢所參考之資料表或檢視表所做的變更 (
ALTER TABLE和ALTER VIEW)。 - 對單一程序所做的變更,此程序會從快取中卸除該程序的所有計畫 (
ALTER PROCEDURE)。 - 對執行計畫所使用之任何索引所做的變更。
- 對執行計畫所使用之統計資料的更新,這些更新是由
UPDATE STATISTICS之類的陳述式明確產生或自動產生的。 - 卸除執行計畫所使用的索引。
- 明確呼叫
sp_recompile。 - 對索引鍵所做的大量變更 (由
INSERT或DELETE陳述式所產生,而這類陳述式是來自其他修改查詢所參考之資料表的使用者)。 - 對於含有觸發程序的資料表,是指插入或刪除資料表中的資料列數目有顯著增加的情況。
- 使用
WITH RECOMPILE選項執行預存程序。
不管是為了讓陳述式正確或是要取得可能更快的查詢執行計畫,多數的重新編譯都是必要的。
在 2005 版之前的 SQL Server 版本中,每當批次內的陳述式導致重新編譯時,無論整個批次是透過預存程序、觸發程序、臨機操作批次或準備陳述式所送出,都會重新編譯。 從 SQL Server 2005 (9.x) 開始,只有觸發重新編譯之批次內的陳述式才會重新編譯。 此外,由於 SQL Server 2005 (9.x) 和更新版本已擴充其功能集,因此包含其他類型的重新編譯。
陳述式層級的重新編譯有益於效能,因為在大部分情況下,只有少量的陳述式會導致重新編譯並造成相關負面影響,也就是 CPU 時間及鎖定。 批次中不必重新編譯的其他陳述式則可避免這些負面影響。
sql_statement_recompile 擴充事件 (xEvent) 會報告陳述式層級重新編譯。 當任何類型的批次需要陳述式層級重新編譯時,就會發生此 xEvent。 這包括預存程序、觸發程序、特定批次和查詢。 批次可透過數種介面提交,包括 sp_executesql、動態 SQL、Prepare 方法或 Execute 方法。
sql_statement_recompile xEvent 的 recompile_cause 資料行包含一個整數碼,可指出重新編譯的原因。 下表包含可能的原因:
結構描述已變更
統計資料已變更
延遲編譯
SET 選項已變更
暫存資料表已變更
遠端資料列集已變更
FOR BROWSE 權限已變更
查詢通知環境已變更
資料分割檢視已變更
資料指標選項已變更
OPTION (RECOMPILE) 要求的
參數化計畫已排清
影響資料庫版本的計畫已變更
強制執行查詢存放區計畫原則已變更
強制執行查詢存放區計畫失敗
查詢存放區遺漏計畫
注意
在沒有 xEvents 可用的 SQL Server 版本中,可以針對報告陳述式層級重新編譯的相同目的,使用 SQL Server Profiler SP:Recompile 追蹤事件。
追蹤事件 SQL:StmtRecompile 也會報告陳述式層級重新編譯,而且此追蹤事件也可用來追蹤及偵錯重新編譯。
SP:Recompile 只能針對預存程序及觸發程序來產生;相較之下,SQL:StmtRecompile 可針對預存程序、觸發程序、特定批次、使用 sp_executesql 執行的批次、準備查詢及動態 SQL 來產生。
SP:Recompile 和 SQL:StmtRecompile 的 EventSubClass 資料行包含一個整數碼,可指出重新編譯的原因。 程式碼的說明請參閱這裡。
注意
當 AUTO_UPDATE_STATISTICS 資料庫選項設定為 ON 時,若其目標資料表或索引檢視表的統計資料或基數明顯和上次執行不同時,就會重新編譯查詢。
此行為適用於標準使用者定義的資料表、暫存資料表,以及 DML 觸發程序所建立的插入和刪除資料表。 如果過多的重新編譯影響了查詢效能,請考慮將此設定值變更為 OFF。 當 AUTO_UPDATE_STATISTICS 資料庫選項設定為 OFF 時,就不會基於統計資料或基數變更發生重新編譯,但 DML INSTEAD OF 觸發程序所建立的插入和刪除資料表例外。 因為這些資料表是在 tempdb 中建立的,所以存取它們的查詢是否要重新編譯,取決於 tempdb 中 AUTO_UPDATE_STATISTICS 的設定。
在 SQL Server 2005 之前,即使此設定為 OFF,還是會繼續根據 DML 觸發程序插入和刪除資料表的基數變更來重新編譯查詢。
參數和執行計畫的重複使用
參數的使用,包括 ADO、OLE DB、和 ODBC 應用程式中的參數標記,可以增加執行計畫的重複使用。
警告
相較於將值串連到字串,然後使用資料存取 API 方法、 EXECUTE 陳述式或 sp_executesql 預存程序來執行該字串,比較安全的方式是使用參數或參數標記來保留使用者輸入的值。
下列這兩個 SELECT 陳述式的唯一差異在於 WHERE 子句中所比較的值:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
這些查詢執行計畫間的唯一差異是用來比較 ProductSubcategoryID 資料行所儲存的值。 雖然目標是要讓 SQL Server 能一直意識到陳述式基本上產生的都是相同計畫,並重複使用這些計畫,但有時 SQL Server 在複雜的 Transact-SQL 陳述式中無法偵測到這種情況。
利用參數將 Transact-SQL 陳述式中的常數分離出來,可以幫助關聯式引擎識別重複的計畫。 您可以使用以下方式來使用參數:
在 Transact-SQL 中,使用
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParm建議針對 Transact-SQL 指令碼、預存程序或動態產生 SQL 陳述式的觸發程序使用此方法。
ADO、OLE DB、和 ODBC 使用參數標記。 參數標記是取代 SQL 陳述式中常數的問號 (?),這些標記將繫結至程式變數。 例如,您可以在 ODBC 應用程式中執行下列動作:
使用
SQLBindParameter,將整數變數繫結到 SQL 陳述式中的第一個參數標記。在變數中放入整數值。
執行陳述式,指定參數標記 (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
在應用程式中使用參數標記時,SQL Server 所包含的 SQL Server Native Client OLE DB 提供者和 SQL Server Native Client ODBC 驅動程式,都會使用
sp_executesql,將陳述式傳送至 SQL Server。設計預存程序,按設計來使用參數。
如果您未明確在應用程式設計中建置參數,也可以仰賴 SQL Server 查詢最佳化工具,利用簡單參數化的預設行為,自動將特定查詢參數化。 另外,您也可以強制查詢最佳化工具考慮將資料庫中的所有查詢參數化,方式是將 ALTER DATABASE 陳述式的 PARAMETERIZATION 選項設為 FORCED。
啟用強制參數化之後,仍會發生簡單參數化。 例如,根據強制參數化的規則,下列查詢無法參數化:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
不過,可根據簡單參數化規則將它參數化。 如果強制參數化嘗試失敗,後續仍會嘗試簡單參數化。
簡單參數化
在 SQL Server 的 Transact-SQL 陳述式中使用參數或參數標記時,有助於關聯式引擎將新的 Transact-SQL 陳述式與先前編譯的現有執行計畫進行配對。
警告
相較於將值串連到字串,然後使用資料存取 API 方法、 EXECUTE 陳述式或 sp_executesql 預存程序來執行該字串,比較安全的方式是使用參數或參數標記來保留使用者輸入的值。
如果在不使用參數的情況下執行 Transact-SQL 陳述式,SQL Server 就會在內部將此陳述式參數化,以增加與現有執行計畫配對的可能性。 此處理序即稱為簡單參數化。 在 2005 版之前的 SQL Server 版本中,此處理序指的就是自動參數化。
請參考這個陳述式:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
在陳述式尾端的數值 1,可以指定成參數。 關聯式引擎會建立此批次的執行計畫,就像已經指定參數來取代值 1 一樣。 由於這個簡單參數化的緣故,SQL Server 可辨識下列兩個陳述式基本上會產生相同的執行計畫,並重複使用第二個陳述式的第一個計畫:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
在處理複雜的 Transact-SQL 陳述式時,關聯式引擎可能會無法判斷哪個運算式可以參數化。 若要提升關聯式引擎將複雜 Transact-SQL 陳述式與現有、未使用之執行計畫配對的能力,請使用 sp_executesql 或參數標記明確指定參數。
注意
使用 +、-、*、/ 或 % 等算術運算子來將 int、smallint、tinyint 或 bigint 常數值隱含或明確轉換為 float、real、decimal 或 numeric 資料類型時,SQL Server 會套用特定的規則來計算運算式結果的類型與有效位數。 不過,這些規則會隨著查詢是否參數化而有所不同。 因此,在某些情況下,查詢中類似的運算式可能會產生不同的結果。
在簡單參數化的預設行為下,SQL Server 可將相對較小的查詢類別參數化。 不過,您可以藉由將 PARAMETERIZATION 命令的 ALTER DATABASE 選項設為 FORCED,來指定資料庫中所有查詢都會依據特定限制進行參數化。 這麼做可降低查詢編譯的頻率,進而改善經歷大量並行查詢的資料庫效能。
此外,您可以指定單一查詢,以及任何其他語法相同但唯有參數值不同的查詢,使其進行參數化。
提示
使用 Entity Framework (EF) 等物件關聯式對應 (ORM) 解決方案時,手動 LINQ 查詢樹狀結構或特定原始 SQL 查詢等應用程式查詢可能不會進行參數化,這會影響計畫的重複使用以及追蹤查詢存放區中查詢的能力。 如需詳細資訊,請參閱 EF 查詢快取和參數化和 EF 原始 SQL 查詢。
強制參數化
您可以藉由指定將資料庫中所有的 SELECT、 INSERT、 UPDATE及 DELETE 陳述式依據特定限制進行參數化,以覆寫 SQL Server 預設的簡單參數化行為。 您可以藉由將 PARAMETERIZATION 陳述式中的 FORCED 選項設為 ALTER DATABASE ,來啟用強制參數化。 強制參數化可藉由降低查詢編譯與重新編譯的頻率,來增進特定資料庫的效能。 可經由強制參數化獲益的資料庫通常會有來自來源 (如銷售點應用程式) 的大量並行查詢。
將 PARAMETERIZATION 選項設為 FORCED時,出現在 SELECT、 INSERT、 UPDATE或 DELETE 陳述式中且以任何形式提交的所有常值,都會在查詢編譯期間轉換為參數。 但出現於下列查詢結構中的常值則為例外:
INSERT...EXECUTE陳述式。- 位於預存程序、觸發程序或使用者自訂函數主體中的陳述式。 SQL Server 已經會重複使用這些常式的查詢計畫。
- 已在用戶端應用程式上完成參數化的準備陳述式。
- 含有 XQuery 方法呼叫的陳述式,其方法會出現在引數通常已參數化的內容中,如
WHERE子句。 若此方法出現在引數未參數化的內容中,則該陳述式的其他部分會進行參數化。 - 位於 Transact-SQL 資料指標內的陳述式 (API 資料指標內的
SELECT陳述式會進行參數化)。 - 被取代的查詢結構。
- 將在
ANSI_PADDING或ANSI_NULLS內容中執行的任何陳述式設為OFF。 - 包含超過 2,097 個可參數化之常值的陳述式。
- 參考變數的陳述式,如
WHERE T.col2 >= @bb。 - 含有
RECOMPILE查詢提示的陳述式。 - 含有
COMPUTE子句的陳述式。 - 含有
WHERE CURRENT OF子句的陳述式。
另外,下列查詢子句不會參數化。 在這些情況下,只有子句不會參數化。 相同查詢內的其他子句可進行強制參數化。
- 任何
SELECT陳述式的 <select_list>。 這包括子查詢的SELECT清單和INSERT陳述式內的SELECT清單。 - 出現在
SELECT陳述式內的子查詢IF陳述式。 - 查詢的
TOP、TABLESAMPLE、HAVING、GROUP BY、ORDER BY、OUTPUT...INTO或FOR XML子句。 - 傳送至
OPENROWSET、OPENQUERY、OPENDATASOURCE、OPENXML或任何FULLTEXT運算子的引數 (直接或做為子運算式)。 LIKE子句的 pattern 和 escape_character 引數。CONVERT子句的 style 引數。IDENTITY子句中的整數常數。- 使用 ODBC 延伸語法指定的常數。
- 可摺疊常數的運算式,其為
+、-、*、/和%運算子的引數。 考量是否可進行強制參數化時,若符合下列其中一項條件,SQL Server 就會認定運算式為可摺疊常數的:- 運算式中未出現資料行、變數或子查詢。
- 運算式包含
CASE子句。
- 查詢提示子句的引數。 這些包括
FAST查詢提示的 number_of_rows 引數、MAXDOP查詢提示的 number_of_processors 引數和MAXRECURSION查詢提示的 number 引數。
參數化會發生在個別 Transact-SQL 陳述式層級上。 換句話說,批次中的個別陳述式會進行參數化。 編譯之後,參數化查詢會在最初提交查詢的批次內容中執行。 若已快取查詢的執行計畫,即可藉由參考 sys.syscacheobjects 動態管理檢視表的 sql 資料行,來判斷查詢是否已參數化。 若查詢已參數化,則此資料行中參數的名稱與資料類型會顯示在提交批次的文字之前,如 (@1 tinyint)。
注意
參數名稱可以是任意的名稱。 使用者或應用程式不應依賴特定的命名順序。 而且,可以在 SQL Server 版本和 Service Pack 升級之間變更下列各項:參數名稱、已參數化的常值選項,以及參數化文字的間距。
參數的資料類型
當 SQL Server 將常值參數化時,參數會轉換為下列資料類型:
- 將以其他方式調整大小以符合 int 資料類型的整數常值會參數化為 int。屬於含有任何比較運算子述詞的較大整數常值 (包括
<、<=、=、!=、>、>=、!<、!>、<>、ALL、ANY、SOME、BETWEEN和IN) 會參數化為 numeric(38,0)。 較大的常值如果不屬於含有比較運算子的述詞,將會參數化為 numeric,其有效位數夠大正好足以支援其大小,而其小數位數為 0。 - 屬於含有比較運算子之述詞的固定點數值常值會參數化為 numeric,其有效位數為 38,而其小數位數夠大正好足以支援其大小。 固定點數值常值如果不屬於含有比較運算子的述詞,將會參數化為 numeric,其有效位數與小數位數夠大正好足以支援其大小。
- 浮點數值常值會參數化為 float(53)。
- 如果非 Unicode 字串常值可容納於 8,000 個字元中,即會參數化為 varchar(8000),如果該常值大於 8,000 個字元,則會參數化為 varchar(max)。
- 如果 Unicode 字串常值可容納於 4,000 個 Unicode 字元中,即會參數化為 nvarchar(4000),如果該常值大於 4,000 個字元,則會參數化為 nvarchar(max)。
- 如果二進位常值可容納於 8,000 個位元組中,就會參數化為 varbinary(8000)。 如果該常值大於 8,000 個位元組,就會轉換為 varbinary(max)。
- Money 類型常值會參數化為 money。
強制參數化的使用指南
將 PARAMETERIZATION 選項設為 FORCED 時,請考量下列事項:
- 強制參數化一旦生效後,會在編譯查詢時將查詢中的常值 (常數) 變更為參數。 因此,查詢最佳化工具可能會選擇到次佳的查詢計畫。 特別是,查詢最佳化工具較不可能比對查詢與索引檢視或計算資料行上的索引。 它也可會為資料分割資料表與分散式資料分割檢視上的查詢選擇次佳的計畫。 針對非常依賴索引檢視或計算資料行上索引的環境,就不應該使用強制參數化。 一般而言,應由具有經驗的資料庫管理員判斷
PARAMETERIZATION FORCED選項的執行不會對效能造成不良影響後,才能使用此選項。 - 只要在查詢執行之內容所屬的資料庫中,將
PARAMETERIZATION選項設為FORCED,參考多個資料庫的分散式查詢即能使用強制參數化。 - 將
PARAMETERIZATION選項設為FORCED,就會從資料庫的計畫快取中排清所有查詢計畫,但目前正在編譯、重新編譯或執行的計畫除外。 在設定變更期間編譯或執行的查詢計畫,會在下次執行查詢時進行參數化。 - 設定
PARAMETERIZATION選項是不需要資料庫層級獨佔鎖定的線上作業。 - 重新附加或還原資料庫時,會保留
PARAMETERIZATION選項目前的設定。
您可以指定在單一查詢以及語法上相同但只有其參數值不同的查詢嘗試簡單參數化,以覆寫強制參數化的行為。 反之,您可以指定只在一組語法相同的查詢嘗試強制參數化,即使資料庫中已停用強制參數化。 此即為計畫指南 的用途。
注意
將 PARAMETERIZATION 選項設為 FORCED 時,錯誤訊息的報告可能會與 PARAMETERIZATION 選項設為 SIMPLE 時不同:強制參數化下可能報告了多個錯誤訊息,簡單參數化下報告的訊息則較少,而發生錯誤的行號可能未正確回報。
準備 SQL 陳述式
SQL Server 關聯式引擎在執行 Transact-SQL 陳述式之前,會先導入準備陳述式的完整支援。 如果應用程式需要執行 Transact-SQL 陳述式數次,則可以使用資料庫 API 來執行下列動作:
- 準備一次陳述式。 這可將 Transact-SQL 陳述式編譯成執行計畫。
- 在每次需要執行陳述式時,執行先行編譯的執行計畫。 這樣在第一次執行後,就不必在每次執行時重新編譯 Transact-SQL 陳述式。 準備和執行陳述式是由 API 函數和方法所控制。 這不屬於 Transact-SQL 語言。 SQL Server Native Client OLE DB 提供者和 SQL Server Native Client ODBC 驅動程式支援執行 Transact-SQL 陳述式的準備/執行模型。 在準備要求中,提供者或驅動程式可搭配準備陳述式的要求來將陳述式傳送到 SQL Server。 SQL Server 會編譯執行計畫,並將該計畫的控制代碼傳回給提供者或驅動程式。 當產生執行要求時,提供者或驅動程式會將要求傳給伺服器,以執行與控制代碼相關聯的計畫。
準備陳述式無法用來在 SQL Server 上建立暫存物件。 準備陳述式也無法參考可建立暫存物件 (如暫存資料表) 的系統預存程序。 這些程序必須直接執行。
過度使用準備/執行模型會降低效能。 如果陳述式只執行一次,則直接執行只需要一次網路往返到伺服器。 如果先準備再執行只執行一次的 Transact-SQL 陳述式,便需要多一次網路往返:一次用來準備陳述式,一次用來執行陳述式。
如果使用參數標記,則準備陳述式會更有效率。 例如,假設應用程式偶爾會被要求從 AdventureWorks 範例資料庫擷取產品資訊。 應用程式有兩種方式可以達成此目的。
使用第一種方式,應用程式可以針對所要求的每個產品執行不同的查詢。
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
使用第二種方式,應用程式會執行下列動作:
準備含有參數標記 (?) 的陳述式:
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;繫結程式變數與參數標記。
每次需要產品資訊時,以索引鍵值填入繫結變數,然後執行陳述式。
如果陳述式執行超過三次以上,則使用第二種方式會比較有效率。
在 SQL Server 中,由於 SQL Server 重複使用執行計畫的方式,讓準備/執行模型相較於直接執行並無任何顯著的優勢。 SQL Server 可提供有效率的演算法,用以配對目前的 Transact-SQL 陳述式以及先前產生用來執行相同 Transact-SQL 陳述式的執行計畫。 如果應用程式多次執行具有參數標記的 Transact-SQL 陳述式,則 SQL Server 將自第一次執行之後,在第二次及後續執行中重複使用執行計畫 (除非計畫快取中的計畫過期)。 但準備/執行模型仍然具有以下優點:
- 利用識別代碼來尋找執行計畫,比用演算法來使 Transact-SQL 陳述式與現有執行計畫相符更具效率。
- 應用程式可以控制何時建立及重複使用執行計畫。
- 準備/執行模型可以移至其他資料庫使用,包括舊版的 SQL Server。
參數敏感度
參數敏感度 (也稱為「參數探測」) 指的是 SQL Server 在編譯或重新編譯期間「探查」目前的參數值,然後將其傳遞給查詢最佳化工具,以便用來產生可能更有效率的查詢執行計畫。
在編譯或重新編譯期間會探查下列批次類型的參數值:
- 預存程序
- 透過
sp_executesql提交的查詢 - 準備查詢
如需針對不佳參數探查問題進行疑難排解的資訊,請參閱:
- 調查並解決參數敏感性問題
- 參數和執行計畫的重複使用
- 參數敏感性計畫最佳化
- 針對 Azure SQL Database 中包含參數區分查詢執行計畫問題的查詢進行疑難排解
- 針對 Azure SQL 受控執行個體中包含參數區分查詢執行計畫問題的查詢進行疑難排解
注意
若是使用 RECOMPILE 提示的查詢,則會探查參數值和區域變數的目前值。 探查到的值 (參數和區域變數值) 是存在於批次中具有 RECOMPILE 提示的陳述式之前位置的值。 特別是對於參數,不會探查批次引動過程呼叫隨附的值。
平行查詢處理
SQL Server 提供平行查詢,讓擁有多個處理器 (CPU) 的電腦也能獲得最佳的查詢執行和索引作業。 由於 SQL Server 可利用數個作業系統背景工作執行緒平行執行查詢或索引作業,因此能快速且有效率地完成作業。
在查詢最佳化期間,SQL Server 會搜尋可能受益於平行執行的查詢或索引作業。 對於這些查詢,SQL Server 會在查詢執行計畫中插入交換運算子,以準備平行執行的查詢。 所謂的交換運算子,是指查詢執行計畫中,提供存取管理、資料重新散佈以及流量控制的運算子。 交換運算子包括當做子類型的 Distribute Streams、 Repartition Streams及 Gather Streams 邏輯運算子,其中的一或多個可以出現在平行查詢之查詢計畫的執行程序表輸出中。
重要
某些建構會禁止 SQL Server 在整個或部分的執行計畫上使用平行處理原則。
禁止平行處理原則的建構包括:
純量 UDF
如需有關純量使用者定義函式的詳細資訊,請參閱建立使用者定義函式。 從 SQL Server 2019 (15.x) 開始,SQL Server 資料庫引擎能夠內嵌這些函數,並且已能在查詢處理期間使用平行處理原則。 如需內嵌純量 UDF 的詳細資訊,請參閱 SQL 資料庫中的智慧型查詢處理。遠端查詢
如需遠端查詢的詳細資訊,請參閱執行程序表邏輯和實體運算子參考。動態資料指標
如需資料指標的詳細資訊,請參閱 DECLARE CURSOR。遞迴查詢
如需遞迴的詳細資訊,請參閱定義和使用遞迴通用資料表運算式的方針和 T-SQL 中的遞迴。多重陳述式資料表值函式 (MSTVF)
如需 MSTVF 的詳細資訊,請參閱建立使用者定義函式 (資料庫引擎)。TOP 關鍵字
如需詳細資訊,請參閱 TOP (Transact-SQL)。
查詢執行計畫可能會在 QueryPlan 元素中包含 NonParallelPlanReason 屬性,用以描述未使用平行處理原則的原因。 適用於此屬性的值包括:
| NonParallelPlanReason 值 | 描述 |
|---|---|
| MaxDOPSetToOne | 平行處理原則的最大程度設定為 1。 |
| EstimatedDOPIsOne | 平行處理原則的估計程度設定為 1。 |
| NoParallelWithRemoteQuery | 平行處理原則不支援遠端查詢。 |
| NoParallelDynamicCursor | 平行計畫不支援動態資料指標。 |
| NoParallelFastForwardCursor | 平行計畫不支援向前快轉資料指標。 |
| NoParallelCursorFetchByBookmark | 平行計畫不支援依書籤擷取的資料指標。 |
| NoParallelCreateIndexInNonEnterpriseEdition | 平行索引建立不支援非 Enterprise 版本。 |
| NoParallelPlansInDesktopOrExpressEdition | 平行計畫不支援 Desktop 和 Express 版本。 |
| NonParallelizableIntrinsicFunction | 查詢正在參考不可平行的內建函式。 |
| CLRUserDefinedFunctionRequiresDataAccess | 平行處理原則不支援需要資料存取的 CLR UDF。 |
| TSQLUserDefinedFunctionsNotParallelizable | 查詢正在參考不可平行的 T-SQL 使用者定義函數。 |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | 資料表變數交易不支援平行巢狀交易。 |
| DMLQueryReturnsOutputToClient | DML 查詢將輸出傳回用戶端且不可平行。 |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | 針對單一線上索引組建之不支援的序列和平行計畫混合。 |
| CouldNotGenerateValidParallelPlan | 驗證平行計畫已失敗,正在容錯回復至序列。 |
| NoParallelForMemoryOptimizedTables | 平行處理原則不支援參考的記憶體內部 OLTP 資料表。 |
| NoParallelForDmlOnMemoryOptimizedTable | 平行處理原則不支援記憶體內部 OLTP 資料表上的 DML。 |
| NoParallelForNativelyCompiledModule | 平行處理原則不支援參考的原生編譯模組。 |
| NoRangesResumableCreate | 針對可繼續之 Create 作業的範圍產生失敗。 |
插入交換運算子之後,結果便是平行查詢執行計畫。 平行查詢執行計畫可以使用一個以上的背景工作執行緒。 非平行 (序列) 查詢使用的序列執行計畫,在執行時只會使用一個背景工作執行緒。 平行查詢實際所使用的背景工作執行緒數目,是在查詢計畫執行初始化時,由計畫的複雜度與平行處理原則的程度決定。
平行處理原則的程度 (DOP) 決定所要使用的 CPU 數目上限,而不是所要使用的背景工作執行緒數。 DOP 限制的設定以工作為準。 它不是根據要求或查詢限制。 這表示在平行查詢執行期間,單一要求可能會繁衍指派至排程器的多個工作。 當有不同工作同時執行時,將能在任何指定的查詢執行點,同時使用多於 MAXDOP 所指定的處理器數量。 如需詳細資訊,請參閱執行緒與工作結構指南。
如果符合下列任一個條件,SQL Server 查詢最佳化工具就不會使用平行執行計畫進行查詢:
- 序列執行計畫很單純,或未超過平行處理原則設定的成本閾值。
- 序列執行計畫的總估計樹狀子目錄成本,低於最佳化工具所探索的任何平行執行計畫。
- 此查詢包含無法平行執行的純量或關聯式運算子。 特定運算子可能造成查詢計畫的一個區段以序列模式執行,或整個計畫以序列模式執行。
注意
平行計畫的總估計樹狀子目錄成本可能會低於平行處理原則設定的成本閾值。 這表示序列計畫的總估計樹狀子目錄成本更高,且系統已選擇總估計樹狀子目錄成本較低的查詢計畫。
平行處理原則的程度 (DOP)
SQL Server 會針對平行查詢執行或索引資料定義語言 (DDL) 作業的每一個執行個體,自動偵測平行處理原則的最佳程度。 其作法是依據下列條件:
SQL Server 是否正在具有多個微處理器或 CPU 的電腦上執行,例如對稱式多處理的電腦 (SMP)。 具有一個以上 CPU 的電腦,才能使用平行查詢。
是否有足夠的背景工作執行緒可以使用。 每一個查詢或索引作業都需要某個數目的背景工作執行緒來執行。 執行平行計畫所需的背景工作執行緒會比執行序列計畫還多,而且所需的背景工作執行緒數目會隨著平行處理原則的程度增加。 當無法滿足平行處理原則特定程度的平行計畫背景工作執行緒需求時,SQL Server 資料庫引擎就會自動降低平行處理原則的程度,或是完全放棄指定工作負載內容中的平行計畫。 然後,它會執行序列計畫 (一個背景工作執行緒)。
已執行之查詢或索引作業的類型。 建立或重建索引,或是卸除叢集索引的索引作業,以及大量使用 CPU 循環的查詢,最適合使用平行計畫。 例如,聯結大型資料表、大型彙總及排序大型結果集,皆適用於平行計畫。 經常在交易處理應用程式中發現的簡單查詢,會尋找執行平行查詢時所需的其他協調作業,此平行查詢比潛在的效能提升更為重要。 為了區分能否從平行處理原則中獲益的查詢,SQL Server 資料庫引擎會比較執行查詢或索引作業的預估成本與平行處理原則的成本閾值。 如果適當測試發現不同的值更適合執行的工作負載,使用者可以使用 sp_configure 來變更預設值 5。
要處理的資料列數量是否足夠。 如果查詢最佳化工具判定資料列數目太少,則不會引進交換運算子來散發資料列。 因此,運算子會循序執行。 在序列計畫中執行運算子,可避免啟動、散發、協調成本超過執行平行運算子所獲得的利益時的案例。
是否能使用目前的散發統計資料。 如果無法使用平行處理原則的最高程度,則在放棄平行計畫前,會先考慮降低程度。 例如,當您在檢視中建立叢集索引時,因為叢集索引尚未存在,所以無法評估散發統計資料。 在此情況下,SQL Server 資料庫引擎無法為索引作業提供平行處理原則的最高程度。 然而,有些運算子 (如排序及掃描) 仍可從平行執行獲益。
注意
只有 SQL Server Enterprise、Developer 和 Evaluation 版本才可使用平行索引作業。
SQL Server 資料庫引擎會在執行期間,判斷目前系統工作負載和先前描述的組態資訊是否允許平行執行。 如果保證可以平行執行,則 SQL Server 資料庫引擎會判定最佳的背景工作執行緒數目,並將平行計畫的執行分散到那些背景工作執行緒上。 當查詢或索引作業開始在多個背景工作執行緒上執行,以進行平行執行時,則在完成作業之前,都會使用相同數目的背景工作執行緒。 每次從計畫快取擷取執行計畫時,SQL Server 資料庫引擎都會重新檢查最佳的背景工作執行緒決策數目。 例如,執行查詢可能會使用到序列計畫,稍後執行同一個查詢會導致平行計畫使用三個背景工作執行緒,而第三次執行查詢的結果則是平行計畫使用四個背景工作執行緒。
平行查詢執行計畫中的 Update 和 Delete 運算子都會以循序方式執行,但是 WHERE 或 UPDATE 陳述式的 DELETE 子句則能以平行方式執行。 真正的資料變更隨即會循序套用到資料庫。
直到 SQL Server 2012 (11.x) 為止,Insert 運算子也是以循序方式執行。 不過,INSERT 陳述式的 SELECT 部分則能以平行方式執行。 真正的資料變更隨即會循序套用到資料庫。
從 SQL Server 2014 (12.x) 和資料庫相容性層級 110 開始,SELECT ... INTO 陳述式能以平行方式執行。 其他形式的 Insert 運算子會採取與針對 SQL Server 2012 (11.x) 所述的相同運作方式。
從 SQL Server 2016 (13.x) 和資料庫相容性層級 130 開始,INSERT ... SELECT 陳述式可以在插入堆積或叢集資料行存放區索引 (CCI) 且使用 TABLOCK 提示時,以平行方式執行。 針對本機暫存資料表 (以 # 前置詞識別) 和全域暫存資料表 (以 ## 前置詞識別) 所進行的插入,也可以透過使用 TABLOCK 提示來啟用平行處理原則。 如需詳細資訊,請參閱 INSERT (Transact-SQL)。
靜態和索引鍵集衍生的資料指標可以利用平行執行計畫來擴展。 但是,動態資料指標的行為僅能由序列執行來提供。 而最佳化工具所產生的查詢序列執行計畫,一定是動態資料指標的一部份。
覆寫平行處理原則的程度
平行處理原則的程度設定平行計畫執行中所要使用的處理器數量。 此設定可在各種層級上設定:
伺服器層級:使用最大平行處理原則程度 (MAXDOP) 伺服器設定選項。
適用於:SQL Server注意
SQL Server 2019 (15.x) 會在安裝過程設定 MAXDOP 伺服器組態選項時提供自動建議。 安裝程式使用者介面可讓您接受建議的設定,或輸入您自己的值。 如需詳細資訊,請參閱資料庫引擎定 - MaxDOP 頁面。
工作負載層級,使用 MAX_DOPResource Governor 工作負載群組組態選項。
適用於:SQL Server資料庫層級,使用 MAXDOP資料庫範圍設定。
適用於:SQL Server 和 Azure SQL 資料庫查詢或索引陳述式層級:使用 MAXDOP查詢提示或 MAXDOP 索引選項。 例如,您可以使用 MAXDOP 選項,利用增加或減少,來控制線上索引作業專用的處理器數目。 如此一來,您就可以平衡索引作業所使用的資源及並行使用者的資源。
適用於:SQL Server 和 Azure SQL 資料庫
將 [平行處理原則的最大程度] 選項設為 0 (預設),可讓 SQL Server 在平行計畫執行中使用所有可用的處理器 (最大值為 64 個處理器)。 雖然當 MAXDOP 選項設定為 0 時,SQL Server 會將執行階段目標設定為 64 個邏輯處理器,但必要時可手動設定不同的值。 針對查詢或索引將 MAXDOP 設定為 0,讓 SQL Server 可針對平行計畫執行中指定的查詢或索引使用所有可用的處理器 (最大值為 64 個處理器)。 MAXDOP 不是所有平行查詢的強制值,而是所有符合平行處理原則資格的查詢暫訂目標。 這表示,如果執行階段沒有足夠的背景工作執行緒可用,查詢可能會使用比 MAXDOP 伺服器組態選項更低的平行處理原則程度來執行。
提示
如需詳細資訊,請參閱 MAXDOP 建議以取得在伺服器、資料庫、查詢或提示層級設定 MAXDOP 的指導方針。
平行查詢範例
下列查詢會計算從 2000 年 4 月 1 日起,某一季之內所下的訂單數量,而這一季的訂單中,至少有一項產品晚於交付日期才送達客戶。 這個查詢會列出這類的訂單數量,並依訂單的優先順序分組,然後以遞增的優先順序排序訂單。
這個範例使用假設性的資料表和資料行名稱。
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
假設下列索引定義於 lineitem 和 orders 資料表上:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
這是針對之前查詢所產生的可能平行計畫:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
上圖所示為使用平行處理原則程度 4 來執行的查詢計畫,包含兩個資料表的聯結。
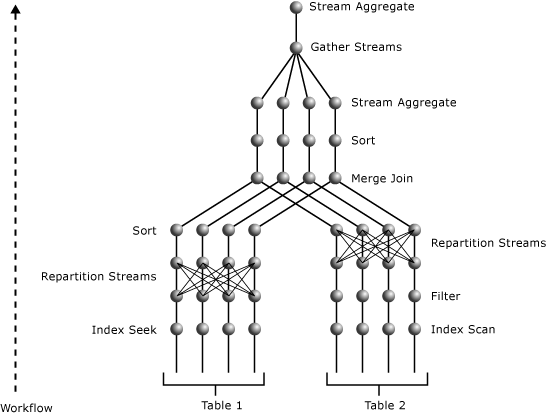
平行計畫包含三個平行處理原則運算子。 o_datkey_ptr 索引的 Index Seek 運算子和 l_order_dates_idx 索引的 Index Scan 運算子會以平行方式執行。 這會產生數個獨佔的資料流。 可分別從 Index Scan 和 Index Seek 運算子上方最接近的 Parallelism 運算子來判斷。 兩者都會重新分割交換類型。 也就是說,它們只是將資料流間的資料重新改組,然後依據其輸入的資料流數量產生等量的輸出資料流。 此資料流數量就等於平行處理原則的程度。
在 l_order_dates_idx Index Scan 運算子上方的 Parallelism 運算子會使用 L_ORDERKEY 值作為索引鍵,重新分割其輸入資料流。 利用這種方式,相同的 L_ORDERKEY 值也會在相同的輸出資料流中產生相同的結果。 同時,輸出資料流會維持 L_ORDERKEY 資料行的順序,以符合 Merge Join 運算子的輸入需求。
在 Index Seek 運算子上方的 Parallelism 運算子會使用 O_ORDERKEY 值,重新分割其輸入資料流。 因為其輸入未在 O_ORDERKEY 資料行值上進行排序,而且此為 Merge Join 運算子中的聯結資料行,所以介於 Parallelism 與 Merge Join 運算子之間的 Sort 運算子,可確保會在聯結資料行上針對 Merge Join 運算子為輸入進行排序。 Sort 運算子 (如 Merge Join 運算子) 會以平行方式執行。
最頂端的 Parallelism 運算子會將數個資料流中的結果,集合成單一資料流。 接著,在 Parallelism 運算子下方之 Stream Aggregate 運算子所執行的部分彙總,會累積為 Parallelism 運算子上方之 Stream Aggregate 運算子中,各個不同 O_ORDERPRIORITY 值的單一 SUM 值。 由於此計畫具有兩個交換區段,且平行處理原則的程度為 4,因此會使用八個背景工作執行緒。
如需此範例中所使用運算子的詳細資訊,請參閱執行程序表邏輯和實體運算子參考。
平行索引作業
為建立或重建索引,或卸除叢集索引的索引作業所內建的查詢計畫,允許在多個微處理器的電腦上進行平行、多背景工作執行緒作業。
注意
只有從 SQL Server 2008 (10.0.x) 開始的 Enterprise Edition 才支援平行索引作業。
SQL Server 會使用與其他查詢相同的演算法,判斷索引作業的平行處理原則程度 (要執行的個別背景工作執行緒總數)。 索引作業的平行處理原則最大程度受限於 平行處理原則的最大程度 伺服器組態選項。 您可以在 CREATE INDEX、ALTER INDEX、DROP INDEX 和 ALTER TABLE 陳述式中設定 MAXDOP 索引選項,來覆寫個別索引作業的 [平行處理原則的最大程度] 值。
當 Database Engine 建立索引執行計畫時,SQL Server 會將平行作業的數目設定為下列項目中的最低值:
- 微處理器的數目或電腦中的 CPU 數。
- [平行處理原則的最大程度] 伺服器組態選項中所指定的數目。
- 未超過 SQL Server 背景工作執行緒所執行工作閾值的 CPU 數目。
例如,電腦上有八個 CPU,但 [平行處理原則的最大程度] 設定為 6,則索引作業不會產生超過六個的平行背景工作執行緒。 如果在建立索引執行計畫時,電腦中有五個 CPU 已經超過 SQL Server 工作的閾值,則執行計畫只會指定三個平行背景工作執行緒。
平行索引作業的主要階段包含下列項目:
- 協定背景工作執行緒會快速及隨意掃描資料表,以估計索引鍵的散佈。 協調背景工作執行緒會建立索引鍵值界限,此界限將建立數個等於平行作業程度的索引鍵值範圍,預期其中的索引鍵值範圍將包含類似數目的資料列。 例如,如果資料表中有四百萬個資料列,而平行處理原則的程度為 4,則協調背景工作執行緒會決定將索引鍵值分成四組資料列,且每個資料列都會有 1 百萬個資料列。 如果無法建立足夠數目的索引鍵範圍以使用所有 CPU,則平行處理原則的程度也會跟著降低。
- 協調背景工作執行緒會分派與平行作業程度相等數目的背景工作執行緒,並且等待這些背景工作執行緒完成它們的工作。 每個背景工作執行緒會使用篩選來掃描基底資料表,並擷取其索引鍵值在背景工作執行緒指定範圍中的資料列。 每個背景工作執行緒會在其索引鍵值範圍中,建立資料列的索引結構。 在資料分割索引的例子中,每個背景工作執行緒都會建立指定數目的資料分割。 背景工作執行緒之間不會共用資料分割。
- 當所有平行背景工作執行緒完成後,協調背景工作執行緒便會將索引次單元連接到單一索引中。 此階段僅適用於離線索引作業。
個別的 CREATE TABLE 或 ALTER TABLE 陳述式可以有多個條件約束,來要求建立索引。 這幾個索引建立作業會以序列方式來執行,即使在有多個 CPU 的電腦上,每個個別索引建立作業可能是平行作業。
分散式查詢結構
Microsoft SQL Server 支援兩種可在 Transact-SQL 陳述式中參考異質 OLE DB 資料來源的方法:
連結伺服器名稱
系統預存程序sp_addlinkedserver和sp_addlinkedsrvlogin可用來將伺服器名稱指定至 OLE DB 資料來源。 您可以使用四個部分名稱,在 Transact-SQL 陳述式中參考這些連結伺服器中的物件。 例如,如果DeptSQLSrvr的連結伺服器名稱是根據 SQL Server 的另一個執行個體所定義,則下列陳述式會參考該伺服器上的資料表:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;您也可以在
OPENQUERY陳述式中指定連結伺服器名稱,以開啟 OLE DB 資料來源中的資料列集。 然後您就能在 Transact-SQL 陳述式中,像參考資料表一樣參考這個資料列集。特定連接子名稱
對於資料來源的非經常性參考,需要以連接至連結伺服器所需的資訊來指定OPENROWSET或OPENDATASOURCE函數。 然後您就能在 Transact-SQL 陳述式中,使用與參考資料表一樣的方式來參考這個資料列集:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server 會使用 OLE DB,在關聯式引擎與儲存引擎間進行通訊。 關聯式引擎會將每個 Transact-SQL 陳述式分解為簡單 OLE DB 資料列集上的一連串作業,而儲存引擎可從基底資料表加以開啟。 這是表示關聯式引擎也可以在任何 OLE DB 資料來源上,開啟簡單的 OLE DB 資料列集。
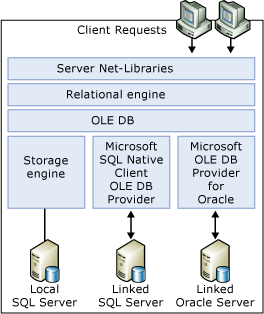
關聯式引擎使用 OLE DB 應用程式開發介面 (API) 來開啟連結伺服器上的資料列集、提取資料列、以及管理交易。
針對每個可做為連結伺服器存取的 OLE DB 資料來源,在執行 SQL Server 的伺服器上必須存在 OLE DB 提供者。 這組可根據特定 OLE DB 資料來源使用的 Transact-SQL 作業,取決於 OLE DB 提供者的能力。
對於每個 SQL Server 執行個體, sysadmin 固定伺服器角色的成員可藉由使用 SQL Server DisallowAdhocAccess 屬性來啟用或停用 OLE DB 提供者的特定連接器名稱的使用。 當啟用特定存取時,任何登入到該執行個體的使用者都可以執行包含特定連接子名稱的 Transact-SQL 陳述式,該連接子名稱會參考可使用 OLE DB 提供者存取網路上的任何資料來源。 若要控制資料來源的存取,sysadmin 角色的成員可以停用該 OLE DB 提供者的特定存取,進而限制使用者只能存取由系統管理員所定義連結伺服器名稱參考的資料來源。 預設會針對 SQL Server OLE DB 提供者啟用特定存取,並針對所有其他的 OLE DB 提供者加以停用。
分散式查詢可使用 Microsoft Windows 帳戶 (SQL Server 服務正在其下執行) 的安全性內容,允許使用者存取其他資料來源 (例如,檔案或 Active Directory 等非關聯式資料來源等)。 SQL Server 會適當地模擬 Windows 登入,但無法模擬 SQL Server 登入。 這可能會允許分散式查詢使用者存取他們沒有使用權限的其他資料來源,但執行 SQL Server 服務的帳戶確實擁有權限。 使用 sp_addlinkedsrvlogin 來定義已經授權存取對應連結伺服器的特定登入。 ad hoc 名稱無法使用此控制,所以啟用 ad hoc 存取的 OLE DB 提供者時請特別小心。
如果可能,SQL Server 會將關聯式作業 (例如聯結、限制、投影、排序和依作業分組) 推送至 OLE DB 資料來源。 SQL Server 不會預設為將基底資料表掃描到 SQL Server 並自行執行關聯式作業。 SQL Server 會查詢 OLE DB 提供者以判斷它支援的 SQL 語法層級,然後根據該資訊,盡可能推送最多關聯式作業給提供者。
SQL Server 會為 OLE DB 提供者指定一種可傳回統計資料的機制,以指如何出在 OLE DB 資料來源中散發索引鍵值。 這讓 SQL Server 查詢最佳化工具能根據各個 Transact-SQL 陳述式的需求,分析資料來源中的資料模式,並提升查詢最佳化工具產生最佳執行計畫的能力。
分割資料表和索引上的查詢處理增強功能
SQL Server 2008 (10.0.x) 已針對許多平行計畫提升了資料分割資料表上的查詢處理效能、變更了平行計畫和序列計畫的表示方式,以及增強了編譯時間和執行階段執行計畫內所提供的資料分割資訊。 本文將描述這些改進的功能、提供如何解譯資料分割資料表和索引之查詢執行計畫的指引,以及提供用來改善資料分割物件上之查詢效能的最佳做法。
注意
在 SQL Server 2014 (12.x) 之前,只有 SQL Server Enterprise、Developer 和 Evaluation 版本才支援資料分割資料表和索引。 從 SQL Server 2016 (13.x) SP1 開始,Microsoft SQL Server Standard 也支援資料分割資料表和索引。
新資料分割感知的搜尋作業
在 SQL Server 中,資料分割資料表的內部表示法已變更。對於查詢處理器而,資料表看起來像是具有以 PartitionID 為開頭資料行的多重資料行索引。 PartitionID 是經過計算的隱藏資料行,可在內部用來代表包含特定資料列之資料分割的 ID 。 例如,假設定義為 T(a, b, c)的資料表 T 已在資料行 a 上進行資料分割,而且資料行 b 上具有叢集索引。 在 SQL Server 中,這個資料分割的資料表會在內部視為非資料分割的資料表,而且具有結構描述 T(PartitionID, a, b, c) 及複合索引鍵 (PartitionID, b)上的叢集索引。 如此可讓查詢最佳化工具根據任何資料分割資料表或索引上的 PartitionID 來執行搜尋作業。
現在完成了此搜尋作業中的資料分割刪除。
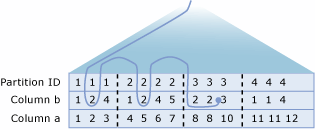
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (當做邏輯前端資料行) 上完成,而其他索引鍵資料行及第二層搜尋 (具有另一個條件) 也可能會在一或多個其他資料行上完成 (針對符合第一層搜尋作業資格的每一個相異值)。 也就是說,這個稱為「略過掃描」的作業可讓查詢最佳化工具根據某一個條件來執行搜尋或掃描作業,以判斷要存取的資料分割及該運算子內的第二層索引搜尋作業,以便從符合其他條件的資料分割中傳回資料列。 例如,假設有以下的查詢。
SELECT * FROM T WHERE a < 10 and b = 2;
在此範例中,假設定義為 T(a, b, c)的資料表 T 已在資料行 a 上進行資料分割,而且資料行 b 上具有叢集索引。 資料表 T 的資料分割界限是由以下資料分割函數所定義:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
為了解決此查詢,查詢處理器會執行第一層搜尋作業,以尋找包含符合 T.a < 10條件之資料列的每一個資料分割。 這會找出要存取的資料分割。 然後處理器會在每個識別出的資料分割中,於資料行 b 上執行叢集索引內的第二層搜尋,以找出符合 T.b = 2 和 T.a < 10條件的資料列。
下圖為略過掃描作業的邏輯表示法。 此圖顯示資料表 T,其中的資料行 a 和 b 中有資料。 資料分割以 1 到 4 進行編號,並以垂直虛線來顯示資料分割界限。 對資料分割的第一層搜尋作業 (此圖並未顯示) 判斷出,資料分割 1、2 和 3 符合針對資料行 a 上資料表和述詞定義之資料分割所默許的搜尋條件。 也就是說, T.a < 10。 略過掃描作業的第二層搜尋部分所周遊的路徑則以曲線表示。 基本上來說,此略過掃描作業會搜尋每一個資料分割,以找出符合 b = 2條件的資料列。 此略過掃描作業的總成本與三個個別索引搜尋的總成本相同。
在查詢執行計畫中顯示資料分割資訊
資料分割資料表和索引上的查詢執行計畫可以使用 Transact-SQL SET 陳述式 SET SHOWPLAN_XML 或 SET STATISTICS XML,或是使用 SQL Server Management Studio 中的圖形化執行計畫輸出進行檢查。 例如,您可以在查詢編輯器工具列上,選取 [顯示估計執行計畫] 來顯示編譯時間執行計畫,以及選取 [包括實際執行計畫]來顯示執行階段計畫。
您可以使用這些工具來確定以下資訊:
- 像是可以存取分割資料表或索引的
scans、seeks、inserts、updates、merges和deletes等作業。 - 查詢所存取的資料分割。 例如,所存取的資料分割總計數和所存取的連續資料分割範圍可以在執行階段執行計畫內使用。
- 當搜尋或掃描作業中使用略過掃描作業來擷取一或多個資料分割中的資料時。
資料分割資訊增強
SQL Server 同時針對編譯時間和執行階段的執行計畫提供了增強的資料分割資訊。 執行計畫現在會提供下列資訊:
- 選擇性的
Partitioned屬性,其指出在資料分割的資料表上執行像是seek、scan、insert、update、merge或delete等運算子。 - 新的
SeekPredicateNew元素搭配SeekKeys子元素,其中包含PartitionID做為前置的索引鍵資料行,以及在PartitionID上指定範圍搜尋的篩選條件。 兩個SeekKeys子元素的存在表示會使用PartitionID上的略過掃描作業。 - 提供所存取之資料分割總計數的摘要資訊。 只有在執行階段計畫中才能使用這項資訊。
為了示範如何在圖形化執行計畫輸出和 XML 執行程序表輸出中顯示這項資訊,假設資料分割資料表 fact_sales上有以下的查詢。 此查詢會更新兩個資料分割中的資料。
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
下圖顯示在此查詢其執行階段執行計畫內 Clustered Index Seek 運算子的屬性。 若要檢視 fact_sales 資料表和資料分割的定義,請參閱本文的「範例」一節。

Partitioned 屬性
在對資料分割的資料表或索引執行類似索引搜尋的運算子時,Partitioned 屬性會出現在編譯時間和執行階段的計畫內,而且會設定為 True (1)。 當這個屬性設定為 False (0) 時,就不會顯示。
Partitioned 屬性可出現在下列實體和邏輯運算子內:
- 資料表掃描
- 索引掃描
- 索引搜尋
- 插入
- 更新
- 刪除
- 合併
如同上圖所示,這個屬性 (Attribute) 會顯示在其定義所在之運算子的屬性 (Property) 內。 在 XML 執行程序表輸出中,這個屬性會以 Partitioned="1" 的形式出現在其定義所在之運算子的 RelOp 節點內。
新的搜尋述詞
在 XML 執行程序表輸出中, SeekPredicateNew 元素會出現在其定義所在的運算子內。 其中最多可包含兩個 SeekKeys 子元素。 第一個 SeekKeys 項目會在邏輯索引的資料分割識別碼層級上指定第一層搜尋作業。 也就是說,這個搜尋會判斷為了滿足查詢條件所必須存取的資料分割。 第二個 SeekKeys 項目會指定略過掃描作業的第二層搜尋部分,其發生於第一層搜尋中識別出的每一個資料分割內。
資料分割摘要資訊
在執行階段執行計畫中,資料分割摘要資訊提供了所存取之資料分割以及所存取之實際資料分割識別的計數。 您可以使用這項資訊來確認已存取查詢中的正確資料分割,而且所有其他資料分割都不在考量之內。
系統會提供下列資訊: Actual Partition Count和 Partitions Accessed。
Actual Partition Count 是查詢所存取的資料分割總數。
Partitions Accessed(位於 XML 執行程序表輸出內) 為資料分割摘要資訊,會出現在它定義所在之運算子的 RuntimePartitionSummary 節點內的新 RelOp 元素中。 下列範例會顯示 RuntimePartitionSummary 元素的內容,指出總共會存取兩個資料分割 (資料分割 2 和 3)。
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
使用其他執行程序表方法來顯示資料分割資訊
執行程序表方法 SHOWPLAN_ALL、SHOWPLAN_TEXT 和 STATISTICS PROFILE 不會報告本文所述的資料分割資訊,但以下情況例外。 要存取的資料分割 (屬於 SEEK 述詞的一部分) 是由表示資料分割識別碼之計算資料行上的範圍述詞所識別。 下列範例會顯示 SEEK 運算子的 Clustered Index Seek 述詞。 系統會存取資料分割 2 和 3,而且搜尋運算子會篩選符合 date_id BETWEEN 20080802 AND 20080902條件的資料列。
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
解譯資料分割堆積的執行計畫
資料分割的堆積會被視為資料分割識別碼上的邏輯索引。 資料分割堆積上的資料分割刪除會在執行計畫中表示為 Table Scan 運算子 (在資料分割識別碼上具有 SEEK 述詞)。 下列範例會顯示所提供的執行程序表資訊:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
解譯共置聯結的執行計畫
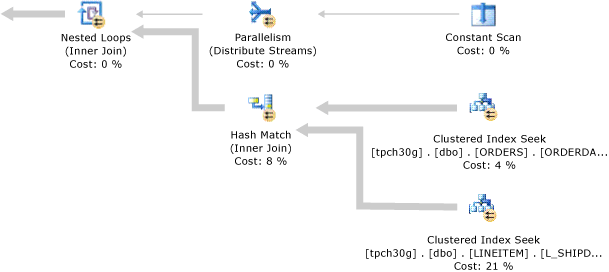
當使用相同或相當的資料分割函數來分割兩個資料表,而且聯結兩端的資料分割資料行指定於查詢的聯結條件內時,可能會發生聯結共現。 查詢最佳化工具可以產生一個計畫,好讓每一個資料表中具有相同資料分割識別碼的資料分割都會個別聯結。 共置聯結的速度快於非共置聯結,因為共置聯結所需的記憶體和處理時間比較少。 查詢最佳化工具會根據成本估計來選擇非共置計畫或共置計畫。
在共置計畫中, Nested Loops 聯結會從內部讀取一或多個聯結資料表或索引資料分割。 Constant Scan 運算子內的數字代表資料分割編號。
當針對資料分割資料表或索引產生共置聯結的平行計畫時,平行處理原則運算子就會出現在 Constant Scan 與 Nested Loops 聯結運算子之間。 在此情況下,聯結外部的多個背景工作執行緒每個都會讀取和處理不同的資料分割。
下圖將示範共置聯結的平行查詢計畫。
資料分割物件的平行查詢執行策略
查詢處理器會將平行執行策略用於從資料分割物件選取的查詢。 在執行策略中,查詢處理器會判斷查詢所需的資料表資料分割,以及配置給每一個資料分割的背景工作執行緒比例。 在大多數情況下,查詢處理器會將相同或幾乎相同的背景工作執行緒數目配置給每一個資料分割,然後以平行方式在資料分割之間執行查詢。 以下段落將更詳細地說明背景工作執行緒配置。
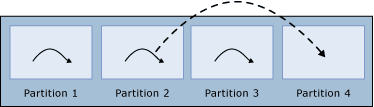
如果背景工作執行緒數目小於資料分割數目,查詢處理器會將每一個背景工作執行緒指派給不同的資料分割,一開始會讓一或多個資料分割未具指派的背景工作執行緒。 當背景工作執行緒在資料分割上完成執行時,查詢處理器會將它指派給下一個資料分割,直到每一個資料分割都已指派單一背景工作執行緒為止。 這是查詢處理器將背景工作執行緒重新配置給其他資料分割的唯一情況。
顯示完成後重新指派的背景工作執行緒。 如果背景工作執行緒數目等於資料分割數目,則查詢處理器會將一個背景工作執行緒指派給每一個資料分割。 背景工作執行緒完成時,不會重新配置給另一個資料分割。

如果背景工作執行緒數目大於資料分割數目,則查詢處理器會將相同的背景工作執行緒數目指派給每一個資料分割。 如果背景工作執行緒數目不是資料分割數目的倍數,則查詢處理器會將一個額外的背景工作執行緒配置給某些資料分割,如此才可使用所有可用的背景工作執行緒。 如果只有一個資料分割,則所有背景工作執行緒都將指派給該資料分割。 在下圖中,有四個資料分割和 14 個背景工作執行緒。 每一個資料分割都指派 3 個背景工作執行緒,其中的兩個資料分割有一個額外的背景工作執行緒,所以一共指派了 14 個背景工作執行緒。 當背景工作執行緒完成時,不會將它重新指派給另一個資料分割。

雖然上面的範例建議一個直接的方式來配置背景工作執行緒,但是實際的策略會更複雜,而且要考量在查詢執行期間所發生的其他變數。 例如,如果資料表已進行資料分割,並在資料行 A 上有一個叢集索引,而且查詢具有述詞子句 WHERE A IN (13, 17, 25),則查詢處理器會將一或多個背景工作執行緒配置給這三個搜尋值 (A=13、A=17 及 A=25) 的每一個,而非每一個資料表資料分割。 只需要執行包含這些值之資料分割內的查詢,而且如果所有的這些搜尋述詞都剛好在相同的資料表資料分割中,則所有的背景工作執行緒都將指派給相同的資料表資料分割。
再舉一例,假設資料表在資料行 A 上具有四個資料分割,而界限點為 (10、20、30)、在資料行 B 上有一個索引,而且查詢具有述詞子句 WHERE B IN (50, 100, 150)。 由於資料表資料分割是以 A 的值為根據,所以 B 的值可能會發生在任何資料表資料分割內。 因此,查詢處理器將會在這四個資料表資料分割的每一個中,搜尋 B (50, 100, 150) 的這三個值的每一個。 查詢處理器會依比例指派背景工作執行緒,好讓它可以透過平行方式執行這 12 個查詢掃描的每一個。
| 根據資料行 A 的資料表資料分割 | 在每一個資料表資料分割中搜尋資料行 B |
|---|---|
| 資料表資料分割 1: A < 10 | B=50, B=100, B=150 |
| 資料表資料分割 2: A >= 10 AND A < 20 | B=50, B=100, B=150 |
| 資料表資料分割 3: A >= 20 AND A < 30 | B=50, B=100, B=150 |
| 資料表資料分割 4: A >= 30 | B=50, B=100, B=150 |
最佳做法
若要讓從大量資料分割資料表和索引中存取大量資料的查詢提升效能,我們建議您採取以下的最佳做法:
- 在多個磁碟之間條狀配置每一個資料分割。 這在使用旋轉磁碟時特別有關。
- 盡可能使用具有充足主記憶體的伺服器,將經常存取的資料分割或所有資料分割納入記憶體中,以減少 I/O 成本。
- 如果您查詢的資料無法納入儲存體中,請壓縮資料表和索引。 如此可減少 I/O 成本。
- 請使用具有快速處理器的伺服器並盡量多使用您可以負擔的處理器核心,以充分利用平行查詢處理功能。
- 確定伺服器擁有足夠的 I/O 控制器頻寬。
- 在每一個大型資料分割資料表上建立叢集索引,以充分利用 B 型樹狀結構的掃描最佳化。
- 當您將資料大量載入資料分割資料表時,請遵循 The Data Loading Performance Guide (資料載入效能指南) 技術白皮書中的最佳做法建議。
範例
下列範例會建立一個測試資料庫,其中包含具有七個資料分割的單一資料表。 當執行此範例中的查詢時,請使用之前所述的工具,以檢視編譯時間和執行階段計畫的資料分割資訊。
注意
這個範例會將一百萬個以上的資料列插入資料表中。 執行此範例可能需要好幾分鐘的時間 (視您的硬體而定)。 在執行此範例之前,請確認有 1.5 GB 以上的磁碟空間可用。
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
相關內容
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應