Xamarin.iOS 中的語音辨識
本文提供新的語音 API,並示範如何在 Xamarin.iOS 應用程式中實作它,以支援連續語音辨識和轉譯語音(從即時或錄製的音訊串流)轉換成文字。
iOS 10 的新功能是 Apple 發行的語音辨識 API,可讓 iOS 應用程式支援連續語音辨識和轉譯語音(從即時或錄製的音訊串流)轉換成文字。
根據 Apple,語音辨識 API 具有下列功能和優點:
- 高度精確
- 藝術狀態
- 容易使用
- 快速
- 支援多種語言
- 尊重用戶隱私權
語音辨識的運作方式
語音辨識是在 iOS 應用程式中實作,方法是取得即時或預先錄製的音訊(以 API 支援的任何口語語言),並將其傳遞至語音辨識器,以傳回口語文字的純文本轉譯。

鍵盤聽寫
當大多數使用者想到 iOS 裝置上的語音辨識時,他們會想到內建的 Siri 語音助理,其與 i 電話 4S 搭配 iOS 5 中的鍵盤聽寫一起發行。
鍵盤聽寫是由任何支援 TextKit 的介面元素所支援,UITextFieldUITextArea而且由使用者按兩下 iOS 虛擬鍵盤中的聽寫按鈕(直接在空格鍵左邊)啟動。
蘋果發佈了下列鍵盤聽寫統計數據(自 2011 年以來收集):
- 自 iOS 5 中發行鍵盤聽寫以來,已廣泛使用鍵盤聽寫。
- 大約 65,000 個應用程式每天使用它。
- 大約三分之一的 iOS 聽寫是在第三方應用程式中完成。
除了在應用程式的UI設計中使用TextKit介面元素以外,鍵盤聽寫非常容易使用,因為開發人員不需要費力。 鍵盤聽寫也具有不需要應用程式的任何特殊許可權要求,才能使用的優點。
使用新語音辨識 API 的應用程式需要使用者授與特殊許可權,因為語音辨識需要 Apple 伺服器上數據的傳輸和暫存記憶體。 如需詳細資訊,請參閱我們的 安全性和隱私權增強功能 檔。
雖然鍵盤聽寫很容易實作,但確實有數個限制和缺點:
- 它需要使用文字輸入欄位和鍵盤的顯示。
- 它僅適用於即時音訊輸入,且應用程式無法控制音訊錄製程式。
- 它無法控制用來解譯使用者語音的語言。
- 應用程式無法知道聽寫按鈕是否連使用者都可以使用。
- 應用程式無法自定義音訊錄製程式。
- 它提供一組非常淺層的結果,缺少時間與信賴等資訊。
語音辨識 API
iOS 10 的新功能 Apple 已發佈語音辨識 API,為 iOS 應用程式實作語音辨識提供了更強大的方式。 此 API 與 Apple 用來為 Siri 和鍵盤聽寫提供電源的 API 相同,而且能夠以最先進的準確度提供快速轉譯。
語音辨識 API 所提供的結果會以透明方式自定義給個別使用者,而不需要應用程式收集或存取任何私人用戶數據。
語音辨識 API 會在用戶說話時,以近乎即時的方式將結果傳回呼叫應用程式,並提供翻譯結果的詳細資訊,而不只是文字。 包括:
- 使用者所說的多次解釋。
- 個別翻譯的信賴等級。
- 計時資訊。
如上所述,即時摘要或來自預先錄製的來源,以及iOS 10支援的任何50種語言和方言,都可以提供翻譯音訊。
語音辨識 API 可用於任何執行 iOS 10 且在大多數情況下的 iOS 裝置上,因為大部分翻譯都會在 Apple 的伺服器上進行,因此需要即時因特網連線。 也就是說,一些較新的iOS裝置一律支援特定語言的裝置上翻譯。
Apple 已包含可用性 API,以判斷目前特定語言是否可供翻譯。 應用程式應該使用此 API,而不是直接測試因特網連線本身。
如上方的鍵盤聽寫一節所述,語音辨識需要透過因特網在 Apple 伺服器上傳輸和暫存數據,因此,應用程式 必須 要求使用者的許可權,以 NSSpeechRecognitionUsageDescription 在其檔案中包含 Info.plist 密鑰並呼叫 SFSpeechRecognizer.RequestAuthorization 方法來執行辨識。
根據用於語音辨識的音訊來源,可能需要對應用程式 Info.plist 檔案進行其他變更。 如需詳細資訊,請參閱我們的 安全性和隱私權增強功能 檔。
在應用程式中採用語音辨識
開發人員必須採取四個主要步驟,才能在iOS應用程式中採用語音辨識:
- 使用
NSSpeechRecognitionUsageDescription金鑰在應用程式的Info.plist檔案中提供使用方式描述。 例如,相機應用程式可能包含下列描述:「 這可讓您只說出 『cheese』這個字來拍攝相片。 - 藉由呼叫 方法來要求授權,
SFSpeechRecognizer.RequestAuthorization以說明NSSpeechRecognitionUsageDescription為何應用程式想要在對話框中存取使用者的語音識別,並允許他們接受或拒絕。 - 建立語音辨識要求:
- 針對磁碟上預先錄製的音訊,請使用 類別
SFSpeechURLRecognitionRequest。 - 針對即時音訊(或記憶體中的音訊),請使用 類別
SFSPeechAudioBufferRecognitionRequest。
- 針對磁碟上預先錄製的音訊,請使用 類別
- 將語音辨識要求傳遞至語音辨識 (
SFSpeechRecognizer) 以開始辨識。 應用程式可以選擇性地保留傳SFSpeechRecognitionTask回的 ,以監視和追蹤辨識結果。
下列步驟將詳細說明。
提供使用方式描述
若要在檔案中Info.plist提供必要的NSSpeechRecognitionUsageDescription金鑰,請執行下列動作:
按兩下檔案
Info.plist以開啟檔案以進行編輯。切換至 [來源] 檢視:
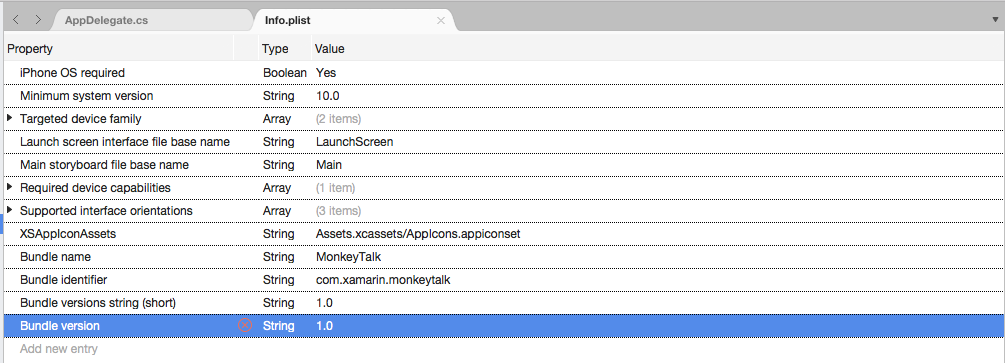
按兩下 [新增專案],針對 [類型
String] 輸入NSSpeechRecognitionUsageDescription,並將 [使用描述] 輸入為 [值]。 例如: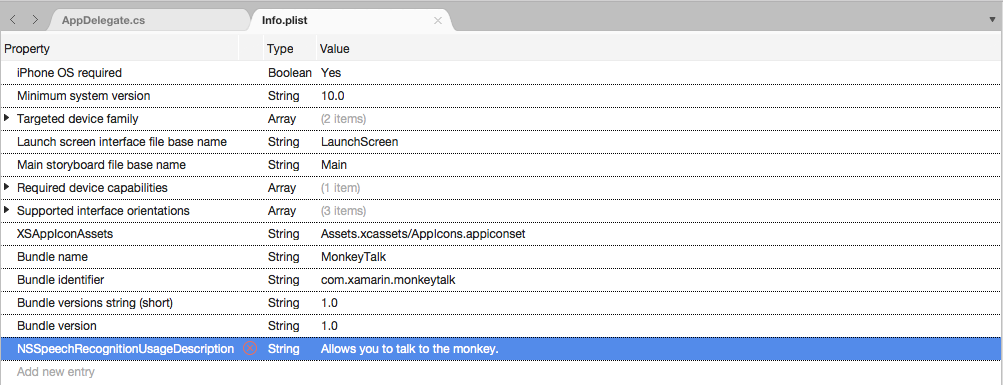
如果應用程式將處理即時音訊轉譯,則也需要麥克風使用描述。 按兩下 [新增專案],針對 [類型
String] 輸入NSMicrophoneUsageDescription,並將 [使用描述] 輸入為 [值]。 例如:
儲存對檔案所做的變更。





重要
如果無法提供上述 Info.plist 任一鍵(NSSpeechRecognitionUsageDescription 或 NSMicrophoneUsageDescription),可能會導致應用程式在嘗試存取語音辨識或麥克風進行即時音訊時失敗,而不會發出警告。
要求授權
若要要求允許應用程式存取語音辨識的必要用戶授權,請編輯主要 View Controller 類別,並新增下列程式代碼:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
類別RequestAuthorization的 SFSpeechRecognizer 方法會使用開發人員在檔案密鑰Info.plist中NSSpeechRecognitionUsageDescription提供的原因,要求使用者存取語音辨識的許可權。
SFSpeechRecognizerAuthorizationStatus結果會傳RequestAuthorization回方法的回呼例程,可用來根據使用者的許可權採取動作。
重要
Apple 建議等到使用者已在應用程式中啟動需要語音辨識的動作,再要求此許可權。
辨識預先錄製的語音
如果應用程式想要從預先錄製的 WAV 或 MP3 檔案辨識語音,則可以使用下列程式代碼:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
查看此程序代碼,首先會嘗試建立語音辨識器 (SFSpeechRecognizer)。 如果語音辨識不支援默認語言, null 則會傳回 ,而且函式會結束。
如果語音辨識器適用於預設語言,應用程式會檢查它目前是否可使用 屬性進行辨識 Available 。 例如,如果裝置沒有作用中的因特網連線,則辨識可能無法使用。
SFSpeechUrlRecognitionRequest會從 NSUrl iOS 裝置上預先錄製的檔案位置建立 ,並且會交給語音辨識器來處理回呼例程。
呼叫回呼時,如果沒有NSErrornull必須處理的錯誤,則為 。 由於語音辨識是以累加方式完成,所以可以多次呼叫回呼例程,因此 SFSpeechRecognitionResult.Final 會測試 屬性,以查看翻譯是否完整且翻譯的最佳版本寫出 (BestTranscription)。
辨識即時語音
如果應用程式想要辨識即時語音,則此程式與辨識預先錄製的語音非常類似。 例如:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
詳細查看此程式碼,它會建立數個私用變數來處理辨識程式:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
它會使用 AV Foundation 來錄製將傳遞至 SFSpeechAudioBufferRecognitionRequest 的音訊,以處理辨識要求:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
如果無法啟動錄製,應用程式會嘗試開始錄製,並處理任何錯誤:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
辨識工作已啟動,且句柄會保留在辨識工作 (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
回呼會以類似上述方式用於預先錄製的語音。
如果使用者停止錄製,則會通知音訊引擎和語音辨識要求:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
如果使用者取消辨識,則會通知音訊引擎和辨識工作:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
如果使用者取消翻譯以釋放記憶體和裝置處理器,請務必呼叫 RecognitionTask.Cancel 。
重要
若無法提供 NSSpeechRecognitionUsageDescription 或 NSMicrophoneUsageDescriptionInfo.plist 鍵,可能會導致應用程式在嘗試存取語音辨識或麥克風進行即時音訊時var node = AudioEngine.InputNode;失敗,而不會發出警告。 如需詳細資訊,請參閱 上面的提供使用量描述 一節。
語音辨識限制
在 iOS 應用程式中使用語音辨識時,Apple 會施加下列限制:
- 語音辨識適用於所有應用程式,但其使用方式並不無限制:
- 個別 iOS 裝置的辨識數目有限,每天可以執行。
- 應用程式會以每天的要求全域進行節流。
- 應用程式必須準備好處理語音辨識網路連線和使用速率限制失敗。
- 語音辨識在使用者的 iOS 裝置上,電池耗盡和高網路流量的成本可能很高,因此,Apple 將嚴格音訊持續時間限制在大約一分鐘的語音上限。
如果應用程式經常達到其速率節流限制,Apple 會要求開發人員與他們連絡。
隱私權和可用性考慮
在 iOS 應用程式中包含語音辨識時,Apple 有下列建議,可讓使用者保持透明並遵守使用者的隱私權:
- 錄製使用者的語音時,請務必清楚指出錄製是在應用程式的使用者介面中進行。 例如,應用程式可能會播放「錄製」音效,並顯示錄製指示器。
- 請勿將語音辨識用於敏感性用戶資訊,例如密碼、健康情況數據或財務資訊。
- 在對它們採取行動之前,先顯示辨識結果。 這不僅會提供應用程式執行動作的意見反應,還允許使用者在進行辨識錯誤時處理錯誤。
摘要
本文介紹新的語音 API,並示範如何在 Xamarin.iOS 應用程式中實作該 API,以支援連續語音辨識和轉譯語音(從即時或錄製的音訊串流)轉換成文字。