Windows Server 2019
A Microsoft server operating system that supports enterprise-level management updated to data storage.
3,518 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJB%3C/text%3E%3C/svg%3E)
We have a cluster of 4 Windows Server 2019 Hyper-V host servers. These servers are attached to FC storage and make use of CSV with NTFS. Networking consists of 10GB Enet using SET teams. This particular cluster hosts almost 200 VM's of which about 45 are Windows 10, generation 2 VM's. The rest of the VM's are either 2012R2, 2016 or 2019 servers.
We recently started monitoring the Microsoft\Windows\Hyper-V-StorageVSP\Admin event log on each of the host servers and noticed that we were getting a LOT of error events like the one below...
Log Name: Microsoft-Windows-Hyper-V-StorageVSP/Admin
Source: Hyper-V-StorageVSP
Event ID: 8
Level: Error
User: SYSTEM
Message: Failed to map guest I/O buffer for write access with status 0xC0000044. Device name = C:\ClusterStorage\CSV1\WIN10VM1\Virtual Hard Disks\WIN10VM1.vhdx
If I look at the system event log of the VM WIN10VM1, we see lots of the following warnings that match up with the same times as the above events on the host server...
Log Name: System
Source: disk
Event ID: 153
Level: Warning
User: N/A
Message: The IO operation at logical block address 0x1a751f9 for Disk 0 (PDO name: \Device\0000002a) was retried.
This happens multiple times a day on all of the Windows 10 VM's. Obviously, across almost 45 VM's, the System log of each has a lot of the disk error event 153 in each of the logs, and of course, each host gets a lot of the previous event log messages as well. This appears to have been going on forever, and only seems to effect the Windows 10 VM's. None of the server VM's seems to be generating any of these warnings or causing any of the host level errors. As far as we can tell, it's not causing any problems with the functionality, but it's very disconcerting seeing disk level errors where I wouldn't otherwise expect it.
Anyone with any ideas, it would be helpful to know what's going on. Thanks.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EUG%3C/text%3E%3C/svg%3E)
Hello, have you found a solution?
greets
At this time we have not found a solution. If we do find a solution, I would be sure to post it up here.
If you do find a solution before I do, please do the same.
Thank you.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
Do you see .RCT files in the folder on the Hyper-V host where the VM's vhdx files are?
If so that suggest RCT (resilient change tracking) is active as part of DPM or Veeam host level backups
Which can also have negative impact on the VM's disk write performance
You are correct that RCT is enabled for some of the VM's that we backup with our backup solution. However, it's not enabled for these Windows 10 desktop VM's.
In this case, at least, that is not the problem.

Hi,
Thanks for your feedback, for error 8, I found the following information:
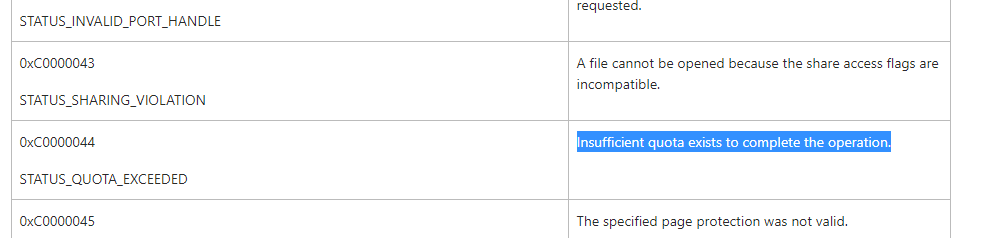
However, there's limited information about how to deal with it. Since the issue may be complex, it's recommended to open a case with MS for deep troublehsooting:
Below is the link to open a case with MS:
https://support.microsoft.com/en-us/gp/customer-service-phone-numbers
Thanks for your time!
Best Regards,
Anne
-----------------------------
If the Answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
Anne,
1) Microsoft Q&A is labeled as: The best place to get answers to all your technical questions on Microsoft products and services. I thought if there is anywhere I could get an answer to this problem, it would be here. I guess I was wrong.
2) Clearly you have never had to open a case with Microsoft support. Prior to Windows Server 2016, we have never had the need to open a case with Microsoft support. If ever we ran into an issue, our experienced team members have been able to resolve those problems, because they were generally configuration issues and not problems with the core product. Since migrating to Windows Server 2016 and 2019, we have had to open numerous cases with Microsoft support for various issues. All of which ended up being bugs.
Microsoft support states that they WILL NOT work to root cause, only break/fix. Additionally, it usually takes them many months to come to the correct conclusion that the issue is a bug that requires a fix from development.
Hi,
In the error 153, please check the error's details, The details section of the event the log record will present what error caused the retry and whether the request was a read or write. Below is an example of the details output:
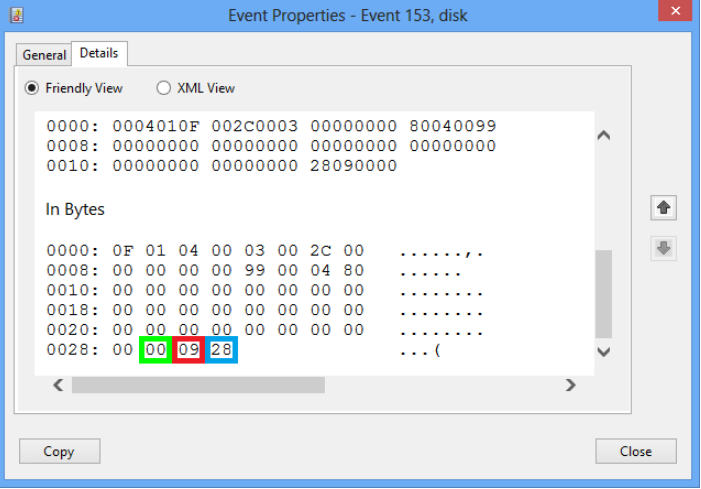
https://learn.microsoft.com/en-us/archive/blogs/ntdebugging/interpreting-event-153-errors
Besides, please check if there's any other errors in the cluster logs, such as CSV event 5120.
Based on my experience, if there's no issue on the operation leave, please check if the FC HBA cards are up to date, if not, please update the HBA cards.
Thanks for your time!
Best Regards,
Anne
-----------------------------
If the Answer is helpful, please click "Accept Answer" and upvote it.
Note: Please follow the steps in our documentation to enable e-mail notifications if you want to receive the related email notification for this thread.
Using the information you provided and the following .h files...
https://github.com/tpn/winsdk-10/blob/master/Include/10.0.14393.0/shared/srb.h
https://github.com/tpn/winsdk-10/blob/master/Include/10.0.14393.0/shared/scsi.h
I was able to look at the details for the event and saw that the status codes were "00 04 88" for the disk 153 events. Using the info from the .h files this tells me SCSISTAT_GOOD, SRB_STATUS_ERROR and SCSIOP_READ16.
I am assuming these means there was an error on read. But I believe that this is a symptom of the problem, and the problem being the event id 8 on the Hyper-V hosts.
What is causing the event id 8 at the host level?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EPV%3C/text%3E%3C/svg%3E)
I am experiencing the same issue on my local machine Hyper-V machines. Both host and guests are Windows 10. There are no errors/warnings on the host machine, all guests reports the "00 04 88" status codes here and there. No data loss, no chkdsk errors.