語音辨識
使用語音辨識來提供輸入、指定動作或命令,以及完成工作。
語音識別由語音執行階段、用於對執行階段進行編程的識別 API、用於聽寫和 Web 搜尋的即用語法以及幫助使用者發現和使用語音識別功能的預設系統 UI 組成。
設定語音辨識
若要使用您的應用程式支援語音識別,使用者必須在其裝置上連接並啟用麥克風,並接受 Microsoft 隱私權政策,授予您的應用程式使用麥克風的權限。
若要自動透過系統對話方塊提示使用者要求存取和使用麥克風音訊來源的權限 (範例來自下方所示的語音辨識和語音合成範例),只需在應用程式封包清單中設定麥克風裝置功能即可。 如需詳細資訊,請參閱應用程式功能宣告

如果使用者點擊「是」授予對麥克風的存取權限,您的應用程式將會新增至設定 - >隱私權 -> 麥克風頁面上的已核准應用程式清單。 不過,由於使用者可以選擇隨時關閉此設定,因此您應該先確認您的應用程式可以存取麥克風,然後再嘗試使用它。
如果您還想支援聽寫、Cortana 或其他語音辨識服務 (例如主題限制中定義的預定義文法),您還必須確認已啟用線上語音辨識 (設定 - >隱私 - >語音)。
此代碼段示範您的應用程式如何檢查麥克風是否存在,以及其是否具有使用它的許可權。
public class AudioCapturePermissions
{
// If no microphone is present, an exception is thrown with the following HResult value.
private static int NoCaptureDevicesHResult = -1072845856;
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
public async static Task<bool> RequestMicrophonePermission()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings settings = new MediaCaptureInitializationSettings();
settings.StreamingCaptureMode = StreamingCaptureMode.Audio;
settings.MediaCategory = MediaCategory.Speech;
MediaCapture capture = new MediaCapture();
await capture.InitializeAsync(settings);
}
catch (TypeLoadException)
{
// Thrown when a media player is not available.
var messageDialog = new Windows.UI.Popups.MessageDialog("Media player components are unavailable.");
await messageDialog.ShowAsync();
return false;
}
catch (UnauthorizedAccessException)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception exception)
{
// Thrown when an audio capture device is not present.
if (exception.HResult == NoCaptureDevicesHResult)
{
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
await messageDialog.ShowAsync();
return false;
}
else
{
throw;
}
}
return true;
}
}
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
IAsyncOperation<bool>^ AudioCapturePermissions::RequestMicrophonePermissionAsync()
{
return create_async([]()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings^ settings = ref new MediaCaptureInitializationSettings();
settings->StreamingCaptureMode = StreamingCaptureMode::Audio;
settings->MediaCategory = MediaCategory::Speech;
MediaCapture^ capture = ref new MediaCapture();
return create_task(capture->InitializeAsync(settings))
.then([](task<void> previousTask) -> bool
{
try
{
previousTask.get();
}
catch (AccessDeniedException^)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception^ exception)
{
// Thrown when an audio capture device is not present.
if (exception->HResult == AudioCapturePermissions::NoCaptureDevicesHResult)
{
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("No Audio Capture devices are present on this system.");
create_task(messageDialog->ShowAsync());
return false;
}
throw;
}
return true;
});
}
catch (Platform::ClassNotRegisteredException^ ex)
{
// Thrown when a media player is not available.
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("Media Player Components unavailable.");
create_task(messageDialog->ShowAsync());
return create_task([] {return false; });
}
});
}
var AudioCapturePermissions = WinJS.Class.define(
function () { }, {},
{
requestMicrophonePermission: function () {
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
return new WinJS.Promise(function (completed, error) {
try {
// Request access to the audio capture device.
var captureSettings = new Windows.Media.Capture.MediaCaptureInitializationSettings();
captureSettings.streamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.audio;
captureSettings.mediaCategory = Windows.Media.Capture.MediaCategory.speech;
var capture = new Windows.Media.Capture.MediaCapture();
capture.initializeAsync(captureSettings).then(function () {
completed(true);
},
function (error) {
// Audio Capture can fail to initialize if there's no audio devices on the system, or if
// the user has disabled permission to access the microphone in the Privacy settings.
if (error.number == -2147024891) { // Access denied (microphone disabled in settings)
completed(false);
} else if (error.number == -1072845856) { // No recording device present.
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
messageDialog.showAsync();
completed(false);
} else {
error(error);
}
});
} catch (exception) {
if (exception.number == -2147221164) { // REGDB_E_CLASSNOTREG
var messageDialog = new Windows.UI.Popups.MessageDialog("Media Player components not available on this system.");
messageDialog.showAsync();
return false;
}
}
});
}
})
辨識語音輸入
約束定義應用程式在語音輸入中識別的單字和片語 (詞彙)。 條件約束是語音辨識的核心,可讓應用程式更充分掌控語音辨識的正確性。
您可以使用下列類型的條件約束來辨識語音輸入。
預先定義的文法
預先定義的聽寫和網路搜尋文法為您的應用程式提供語音識別,無需您編寫文法。 使用這些文法時,語音辨識會由遠端 Web 服務執行,並將結果傳回至裝置。
預設的自由文字聽寫文法可以識別使用者可以用特定語言說出的大多數單字和片語,並且經過最佳化以識別片語。 如果您未指定 SpeechRecognizer 物件的任何條件約束,則會使用預先定義的聽寫文法。 當您不想限制使用者可以說的內容時,自由文字聽寫非常有用。 一般用途包括建立筆記或聽寫訊息的內容。
網頁搜尋文法,例如聽寫文法,包含使用者可能會說的大量文字和片語。 但是,這已經過最佳化,可以識別人們在搜尋網路時通常使用的術語。
注意
由於預先定義的聽寫和網路搜尋文法可能很大,而且是透過線上 (不在裝置上),因此效能可能不如裝置上安裝的自訂文法快。
這些預先定義的文法可用於識別長達 10 秒的語音輸入,並且不需要您進行任何創作。 但是,它們確實需要連接到網路。
若要使用 Web 服務條件約束,必須在設定中啟用語音輸入和聽寫支援,方法是在設定 - >隱私權 - >語音、筆跡和輸入中開啟「了解我」選項。
在這裡,我們會示範如何測試是否啟用語音輸入,並開啟 設定 - >隱私權 -> 語音、筆跡和輸入頁面,如果沒有的話。
首先,我們會將全域變數 (HResultPrivacyStatementDeclined) 初始化為 0x80045509 的 HResult 值。 請參閱 C# 或 Visual Basic 中的例外狀況處理。
private static uint HResultPrivacyStatementDeclined = 0x80045509;
然後,我們在識別過程中捕獲任何標準例外狀況,並測試 HResult 值是否等於 HResult PrivacyStatementDeclined 變數的值。 如果是,我們會顯示警告並呼叫 await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts")); 以開啟設定頁面。
catch (Exception exception)
{
// Handle the speech privacy policy error.
if ((uint)exception.HResult == HResultPrivacyStatementDeclined)
{
resultTextBlock.Visibility = Visibility.Visible;
resultTextBlock.Text = "The privacy statement was declined." +
"Go to Settings -> Privacy -> Speech, inking and typing, and ensure you" +
"have viewed the privacy policy, and 'Get To Know You' is enabled.";
// Open the privacy/speech, inking, and typing settings page.
await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts"));
}
else
{
var messageDialog = new Windows.UI.Popups.MessageDialog(exception.Message, "Exception");
await messageDialog.ShowAsync();
}
}
請參閱 SpeechRecognitionTopicConstraint。
程式設計版面清單條件約束
程式設計清單約束提供了一種使用單字或片語清單建立簡單文法的輕量級方法。 清單約束非常適合識別簡短且不同的片語。 明確指定文法中的所有單字還可以提高辨識準確性,因為語音辨識引擎只需處理語音即可確認配對。 該清單也可以透過程式設計更新。
清單條件約束是由字串數位所組成,代表您的應用程式將接受以進行辨識作業的語音輸入。 您可以藉由建立語音辨識清單條件約束物件並傳遞字串陣列,在應用程式中建立清單條件約束。 然後,將該物件新增至辨識器的條件約束集合。 當語音辨識數位中的任何一個字串時,辨識就會成功。
請參閱 SpeechRecognitionListConstraint。
SRGS 文法
語音辨識文法規格 (SRGS) 文法是靜態檔,與程式設計清單條件約束不同,會使用 SRGS 1.0版所定義的 XML 格式。 SRGS 文法可讓您在一次識別中捕獲多個語義,從而提供對語音辨識體驗的最大控制。
請參閱 SpeechRecognitionGrammarFileConstraint。
語音命令條件約束
使用語音命令定義 (VCD) XML 檔案來定義使用者可在啟動應用程式時用來起始動作的命令。 如需詳細資訊,請參閱透過 Cortana 使用語音命令啟用前景應用程式。
請參閱 SpeechRecognitionVoiceCommandDefinitionConstraint/
注意您使用哪種類型的約束類型取決於您想要建立的識別體驗的複雜性。 任何都可能是特定識別任務的最佳選擇,並且您可能會在應用程式中找到所有類型的約束的用途。 若要開始使用條件約束,請參閱定義自訂辨識條件約束。
預先定義的通用 Windows 應用程式聽寫語法可識別語言中的大多數單字和片語。 當語音辨識器物件在沒有自訂約束的情況下執行個體化時,它預設會被啟動。
在此範例中,我們會示範如何:
- 建立語音辨識器。
- 編譯預設的通用 Windows 應用程式約束 (尚未將任何語法新增至語音辨識器的語法集中)。
- 使用 RecognizeWithUIAsync 方法所提供的基本辨識 UI 和 TTS 意見反應,開始接聽語音。 如果不需要預設 UI,請使用 RecognizeAsync 方法。
private async void StartRecognizing_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Compile the dictation grammar by default.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
自訂辨識 UI
當您的應用程式透過呼叫 SpeechRecognizer.RecognizeWithUIAsync 嘗試語音辨識時,會依下列順序顯示數個畫面。
如果您使用以預先定義的文法為基礎的條件約束 (聽寫或 Web 搜尋):
- 聽力螢幕。
- 思考畫面。
- 聽到您說出畫面或錯誤畫面。
如果您使用基於單字或短語清單的約束,或基於 SRGS 語法檔案的約束:
- 聽力螢幕。
- 如果使用者所說的話可以解釋為多個潛在結果,則您說的是畫面。
- 聽到您說出畫面或錯誤畫面。
下圖顯示語音辨識器螢幕之間的流程範例,該辨識器會根據 SRGS 文法檔案使用條件約束。 在此範例中,語音辨識成功。

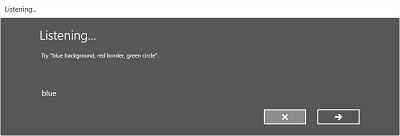
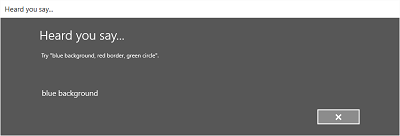
聽力螢幕可以提供應用程式可以識別的單字或短語的範例。 在這裡,我們展示如何使用 SpeechRecognizerUIOptions 類別的屬性 (透過呼叫 SpeechRecognizer.UIOptions 屬性取得) 來自訂收聽螢幕上的內容。
private async void WeatherSearch_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Listen for audio input issues.
speechRecognizer.RecognitionQualityDegrading += speechRecognizer_RecognitionQualityDegrading;
// Add a web search grammar to the recognizer.
var webSearchGrammar = new Windows.Media.SpeechRecognition.SpeechRecognitionTopicConstraint(Windows.Media.SpeechRecognition.SpeechRecognitionScenario.WebSearch, "webSearch");
speechRecognizer.UIOptions.AudiblePrompt = "Say what you want to search for...";
speechRecognizer.UIOptions.ExampleText = @"Ex. 'weather for London'";
speechRecognizer.Constraints.Add(webSearchGrammar);
// Compile the constraint.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
//await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
相關文章
範例

意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應