針對可用性群組故障轉移 Always On 疑難解答
注意事項
若要自動化本文所述的手動分析,請參閱 使用 AGDiag 診斷可用性群組健康情況事件。
本文提供疑難解答步驟,協助您判斷可用性群組故障轉移的原因。
Always On 健康情況問題或故障轉移的徵兆和影響
Always On 透過不同機制實作健全狀況監視,以確保裝載主要復本、基礎叢集和系統健康情況的 Microsoft SQL Server 實例健康情況。 識別到 Windows 叢集或 Always On 健康情況問題時,生產工作負載會暫時中斷。
偵測到健康情況時,通常會發生下列事件序列。 在整個疑難解答員中,健康情況事件會在下列事件的參考中提及:
可用性群組複本和資料庫從主要角色轉換為解析角色。
可用性群組資料庫會轉換為離線,且無法再存取。
Windows 叢集會將可用性群組叢集資源標示為失敗。
Windows 叢集會嘗試讓可用性群組角色在原始或自動故障轉移夥伴複本) 上重新上線 (。
如果 Always On 和 Windows 叢集健康情況監視偵測到其狀況良好,可用性群組角色就會成功上線。
如果成功,可用性群組復本和資料庫會轉換成主要角色,而可用性群組資料庫會上線,並可供您的應用程式存取。
應用程式無法存取可用性群組資料庫
偵測到健康情況時,可用性群組複本和資料庫會轉換為解析角色,而可用性群組資料庫會脫機。 當復本在原始復本伺服器或故障轉移夥伴複本伺服器) 上線的主要角色 (之後,複本和資料庫會再次轉換為在線。 當複本和資料庫正在解析並離線時,嘗試存取這些可用性群組資料庫的任何應用程式都會失敗,併產生「錯誤 983」訊息: Unable to access availability database...。 如果 SQL Server 設定為記錄失敗的登入嘗試,此錯誤也會記錄在 Microsoft SQL Server 錯誤記錄檔中:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
可用性群組在主要角色中重新上線之前處於解析角色的期間,通常只會持續幾秒鐘或甚至少於一秒。
識別及診斷 Always On 可用性群組健康情況事件或故障轉移
1.識別 Always On 健康情況趨勢
您可能會調查單一 Always On 健康情況事件,或可能是近期或持續發生間歇性中斷生產環境的健康情況問題趨勢。 下列問題可協助您縮小範圍,並將生產環境中可能與這些健康情況問題相關的最近變更相互關聯:
- Always On 或叢集健康情況事件趨勢何時開始?
- 健康情況事件是否在某一天發生?
- 健康情況事件是否在一天的特定時間發生?
- 健康情況事件是否發生在當月的某一天或一周?
如果您偵測到趨勢,請在虛擬環境中檢查系統 (主機系統的排程維護,) 、ETL 批次和其他可能與這些健康情況事件相互關聯的作業。 如果系統是虛擬機,請調查主機系統是否有可能在中斷時引入的變更。
請考慮可能與健康情況問題 (時間相互關聯的忙碌臨機操作生產工作負載,例如,使用者第一次登入系統時,或使用者從午餐) 返回時。
注意事項
這是考慮一個計劃來收集整個一周和一個月的效能數據的好時機。 若要進一步了解系統何時最忙碌,您可以測量 Windows 性能監視器計數器,例如 Processor Information::% Processor Time、 Memory::Available MBytes和 MSSQLServer:SQL Statistics::Batch Requests/sec。
2.檢閱叢集記錄
Windows 叢集記錄檔是最完整的記錄檔,可用來識別 Always On 或叢集健康情況事件的種類,以及偵測到造成事件的健康情況。 若要產生並開啟叢集記錄檔,請遵循下列步驟:
使用 Windows PowerShell 在健全狀況事件時裝載主要複本的叢集節點上產生 Windows 叢集記錄。 例如,使用 'sql19agn1' 作為 SQL Server 型伺服器名稱,在提升許可權的 PowerShell 視窗中執行下列 Cmdlet:
get-clusterlog -Node sql19agn1 -UseLocalTime

注意事項
根據預設,記錄檔會建立在 %WINDIR%\cluster\reports 中。
3.在叢集記錄中尋找健康情況事件
Always On 使用數種健康情況監視機制來監視可用性群組健康情況。 除了 Windows 叢集健康情況事件 (Windows 叢集偵測到叢集節點) 的健康情況問題之外,Always On 還有四種不同類型的健康情況檢查:
- SQL Server 服務未執行
- SQL Server 租用逾時
- SQL Server 健康情況檢查逾時
- 內部健康 SQL Server 問題
您可以藉由搜尋字串 的叢集記錄檔,找出這些 Always On 特定健康情況事件的任何一個[hadrag] Resource Alive result 0。 偵測到這些事件時,此字串會儲存在叢集記錄檔中。 例如:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
您可以使用工具來尋找叢集記錄檔中的所有健康情況事件,以便產生 Always On 健康情況問題的摘要報告。 這有助於識別時間趨勢,並判斷特定類型的 Always On 健康情況是否週期性。 下列螢幕快照顯示如何使用文本編輯器 (NotePad++,在此案例中,) 尋找叢集記錄檔中包含 [hadrag] Resource Alive result 0 字串的所有行:

判斷觸發故障轉移的健康情況問題種類
若要判斷您在主要複本的叢集記錄檔中找到的健全狀況問題種類,請將這些問題與後續幾節中所述的問題進行比較。
叢集健康情況事件
Microsoft Windows 叢集會監視叢集中成員伺服器的健康情況。 如果偵測到健康情況問題,可能會從叢集移除叢集成員伺服器。 此外,叢集資源 (包括已移除叢集成員伺服器上裝載的可用性群組角色) ,如果已設定為自動故障轉移,則會移至可用性群組故障轉移夥伴複本。
叢集健康情況事件的徵兆
以下是叢集記錄檔中的叢集健康情況事件範例。 若要尋找它,您可以搜尋 Lost quorum 或 Cluster service has terminated ,因為在可用性群組角色變更或故障轉移期間可能會出現。
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
另一種識別此事件的方式是搜尋 Windows 系統事件記錄檔:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
診斷叢集健康情況事件
Windows 事件記錄檔中的錯誤 (事件 1135 和 1177) 表示網路連線是事件的原因。 這是偵測到叢集健康情況問題的最常見原因。 下列範例顯示其他叢集成員伺服器無法與裝載可用性群組主要復本的這部伺服器通訊,而且此問題觸發了從叢集移除叢集節點:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
您可以搜尋叢集記錄檔,以尋找節點連線失敗的證據。 從您找到 Lost quorum的叢集記錄檔中的位置,向後搜尋字串,例如 Failed to connect to remote endpoint、 unreachable和 is broken。
解決叢集健康情況事件
請確定叢集健康情況監視適用於主機環境。 如需裝載於 Microsoft Azure SQL Server Always On 可用性群組的詳細資訊,請參閱 Windows Server 故障轉移叢集概觀 - Azure VM 上的 SQL Server。
如有必要,請考慮連絡 Microsoft Windows 高可用性支援以開啟支援事件。
SQL Server 服務關閉:Always On 健康情況事件
Always On 健康情況監視可以偵測裝載可用性群組主要復本的 SQL Server 服務是否不再執行。
SQL Server 服務關機的徵兆
以下是可用性群組角色 'ag' 的叢集記錄報告範例,指出因為傳回進程標識0碼而QueryServiceStatusEx失敗:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
診斷和解決 SQL 服務關機事件
檢查 Windows 系統事件記錄檔並 SQL Server 錯誤記錄檔,以取得非預期的 SQL Server 關機。
如果 SQL Server 由系統關機或系統管理關機關閉,您會在 SQL Server 錯誤記錄檔中看到下列專案:
2023-03-10 09:38:46.73 spid9s SQL Server 因應 Service Control Manager 的「停止」要求而終止。 這隻是一則訊息訊息。 不需要使用者動作。
Windows 系統事件記錄檔會顯示下列錯誤專案:
資訊 3/10/2023 上午 9:41:06 服務控制管理員 7036 無 SQL Server (MSSQLSERVER) 服務進入停止狀態。
如果 SQL Server 意外關閉,Windows 系統事件記錄檔會顯示下列錯誤專案:
錯誤 3/10/2023 8:37:46 AM Service Control Manager 7034 None #DC50FC07DF19D4CC5B1CE3D3B1655AFE9 (MSSQLSERVER) 服務意外終止。 它已 () 完成此作業 1 次。
檢查 SQL Server 錯誤記錄檔的結尾,以取得線索。 如果錯誤記錄檔突然結束,這表示它已強制關閉。 例如,如果 SQL Server 使用任務管理員終止,SQL Server 錯誤報告就不會顯示任何可能造成進程關閉的內部問題相關信息。
如果 SQL Server 內部健康情況問題導致 SQL Server 意外終止,可能會有可能嚴重例外狀況的線索, (包括在 SQL 錯誤記錄檔結尾) 產生傾印檔案診斷。 檢閱線索並採取必要的動作。 如果您找到傾印檔案,請考慮開啟連絡 Microsoft SQL Server 支援,並提供 SQL Server 錯誤記錄檔和傾印檔案內容,以供進一步調查。
租用逾時:Always On 健康情況事件
Always On 使用「租用」機制來監視安裝 SQL Server 之計算機的健康情況。 默認租用逾時為20秒。
Always On 租用逾時事件的徵兆
以下是叢集記錄中 Always On 租用逾時的範例輸出。 您可以搜尋這些字串,以在叢集記錄中找出租用逾時。
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
如需租用逾時的詳細資訊,請參閱機制中的租用機制一節,以及 Always On 可用性群組的租用、叢集和健康情況檢查逾時指導方針。
診斷和解決 Always On 租用逾時事件
有兩個主要問題可能會觸發租用逾時:
SQL Server 傾印檔案診斷:當 SQL Server 偵測到某些內部健康情況事件,例如存取違規、判斷提示或排程器死結時,它會在 SQL Server \LOG 資料夾中 (.mdmp) 產生診斷傾印檔案。
全系統的效能問題:租用逾時不一定表示 SQL Server 健康情況問題。 相反地,這可能表示全系統的健全狀況問題也會影響 SQL Server 型伺服器的健康情況。 如需更詳細的疑難解答步驟,請 參閱MSSQLSERVER_19407。
1.SQL Server 傾印檔案診斷
SQL Server 可能會偵測內部健康情況問題,例如存取違規、判斷提示或死結的排程器。 在此情況下,程式會在診斷程式 SQL Server 程式的 SQL Server \LOG 資料夾中,產生 (.mdmp) 的迷你傾印檔案。 當迷你傾印檔案寫入磁碟時,SQL Server 程序會凍結數秒。 在此期間,SQL Server 進程中的所有線程都處於凍結狀態。 這包括 Always On 健康情況監視所監視的租用線程。 因此,Always On 可能會偵測到租用逾時。
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
若要解決此問題,必須調查傾印檔案診斷的根本原因。 請考慮連絡 Microsoft SQL Server 支援,以提供 SQL Server 錯誤記錄檔和傾印檔案內容,以供進一步調查。
2.高 CPU 使用量或其他系統效能問題
租用逾時表示會影響整個系統的效能問題,包括 SQL Server。 若要診斷系統問題,Always On 健康情況診斷會報告叢集記錄中的效能監視數據,並包含租用逾時事件。 效能數據會跨越約 50 秒,導致租用逾時事件,並報告 CPU 使用率、可用記憶體和磁碟延遲。
以下是報告的效能數據範例,其中顯示叢集記錄中的租用逾時。 在此範例輸出中,可能會與租用逾時相關的高整體 CPU 使用率。
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
如果效能數據在租用逾時時顯示高 CPU 使用率、低記憶體條件或高磁碟延遲,請開始收集主要復本上一整天的 效能監視器 數據,以調查這些徵兆。 藉由擷取較長期間的效能監視數據,您可以更清楚地識別這些資源的基準和尖峰值,並在租用逾時時監視這些資源的變更。 當您收集此數據時,請考慮 SQL Server 中是否有特定排程或臨機操作工作負載與這些資源問題和健康情況事件的時間相互關聯。
您也應該擷取報告相同系統資源使用量的計數器,包括下列專案:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
健康情況檢查逾時:Always On 健康情況事件
當可用性群組復本轉換成主要角色時,Always On 健康情況監視會建立與 SQL Server 實例的本機 ODBC 連線。 當 Always On 連線並監視時,如果 SQL Server 未在針對可用性群組的健康情況檢查逾時設定的期間內回應 ODBC 連線, (預設值為 30 秒) ,則會觸發健康情況檢查逾時事件。 在此情況下,可用性群組會從主要角色轉換為解析角色,並在設定為執行此動作時起始故障轉移。
For more information about health check time-outs, see the "Health check timeout operation" section in Mechanics and guidelines of lease, cluster, and health check timeouts for Always On availability groups.
以下是叢集記錄中所報告的 Always On 健康狀態檢查逾時:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
診斷和解決健康情況檢查逾時事件 Always On
下一節可協助您檢閱 SQL Server 記錄中是否有您可能會找到的“bread crumb” 事件,且這些事件與 Always On 偵測到並報告的健康情況檢查逾時相關。 此處檢閱的記錄包括確認健康情況檢查逾時) 的叢集記錄 (、system_health擴充事件記錄檔和 SQL Server 錯誤記錄 (兩者都位於 SQL Server \LOG 資料夾) 中,以及 Windows 系統事件記錄檔中。 使用這些記錄和其他記錄來尋找相互關聯的事件,這些事件可協助您界定健康情況檢查逾時的原因。
1.檢查未產生的排程器事件
Always On 健康狀態檢查逾時通常是由 SQL Server 中的「未產生」事件所造成。 當 SQL Server 偵測到線程未在排程器上產生時,它會報告發生未產生的排程器事件。 如果您在未收到 CPU 時間的相同排程器上看到其他工作,這是未產生排程器的主要標誌。 此行為可能會導致這些工作延遲執行,以及指派給特定 CPU 時間排程器的工作負載「耗盡」。
若要檢查未產生的排程器事件,請遵循下列步驟:
檢查 SQL Server
system_health擴充事件記錄檔,以判斷是否在 Always On 健康情況檢查逾時事件的時間前後報告某種非產生的排程器事件。 您可能會發現非產生的事件包括下列專案:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
開啟主要復本上 SQL Server 系統健康情況擴充事件記錄檔,以取得可疑健康狀態檢查逾時的時間。
在 SQL Server Management Studio (SSMS) 中,移至 [檔案>開啟],然後選取 [合併擴充事件檔案]。
選取 [新增] 按鈕。
在 [檔案開啟] 對話框中,流覽至 SQL Server \LOG 目錄中的檔案。
按住 Control,然後選取名稱開頭為 的
system_health_xxx.xel檔案。選 取 [開啟>確定]。
篩選結果。 以滑鼠右鍵按下 名稱 資料行下的事件,然後選取 [依此值篩選]。

定義篩選來排序 名稱 數據行中值包含
yield的數據列,如下列螢幕快照所示。 這會傳回可能已記錄在記錄中system_health的所有非產生事件類型。
比較時間戳,以查看健康情況檢查逾時時是否有未產生的事件。以下是叢集記錄中所報告的健康情況檢查逾時:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.您可以看到在健康情況檢查逾時時發生未產生的事件。
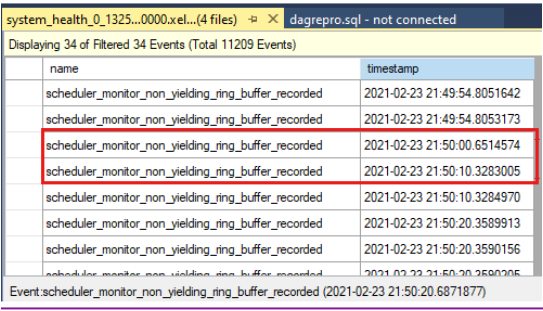
如果偵測到非產生事件,請檢查非產生事件的原因。 請考慮連絡 SQL Server 支援小組,以調查未產生的事件。
2.檢查 SQL Server 錯誤記錄檔
檢查 SQL Server 錯誤記錄檔,以在健康情況檢查逾時時將事件相互關聯。這些事件可能會提供「階層階層」,建議進一步的步驟來界定健康情況檢查逾時的根本原因。
例如,下列記錄項目顯示叢集記錄中發生健康情況檢查逾時:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
在 SQL Server 錯誤記錄檔中,在健康情況檢查逾時的秒內,SQL Server 報告它偵測到嚴重的 I/O 延遲:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
檢閱系統事件記錄檔,以取得可能與健康情況檢查逾時事件相關的可能系統線索。 當您檢閱 Windows 系統事件記錄檔時,可能會發現相同健康情況檢查逾時同時回報的 I/O 問題:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server 健康情況:Always On 健康情況事件
Always On 會監視不同種類的 SQL Server 健康情況事件。 當其裝載可用性群組主要複本時,SQL Server 使用不同的元件持續執行sp_server_diagnostics報告 SQL Server 健康情況。 偵測到任何健康情況問題時,sp_server_diagnostics回報該特定元件的錯誤,然後將結果傳回 Always On 健康情況偵測程式。 報告錯誤時,可用性群組角色會在可用性群組設定為執行此動作時顯示失敗狀態和可能的故障轉移。
Always On SQL Server 健康情況事件的徵兆
以下是叢集記錄中所sp_server_diagnostics報告 SQL Server 健康情況問題的範例。 SQL Server 報告系統元件中的「錯誤」狀態,以 Always On 健康情況監視,而 「contoso-ag」 可用性群組會轉換成失敗狀態。
注意事項
SQL Server 健康情況問題會產生與健康情況檢查逾時類似的報告。這兩個健康情況事件都會報告 Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel。 SQL Server 健康情況事件的差別在於,它會報告 SQL Server元件從「警告」變更為「錯誤」。
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
診斷和解決 SQL Server 健康情況事件
SQL Server 健康情況所報告的健康情況問題類型應該會決定根本原因分析的方向。
根據預設,當您部署可用性群組時, FAILURE_CONDITION_LEVEL 會設定為三。 這會啟動某些健康情況配置檔的監視,但並非所有 SQL Server 狀況配置檔。 在預設層級,當 SQL Server 產生太多傾印檔案、寫入存取違規或孤立的線程鎖定時,Always On 會觸發健康情況事件。 將可用性群組設定為層級 4 或 5,將會擴充受監視的 SQL Server 健康情況問題類型。 如需 SQL Server 健全狀況 Always On 監視器的詳細資訊,請參閱設定可用性群組的彈性自動故障轉移原則 - SQL Server Always On。
若要識別 Always On 特定健康情況問題,請遵循下列步驟:
開啟主要復本上 SQL Server 叢集診斷擴充事件記錄檔,以取得發生可疑 SQL Server 健康情況事件的時間。
在 SSMS 中,移至 [檔案>開啟],然後選取 [ 合併擴充事件檔案]。
選取 新增。
在 [檔案開啟] 對話框中,流覽至 SQL Server \LOG 目錄中的檔案。
按 下 [控制],選取名稱符合
<servername>_<instance>_SQLDIAG_xxx.xel的檔案,然後選取 [ 開啟>確定]。
您會在 SSMS 中看到包含擴充事件的新索引標籤視窗,如下列螢幕快照所示。
若要調查 SQL Server 健康情況問題,請找出
component_health_result其state_desc值為 的error。 以下是系統元件事件的範例,此事件會向健康情況監視回報錯誤 Always On:
按兩下下方窗格中 的數據 行。 這會在新的SSMS視窗窗格中開啟詳細的元件數據以供檢閱。 以下是系統元件資料的外觀:

請注意,'totalDumprequests=186' 數據表示此 SQL Server 上已產生太多傾印檔案診斷事件。 這就是系統元件回報錯誤狀態的原因。 當 Always On 健康情況監視收到此錯誤狀態時,會觸發可用性群組健康情況事件。 您也可以從系統元件數據中提供的數據,確認未偵測到任何寫入存取違規或孤立線程鎖定。
如有必要,請連絡 SQL Server 支援人員以開啟支援事件,以取得進一步協助以找出這些內部 SQL Server 健康問題的根本原因。



意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應