DBCC SHOW_STATISTICS (Transact-SQL)
適用於:![]() Microsoft Fabric 中 Microsoft Fabric
Microsoft Fabric 中 Microsoft Fabric![]() 倉儲中的 SQL Server
倉儲中的 SQL Server![]() Azure SQL 資料庫
Azure SQL 資料庫![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL 分析端點
SQL 分析端點
針對資料表或索引檢視表顯示目前的查詢最佳化統計資料。 查詢最佳化工具會使用統計資料來估計基數或查詢結果中的資料列數目,以利其建立高品質的查詢計劃。 例如,查詢最佳化工具可使用基數預估來選擇查詢計劃中的索引搜尋運算子,而不是索引掃描運算子,避免發生資源密集的索引掃描來提高查詢效能。
查詢最佳化工具會將資料表或索引檢視表的統計資料儲存在統計資料物件中。 如果是資料表,將會在索引或資料表資料行清單上建立統計資料物件。 統計資料物件包含標頭 (其中包含有關統計資料的中繼資料)、長條圖 (包含統計資料物件之第一個索引鍵資料行中的值分佈),以及用來測量跨資料行關聯的密度向量。 資料庫引擎可以使用統計資料物件中的任何資料來計算基數預估。 如需詳細資訊,請參閱統計資料和基數估計 (SQL Server)。
DBCC SHOW_STATISTICS 會根據儲存在統計資料物件中的資料來顯示標頭、長條圖和密度向量。 此語法可讓您指定資料表或索引檢視表,連同目標索引名稱、統計資料名稱或資料行名稱。
舊版 SQL Server的重要更新:
從 SQL Server 2012 (11.x) Service Pack 1 開始,sys.dm_db_stats_properties 動態管理檢視可讓您以程式設計方式擷取統計資料物件中包含的標頭資訊,以取得非累加統計資料。
從 SQL Server 2014 (12.x) Service Pack 2 和 SQL Server 2012 (11.x) Service Pack 1 開始,sys.dm_db_incremental_stats_properties 動態管理檢視可讓您以程式設計方式擷取統計資料物件中包含的標頭資訊,以取得累加統計資料。
從 SQL Server 2016 (13.x) Service Pack 1 CU 2 開始,sys.dm_db_stats_histogram 動態管理檢視可讓您以程式設計方式擷取統計資料物件中包含的長條圖資訊。
-
Azure Synapse Analytics 的無伺服器 SQL 集區不支援此語法。
如需 Microsoft Fabric 中統計數據的詳細資訊,請參閱 統計數據。
語法
SQL Server 和 Azure SQL Database 的語法:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Azure Synapse Analytics、Analytics Platform System (PDW) 和 Microsoft Fabric 的語法:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
注意
若要檢視 SQL Server 2014 (12.x) 和舊版的 Transact-SQL 語法,請參閱 舊版檔。
引數
table_or_indexed_view_name
要顯示統計資料資訊之資料表或索引檢視表的名稱。
table_name
包含要顯示之統計資料的資料表名稱。 數據表不能是外部數據表。
目標
要顯示統計資料資訊之索引、統計資料或資料行的名稱。 「目標」以括號、單引號、雙引號括住,或是沒有引號。
- 如果「目標」是資料表或索引檢視表上現有索引或統計資料的名稱,便會傳回這個目標的相關統計資料資訊。
- 如果「目標」是現有資料行的名稱,而且這個資料行含有自動建立的統計資料物件,便會傳回自動建立統計資料的相關資訊。
如果數據行目標沒有自動建立的統計數據,則會傳回錯誤訊息 2767。
在 Azure Synapse Analytics 和分析平台系統 (PDW), 目標 不能是數據行名稱。
在 Microsoft Fabric 的 Warehouse 中, 目標 可以是單一數據行直方圖統計數據或數據行的名稱。 如果數據行名稱用於 目標,此命令只會傳回自動產生直方圖統計數據的散發資訊。 若要檢視手動建立直方圖統計數據的相關信息,請將統計數據名稱指定為 目標。
NO_INFOMSGS
抑制所有嚴重性層級在 0 到 10 的參考用訊息。
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
如果指定其中一或多個選項,就會限制陳述式針對指定之選項所傳回的結果集。 如果沒有指定任何選項,便會傳回所有的統計資料資訊。
STATS_STREAM 僅供參考之用。 不支援。 我們無法保證未來的相容性。
結果集
下表描述指定 STAT_HEADER 時,結果集所傳回的資料行。
| 資料行名稱 | Description |
|---|---|
| 名稱 | 統計資料物件的名稱。 |
| 已更新 | 上次更新統計資料的日期和時間。 STATS_DATE 函數是擷取這項資訊的替代方式。 如需詳細資訊,請參閱此頁的備註一節。 |
| 資料列 | 上一次更新統計資料時位於資料表或索引檢視表中的資料列總數。 如果篩選了統計資料或是統計資料對應至篩選過的索引,此資料列數可能會少於資料表中的資料列數。 如需詳細資訊,請參閱統計資料。 |
| 取樣的資料列 | 針對統計資料計算進行取樣的資料列總數。 如果取樣的資料列數 < 資料列數,顯示的長條圖和密度結果將會是根據取樣資料列數的預估值。 |
| 步驟 | 長條圖中的步驟數。 每一個步驟都會跨越某個範圍的資料行值,後面緊接著上限資料行值。 長條圖步驟會在統計資料中的第一個索引鍵資料行上定義。 步驟數的最大值為 200。 |
| 密度 | 針對統計資料物件第一個索引鍵資料行中的所有值,計算為 1 / 相異值,不包括長條圖界限值。 查詢優化器不會使用此密度值,而且會顯示為與 SQL Server 2008 (10.0.x) 之前的版本回溯相容性。 |
| 平均索引鍵長度 | 針對統計資料物件中的所有索引鍵資料行計算之每個值的平均位元組數。 |
| String Index | Yes 表示統計資料物件包含了字串摘要統計資料來改善使用 LIKE 運算子之查詢述詞的基數預估,例如 WHERE ProductName LIKE '%Bike'。 字串摘要統計數據會與直方圖分開儲存,而且當統計數據對象的類型為char、varchar、nchar、nvarchar、varchar(max)、nvarchar(max)、text 或ntext時,就會在統計數據物件的第一個索引鍵數據行上建立。 |
| 篩選運算式 | 包含在統計資料物件中之資料表資料列子集的述詞。 NULL = 非篩選的統計資料。 如需篩選述詞的詳細資訊,請參閱建立篩選的索引。 如需已篩選統計資料的詳細資訊,請參閱統計資料。 |
| Unfiltered Rows | 套用篩選運算式之前,資料表中的資料列總數。 如果 Filter Expression 為 NULL,則 Unfiltered Rows 等於 Rows。 |
| 保存取樣百分比 | 用於未明確指定取樣百分比之統計數據更新的保存樣本百分比。 如果值為零,表示這個統計資料未設定保存取樣百分比。 套用至:SQL Server 2016 (13.x) Service Pack 1 CU 4 |
下表描述指定 DENSITY_VECTOR 時,結果集所傳回的資料行。
| 資料行名稱 | 描述 |
|---|---|
| 所有密度 | 密度是 1 / 相異值。 結果會針對統計資料物件中資料行的每個前置詞來顯示密度,一個密度一個資料列。 相異值是每個資料列和每個資料行前置詞的資料行值相異清單。 例如,如果統計資料物件包含索引鍵資料行 (A, B, C),結果就會報告每一個資料行前置詞中相異值清單的密度:(A)、(A,B) 和 (A, B, C)。 使用前置詞 (A, B, C) 時,這些清單的每一個都會是相異值清單:(3, 5, 6)、(4, 4, 6)、(4, 5, 6)、(4, 5, 7)。 使用前置詞 (A, B) 時,相同的資料行值都會有這些相異值清單:(3, 5)、(4, 4) 和 (4, 5) |
| 平均長度 | 平均長度 (以位元組為單位),用來儲存資料行前置詞的資料行值清單。 例如,如果清單 (3, 5, 6) 中的每一個值都需要 4 位元組,長度就是 12 位元組。 |
| 資料行 | 在前置詞中顯示 All density 和 Average length 的資料行名稱。 |
下表描述指定 HISTOGRAM 選項時,結果集所傳回的資料行。
| 資料行名稱 | 描述 |
|---|---|
| RANGE_HI_KEY | 長條圖步驟的上限資料行值。 此資料行值也稱為索引鍵值。 |
| RANGE_ROWS | 資料行值在長條圖步驟內的預估資料列數,不包括上限。 |
| EQ_ROWS | 資料行值等於長條圖步驟之上限的預估資料列數。 |
| DISTINCT_RANGE_ROWS | 在長條圖步驟內具有相異資料行值的預估資料列數,不包括上限。 |
| AVG_RANGE_ROWS | 在長條圖步驟內具有重複資料行值的平均資料列數,不包括上限。 當 DISTINCT_RANGE_ROWS 大於 0 時,AVG_RANGE_ROWS 的計算方式為 RANGE_ROWS 除以 DISTINCT_RANGE_ROWS。 當 DISTINCT_RANGE_ROWS 為 0 時,AVG_RANGE_ROWS 會針對長條圖步驟傳回 1。 |
備註
統計資料更新日期儲存在統計資料 Blob 物件中,其中還有長條圖和密度向量,不是儲存在中繼資料中。 當未讀取任何資料以產生統計資料資料時,不會建立統計數據 Blob、無法使用日期,且 更新 的數據行為 NULL。 這是述詞不會傳回任何數據列或新空白數據表之篩選統計數據的情況。
長條圖
長條圖會測量資料集中每一個相異值的發生頻率。 查詢最佳化工具會計算有關統計資料物件之第一個索引鍵資料行中資料行值的長條圖,以統計方式取樣資料列或執行資料表或檢視表中所有資料列的完整掃描來選取資料行值。 如果從取樣的數據列集建立直方圖,則數據列數目和相異值數目的預存總計是估計值,而且不需要是整數。
若要建立長條圖,查詢最佳化工具會排序資料行值、計算符合每一個相異資料行值的值數目,然後將資料行值彙總成最多 200 個連續長條圖步驟。 每一個步驟都包含某個範圍的資料行值,後面緊接著上限資料行值。 此範圍包括界限值之間的所有可能資料行值,但是不包括界限值本身。 最低的已排序資料行值就是第一個長條圖步驟的上限值。
下列長條圖顯示包含六個步驟的長條圖。 第一個上限值左側的區域就是第一個步驟。

每一個長條圖步驟:
- 粗線代表上限值 (RANGE_HI_KEY) 以及其所發生的次數 (EQ_ROWS)
- RANGE_HI_KEY 左邊的實線區域代表資料行值範圍以及每一個資料行值發生的平均次數 (AVG_RANGE_ROWS)。 第一個長條圖步驟的 AVG_RANGE_ROWS 一定是 0。
- 虛線代表用來預估範圍內相異值總數的取樣值 (DISTINCT_RANGE_ROWS) 以及範圍內的值總數 (RANGE_ROWS)。 查詢優化器會使用RANGE_ROWS和DISTINCT_RANGE_ROWS來計算AVG_RANGE_ROWS,而且不會儲存取樣的值。
查詢最佳化工具會根據長條圖步驟的統計重要性來定義長條圖步驟。 它會使用最大值差異演算法,讓長條圖中的步驟數減至最少,同時讓界限值之間的差異最大化。 步驟數的最大值為 200。 長條圖步驟的數目可以少於相異值數目,即使包含了少於 200 個界限點的資料行也是如此。 例如,包含 100 個相異值的資料行可以擁有少於 100 個界限點的長條圖。
密度向量
查詢最佳化工具會使用密度來增強查詢的基數預估,這些查詢會從相同的資料表或索引檢視表傳回多個資料行。 密度向量針對統計資料物件中資料行的每個前置詞各包含一個密度。 例如,如果統計資料物件具有 CustomerId、ItemId 和 Price 等索引鍵資料行,就會根據下列每一個資料行前置詞來計算密度。
| 資料行前置詞 | 計算密度的依據 |
|---|---|
(CustomerId) |
與 的值相符的資料列CustomerId |
(CustomerId, ItemId) |
與 CustomerId 和 ItemId 的值相符的資料列 |
(CustomerId, ItemId, Price) |
與 CustomerId、ItemId 和 Price 的值相符的資料列 |
限制
DBCC SHOW_STATISTICS 不會提供空間索引或記憶體優化數據行存放區索引的統計數據。
SQL Server 和 SQL 資料庫的權限
若要檢視統計資料物件,使用者必須具有資料表的 SELECT 權限。
SELECT 權限必須先符合下列需求,才能執行此命令:
- 使用者必須有統計資料物件的所有資料行的權限
- 使用者必須有篩選條件 (如果有) 的所有資料行的權限
- 數據表不能有數據列層級的安全策略。
- 如果統計數據物件內的任何數據行都以動態數據遮罩規則遮罩,除了
SELECT許可權之外,用戶還必須擁有UNMASK許可權,或成為db_ddladmin角色的成員。
在 SQL Server 2012 (11.x) Service Pack 1 之前的版本,用戶必須擁有數據表,或者用戶必須是系統管理員固定伺服器角色、db_owner固定資料庫角色或db_ddladmin固定資料庫角色的成員。
注意
若要將行為變更回 SQL Server 2012 (11.x) Service Pack 1 行為,請使用追蹤旗標 9485。
Azure Synapse Analytics 和 Analytics Platform System (PDW) 的權限
DBCC SHOW_STATISTICSSELECT需要 sysadmin 固定伺服器角色、db_owner固定資料庫角色或db_ddladmin固定資料庫角色之數據表或成員資格的許可權。
Azure Synapse Analytics 和 Analytics Platform System (PDW) 的限制事項
DBCC SHOW_STATISTICS 會顯示在控制節點層級的 Shell 資料庫中儲存的統計資料。 它不會顯示 SQL Server 在計算節點上自動建立的統計數據。
DBCC SHOW_STATISTICS 外部數據表不支援。
在 Microsoft Fabric 中, DBCC SHOW_STATISTICS 只會顯示直方圖統計數據的結果,而不是 ACE-* 統計數據。
範例:SQL Server 和 Azure SQL Database
A. 傳回所有的統計資料資訊
下列範例會顯示 AdventureWorks2022 資料庫中數據表索引Person.Address的所有統計數據資訊AK_Address_rowguid。
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. 指定 HISTOGRAM 選項
這會限制 Customer_LastName 顯示的統計資料資訊是 HISTOGRAM 資料。
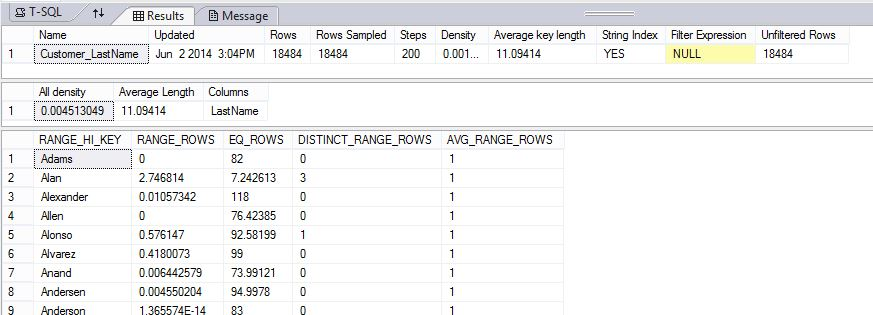
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
範例:Azure Synapse Analytics 和 Analytics Platform System (PDW)
C. 顯示一個統計資料物件的內容
下列範例會建立統計數據對象,然後顯示 AdventureWorksPDW2022 範例資料庫中數據表上統計數據DimCustomer的內容Customer_LastName。
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
結果會顯示標頭、密度向量和部分長條圖。
另請參閱
- 統計資料
- Microsoft Fabric 中的統計數據
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
後續步驟
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應